Recognition: unknown
UniCVR: From Alignment to Reranking for Unified Zero-Shot Composed Visual Retrieval
Pith reviewed 2026-05-10 01:21 UTC · model grok-4.3
The pith
UniCVR unifies composed image retrieval, multi-turn image retrieval, and composed video retrieval into one zero-shot framework without task-specific annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
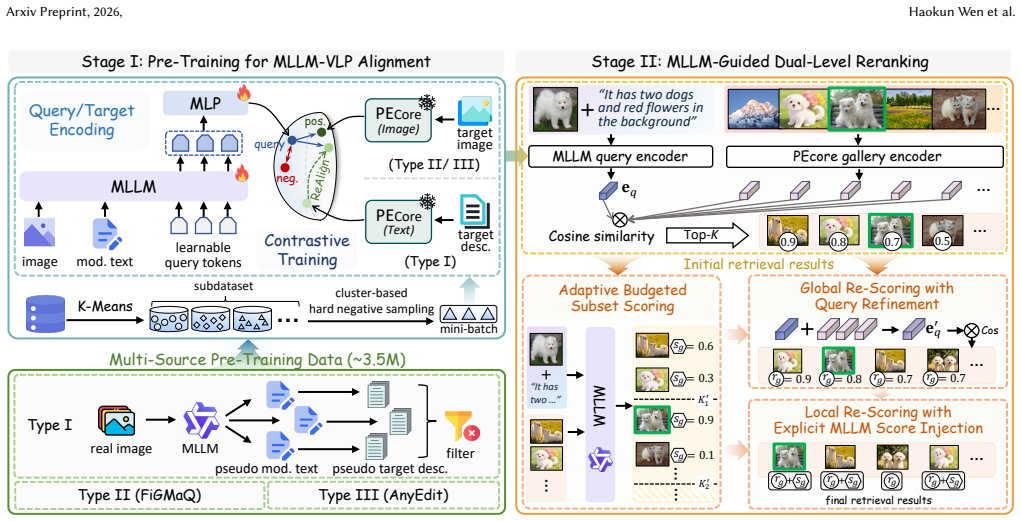
UniCVR is the first unified zero-shot composed visual retrieval framework that jointly addresses composed image retrieval, multi-turn composed image retrieval, and composed video retrieval without any task-specific human-annotated data. It strategically combines multimodal large language models for compositional query understanding with vision-language pre-trained models for structured visual retrieval. The system runs in two stages: contrastive training of the language model as a query embedder on approximately 3.5 million multi-source samples using cluster-based hard negative sampling, followed by an MLLM-guided dual-level reranking mechanism that scores a small budgeted subset of top hits
What carries the argument
The two-stage UniCVR pipeline: Stage I contrastive alignment of the MLLM as compositional query embedder on a multi-source dataset, and Stage II MLLM-guided dual-level reranking with adaptive budgeted subset scoring.
If this is right
- The same model and training recipe delivers cutting-edge performance across all three tasks on five benchmarks.
- No task-specific human annotations are required, only the initial multi-source contrastive dataset.
- The reranking step adds only minimal computational overhead while producing more accurate final rankings.
- The approach generalizes across both image and video modalities under the shared composition paradigm.
Where Pith is reading between the lines
- The method could be tested on additional compositional tasks such as audio or 3D scene retrieval by swapping the gallery encoder.
- Reducing the size of the 3.5M alignment dataset while preserving transfer might be possible through more targeted negative sampling.
- The dual-level reranking signals could be fed back into further fine-tuning of the embedder for iterative improvement.
- This unification highlights that the bottleneck in these tasks is query composition rather than modality-specific retrieval mechanics.
Load-bearing premise
That contrastive alignment of the MLLM on the curated 3.5 million sample dataset produces embeddings that transfer zero-shot to all three tasks and that the subsequent dual-level reranking reliably improves rankings at low cost.
What would settle it
A benchmark run in which the single unified model fails to match or exceed the accuracy of separate task-specific baselines on any of the five standard test sets for composed image retrieval, multi-turn retrieval, or composed video retrieval.
Figures







read the original abstract
Composed image retrieval, multi-turn composed image retrieval, and composed video retrieval all share a common paradigm: composing the reference visual with modification text to retrieve the desired target. Despite this shared structure, the three tasks have been studied in isolation, with no prior work proposing a unified framework, let alone a zero-shot solution. In this paper, we propose UniCVR, the first unified zero-shot composed visual retrieval framework that jointly addresses all three tasks without any task-specific human-annotated data. UniCVR strategically combines two complementary strengths: Multimodal Large Language Models (MLLMs) for compositional query understanding and Vision-Language Pre-trained (VLP) models for structured visual retrieval. Concretely, UniCVR operates in two stages. In Stage I, we train the MLLM as a compositional query embedder via contrastive learning on a curated multi-source dataset of approximately 3.5M samples, bridging the heterogeneous embedding spaces between the MLLM and the frozen VLP gallery encoder. A cluster-based hard negative sampling strategy is proposed to strengthen contrastive supervision. In Stage II, we introduce an MLLM-guided dual-level reranking mechanism that applies adaptive budgeted subset scoring to a small number of top-ranked candidates, and then exploits the resulting relevance signals through a dual-level re-scoring scheme, producing more accurate final rankings with minimal computational overhead. Extensive experiments across five benchmarks covering all three tasks demonstrate that UniCVR achieves cutting-edge performance, validating its effectiveness and generalizability. Our data and code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UniCVR, the first unified zero-shot framework for composed visual retrieval that jointly handles composed image retrieval (CIR), multi-turn CIR, and composed video retrieval (CVR) without task-specific human-annotated data. It employs a two-stage pipeline: Stage I aligns an MLLM as a compositional query embedder to a frozen VLP gallery encoder via contrastive learning on a curated ~3.5M multi-source dataset with cluster-based hard-negative sampling; Stage II applies an MLLM-guided dual-level reranking mechanism using adaptive budgeted subset scoring on top candidates followed by dual-level re-scoring. The paper reports extensive experiments on five benchmarks spanning the three tasks and claims cutting-edge performance.
Significance. If the zero-shot transfer from image-centric contrastive alignment to video and multi-turn tasks is substantiated, the work would be significant as the first unified framework that eliminates the need for per-task annotations and data curation. The combination of MLLM compositional understanding with efficient VLP retrieval plus low-overhead reranking offers a practical advance; the release of data and code would further strengthen reproducibility.
major comments (3)
- [Stage I data curation] Data curation description (method section on Stage I): The 3.5M-sample multi-source dataset is described at a high level with no breakdown of video clips, multi-turn dialogues, or their proportions. Since contrastive alignment occurs exclusively on this dataset, the zero-shot claim for CVR and multi-turn CIR requires explicit confirmation that temporal or iterative structure is either present or unnecessary for transfer.
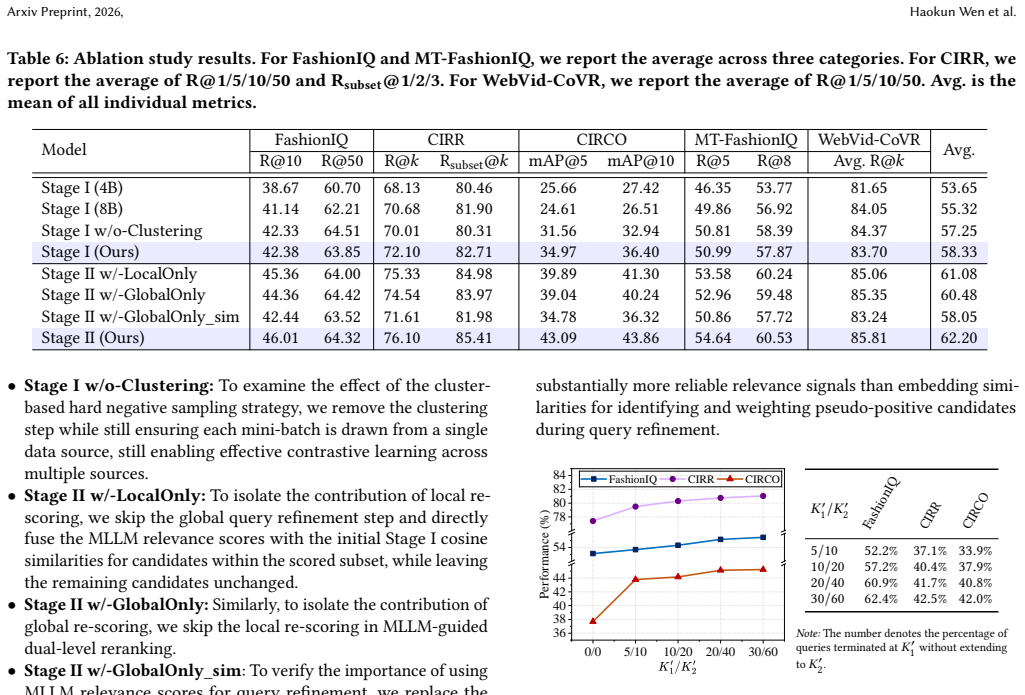
- [Experiments across five benchmarks] Experiments and ablations (results section): No ablation isolating Stage I embedding quality on the video benchmarks is reported, nor is there error analysis or quantitative results in the abstract. Without these, it is impossible to verify that the unified zero-shot transfer succeeds before reranking is applied, which is load-bearing for the central claim.
- [Stage I contrastive learning] Hard-negative sampling (Stage I method): The cluster-based hard-negative strategy is introduced to strengthen supervision, but implementation details (cluster formation, selection criteria, and comparison to standard in-batch or mined negatives) remain high-level. This affects reproducibility and the claimed strengthening of contrastive alignment.
minor comments (2)
- [Abstract] The abstract states performance claims without any numerical results, ablation summaries, or dataset statistics; adding a concise quantitative highlight would improve readability.
- [Stage II reranking] Notation for the dual-level reranking (Stage II) could be clarified with an equation or pseudocode to distinguish the subset scoring from the final re-scoring step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point-by-point below, proposing specific revisions to improve clarity, reproducibility, and validation of our claims.
read point-by-point responses
-
Referee: [Stage I data curation] Data curation description (method section on Stage I): The 3.5M-sample multi-source dataset is described at a high level with no breakdown of video clips, multi-turn dialogues, or their proportions. Since contrastive alignment occurs exclusively on this dataset, the zero-shot claim for CVR and multi-turn CIR requires explicit confirmation that temporal or iterative structure is either present or unnecessary for transfer.
Authors: We appreciate this observation. The curated dataset consists exclusively of image-text pairs drawn from multiple existing composed image retrieval sources and related resources; it contains no video clips or multi-turn dialogues. This is by design, as Stage I focuses on aligning compositional query understanding in the MLLM with the frozen VLP space. The MLLM's pre-trained multimodal reasoning enables zero-shot generalization to temporal and iterative structures without explicit exposure during alignment. In the revision we will add a detailed breakdown of data sources and proportions to Section 3.1, together with a concise discussion of the transfer mechanism. revision: yes
-
Referee: [Experiments across five benchmarks] Experiments and ablations (results section): No ablation isolating Stage I embedding quality on the video benchmarks is reported, nor is there error analysis or quantitative results in the abstract. Without these, it is impossible to verify that the unified zero-shot transfer succeeds before reranking is applied, which is load-bearing for the central claim.
Authors: We agree that isolating Stage I performance is essential to substantiate the zero-shot transfer. In the revised manuscript we will add an ablation that reports retrieval metrics using only the Stage I embeddings (i.e., without reranking) on the composed video retrieval benchmarks. We will also incorporate a dedicated error analysis subsection in the results and include key quantitative highlights in the abstract to better support the central claim. revision: yes
-
Referee: [Stage I contrastive learning] Hard-negative sampling (Stage I method): The cluster-based hard-negative strategy is introduced to strengthen supervision, but implementation details (cluster formation, selection criteria, and comparison to standard in-batch or mined negatives) remain high-level. This affects reproducibility and the claimed strengthening of contrastive alignment.
Authors: We acknowledge that additional implementation details are required for reproducibility. We will expand the description in Section 3.2 to specify cluster formation (k-means on gallery embeddings), selection criteria (top-k hardest negatives within the same cluster, excluding the positive), and direct comparisons against in-batch negatives and standard mining strategies, supported by new ablation results. revision: yes
Circularity Check
No circularity: empirical alignment and reranking rest on external data and frozen models
full rationale
The paper presents an empirical two-stage pipeline: contrastive training of an MLLM embedder on a 3.5M-sample curated multi-source dataset (Stage I) followed by MLLM-guided dual-level reranking on top candidates (Stage II). No equations, first-principles derivations, or predictions are offered that reduce by construction to fitted parameters or self-referential definitions. The zero-shot transfer claim is validated experimentally across five benchmarks rather than derived from any internal loop. No self-citations are invoked as load-bearing uniqueness theorems, and the method uses frozen VLP encoders and external data, keeping the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Contrastive learning on a mixed multi-source dataset produces transferable compositional embeddings.
- domain assumption MLLM can provide reliable relevance signals for reranking a small candidate set.
Reference graph
Works this paper leans on
-
[1]
Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S
Xintong Han, Zuxuan Wu, Phoenix X. Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S. Davis. Automatic spatially-aware fashion concept discovery. In Proceedings of the IEEE International Conference on Computer Vision, , pages 1472--1480. IEEE , 2017
2017
-
[2]
Fire: Enhancing mllms with fine-grained context learning for complex image retrieval
Bohan Hou, Haoqiang Lin, Xuemeng Song, Haokun Wen, Meng Liu, Yupeng Hu, and Xiangyu Zhao. Fire: Enhancing mllms with fine-grained context learning for complex image retrieval. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval , pages 803--812. ACM , 2025
2025
-
[3]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning , pages 12888--12900. PMLR , 2022
2022
-
[4]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems , pages 34892--34916. Curran Associates, Inc., 2023
2023
-
[5]
Frangi, and Jing - Yu Yang
Jian Yang, David Zhang, Alejandro F. Frangi, and Jing - Yu Yang. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence , 26(1):131--137, 2004
2004
-
[6]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 26125--26135. Computer Vision Foundation / IEEE , 2025
2025
-
[7]
Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
Xiaomin Yu, Yi Xin, Wenjie Zhang, Chonghan Liu, Hanzhen Zhao, Xiaoxing Hu, Xinlei Yu, Ziyue Qiao, Hao Tang, Xue Yang, Xiaobin Hu, Chengwei Qin, Hui Xiong, Yu Qiao, and Shuicheng Yan. Modality gap-driven subspace alignment training paradigm for multimodal large language models. CoRR , abs/2602.07026, 2026
work page internal anchor Pith review arXiv 2026
-
[8]
Proceedings of the
Alberto Baldrati and Lorenzo Agnolucci and Marco Bertini and Alberto Del Bimbo , title =. Proceedings of the
-
[9]
Lorenzo Agnolucci and Alberto Baldrati and Alberto Del Bimbo and Marco Bertini , title =
-
[10]
Proceedings of the International
Haoqiang Lin and Haokun Wen and Xuemeng Song and Meng Liu and Yupeng Hu and Liqiang Nie , title =. Proceedings of the International
-
[11]
Proceedings of the
Yucheng Suo and Fan Ma and Linchao Zhu and Yi Yang , title =. Proceedings of the
-
[12]
Proceedings of the
Geonmo Gu and Sanghyuk Chun and Wonjae Kim and Yoohoon Kang and Sangdoo Yun , title =. Proceedings of the
-
[13]
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions , booktitle =
Kai Zhang and Yi Luan and Hexiang Hu and Kenton Lee and Siyuan Qiao and Wenhu Chen and Yu Su and Ming. MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions , booktitle =
-
[14]
Transactions on Machine Learning Research , volume =
Geonmo Gu and Sanghyuk Chun and Wonjae Kim and HeeJae Jun and Yoohoon Kang and Sangdoo Yun , title =. Transactions on Machine Learning Research , volume =
-
[15]
Proceedings of the International
Zhenyu Yang and Dizhan Xue and Shengsheng Qian and Weiming Dong and Changsheng Xu , title =. Proceedings of the International
-
[16]
Proceedings of the
Zhenyu Yang and Shengsheng Qian and Dizhan Xue and Jiahong Wu and Fan Yang and Weiming Dong and Changsheng Xu , title =. Proceedings of the
-
[17]
Proceedings of the
Yuanmin Tang and Jue Zhang and Xiaoting Qin and Jing Yu and Gaopeng Gou and Gang Xiong and Qingwei Lin and Saravan Rajmohan and Dongmei Zhang and Qi Wu , title =. Proceedings of the
-
[18]
Proceedings of the International
Bohan Hou and Haoqiang Lin and Xuemeng Song and Haokun Wen and Meng Liu and Yupeng Hu and Xiangyu Zhao , title =. Proceedings of the International
-
[19]
Proceedings of the International
Zhe Li and Lei Zhang and Kun Zhang and Weidong Chen and Yongdong Zhang and Zhendong Mao , title =. Proceedings of the International
-
[20]
Proceedings of the International Conference on Learning Representations , publisher =
Shyamgopal Karthik and Karsten Roth and Massimiliano Mancini and Zeynep Akata , title =. Proceedings of the International Conference on Learning Representations , publisher =
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
CoTMR: chain-of-thought multi-scale reasoning for training-free zero-shot composed image retrieval , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=. 2025 , publisher =
2025
-
[22]
Proceedings of the
Zhangtao Cheng and Yuhao Ma and Jian Lang and Kunpeng Zhang and Ting Zhong and Yong Wang and Fan Zhou , title =. Proceedings of the
-
[23]
Proceedings of the International
Yifei Yuan and Wai Lam , title =. Proceedings of the International
-
[24]
Christensen , title =
Anwesan Pal and Sahil Wadhwa and Ayush Jaiswal and Xu Zhang and Yue Wu and Rakesh Chada and Pradeep Natarajan and Henrik I. Christensen , title =. Proceedings of the
-
[25]
Dialog-based Interactive Image Retrieval , booktitle =
Xiaoxiao Guo and Hui Wu and Yu Cheng and Steven Rennie and Gerald Tesauro and Rog. Dialog-based Interactive Image Retrieval , booktitle =
-
[26]
Proceedings of the
Hao Wei and Shuhui Wang and Zhe Xue and Shengbo Chen and Qingming Huang , title =. Proceedings of the
-
[27]
CoVR: Learning Composed Video Retrieval from Web Video Captions , booktitle =
Lucas Ventura and Antoine Yang and Cordelia Schmid and G. CoVR: Learning Composed Video Retrieval from Web Video Captions , booktitle =
-
[28]
Khan and Michael Felsberg and Mubarak Shah and Fahad Shahbaz Khan , title =
Omkar Thawakar and Muzammal Naseer and Rao Muhammad Anwer and Salman H. Khan and Michael Felsberg and Mubarak Shah and Fahad Shahbaz Khan , title =. Proceedings of the
-
[29]
CoVR-2: Automatic Data Construction for Composed Video Retrieval , journal =
Lucas Ventura and Antoine Yang and Cordelia Schmid and G. CoVR-2: Automatic Data Construction for Composed Video Retrieval , journal =
-
[30]
Proceedings of the International Conference on Learning Representations , publisher =
Yue Wu and Zhaobo Qi and Yiling Wu and Junshu Sun and Yaowei Wang and Shuhui Wang , title =. Proceedings of the International Conference on Learning Representations , publisher =
-
[31]
Proceedings of the
Zhiwei Chen and Yupeng Hu and Zixu Li and Zhiheng Fu and Haokun Wen and Weili Guan , title =. Proceedings of the
-
[32]
Proceedings of the
Haokun Wen and Xian Zhang and Xuemeng Song and Yinwei Wei and Liqiang Nie , title =. Proceedings of the
-
[33]
Proceedings of the
Zhiwei Chen and Yupeng Hu and Zixu Li and Zhiheng Fu and Xuemeng Song and Liqiang Nie , title =. Proceedings of the
-
[34]
ACM Transactions on Information Systems , volume =
Xuemeng Song and Haoqiang Lin and Haokun Wen and Bohan Hou and Mingzhu Xu and Liqiang Nie , title =. ACM Transactions on Information Systems , volume =
-
[35]
Haokun Wen and Xuemeng Song and Jianhua Yin and Jianlong Wu and Weili Guan and Liqiang Nie , title =
-
[36]
Mm-Embed: Universal Multimodal Retrieval with Multimodal
Sheng. Mm-Embed: Universal Multimodal Retrieval with Multimodal. Proceedings of the International Conference on Learning Representations , pages =
-
[37]
Proceedings of the Conference on Artificial Intelligence , pages =
Huang, Weiquan and Wu, Aoqi and Yang, Yifan and Luo, Xufang and Yang, Yuqing and Naseem, Usman and Wang, Chunyu and Dai, Qi and Dai, Xiyang and Chen, Dongdong and Luo, Chong and Qiu, Lili and Hu, Liang , title =. Proceedings of the Conference on Artificial Intelligence , pages =
-
[38]
Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval , booktitle =
Kuniaki Saito and Kihyuk Sohn and Xiang Zhang and Chun. Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval , booktitle =
-
[39]
Proceedings of the International Conference on Machine Learning , pages =
Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever , title =. Proceedings of the International Conference on Machine Learning , pages =
-
[40]
Proceedings of the International Conference on Learning Representations , publisher =
Ziyan Jiang and Rui Meng and Xinyi Yang and Semih Yavuz and Yingbo Zhou and Wenhu Chen , title =. Proceedings of the International Conference on Learning Representations , publisher =
-
[41]
Bach , title =
Reza Esfandiarpoor and Cristina Menghini and Stephen H. Bach , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages =
-
[42]
Perception Encoder: The best visual embeddings are not at the output of the network , journal =
Daniel Bolya and Po. Perception Encoder: The best visual embeddings are not at the output of the network , journal =
-
[43]
CoRR , volume =
Qwen Team , title =. CoRR , volume =
-
[44]
Kankanhalli , title =
Wei Li and Hehe Fan and Yongkang Wong and Yi Yang and Mohan S. Kankanhalli , title =. Proceedings of the International Conference on Machine Learning , pages =
-
[45]
Transfer between Modalities with MetaQueries , journal =
Xichen Pan and Satya Narayan Shukla and Aashu Singh and Zhuokai Zhao and Shlok Kumar Mishra and Jialiang Wang and Zhiyang Xu and Jiuhai Chen and Kunpeng Li and Felix Juefei. Transfer between Modalities with MetaQueries , journal =
-
[46]
Proceedings of the
Qifan Yu and Wei Chow and Zhongqi Yue and Kaihang Pan and Yang Wu and Xiaoyang Wan and Juncheng Li and Siliang Tang and Hanwang Zhang and Yueting Zhuang , title =. Proceedings of the
-
[47]
Advances in Neural Information Processing Systems , year =
Haotian Liu and Chunyuan Li and Qingyang Wu and Yong Jae Lee , title =. Advances in Neural Information Processing Systems , year =
-
[48]
Huang and Xiao Zhang and Menglong Zhu and Yuan Li and Yang Zhao and Larry S
Xintong Han and Zuxuan Wu and Phoenix X. Huang and Xiao Zhang and Menglong Zhu and Yuan Li and Yang Zhao and Larry S. Davis , title =. Proceedings of the
-
[49]
CoRR , volume =
Xiaomin Yu and Yi Xin and Wenjie Zhang and Chonghan Liu and Hanzhen Zhao and Xiaoxing Hu and Xinlei Yu and Ziyue Qiao and Hao Tang and Xue Yang and Xiaobin Hu and Chengwei Qin and Hui Xiong and Yu Qiao and Shuicheng Yan , title =. CoRR , volume =
-
[50]
Proceedings of the
Sophia Gu and Christopher Clark and Aniruddha Kembhavi , title =. Proceedings of the
-
[51]
ImageNet:
Jia Deng and Wei Dong and Richard Socher and Li. ImageNet:. Proceedings of the
-
[52]
Proceedings of the International Conference on Learning Representations , publisher =
Cong Wei and Zheyang Xiong and Weiming Ren and Xeron Du and Ge Zhang and Wenhu Chen , title =. Proceedings of the International Conference on Learning Representations , publisher =
-
[53]
Efros , title =
Tim Brooks and Aleksander Holynski and Alexei A. Efros , title =. Proceedings of the
-
[54]
Proceedings of the Berkeley Symposium on Mathematical statistics and Probability , pages=
Some methods of classification and analysis of multivariate observations , author=. Proceedings of the Berkeley Symposium on Mathematical statistics and Probability , pages=
-
[55]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =
-
[56]
Proceedings of the
Yikun Liu and Yajie Zhang and Jiayin Cai and Xiaolong Jiang and Yao Hu and Jiangchao Yao and Yanfeng Wang and Weidi Xie , title =. Proceedings of the
-
[57]
Proceedings of the
Xia Li and Wengang Zhou and Jinhui Tang and Qi Tian , title =. Proceedings of the
-
[58]
Query expansion by spatial co-occurrence for image retrieval , booktitle =
Yingfei Li and Bo Geng and Zheng. Query expansion by spatial co-occurrence for image retrieval , booktitle =
-
[59]
Hui Wu and Yupeng Gao and Xiaoxiao Guo and Ziad Al. Fashion. Proceedings of the
-
[60]
Proceedings of the
Zheyuan Liu and Cristian Rodriguez Opazo and Damien Teney and Stephen Gould , title =. Proceedings of the
-
[61]
Proceedings of the International Conference on Learning Representations , publisher =
Ilya Loshchilov and Frank Hutter , title =. Proceedings of the International Conference on Learning Representations , publisher =
-
[62]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages =
Weiwei Sun and Lingyong Yan and Xinyu Ma and Shuaiqiang Wang and Pengjie Ren and Zhumin Chen and Dawei Yin and Zhaochun Ren , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages =
-
[64]
Findings of the Association for Computational Linguistics , pages =
Zhen Qin and Rolf Jagerman and Kai Hui and Honglei Zhuang and Junru Wu and Le Yan and Jiaming Shen and Tianqi Liu and Jialu Liu and Donald Metzler and Xuanhui Wang and Michael Bendersky , title =. Findings of the Association for Computational Linguistics , pages =
-
[65]
Proceedings of the International
Xueguang Ma and Liang Wang and Nan Yang and Furu Wei and Jimmy Lin , title =. Proceedings of the International
-
[66]
Proceedings of the Workshop on Representation Learning for NLP , pages =
Luyu Gao and Yunyi Zhang and Jiawei Han and Jamie Callan , title =. Proceedings of the Workshop on Representation Learning for NLP , pages =
-
[67]
Junnan Li and Dongxu Li and Caiming Xiong and Steven C. H. Hoi , title =. Proceedings of the International Conference on Machine Learning , pages =
-
[68]
Frangi and Jing
Jian Yang and David Zhang and Alejandro F. Frangi and Jing. Two-Dimensional. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.