Recognition: unknown
CyberCertBench: Evaluating LLMs in Cybersecurity Certification Knowledge
Pith reviewed 2026-05-10 00:28 UTC · model grok-4.3
The pith
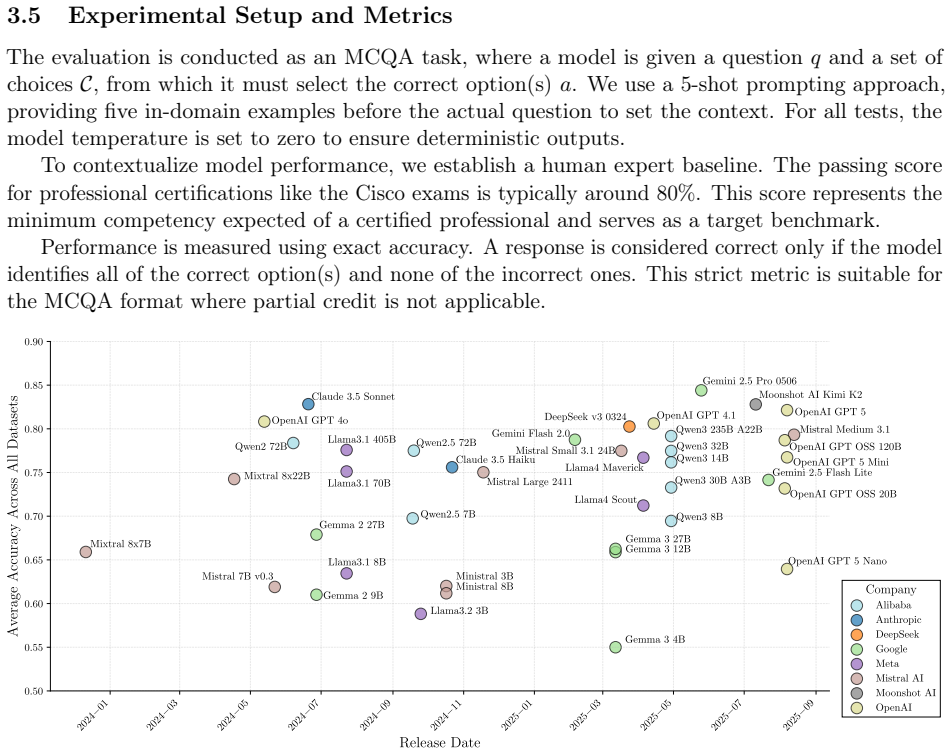
Frontier LLMs perform at human expert level on general IT security certifications but decline on vendor-specific and formal standards questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CyberCertBench is a new suite of MCQA benchmarks derived from industry-recognized certifications in information technology cybersecurity and operational technology security. Evaluation using this benchmark shows that frontier models achieve human expert level in general networking and IT security knowledge, but their accuracy declines in questions that require vendor-specific nuances or knowledge in formal standards like IEC 62443. A Proposer-Verifier framework is proposed to generate interpretable natural language explanations for model performance, and analysis shows gains in parameter efficiency with diminishing returns in recent larger models.
What carries the argument
CyberCertBench, the suite of multiple-choice questions extracted from professional cybersecurity certifications, serves as the evaluation tool to measure LLM domain knowledge against industry standards; the Proposer-Verifier framework generates explanations of model outputs.
If this is right
- Models can be trusted for general cybersecurity advice but require verification on specialized standards.
- Recent model releases show improved efficiency per parameter but limited gains from further scaling.
- The benchmark provides a standardized way to track progress in domain-specific LLM capabilities.
- Developers can use the results to prioritize training on vendor-specific and standards-based content.
Where Pith is reading between the lines
- Expanding the benchmark to include more certifications could create a comprehensive test suite for professional domains.
- If LLMs continue to improve on these questions, they might eventually be used to assist in preparing for or even taking certification exams.
- Real-world application would still need testing beyond exam-style questions to confirm practical utility.
Load-bearing premise
That the questions from existing professional certifications form a valid and comprehensive proxy for the domain knowledge LLMs need in actual cybersecurity practice.
What would settle it
A direct comparison where human cybersecurity experts score significantly higher or lower than the reported model accuracies on the same set of certification questions would challenge the claim of human-expert level performance.
Figures




read the original abstract
The rapid evolution and use of Large Language Models (LLMs) in professional workflows require an evaluation of their domain-specific knowledge against industry standards. We introduceCyberCertBench, a new suite of Multiple Choice Question Answering (MCQA) benchmarks derived from industry recognized certifications. CyberCertBench evaluates LLM domain knowledgeagainst the professional standards of Information Technology cybersecurity and more specializedareas such as Operational Technology and related cybersecurity standards. Concurrently, we propose and validate a novel Proposer-Verifier framework, a methodology to generate interpretable,natural language explanations for model performance. Our evaluation shows that frontier modelsachieve human expert level in general networking and IT security knowledge. However, theiraccuracy declines in questions that require vendor-specific nuances or knowledge in formalstandards, like, e.g., IEC 62443. Analysis of model scaling trend and release date demonstratesremarkable gains in parameter efficiency, while recent larger models show diminishing returns.Code and evaluation scripts are available at: https://github.com/GKeppler/CyberCertBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CyberCertBench, a suite of MCQA benchmarks extracted from industry cybersecurity certifications spanning general IT security, networking, operational technology, and standards such as IEC 62443. It proposes a Proposer-Verifier framework to generate natural-language explanations for model outputs and evaluates several frontier LLMs, claiming they reach human-expert performance on general topics while showing accuracy drops on vendor-specific and formal-standards questions. The work also reports scaling trends indicating improved parameter efficiency with diminishing returns for the largest recent models and releases code and scripts for reproducibility.
Significance. If the central performance claims are substantiated, CyberCertBench would provide a useful, certification-aligned resource for tracking LLM progress in a high-stakes professional domain. The Proposer-Verifier framework offers a lightweight approach to interpretability that could be adopted more broadly. The explicit release of code and evaluation scripts at the cited GitHub repository is a clear strength that supports reproducibility and community follow-up.
major comments (3)
- [Abstract] Abstract: the assertion that 'frontier models achieve human expert level in general networking and IT security knowledge' is not supported by any direct measurement of human expert accuracy on the CyberCertBench items themselves; the manuscript provides neither human baseline scores on the extracted questions nor inter-rater reliability statistics, leaving the 'human expert level' threshold dependent on unverified nominal passing scores rather than empirical comparison.
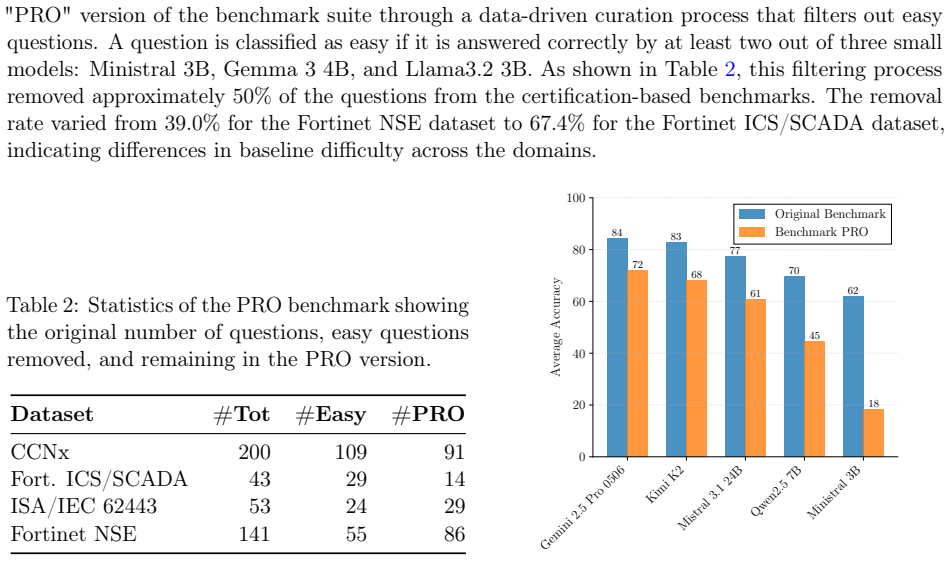
- [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: no criteria are stated for question selection, filtering, or validation from the source certifications, nor are controls described for training-data contamination, prompt sensitivity, or statistical significance of the reported accuracy trends and the observed decline on IEC 62443 and vendor-specific items.
- [Proposer-Verifier framework section] Proposer-Verifier framework section: the claim that the framework produces 'faithful and non-misleading' natural-language explanations is presented without quantitative validation (e.g., human agreement metrics, faithfulness scores, or error analysis), so it is unclear whether the generated explanations reliably reflect model reasoning.
minor comments (2)
- [Abstract] Abstract: typographical errors include 'introduceCyberCertBench' (missing space) and 'specializedareas' (missing space).
- The manuscript would benefit from an explicit table or appendix listing the source certifications, number of questions per domain, and any deduplication steps performed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments have identified important areas where additional clarity and rigor will strengthen the manuscript. We address each major comment below and have revised the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'frontier models achieve human expert level in general networking and IT security knowledge' is not supported by any direct measurement of human expert accuracy on the CyberCertBench items themselves; the manuscript provides neither human baseline scores on the extracted questions nor inter-rater reliability statistics, leaving the 'human expert level' threshold dependent on unverified nominal passing scores rather than empirical comparison.
Authors: We agree that direct human-expert accuracy on the exact CyberCertBench questions would constitute stronger evidence. The original phrasing relied on the fact that the questions originate from certification exams whose published passing thresholds (typically 70-80%) serve as the de-facto human-expert benchmark. In the revised manuscript we have replaced the claim with the more precise statement that frontier models reach or exceed the nominal passing thresholds reported for these certifications. We have also added an explicit limitations paragraph noting the absence of item-level human baselines and inter-rater statistics as an avenue for future work. revision: yes
-
Referee: [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: no criteria are stated for question selection, filtering, or validation from the source certifications, nor are controls described for training-data contamination, prompt sensitivity, or statistical significance of the reported accuracy trends and the observed decline on IEC 62443 and vendor-specific items.
Authors: We acknowledge that the original text omitted explicit selection criteria and controls. The revised benchmark-construction section now details the extraction pipeline, including relevance filtering, removal of ambiguous or duplicate items, and a two-author validation pass. We describe steps taken to reduce contamination risk (use of recent certification materials and manual overlap checks with common pre-training corpora). We have added a prompt-sensitivity analysis across three prompt templates and report the resulting accuracy variance. Finally, we include 95% confidence intervals for all accuracy figures and note that the performance gap on IEC 62443 and vendor-specific items remains statistically significant under a paired t-test. revision: yes
-
Referee: [Proposer-Verifier framework section] Proposer-Verifier framework section: the claim that the framework produces 'faithful and non-misleading' natural-language explanations is presented without quantitative validation (e.g., human agreement metrics, faithfulness scores, or error analysis), so it is unclear whether the generated explanations reliably reflect model reasoning.
Authors: The original manuscript supported the framework primarily through illustrative examples. We agree that quantitative validation is necessary. In the revision we have added a human evaluation on a stratified sample of 100 explanations: two independent annotators rated faithfulness and absence of misleading content, yielding Cohen’s κ = 0.81. We also include a brief error analysis classifying the small fraction of lower-faithfulness cases. These results are now reported in the Proposer-Verifier section and support the original qualitative claims with empirical metrics. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with no derivations or self-referential reductions
full rationale
The paper constructs CyberCertBench directly from external industry certification materials and reports LLM performance via straightforward accuracy measurements on those items, along with an empirically validated Proposer-Verifier explanation framework. No mathematical derivations, equations, fitted parameters, or ansatzes appear in the described work. Central claims rest on direct testing against the benchmark rather than any reduction to prior results by construction, self-citation chains, or renaming of known patterns. This is a standard empirical evaluation paper whose findings are independent of the inputs used to build the test set.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple-choice questions drawn from professional cybersecurity certifications accurately and comprehensively measure the domain knowledge required for expert-level practice.
invented entities (1)
-
Proposer-Verifier framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models
Priyan Vaithilingam, Tianyi Zhang, and Elena L. Glassman. Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models. In Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems, CHI EA ’22, pages 1–7. Association for Computing Machinery. ISBN 978-1-4503-9156-6. doi: 10.1145/34...
-
[2]
Grounded Copilot: How Programmers Interact with Code-Generating Models
ShraddhaBarke, MichaelB.James, andNadiaPolikarpova. Groundedcopilot: Howprogrammers interact with code-generating models.Proc. ACM Program. Lang., 7(OOPSLA1):85–111, 2023. doi: 10.1145/3586030. URL https://doi.org/10.1145/3586030
-
[3]
Ranim Khojah, Mazen Mohamad, Philipp Leitner, and Francisco Gomes de Oliveira Neto. Beyond code generation: An observational study of chatgpt usage in software engineering practice.Proc. ACM Softw. Eng., 1(FSE):1819–1840, 2024. doi: 10.1145/3660788. URL https://doi.org/10.1145/3660788
-
[4]
CTIBench: A benchmark for evaluating llms in cyber threat intelligence
Md Tanvirul Alam, Dipkamal Bhusal, Le Nguyen, and Nidhi Rastogi. CTIBench: A benchmark for evaluating llms in cyber threat intelligence. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Ad- vances in Neural Information Processing Systems, volume 37, pages 50805–50825. Cur- ran Associates, Inc. URL https://proce...
2024
-
[5]
Mikel Rodriguez, Raluca Ada Popa, Four Flynn, Lihao Liang, Allan Dafoe, and Anna Wang. A framework for evaluating emerging cyberattack capabilities of AI.arXiv preprint arXiv: 2503.11917, 2025. doi: 10.48550/ARXIV.2503.11917. URL https://doi.org/10.48550/arXiv. 2503.11917
-
[6]
Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W
Andy K. Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W. Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Julian Jasper, Pura Peetathawatchai, Ari Glenn, Vikram Sivashankar, Daniel Zamoshchin, Leo Glikbarg, Derek Askaryar, Haoxiang Yang, Aolin Zhang, Rishi Alluri, Nathan Tran, and et al. Cybench: A framework for evaluating cyber...
2025
-
[7]
doi: 10.3390/healthcare11060887
Malik Sallam. Chatgpt utility in health care education, research, and practice: Systematic review on the promising perspectives and valid concerns.Healthcare, 11:887, 03 2023. doi: 10.3390/healthcare11060887
-
[8]
egridgpt: Trustworthy ai in the control room
Seong Lok Choi, Rishabh Jain, Patrick Emami, Karin Wadsack, Fei Ding, Hongfei Sun, Kenny Gruchalla, Junho Hong, Hongming Zhang, Xiangqi Zhu, et al. egridgpt: Trustworthy ai in the control room. Technical report, National Renewable Energy Laboratory (NREL), Golden, CO (United States), 05 2024. URL https://www.osti.gov/biblio/2352232
-
[9]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Comput. Surv., 55(12):248:1–248:38, 2023. doi: 10.1145/3571730. URL https://doi.org/ 10.1145/3571730. 15
-
[10]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[11]
Norbert Tihanyi, Mohamed Amine Ferrag, Ridhi Jain, Tamás Bisztray, and Mérouane Debbah. Cybermetric: A benchmark dataset based on retrieval-augmented generation for evaluating llms in cybersecurity knowledge. InIEEE International Conference on Cyber Security and Resilience, CSR 2024, London, UK, September 2-4, 2024, pages 296–302. IEEE, 2024. doi: 10.1109...
-
[12]
Ioannis Zografopoulos, Juan Ospina, Xiaorui Liu, and Charalambos Konstantinou. Cyber- physical energy systems security: Threat modeling, risk assessment, resources, metrics, and case studies.IEEE Access, 9:29775–29818, 2021. doi: 10.1109/ACCESS.2021.3058403
-
[13]
On hallucination and predictive uncertainty in conditional language generation
Yijun Xiao and William Yang Wang. On hallucination and predictive uncertainty in conditional language generation. In Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty, editors,Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2734–2744, Online, April 2021. Association for Computati...
-
[14]
Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Ariel Herbert-Voss, Cort B. Breuer, Andy Z...
2024
-
[15]
Seceval: A comprehensive benchmark for evaluating cybersecurity knowledge of foundation models
Guancheng Li, Yifeng Li, Wang Guannan, Haoyu Yang, and Yang Yu. Seceval: A comprehensive benchmark for evaluating cybersecurity knowledge of foundation models. https://github.com/XuanwuAI/SecEval, 2023
2023
-
[16]
Zefang Liu. Secqa: A concise question-answering dataset for evaluating large language models in computer security.arXiv preprint arXiv: 2312.15838, 2023. doi: 10.48550/ARXIV.2312.15838. URL https://doi.org/10.48550/arXiv.2312.15838
-
[17]
Occult: Evaluating large language models for offensive cyber operation capabilities,
Michael Kouremetis, Marissa Dotter, Alex Byrne, Dan Martin, Ethan Michalak, Gianpaolo Russo, Michael Threet, and Guido Zarrella. OCCULT: evaluating large language models for offensive cyber operation capabilities.arXiv preprint arXiv: 2502.15797, 2025. doi: 10.48550/ ARXIV.2502.15797. URL https://doi.org/10.48550/arXiv.2502.15797
-
[18]
Mary Phuong, Matthew Aitchison, Elliot Catt, Sarah Cogan, Alexandre Kaskasoli, Victoria Krakovna, David Lindner, Matthew Rahtz, Yannis Assael, Sarah Hodkinson, Heidi Howard, Tom Lieberum, Ramana Kumar, Maria Abi Raad, Albert Webson, Lewis Ho, Sharon Lin, Sebastian Farquhar, Marcus Hutter, Grégoire Delétang, Anian Ruoss, Seliem El-Sayed, Sasha Brown, 16 An...
-
[19]
Pentestgpt: Evaluating and harnessing large language models for automated penetration testing
Gelei Deng, Yi Liu, Víctor Mayoral Vilches, Peng Liu, Yuekang Li, Yuan Xu, Martin Pinzger, Stefan Rass, Tianwei Zhang, and Yang Liu. Pentestgpt: Evaluating and harnessing large language models for automated penetration testing. In Davide Balzarotti and Wenyuan Xu, editors,33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August ...
2024
-
[20]
An empirical evaluation of llms for solving offensive security challenges
Minghao Shao, Boyuan Chen, Sofija Jancheska, Brendan Dolan-Gavitt, Siddharth Garg, Ramesh Karri, and Muhammad Shafique. An Empirical Evaluation of LLMs for Solving Offensive Security Challenges.arXiv preprint arXiv: 2402.11814, 2024. doi: 10.48550/ARXIV.2402.11814. URL https://arxiv.org/abs/2402.11814
-
[21]
NYU CTF bench: A scalable open-source benchmark dataset for evaluating llms in offensive security
Minghao Shao, Sofija Jancheska, Meet Udeshi, Brendan Dolan-Gavitt, Haoran Xi, Kimberly Milner, Boyuan Chen, Max Yin, Siddharth Garg, Prashanth Krishnamurthy, Farshad Khor- rami, Ramesh Karri, and Muhammad Shafique. NYU CTF bench: A scalable open-source benchmark dataset for evaluating llms in offensive security. In Amir Globersons, Lester Mackey, Danielle...
2024
-
[22]
Jiacen Xu, Jack W. Stokes, Geoff McDonald, Xuesong Bai, David Marshall, Siyue Wang, Adith Swaminathan, and Zhou Li. Autoattacker: A large language model guided system to implement automatic cyber-attacks.arXiv preprint arXiv: 2403.01038, 2024. doi: 10.48550/ARXIV.2403. 01038. URL https://doi.org/10.48550/arXiv.2403.01038
-
[23]
Talor Abramovich, Meet Udeshi, Minghao Shao, Kilian Lieret, Haoran Xi, Kimberly Milner, Sofija Jancheska, John Yang, Carlos E. Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik Narasimhan, Ramesh Karri, and Ofir Press. Enigma: Enhanced interactive generative model agent for CTF challenges.arXiv preprint a...
-
[24]
Meet Udeshi, Minghao Shao, Haoran Xi, Nanda Rani, Kimberly Milner, Venkata Sai Charan Putrevu, Brendan Dolan-Gavitt, Sandeep Kumar Shukla, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. D-CIPHER: dynamic collaborative intelligent agents with planning and heterogeneous execution for enhanced reasoning in offensive security....
-
[25]
Andrey Anurin, Jonathan Ng, Kibo Schaffer, Jason Schreiber, and Esben Kran. Catastrophic cyber capabilities benchmark (3CB): robustly evaluating LLM agent cyber offense capabilities. arXiv preprint arXiv: 2410.09114, 2024. doi: 10.48550/ARXIV.2410.09114. URL https: //doi.org/10.48550/arXiv.2410.09114. 17
-
[26]
Cyberbench: A multi-task benchmark for evaluating large language models in cybersecurity
Zefang Liu, Jialei Shi, and John F Buford. Cyberbench: A multi-task benchmark for evaluating large language models in cybersecurity. AAAI-24 Workshop on Artificial Intelligence for Cyber Security (AICS), 2024
2024
-
[27]
Shengye Wan, Cyrus Nikolaidis, Daniel Song, David Molnar, James Crnkovich, Jayson Grace, Manish Bhatt, Sahana Chennabasappa, Spencer Whitman, Stephanie Ding, Vlad Ionescu, Yue Li, and Joshua Saxe. CYBERSECEVAL 3: Advancing the evaluation of cybersecurity risks and capabilities in large language models.arXiv preprint arXiv: 2408.01605, 2024. doi: 10.48550/...
-
[28]
Tao, Z., Lin, T., Chen, X., Li, H., Wu, Y ., Li, Y ., Jin, Z., Huang, F., Tao, D., and Zhou, J
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cornelius Aschermann, Yaohui Chen, Dhaval Kapil, David Molnar, Spencer Whitman, and Joshua Saxe. Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models.arXiv preprint arXiv: 2404.13161, 2024. doi: 10.48550/ARXIV.2404. 1316...
-
[29]
Wesley Joon-Wie Tann, Yuancheng Liu, Jun Heng Sim, Choon Meng Seah, and Ee-Chien Chang. Using large language models for cybersecurity capture-the-flag challenges and certification questions.arXiv preprint arXiv: 2308.10443, 2023. doi: 10.48550/ARXIV.2308.10443. URL https://doi.org/10.48550/arXiv.2308.10443
-
[30]
Evaluating Large Language Models in Cybersecurity Knowledge with Cisco Certificates
Gustav Keppler, Jeremy Kunz, Veit Hagenmeyer, and Ghada Elbez. Evaluating Large Language Models in Cybersecurity Knowledge with Cisco Certificates. InSecure IT Systems: 29th Nordic Conference, NordSec 2024 Karlstad, Sweden, November 6–7, 2024 Proceedings, pages 219–238. Springer-Verlag. ISBN 978-3-031-79006-5. doi: 10.1007/978-3-031-79007-2_12. URL https:...
-
[31]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
2023
-
[32]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela ...
2024
-
[33]
Describing Differences between Text Distributions with Natural Language
Ruiqi Zhong, Charlie Snell, Dan Klein, and Jacob Steinhardt. Describing Differences between Text Distributions with Natural Language. InProceedings of the 39th International Conference 18 on Machine Learning, pages 27099–27116. PMLR. URL https://proceedings.mlr.press/v162/ zhong22a.html
-
[34]
U-shaped and inverted-u scaling behind emergent abilities of large language models
Tung-Yu Wu and Melody Lo. U-shaped and inverted-u scaling behind emergent abilities of large language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/ forum?id=jjfve2gIXe
2025
-
[35]
Arno Kok, Alberto Martinetti, and Jan Braaksma. The impact of integrating information technology with operational technology in physical assets: A literature review.IEEE Access, 12:111832–111845, 2024. doi: 10.1109/ACCESS.2024.3442443. 19 Appendices A Synthesized Descriptions of Question Difficulty The following tables provides the short and complete, syn...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.