Recognition: unknown
MLG-Stereo: ViT Based Stereo Matching with Multi-Stage Local-Global Enhancement
Pith reviewed 2026-05-10 00:08 UTC · model grok-4.3
The pith
MLG-Stereo adds multi-granularity features, local-global cost volumes, and guided recurrent units to ViT stereo matching so it can predict details at any image resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
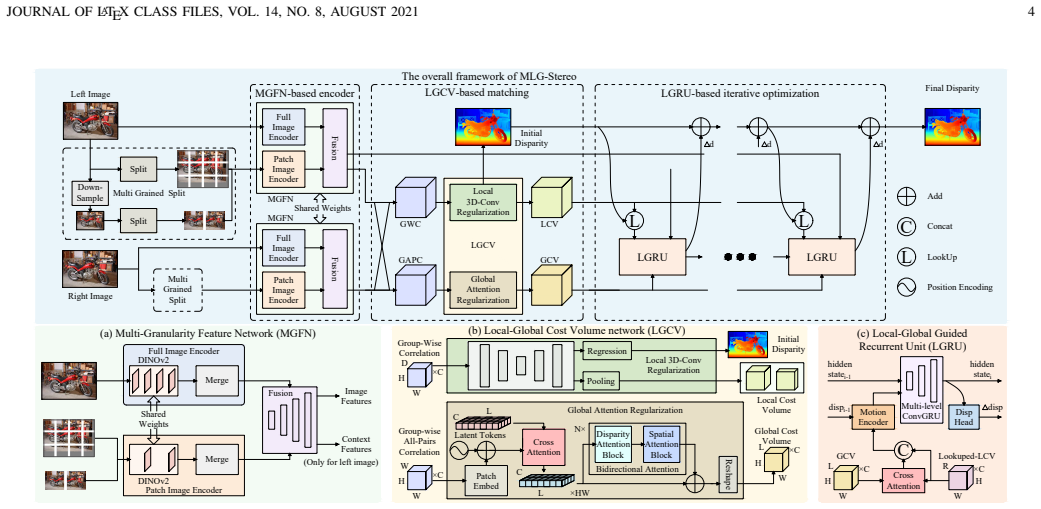
MLG-Stereo extends global modeling past the encoder by building a Multi-Granularity Feature Network that extracts both global context and local geometry from arbitrary-resolution inputs, a Local-Global Cost Volume that encodes both correlated local matches and global-aware information, and a Local-Global Guided Recurrent Unit that refines disparity locally while guided by global cues, producing competitive results on Middlebury and KITTI-2015 and leading results on KITTI-2012.
What carries the argument
The combination of Multi-Granularity Feature Network, Local-Global Cost Volume, and Local-Global Guided Recurrent Unit that carries global context through every stage while preserving local geometric detail.
If this is right
- ViT stereo methods can now process test images at resolutions different from training without scale-induced errors.
- Detail recovery in textured or occluded regions improves while global consistency is retained.
- The same three-stage pattern can be reused on other dense prediction tasks that need both wide context and fine local accuracy.
Where Pith is reading between the lines
- The same local-global staging might reduce the resolution sensitivity seen in ViT models for optical flow or monocular depth estimation.
- A controlled test that varies input resolution continuously would directly quantify how much the new components reduce the training-inference scale gap.
- Replacing the ViT backbone with a different global feature extractor could reveal whether the gains depend on the transformer architecture itself.
Load-bearing premise
The added networks and units close the gap between global modeling and local detail without introducing resolution-specific artifacts or overfitting to the chosen benchmarks.
What would settle it
Measure whether accuracy falls sharply when the same model is tested on image pairs whose resolution or scene statistics lie well outside the Middlebury and KITTI training distributions.
Figures







read the original abstract
With the development of deep learning, ViT-based stereo matching methods have made significant progress due to their remarkable robustness and zero-shot ability. However, due to the limitations of ViTs in handling resolution sensitivity and their relative neglect of local information, the ability of ViT-based methods to predict details and handle arbitrary-resolution images is still weaker than that of CNN-based methods. To address these shortcomings, we propose MLG-Stereo, a systematic pipeline-level design that extends global modeling beyond the encoder stage. First, we propose a Multi-Granularity Feature Network to effectively balance global context and local geometric information, enabling comprehensive feature extraction from images of arbitrary resolution and bridging the gap between training and inference scales. Then, a Local-Global Cost Volume is constructed to capture both locally-correlated and global-aware matching information. Finally, a Local-Global Guided Recurrent Unit is introduced to iteratively optimize the disparity locally under the guidance of global information. Extensive experiments are conducted on multiple benchmark datasets, demonstrating that our MLG-Stereo exhibits highly competitive performance on the Middlebury and KITTI-2015 benchmarks compared to contemporaneous leading methods, and achieves outstanding results in the KITTI-2012 dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MLG-Stereo, a ViT-based stereo matching architecture that introduces a Multi-Granularity Feature Network to balance global context and local geometric information for arbitrary-resolution inputs, a Local-Global Cost Volume to capture both local correlations and global-aware matching cues, and a Local-Global Guided Recurrent Unit for iterative disparity optimization under global guidance. The central claim is that this pipeline-level extension of global modeling beyond the encoder addresses ViT limitations in resolution sensitivity and local detail handling, yielding highly competitive results on Middlebury and KITTI-2015 benchmarks and outstanding results on KITTI-2012.
Significance. If the benchmark gains prove robust and generalizable, the work could meaningfully advance practical ViT deployment in stereo matching by mitigating resolution mismatches between training and inference. The multi-stage local-global design offers a coherent architectural response to known ViT-CNN trade-offs, and the emphasis on arbitrary-resolution capability is a timely contribution if supported by targeted experiments.
major comments (3)
- Abstract: The performance claims rest on unspecified experimental controls with no error bars, ablation tables, or quantitative deltas provided, which is load-bearing because the central assertion that the three modules close the ViT resolution and local-detail gaps cannot be evaluated without evidence that each component contributes measurably beyond baselines.
- Multi-Granularity Feature Network description: The scale-bridging claim (bridging training and inference scales for arbitrary-resolution inference) lacks direct verification via resolution-shift experiments or cross-benchmark generalization tests; without such tests the architecture may simply fit the Middlebury/KITTI training crops rather than decouple performance from resolution.
- Local-Global Cost Volume and Recurrent Unit sections: Interaction details between these modules and the feature network are insufficient to confirm they avoid introducing interpolation artifacts or forcing the cost volume to compensate for upstream resolution sensitivity, undermining the pipeline-level design claim.
minor comments (2)
- Abstract: Include at least one key quantitative result (e.g., EPE or D1-all on a benchmark) to ground the qualitative descriptors 'highly competitive' and 'outstanding'.
- Notation: Define all acronyms (ViT, EPE, etc.) on first use and ensure consistent terminology for 'local-global' across sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the experimental evidence and architectural clarity while preserving the core contributions of MLG-Stereo.
read point-by-point responses
-
Referee: Abstract: The performance claims rest on unspecified experimental controls with no error bars, ablation tables, or quantitative deltas provided, which is load-bearing because the central assertion that the three modules close the ViT resolution and local-detail gaps cannot be evaluated without evidence that each component contributes measurably beyond baselines.
Authors: We agree that the abstract would be strengthened by including key quantitative deltas and references to supporting evidence. The full manuscript already contains comparison tables on Middlebury, KITTI-2012, and KITTI-2015 along with module ablations; however, to directly address the concern we will revise the abstract to highlight specific improvements (e.g., EPE and D1 reductions versus strong ViT and CNN baselines) and ensure the experimental section reports error bars from repeated runs where feasible. We will also expand the ablation subsection to explicitly quantify each module's contribution. revision: yes
-
Referee: Multi-Granularity Feature Network description: The scale-bridging claim (bridging training and inference scales for arbitrary-resolution inference) lacks direct verification via resolution-shift experiments or cross-benchmark generalization tests; without such tests the architecture may simply fit the Middlebury/KITTI training crops rather than decouple performance from resolution.
Authors: The Multi-Granularity Feature Network combines ViT global context with local geometric cues at multiple scales precisely to support arbitrary-resolution inputs. While results across Middlebury (high-resolution) and KITTI (lower-resolution) datasets provide supporting evidence of generalization, we acknowledge that dedicated resolution-shift tests would offer stronger verification. We will therefore add targeted experiments: training on standard crops and evaluating on upsampled/downsampled versions of the same scenes, plus explicit cross-benchmark resolution transfer tests, to demonstrate that performance is not merely an artifact of training-crop fitting. revision: yes
-
Referee: Local-Global Cost Volume and Recurrent Unit sections: Interaction details between these modules and the feature network are insufficient to confirm they avoid introducing interpolation artifacts or forcing the cost volume to compensate for upstream resolution sensitivity, undermining the pipeline-level design claim.
Authors: We will augment the manuscript with a detailed data-flow diagram and additional textual description clarifying the interfaces between the Multi-Granularity Feature Network, Local-Global Cost Volume, and Local-Global Guided Recurrent Unit. We will also include a short analysis (supported by qualitative visualizations) showing that the local-global cost construction operates on the already multi-scale features without introducing interpolation artifacts, and that the recurrent refinement leverages global guidance to improve rather than merely compensate for any upstream resolution effects. This will make the pipeline-level extension of global modeling explicit. revision: yes
Circularity Check
No circularity: empirical architecture proposal validated on external benchmarks
full rationale
The paper describes an empirical neural architecture (MLG-Stereo) with three proposed modules: Multi-Granularity Feature Network, Local-Global Cost Volume, and Local-Global Guided Recurrent Unit. Performance is asserted via direct comparison on standard external datasets (Middlebury, KITTI-2012, KITTI-2015). No equations, derivations, or predictions are present that reduce to fitted parameters or self-referential definitions by construction. No load-bearing self-citations or uniqueness theorems imported from prior author work appear in the abstract or described claims. The central assertions remain falsifiable through independent benchmark evaluation and do not collapse into tautological renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ViTs inherently neglect local geometric information and are sensitive to resolution changes between train and inference.
invented entities (3)
-
Multi-Granularity Feature Network
no independent evidence
-
Local-Global Cost Volume
no independent evidence
-
Local-Global Guided Recurrent Unit
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Computer stereo vision for autonomous driving,
R. Fan, L. Wang, M. J. Bocus, and I. Pitas, “Computer stereo vision for autonomous driving,”arXiv preprint arXiv:2012.03194, 2020
-
[2]
Re-parameterized real- time stereo matching network based on mixed cost volumes toward autonomous driving,
B. Yao, W. Wei, J. Huang, B. Liang, and J. Li, “Re-parameterized real- time stereo matching network based on mixed cost volumes toward autonomous driving,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 12, pp. 14 914–14 926, 2023
2023
-
[3]
An application of stereo matching algorithm based on transfer learning on robots in multiple scenes,
Y . Bi, C. Li, X. Tong, G. Wang, and H. Sun, “An application of stereo matching algorithm based on transfer learning on robots in multiple scenes,”Scientific Reports, vol. 13, no. 1, p. 12739, 2023
2023
-
[4]
A new fast and robust stereo matching algorithm for robotic systems,
M. Samadi and M. F. Othman, “A new fast and robust stereo matching algorithm for robotic systems,” inThe 9th International Conference on Computing and InformationTechnology (IC2IT2013) 9th-10th May 2013 King Mongkut’s University of Technology North Bangkok. Springer, 2013, pp. 281–290
2013
-
[5]
Exploring stereovision-based 3-d scene reconstruction for augmented reality,
G.-Y . Nie, Y . Liu, C. Wang, Y . Liu, and Y . Wang, “Exploring stereovision-based 3-d scene reconstruction for augmented reality,” in 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR). IEEE, 2019, pp. 1100–1101
2019
-
[6]
Stereo matching in time: 100+ fps video stereo matching for extended reality,
Z. Cheng, J. Yang, and H. Li, “Stereo matching in time: 100+ fps video stereo matching for extended reality,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 8719– 8728
2024
-
[7]
End-to-end learning of geometry and context for deep stereo regression,
A. Kendall, H. Martirosyan, S. Dasgupta, P. Henry, R. Kennedy, A. Bachrach, and A. Bry, “End-to-end learning of geometry and context for deep stereo regression,” inICCV, 2017, pp. 66–75
2017
-
[8]
Pyramid stereo matching network,
J.-R. Chang and Y .-S. Chen, “Pyramid stereo matching network,” in CVPR, 2018, pp. 5410–5418
2018
-
[9]
Group-wise correlation stereo network,
X. Guo, K. Yang, W. Yang, X. Wang, and H. Li, “Group-wise correlation stereo network,” inCVPR, 2019, pp. 3273–3282
2019
-
[10]
Raft-stereo: Multilevel recurrent field transforms for stereo matching,
L. Lipson, Z. Teed, and J. Deng, “Raft-stereo: Multilevel recurrent field transforms for stereo matching,” in3DV. IEEE, 2021, pp. 218–227
2021
-
[11]
High- frequency stereo matching network,
H. Zhao, H. Zhou, Y . Zhang, J. Chen, Y . Yang, and Y . Zhao, “High- frequency stereo matching network,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1327–1336
2023
-
[12]
Eai-stereo: Error aware iterative network for stereo matching,
H. Zhao, H. Zhou, Y . Zhang, Y . Zhao, Y . Yang, and T. Ouyang, “Eai-stereo: Error aware iterative network for stereo matching,” in Proceedings of the Asian Conference on Computer Vision, 2022, pp. 315–332
2022
-
[13]
Iterative geometry encoding volume for stereo matching,
G. Xu, X. Wang, X. Ding, and X. Yang, “Iterative geometry encoding volume for stereo matching,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023, pp. 21 919– 21 928. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 Bad 2: 10.2 Bad 2: 4.93 Bad 2: 4.83 Bad 2: 4.81 Bad 2: 4.26 Bad 2: 9.38 Bad 2: 5.00 Bad...
2023
-
[14]
Selective-stereo: Adaptive frequency information selection for stereo matching,
X. Wang, G. Xu, H. Jia, and X. Yang, “Selective-stereo: Adaptive frequency information selection for stereo matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 701–19 710
2024
-
[15]
All-in-one: Transferring vision foundation models into stereo matching,
J. Zhou, H. Zhang, J. Yuan, P. Ye, T. Chen, H. Jiang, M. Chen, and Y . Zhang, “All-in-one: Transferring vision foundation models into stereo matching,”arXiv preprint arXiv:2412.09912, 2024
-
[16]
Revisiting stereo depth estimation from a sequence-to-sequence perspective with transformers,
Z. Li, X. Liu, N. Drenkow, A. Ding, F. X. Creighton, R. H. Tay- lor, and M. Unberath, “Revisiting stereo depth estimation from a sequence-to-sequence perspective with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 6197–6206
2021
-
[17]
Context-enhanced stereo transformer,
W. Guo, Z. Li, Y . Yang, Z. Wang, R. H. Taylor, M. Unberath, A. Yuille, and Y . Li, “Context-enhanced stereo transformer,” inEuropean Confer- ence on Computer Vision. Springer, 2022, pp. 263–279
2022
-
[18]
Unifying flow, stereo and depth estimation,
H. Xu, J. Zhang, J. Cai, H. Rezatofighi, F. Yu, D. Tao, and A. Geiger, “Unifying flow, stereo and depth estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[19]
Playing to vision foundation model’s strengths in stereo matching,
C.-W. Liu, Q. Chen, and R. Fan, “Playing to vision foundation model’s strengths in stereo matching,”IEEE Transactions on Intelligent Vehicles, 2024
2024
-
[20]
Fast approximate energy min- imization via graph cuts,
Y . Boykov, O. Veksler, and R. Zabih, “Fast approximate energy min- imization via graph cuts,”IEEE Transactions on pattern analysis and machine intelligence, vol. 23, no. 11, pp. 1222–1239, 2001. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2001
-
[21]
Segment-based stereo matching using belief propagation and a self-adapting dissimilarity measure,
A. Klaus, M. Sormann, and K. Karner, “Segment-based stereo matching using belief propagation and a self-adapting dissimilarity measure,” in 18th International Conference on Pattern Recognition (ICPR’06), vol. 3. IEEE, 2006, pp. 15–18
2006
-
[22]
Stereo matching using belief propagation,
J. Sun, N.-N. Zheng, and H.-Y . Shum, “Stereo matching using belief propagation,”IEEE Transactions on pattern analysis and machine intelligence, vol. 25, no. 7, pp. 787–800, 2003
2003
-
[23]
Stereo match- ing with color-weighted correlation, hierarchical belief propagation, and occlusion handling,
Q. Yang, L. Wang, R. Yang, H. Stew ´enius, and D. Nist´er, “Stereo match- ing with color-weighted correlation, hierarchical belief propagation, and occlusion handling,”IEEE transactions on pattern analysis and machine intelligence, vol. 31, no. 3, pp. 492–504, 2008
2008
-
[24]
Real-time correlation- based stereo vision with reduced border errors,
H. Hirschm ¨uller, P. R. Innocent, and J. Garibaldi, “Real-time correlation- based stereo vision with reduced border errors,”International Journal of Computer Vision, vol. 47, pp. 229–246, 2002
2002
-
[25]
A hierarchical symmetric stereo algorithm using dynamic programming,
G. Van Meerbergen, M. Vergauwen, M. Pollefeys, and L. Van Gool, “A hierarchical symmetric stereo algorithm using dynamic programming,” International Journal of Computer Vision, vol. 47, pp. 275–285, 2002
2002
-
[26]
Accurate and efficient stereo processing by semi- global matching and mutual information,
H. Hirschmuller, “Accurate and efficient stereo processing by semi- global matching and mutual information,” in2005 IEEE Computer Soci- ety Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 2. IEEE, 2005, pp. 807–814
2005
-
[27]
Computing the stereo matching cost with a convolutional neural network,
J. Zbontar and Y . LeCun, “Computing the stereo matching cost with a convolutional neural network,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1592–1599
2015
-
[28]
Pyramid stereo matching network,
J.-R. Chang and Y .-S. Chen, “Pyramid stereo matching network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5410–5418
2018
-
[29]
Raft: Recurrent all-pairs field transforms for optical flow,
Z. Teed and J. Deng, “Raft: Recurrent all-pairs field transforms for optical flow,” inECCV. Springer, 2020, pp. 402–419
2020
-
[30]
Iterative geometry encoding volume for stereo matching,
G. Xu, X. Wang, X. Ding, and X. Yang, “Iterative geometry encoding volume for stereo matching,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023, pp. 21 919– 21 928
2023
-
[31]
Foundationstereo: Zero-shot stereo matching,
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield, “Foundationstereo: Zero-shot stereo matching,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5249– 5260
2025
-
[32]
Defom-stereo: Depth foundation model based stereo matching,
H. Jiang, Z. Lou, L. Ding, R. Xu, M. Tan, W. Jiang, and R. Huang, “Defom-stereo: Depth foundation model based stereo matching,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 21 857–21 867
2025
-
[33]
Monster: Marry monodepth to stereo unleashes power,
J. Cheng, L. Liu, G. Xu, X. Wang, Z. Zhang, Y . Deng, J. Zang, Y . Chen, Z. Cai, and X. Yang, “Monster: Marry monodepth to stereo unleashes power,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6273–6282
2025
-
[34]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[35]
Swin transformer v2: Scaling up capacity and resolution,
Z. Liu, H. Hu, Y . Lin, Z. Yao, Z. Xie, Y . Wei, J. Ning, Y . Cao, Z. Zhang, L. Dong, F. Wei, and B. Guo, “Swin transformer v2: Scaling up capacity and resolution,” inInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[36]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the International Conference on Computer Vision (ICCV), 2021
2021
-
[37]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P.-Y . Huang, H. Xu, V . Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features withou...
2023
-
[38]
Swin-unet: Unet-like pure transformer for medical image segmenta- tion,
H. Cao, Y . Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, and M. Wang, “Swin-unet: Unet-like pure transformer for medical image segmenta- tion,” inEuropean conference on computer vision. Springer, 2022, pp. 205–218
2022
-
[39]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” inCVPR, 2024
2024
-
[40]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”arXiv:2406.09414, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
Depth anything: Unleash- ing the power of large-scale unlabeled data
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,”arXiv preprint arXiv:2401.10891, 2024
-
[42]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
A. Bochkovskii, A. Delaunoy, H. Germain, M. Santos, Y . Zhou, S. R. Richter, and V . Koltun, “Depth pro: Sharp monocular metric depth in less than a second,”arXiv preprint arXiv:2410.02073, 2024
work page internal anchor Pith review arXiv 2024
-
[43]
Bowen Jing, Bonnie Berger, and Tommi Jaakkola
A. Jaegle, S. Borgeaud, J.-B. Alayrac, C. Doersch, C. Ionescu, D. Ding, S. Koppula, D. Zoran, A. Brock, E. Shelhameret al., “Perceiver io: A general architecture for structured inputs & outputs,”arXiv preprint arXiv:2107.14795, 2021
-
[44]
Twins: Revisiting the design of spatial attention in vision trans- formers,
X. Chu, Z. Tian, Y . Wang, B. Zhang, H. Ren, X. Wei, H. Xia, and C. Shen, “Twins: Revisiting the design of spatial attention in vision trans- formers,”Advances in neural information processing systems, vol. 34, pp. 9355–9366, 2021
2021
-
[45]
A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,
N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox, “A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4040– 4048
2016
-
[46]
Virtual kitti 2,
Y . Cabon, N. Murray, and M. Humenberger, “Virtual kitti 2,” 2020
2020
-
[47]
Virtual worlds as proxy for multi-object tracking analysis,
A. Gaidon, Q. Wang, Y . Cabon, and E. Vig, “Virtual worlds as proxy for multi-object tracking analysis,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2016, pp. 4340–4349
2016
-
[48]
High-resolution stereo datasets with subpixel-accurate ground truth,
D. Scharstein, H. Hirschm ¨uller, Y . Kitajima, G. Krathwohl, N. Ne ˇsi´c, X. Wang, and P. Westling, “High-resolution stereo datasets with subpixel-accurate ground truth,” inGCPR. Springer, 2014, pp. 31– 42
2014
-
[49]
Are we ready for autonomous driving? the kitti vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” inCVPR. IEEE, 2012, pp. 3354–3361
2012
-
[50]
Object scene flow for autonomous vehicles,
M. Menze and A. Geiger, “Object scene flow for autonomous vehicles,” inCVPR, 2015, pp. 3061–3070
2015
-
[51]
Adstereo: Efficient stereo matching with adaptive downsampling and disparity alignment,
Y . Wang, K. Li, L. Wang, J. Hu, D. Oliver Wu, and Y . Guo, “Adstereo: Efficient stereo matching with adaptive downsampling and disparity alignment,”IEEE Transactions on Image Processing, vol. 34, pp. 1204– 1218, 2025
2025
-
[52]
Practical stereo matching via cascaded recurrent network with adaptive correlation,
J. Li, P. Wang, P. Xiong, T. Cai, Z. Yan, L. Yang, J. Liu, H. Fan, and S. Liu, “Practical stereo matching via cascaded recurrent network with adaptive correlation,” inCVPR, 2022, pp. 16 263–16 272
2022
-
[53]
Consistency-aware self-training for iterative-based stereo matching,
J. Zhou, P. Ye, H. Zhang, J. Yuan, R. Qiang, L. YangChenXu, W. Cailin, F. Xu, and T. Chen, “Consistency-aware self-training for iterative-based stereo matching,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 641–16 650
2025
-
[54]
Igev++: Iterative multi-range geometry encoding volumes for stereo matching,
G. Xu, X. Wang, Z. Zhang, J. Cheng, C. Liao, and X. Yang, “Igev++: Iterative multi-range geometry encoding volumes for stereo matching,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[55]
Cfnet: Cascade and fused cost volume for robust stereo matching,
Z. Shen, Y . Dai, and Z. Rao, “Cfnet: Cascade and fused cost volume for robust stereo matching,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13 906–13 915
2021
-
[56]
Region separable stereo matching,
J. Cheng, X. Yang, Y . Pu, and P. Guo, “Region separable stereo matching,”IEEE Transactions on Multimedia, vol. 25, pp. 4880–4893, 2022
2022
-
[57]
Unambiguous pyramid cost volumes fusion for stereo matching,
Q. Chen, B. Ge, and J. Quan, “Unambiguous pyramid cost volumes fusion for stereo matching,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 9223–9236, 2023
2023
-
[58]
Deep stereo net- work with mrf-based cost aggregation,
K. Zeng, H. Zhang, W. Wang, Y . Wang, and J. Mao, “Deep stereo net- work with mrf-based cost aggregation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, pp. 2426–2438, 2023
2023
-
[59]
Region-aware driven distribution optimization for stereo matching,
L. Zhu, E. Rigall, Y . Gao, Z. Zhang, Y . Bai, and J. Dong, “Region-aware driven distribution optimization for stereo matching,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[60]
Tartanair: A dataset to push the limits of visual slam,
W. Wang, D. Zhu, X. Wang, Y . Hu, Y . Qiu, C. Wang, Y . Hu, A. Kapoor, and S. Scherer, “Tartanair: A dataset to push the limits of visual slam,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 4909–4916
2020
-
[61]
Falling things: A synthetic dataset for 3d object detection and pose estimation,
J. Tremblay, T. To, and S. Birchfield, “Falling things: A synthetic dataset for 3d object detection and pose estimation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018, pp. 2038–2041
2018
-
[62]
Instereo2k: a large real dataset for stereo matching in indoor scenes,
W. Bao, W. Wang, Y . Xu, Y . Guo, S. Hong, and X. Zhang, “Instereo2k: a large real dataset for stereo matching in indoor scenes,”Science China Information Sciences, vol. 63, pp. 1–11, 2020
2020
-
[63]
Hierarchical deep stereo matching on high-resolution images,
G. Yang, J. Manela, M. Happold, and D. Ramanan, “Hierarchical deep stereo matching on high-resolution images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5515–5524
2019
-
[64]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 Haoyu Zhangreceived the B.S. degree in electronic science and technology from the School of Infor- mation Science and ...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.