Recognition: unknown
Distributional Value Estimation Without Target Networks for Robust Quality-Diversity
Pith reviewed 2026-05-10 00:07 UTC · model grok-4.3
The pith
Target-free distributional critics enable stable high-UTD training in quality-diversity reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QDHUAC is a sample-efficient, target-free and distributional QD-RL algorithm that provides dense and low-variance gradient signals, which enables high-UTD training for Dominated Novelty Search whilst requiring an order of magnitude fewer environment steps. We demonstrate that our method enables stable training at high UTD ratios, achieving competitive coverage and fitness on high-dimensional Brax environments with an order of magnitude fewer samples than baselines.
What carries the argument
Target-free distributional critic paired with Dominated Novelty Search, supplying stable low-variance gradients for high-UTD actor-critic updates across the QD population.
Load-bearing premise
Distributional value estimation without target networks supplies sufficiently stable and low-variance gradients to support high-UTD training inside Dominated Novelty Search without introducing instability or bias in the QD population.
What would settle it
Observing gradient instability, training divergence, or substantially lower QD coverage and fitness when the target-free distributional critic is used at high UTD ratios on the same Brax environments.
Figures


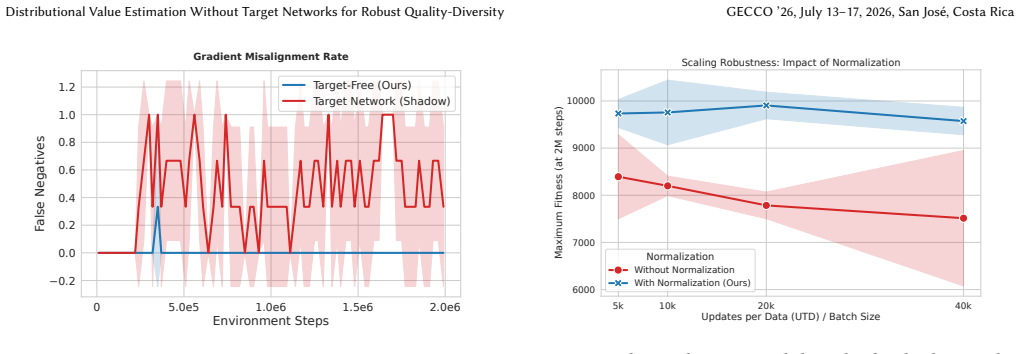


read the original abstract
Quality-Diversity (QD) algorithms excel at discovering diverse repertoires of skills, but are hindered by poor sample efficiency and often require tens of millions of environment steps to solve complex locomotion tasks. Recent advances in Reinforcement Learning (RL) have shown that high Update-to-Data (UTD) ratios accelerate Actor-Critic learning. While effective, standard high-UTD algorithms typically utilise target networks to stabilise training. This requirement introduces a significant computational bottleneck, rendering them impractical for resource-intensive Quality-Diversity (QD) tasks where sample efficiency and rapid population adaptation are critical. In this paper, we introduce QDHUAC, a sample-efficient, target-free and distributional QD-RL algorithm that provides dense and low-variance gradient signals, which enables high-UTD training for Dominated Novelty Search whilst requiring an order of magnitude fewer environment steps. We demonstrate that our method enables stable training at high UTD ratios, achieving competitive coverage and fitness on high-dimensional Brax environments with an order of magnitude fewer samples than baselines. Our results suggest that combining target-free distributional critics with dominance-based selection is a key enabler for the next generation of sample-efficient evolutionary RL algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QDHUAC, a target-free distributional Quality-Diversity RL algorithm that combines distributional value estimation with Dominated Novelty Search to enable stable high-UTD training. It claims this yields competitive coverage and fitness on high-dimensional Brax environments using an order of magnitude fewer environment steps than baselines, with the combination of target-free distributional critics and dominance-based selection as the key enabler.
Significance. If the results hold after proper validation, the approach could improve sample efficiency in QD-RL by removing target network overhead and supporting higher UTD ratios, with potential to scale evolutionary RL methods. The work highlights a promising direction for robust gradient signals in population-based algorithms, but the attribution to distributional estimation specifically requires stronger evidence.
major comments (2)
- [Experimental Results / Ablation Studies] The central claim that distributional value estimation without target networks supplies sufficiently stable and low-variance gradients for high-UTD training inside Dominated Novelty Search is load-bearing, yet no ablation is described that isolates this component (e.g., standard TD critic without targets at identical UTD ratios under the same dominance selection). Dominated Novelty Search's Pareto filtering may itself reduce effective variance, undermining the headline attribution.
- [Abstract and §4 (Experiments)] The abstract asserts empirical success on Brax tasks with specific performance gains, but the manuscript supplies no experimental details, baseline descriptions, statistical tests, ablation results, or hyperparameter settings for the high-UTD regime. This prevents verification of the stability claim and the 'order of magnitude fewer samples' result.
minor comments (2)
- [Method Description] Clarify the exact UTD ratios tested and how they compare to prior high-UTD RL methods that rely on targets.
- [§3 (Algorithm)] The notation for the distributional critic and dominance-based selection could be made more explicit with pseudocode or equations to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address the major comments point by point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that distributional value estimation without target networks supplies sufficiently stable and low-variance gradients for high-UTD training inside Dominated Novelty Search is load-bearing, yet no ablation is described that isolates this component (e.g., standard TD critic without targets at identical UTD ratios under the same dominance selection). Dominated Novelty Search's Pareto filtering may itself reduce effective variance, undermining the headline attribution.
Authors: We agree that an ablation isolating the distributional critic from a standard TD critic (both without target networks) at identical high UTD ratios and under the same Dominated Novelty Search selection would provide stronger evidence for the specific contribution of distributional estimation. While the current results demonstrate stable high-UTD training with the integrated method, we will add this ablation study in the revised manuscript to directly address the potential confounding role of Pareto filtering and to clarify the source of gradient stability. revision: yes
-
Referee: The abstract asserts empirical success on Brax tasks with specific performance gains, but the manuscript supplies no experimental details, baseline descriptions, statistical tests, ablation results, or hyperparameter settings for the high-UTD regime. This prevents verification of the stability claim and the 'order of magnitude fewer samples' result.
Authors: We acknowledge that the experimental section would benefit from greater detail to support reproducibility and verification of the claims. The manuscript contains baseline descriptions and high-level experimental setup in Section 4, but we will expand it to include full hyperparameter tables for the high-UTD regime, statistical reporting (means and standard deviations across multiple seeds), additional ablation results, and explicit environment-step comparisons that substantiate the reported sample-efficiency gains. revision: yes
Circularity Check
No circularity: empirical algorithmic proposal without self-referential derivations
full rationale
The paper presents QDHUAC as a novel combination of target-free distributional critics and Dominated Novelty Search to enable high-UTD training. No equations, parameter fittings, uniqueness theorems, or derivation chains are described that reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. Claims rest on empirical results for coverage and fitness on Brax environments rather than any closed-loop mathematical reduction. This is a standard non-circular presentation of an algorithmic method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ryan Bahlous-Boldi, Maxence Faldor, Luca Grillotti, Hannah Janmohamed, Lisa Coiffard, Lee Spector, and Antoine Cully. 2025. Dominated novelty search: Rethinking local competition in quality-diversity. InProceedings of the Genetic and Evolutionary Computation Conference. 104–112
2025
-
[2]
David Balduzzi, Marcus Frean, Lennox Leary, JP Lewis, Kurt Wan-Duo Ma, and Brian McWilliams. 2017. The shattered gradients problem: If resnets are the answer, then what is the question?. InInternational conference on machine learning. PMLR, 342–350
2017
-
[3]
Marc G Bellemare, Will Dabney, and Rémi Munos. 2017. A distributional perspec- tive on reinforcement learning. InInternational conference on machine learning. PMLR, 449–458
2017
-
[4]
2023.Distributional rein- forcement learning
Marc G Bellemare, Will Dabney, and Mark Rowland. 2023.Distributional rein- forcement learning. MIT Press
2023
- [5]
-
[6]
Felix Chalumeau, Bryan Lim, Raphael Boige, Maxime Allard, Luca Grillotti, Manon Flageat, Valentin Macé, Guillaume Richard, Arthur Flajolet, Thomas Pierrot, et al. 2024. QDax: A library for quality-diversity and population-based algorithms with hardware acceleration.Journal of Machine Learning Research25, 108 (2024), 1–16
2024
- [7]
- [8]
-
[9]
Will Dabney, Mark Rowland, Marc Bellemare, and Rémi Munos. 2018. Distri- butional reinforcement learning with quantile regression. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[10]
Pierluca D’Oro, Max Schwarzer, Evgenii Nikishin, Pierre-Luc Bacon, Marc G Bellemare, and Aaron Courville. 2022. Sample-efficient reinforcement learning by breaking the replay ratio barrier. InDeep Reinforcement Learning Workshop NeurIPS 2022
2022
- [11]
-
[12]
Jesse Farebrother, Jordi Orbay, Quan Vuong, Adrien Ali Taïga, Yevgen Chebotar, Ted Xiao, Alex Irpan, Sergey Levine, Pablo Samuel Castro, Aleksandra Faust, et al
- [13]
-
[14]
William Fedus, Prajit Ramachandran, Rishabh Agarwal, Yoshua Bengio, Hugo Larochelle, Mark Rowland, and Will Dabney. 2020. Revisiting fundamentals of experience replay. InInternational conference on machine learning. PMLR, 3061–3071
2020
- [15]
-
[16]
Scott Fujimoto, Herke Hoof, and David Meger. 2018. Addressing function ap- proximation error in actor-critic methods. InInternational conference on machine learning. PMLR, 1587–1596
2018
-
[17]
Florin Gogianu, Tudor Berariu, Mihaela C Rosca, Claudia Clopath, Lucian Buso- niu, and Razvan Pascanu. 2021. Spectral normalisation for deep reinforcement learning: an optimisation perspective. InInternational Conference on Machine Learning. PMLR, 3734–3744
2021
-
[18]
Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. 2017. Improved training of wasserstein gans.Advances in neural information processing systems30 (2017)
2017
-
[19]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning. Pmlr, 1861–1870
2018
-
[20]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Identity mappings in deep residual networks. InEuropean conference on computer vision. Springer, 630–645
2016
-
[21]
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostro- vski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver
-
[22]
In Proceedings of the AAAI conference on artificial intelligence, Vol
Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32
- [23]
- [24]
-
[25]
Sergey Ioffe. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift.arXiv preprint arXiv:1502.03167(2015)
work page internal anchor Pith review arXiv 2015
-
[26]
Hannah Janmohamed and Antoine Cully. 2025. Multi-objective quality-diversity in unstructured and unbounded spaces. InProceedings of the Genetic and Evolu- tionary Computation Conference. 149–157
2025
-
[27]
Bryan Lim, Manon Flageat, and Antoine Cully. 2023. Understanding the synergies between quality-diversity and deep reinforcement learning. InProceedings of the Genetic and Evolutionary Computation Conference. 1212–1220
2023
-
[28]
Clare Lyle, Marc G Bellemare, and Pablo Samuel Castro. 2019. A comparative analysis of expected and distributional reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 4504–4511
2019
- [29]
-
[30]
Jean-Baptiste Mouret and Jeff Clune. 2015. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909(2015)
work page Pith review arXiv 2015
-
[31]
Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miłoś, and Marek Cygan. 2024. Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control.Advances in neural information processing systems37 (2024), 113038–113071
2024
-
[32]
Evgenii Nikishin, Max Schwarzer, Pierluca D’Oro, Pierre-Luc Bacon, and Aaron Courville. 2022. The primacy bias in deep reinforcement learning. InInternational conference on machine learning. PMLR, 16828–16847
2022
-
[33]
Olle Nilsson and Antoine Cully. 2021. Policy gradient assisted map-elites. In Proceedings of the Genetic and Evolutionary Computation Conference. 866–875
2021
-
[34]
Eleni Nisioti, Erwan Plantec, Milton Montero, Joachim Pedersen, and Sebastian Risi. 2025. When Does Neuroevolution Outcompete Reinforcement Learning in Transfer Learning Tasks?. InProceedings of the Genetic and Evolutionary Compu- tation Conference. 48–57
2025
-
[35]
Thomas Pierrot, Valentin Macé, Felix Chalumeau, Arthur Flajolet, Geoffrey Cideron, Karim Beguir, Antoine Cully, Olivier Sigaud, and Nicolas Perrin-Gilbert
-
[36]
InProceedings of the Genetic and Evolutionary Computation Conference
Diversity policy gradient for sample efficient quality-diversity optimiza- tion. InProceedings of the Genetic and Evolutionary Computation Conference. 1075–1083
-
[37]
Justin K Pugh, Lisa B Soros, and Kenneth O Stanley. 2016. Quality diversity: A new frontier for evolutionary computation.Frontiers in Robotics and AI3 (2016), 40
2016
-
[38]
Carlo Romeo, Girolamo Macaluso, Alessandro Sestini, and Andrew D Bagdanov
- [39]
-
[40]
Tim Salimans and Durk P Kingma. 2016. Weight normalization: A simple repa- rameterization to accelerate training of deep neural networks.Advances in neural information processing systems29 (2016)
2016
-
[41]
Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. 2018. How does batch normalization help optimization?Advances in neural information processing systems31 (2018)
2018
- [42]
-
[43]
Max Schwarzer, Johan Samir Obando Ceron, Aaron Courville, Marc G Bellemare, Rishabh Agarwal, and Pablo Samuel Castro. 2023. Bigger, better, faster: Human- level atari with human-level efficiency. InInternational Conference on Machine Learning. PMLR, 30365–30380
2023
-
[44]
Samarth Sinha, Homanga Bharadhwaj, Aravind Srinivas, and Animesh Garg
- [45]
-
[46]
Chen Tessler, Guy Tennenholtz, and Shie Mannor. 2019. Distributional policy optimization: An alternative approach for continuous control.Advances in Neural Information Processing Systems32 (2019)
2019
-
[47]
Vassilis Vassiliades, Konstantinos Chatzilygeroudis, and Jean-Baptiste Mouret
-
[48]
Using centroidal voronoi tessellations to scale up the multidimensional archive of phenotypic elites algorithm.IEEE Transactions on Evolutionary Com- putation22, 4 (2017), 623–630
2017
-
[49]
Ke Xue, Ren-Jian Wang, Pengyi Li, Dong Li, Jianye Hao, and Chao Qian. 2024. Sample-efficient quality-diversity by cooperative coevolution. InThe Twelfth International Conference on Learning Representations. GECCO ’26, July 13–17, 2026, San José, Costa Rica Koohy et al. Appendix 6.1 Hyperparameters for QDHUAC Table 1:Hyperparameters for QDHUAC. We separate...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.