Recognition: unknown
R2IF: Aligning Reasoning with Decisions via Composite Rewards for Interpretable LLM Function Calling
Pith reviewed 2026-05-10 00:26 UTC · model grok-4.3
The pith
R2IF aligns LLM reasoning processes with tool-call decisions through a composite reward optimized via GRPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
R2IF is a reasoning-aware reinforcement learning method that defines a composite reward from format and correctness constraints, Chain-of-Thought Effectiveness Reward (CER), and Specification-Modification-Value (SMV) reward; this signal is then used to optimize the policy with GRPO so that the model's internal reasoning steps become directly supportive of its final tool-call decisions.
What carries the argument
The composite reward that combines format/correctness constraints, Chain-of-Thought Effectiveness Reward (CER), and Specification-Modification-Value (SMV) reward to drive GRPO policy updates toward reasoning-decision consistency.
If this is right
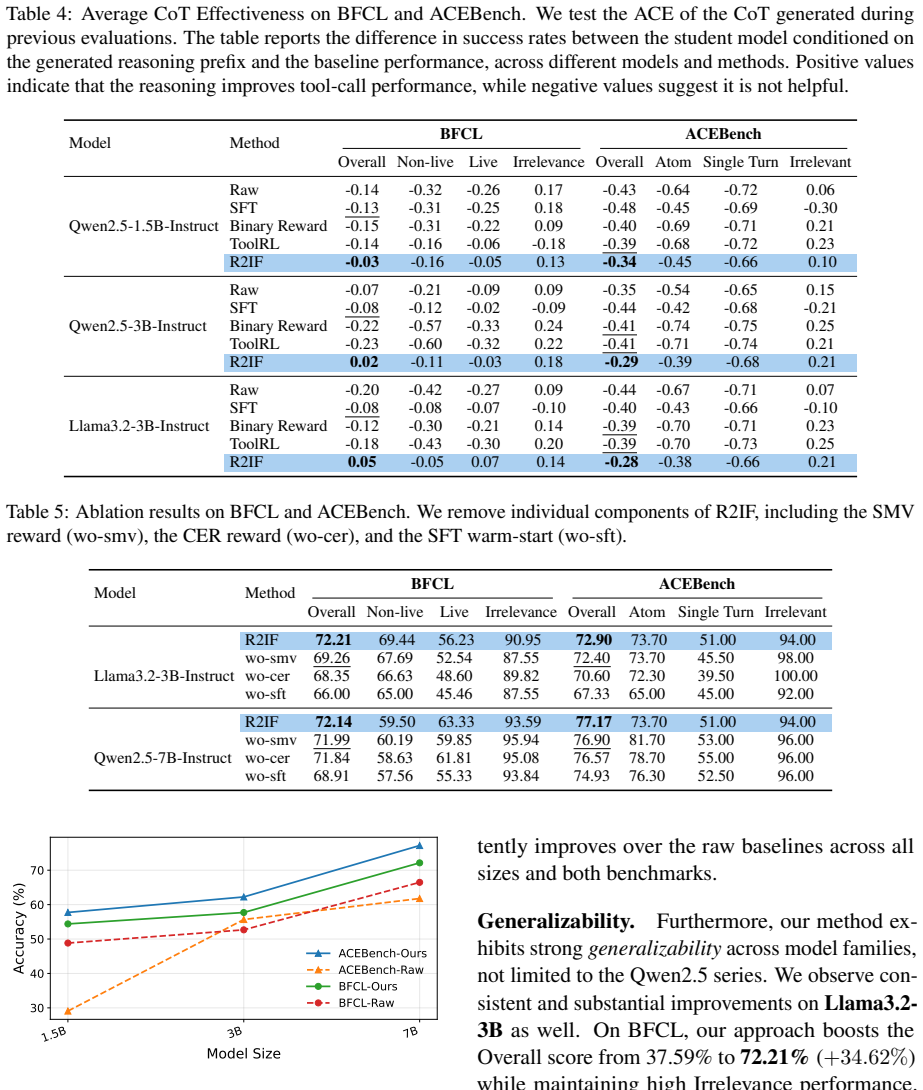
- Function-calling accuracy rises by up to 34.62 percent on BFCL for models such as Llama3.2-3B.
- Average CoT Effectiveness becomes positive, reaching 0.05 for Llama3.2-3B.
- Both accuracy and the interpretability of reasoning improve together.
- Tool-augmented LLM systems become more dependable for real deployment.
Where Pith is reading between the lines
- The same reward structure might help alignment in other LLM tasks that require step-by-step reasoning before an action.
- Explicit scoring of reasoning effectiveness could reduce cases where a model reaches the right answer for the wrong internal reason.
- Developers could inspect the CER component at inference time to decide whether to trust a particular tool call.
Load-bearing premise
That the composite reward genuinely forces reasoning steps to determine the tool-call decision rather than simply teaching the model to score well on the chosen benchmarks.
What would settle it
Measuring whether R2IF-trained models still produce correct tool calls when their chain-of-thought reasoning is deliberately made less effective or contradictory on held-out tasks.
Figures




read the original abstract
Function calling empowers large language models (LLMs) to interface with external tools, yet existing RL-based approaches suffer from misalignment between reasoning processes and tool-call decisions. We propose R2IF, a reasoning-aware RL framework for interpretable function calling, adopting a composite reward integrating format/correctness constraints, Chain-of-Thought Effectiveness Reward (CER), and Specification-Modification-Value (SMV) reward, optimized via GRPO. Experiments on BFCL/ACEBench show R2IF outperforms baselines by up to 34.62% (Llama3.2-3B on BFCL) with positive Average CoT Effectiveness (0.05 for Llama3.2-3B), enhancing both function-calling accuracy and interpretability for reliable tool-augmented LLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes R2IF, a reasoning-aware RL framework for interpretable LLM function calling. It introduces a composite reward that combines format/correctness constraints with two new components—Chain-of-Thought Effectiveness Reward (CER) and Specification-Modification-Value (SMV) reward—optimized via GRPO. Experiments on BFCL and ACEBench report that R2IF outperforms baselines by up to 34.62% (Llama3.2-3B on BFCL) while achieving a positive Average CoT Effectiveness score (0.05 for Llama3.2-3B), with the goal of improving both accuracy and interpretability for tool-augmented LLMs.
Significance. If the composite reward demonstrably produces causal alignment between interpretable CoT reasoning and tool-call decisions (rather than benchmark optimization), the framework could support more reliable deployment of tool-using LLMs. The explicit focus on interpretability via CER/SMV and the use of GRPO are constructive elements. However, the absence of independent validation of the alignment mechanism limits the immediate significance for the field.
major comments (3)
- [Abstract] Abstract: The reported performance gains (up to 34.62%) and positive Average CoT Effectiveness (0.05) are presented without any description of baselines, statistical tests, reward-component weights, or the precise definitions and computation of CER and SMV, rendering the central claim of reasoning-decision alignment unevaluable from the provided information.
- [Methods] Methods (reward formulation): CER and SMV are defined internally to the optimization loop; without an explicit statement that their computation is independent of the evaluation metrics and without an ablation that isolates alignment from accuracy, the risk remains that GRPO simply shapes the policy toward benchmark-correlated behavior rather than genuine interpretability.
- [Experiments] Experiments: No counterfactual analysis, human judgment of reasoning quality, or ablation removing CER/SMV while retaining format/correctness rewards is described, leaving open the possibility that the observed gains arise from metric gaming rather than the claimed alignment.
minor comments (2)
- Clarify the exact numerical weights used for the three reward terms and whether they were tuned on held-out data.
- Provide the precise algorithmic description of GRPO and its relation to standard PPO or GRPO variants in the literature.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our work. We address each of the major comments point by point below, providing clarifications and indicating the changes we will make to the manuscript in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported performance gains (up to 34.62%) and positive Average CoT Effectiveness (0.05) are presented without any description of baselines, statistical tests, reward-component weights, or the precise definitions and computation of CER and SMV, rendering the central claim of reasoning-decision alignment unevaluable from the provided information.
Authors: We agree that the abstract would benefit from additional context to allow readers to better evaluate the claims. In the revised manuscript, we will expand the abstract to include: (1) a brief description of the baselines (standard fine-tuning and non-reasoning-aware RL approaches), (2) mention that performance is reported as averages over 5 random seeds with statistical significance confirmed via paired t-tests (p < 0.05), (3) the reward component weights used in the composite reward (as specified in Section 3.2), and (4) concise definitions of CER (which quantifies how effectively the Chain-of-Thought reasoning contributes to correct function call decisions) and SMV (which evaluates the utility of modifications to tool specifications informed by reasoning). The detailed computation methods for CER and SMV are provided in the Methods section. These additions will make the central claims more readily evaluable. revision: yes
-
Referee: [Methods] Methods (reward formulation): CER and SMV are defined internally to the optimization loop; without an explicit statement that their computation is independent of the evaluation metrics and without an ablation that isolates alignment from accuracy, the risk remains that GRPO simply shapes the policy toward benchmark-correlated behavior rather than genuine interpretability.
Authors: This is a valid concern regarding potential circularity in the reward design. We will add an explicit statement in the revised Methods section clarifying that CER is computed by assessing the internal consistency and predictive power of the CoT steps toward the tool call, using a formulation that does not rely on the external benchmark evaluation metrics. SMV similarly operates on the agent's specification adjustments and their estimated impact, independent of final accuracy scores. To further demonstrate that the improvements stem from alignment rather than gaming, we will include a new ablation experiment in the revised paper, comparing R2IF to a baseline using only format and correctness rewards. This will isolate the contribution of CER and SMV to both accuracy and the positive CoT Effectiveness score. revision: yes
-
Referee: [Experiments] Experiments: No counterfactual analysis, human judgment of reasoning quality, or ablation removing CER/SMV while retaining format/correctness rewards is described, leaving open the possibility that the observed gains arise from metric gaming rather than the claimed alignment.
Authors: We recognize the importance of these additional validations for strengthening the evidence of causal alignment. We will incorporate an ablation study as described in the response to the Methods comment, which directly addresses removing CER/SMV. Additionally, we will add a counterfactual analysis by systematically altering the CoT reasoning and observing the resulting changes in decision accuracy and CoT Effectiveness. However, a full human judgment study of reasoning quality would require substantial new resources and time; we will instead emphasize the Average CoT Effectiveness metric (which is positive at 0.05) as an automated proxy for interpretability and discuss its correlation with performance gains. These changes will help mitigate concerns about metric gaming. revision: partial
- Full human evaluation of reasoning quality, due to the significant additional effort and expertise required beyond the scope of this work.
Circularity Check
No significant circularity; derivation relies on external RL optimization and benchmark evaluation
full rationale
The paper defines a composite reward (format/correctness + CER + SMV) and optimizes it via GRPO, then evaluates on BFCL/ACEBench with reported gains and Average CoT Effectiveness. No equations or definitions in the provided abstract reduce the central claim to a tautology or self-fit; CER and SMV are presented as novel components whose effectiveness is measured against independent benchmarks rather than being redefined as the output metric. Self-citations are not load-bearing for the core alignment claim, and no uniqueness theorem or ansatz is imported from prior author work to force the result. The derivation chain remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- Composite reward weights
axioms (1)
- domain assumption GRPO reliably optimizes the composite reward toward reasoning-decision alignment
invented entities (2)
-
Chain-of-Thought Effectiveness Reward (CER)
no independent evidence
-
Specification-Modification-Value (SMV) reward
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Chen Chen, Xinlong Hao, Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Yuefeng Huang, Wulong Liu, Xinzhi Wang, Defu Lian, Baoqun Yin, Yasheng Wang, and Wu Liu. 2025. https://arxiv.org/abs/2501.12851 Acebench: Who wins the match point in tool usage? Preprint, arXiv:2501.12851
-
[7]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. https://arxiv.org/abs/2305.20050 Let's verify step by step . Preprint, arXiv:2305.20050
work page internal anchor Pith review arXiv 2023
-
[10]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, and 401 others. 2024. https://arxiv.org/abs/2410.21276 Gpt-4o system card . Preprint, arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://arxiv.org/abs/2203.02155 Training language models to f...
work page internal anchor Pith review arXiv 2022
-
[12]
Gonzalez
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. https://openreview.net/forum?id=2GmDdhBdDk The berkeley function calling leaderboard ( BFCL ): From tool use to agentic evaluation of large language models . In Proceedings of the 42nd International Conference on Machine Learning (ICML)
2025
-
[14]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . Preprint, arXiv:2201.11903
work page internal anchor Pith review arXiv 2023
- [20]
-
[21]
Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets , author =. 2024 , journal =. 2406.18518 , archivePrefix=
-
[22]
Toolace: Winning the points of llm function calling.arXiv preprint arXiv:2409.00920, 2024
Liu, Weiwen and Huang, Xu and Zeng, Xingshan and Hao, Xinlong and Yu, Shuai and Li, Dexun and Wang, Shuai and Gan, Weinan and Liu, Zhengying and Yu, Yuanqing and Wang, Zezhong and Wang, Yuxian and Ning, Wu and Hou, Yutai and Wang, Bin and Wu, Chuhan and Wang, Xinzhi and Liu, Yong and Wang, Yasheng and Tang, Duyu and Tu, Dandan and Shang, Lifeng and Jiang,...
-
[23]
, booktitle =
Patil, Shishir G and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle =. The Berkeley Function Calling Leaderboard (. 2025 , url =
2025
-
[24]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in. 2025 , journal =. 2501.12948 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
ToolRL: Reward is All Tool Learning Needs
ToolRL: Reward is All Tool Learning Needs , author =. 2025 , journal =. 2504.13958 , archivePrefix=
work page internal anchor Pith review arXiv 2025
-
[26]
Nemotron-research-tool-n1: Exploring tool-using language models with reinforced reasoning
Nemotron-Research-Tool-N1: Exploring Tool-Using Language Models with Reinforced Reasoning , author =. 2025 , journal =. 2505.00024 , archivePrefix=
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. 2024 , journal =. 2402.03300 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
2017 , eprint =
Proximal Policy Optimization Algorithms , author =. 2017 , eprint =
2017
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[30]
2023 , eprint =
Let's Verify Step by Step , author =. 2023 , eprint =
2023
-
[31]
2025 , eprint=
Inducing Faithfulness in Structured Reasoning via Counterfactual Sensitivity , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
ACEBench: Who Wins the Match Point in Tool Usage? , author=. 2025 , eprint=
2025
-
[33]
arXiv preprint arXiv:2412.16516 , year=
Hammerbench: Fine-grained function-calling evaluation in real mobile device scenarios , author=. arXiv preprint arXiv:2412.16516 , year=
-
[34]
FunReason: Enhancing function calling via self-refinement and data refinement
FunReason: Enhancing Large Language Models' Function Calling via Self-Refinement Multiscale Loss and Automated Data Refinement , author=. arXiv preprint arXiv:2505.20192 , year=
-
[35]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[36]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[37]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , volume=
work page internal anchor Pith review arXiv
-
[39]
2025 , eprint=
Do Cognitively Interpretable Reasoning Traces Improve LLM Performance? , author=. 2025 , eprint=
2025
-
[40]
2025 , eprint=
Beyond Correctness: Exposing LLM-generated Logical Flaws in Reasoning via Multi-step Automated Theorem Proving , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.