Recognition: unknown
Unlocking the Forecasting Economy: A Suite of Datasets for the Full Lifecycle of Prediction Market: [Experiments \& Analysis]
Pith reviewed 2026-05-10 01:25 UTC · model grok-4.3
The pith
A unified dataset suite now covers the full lifecycle of decentralized prediction markets on Polymarket from creation to settlement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
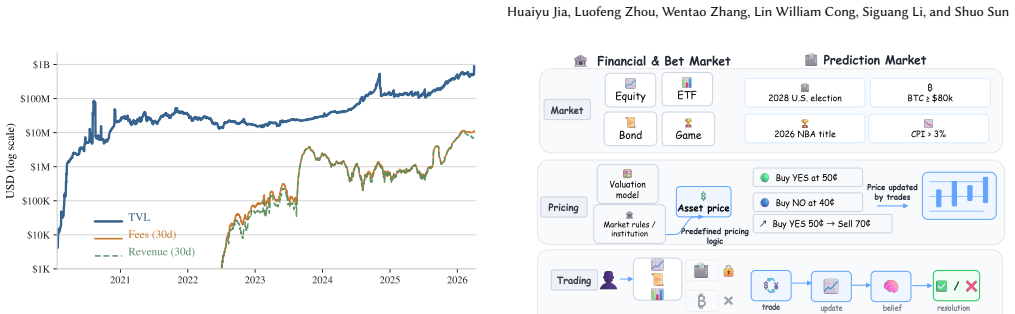
The authors build a unified relational data system that integrates three canonical layers: market metadata, fill-level trading records, and oracle-resolution events, through identifier resolution, on-chain recovery, and incremental updates. The resulting dataset spans October 2020 to March 2026 and comprises more than 770 thousand market records, over 943 million fill records, and nearly 2 million oracle events. They demonstrate its utility through descriptive analyses and case studies on NBA outcome calibration and CPI expectation reconstruction.
What carries the argument
The unified relational data system integrating market metadata, trading records, and oracle events using identifier resolution and incremental updates.
Load-bearing premise
That the cross-source identifier resolution and incremental updates create complete and accurate links between off-chain metadata, on-chain trades, and oracle events with no major missing or mismatched records.
What would settle it
Finding a significant number of markets where the linked trade records or oracle events do not match the actual blockchain transactions or public resolutions would show the integration is incomplete.
Figures












read the original abstract
Prediction markets are markets for trading claims on future events, such as presidential elections, and their prices provide continuously updated signals of collective beliefs. In decentralized platforms such as Polymarket, the market lifecycle spans market creation, token registration, trading, oracle interaction, dispute, and final settlement, yet the corresponding data are fragmented across heterogeneous off-chain and on-chain sources. We present the first continuously maintained dataset suite for the full lifecycle of decentralized prediction markets, built on Polymarket. To address the challenges of large-scale cross-source integration, incomplete linkage, and continuous synchronization, we build a unified relational data system that integrates three canonical layers: market metadata, fill-level trading records, and oracle-resolution events, through identifier resolution, on-chain recovery, and incremental updates. The resulting dataset spans October 2020 to March 2026 and comprises more than 770 thousand market records, over 943 million fill records, and nearly 2 million oracle events. We describe the data model, collection pipeline, and consistency mechanisms that make the dataset reproducible and extensible, and we demonstrate its utility through descriptive analyses of market activity and two downstream case studies: NBA outcome calibration and CPI expectation reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first continuously maintained dataset suite for the full lifecycle of decentralized prediction markets on Polymarket. It integrates three layers—market metadata, fill-level trading records, and oracle-resolution events—via identifier resolution, on-chain recovery, and incremental updates to produce a unified relational system. The resulting dataset spans October 2020–March 2026 and contains more than 770 thousand market records, over 943 million fill records, and nearly 2 million oracle events. The authors describe the data model, collection pipeline, and consistency mechanisms for reproducibility and extensibility, and illustrate utility through descriptive analyses of market activity plus two case studies on NBA outcome calibration and CPI expectation reconstruction.
Significance. If the integration mechanisms achieve complete and accurate linkage, the dataset would be a substantial resource for research on prediction markets, collective belief formation, and forecasting. Its scale, continuous maintenance, and coverage of the entire market lifecycle (creation through settlement) enable analyses that were previously limited by fragmented data sources. The emphasis on reproducibility, extensibility, and open case studies further enhances its value for downstream empirical work in the field.
major comments (1)
- Abstract: The central claim that the unified relational system produces a complete, error-free dataset via identifier resolution, on-chain recovery, and incremental updates is not supported by any quantitative validation. No success rates for cross-source identifier matching, mismatch frequencies, missing-record detection rates, or ground-truth completeness checks on any subset are reported, despite the dataset scale (770k markets, 943M fills, 2M oracle events) being presented as a direct outcome of these mechanisms. This is load-bearing for the paper's contribution, as the downstream case studies (NBA calibration, CPI reconstruction) and all activity statistics rest on the unverified assumption that integration artifacts do not distort the data.
minor comments (1)
- Abstract and title: The title contains the bracketed placeholder '[Experiments & Analysis]', which should be removed or clarified for a final manuscript. The abstract's scale figures ('more than 770 thousand', 'over 943 million', 'nearly 2 million') would benefit from exact counts and a dedicated table or section summarizing dataset statistics.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the importance of quantitative validation for our integration claims. We agree this is a substantive point and will revise the manuscript accordingly to include explicit metrics and a dedicated validation section.
read point-by-point responses
-
Referee: [—] Abstract: The central claim that the unified relational system produces a complete, error-free dataset via identifier resolution, on-chain recovery, and incremental updates is not supported by any quantitative validation. No success rates for cross-source identifier matching, mismatch frequencies, missing-record detection rates, or ground-truth completeness checks on any subset are reported, despite the dataset scale (770k markets, 943M fills, 2M oracle events) being presented as a direct outcome of these mechanisms. This is load-bearing for the paper's contribution, as the downstream case studies (NBA calibration, CPI reconstruction) and all activity statistics rest on the unverified assumption that integration artifacts do not distort the data.
Authors: We acknowledge that the manuscript describes the integration mechanisms (identifier resolution, on-chain recovery, and incremental updates) but does not report quantitative validation metrics such as matching success rates, mismatch frequencies, or ground-truth completeness checks. This omission weakens the support for the completeness claims. In the revised version we will add a new subsection titled 'Validation of Integration Pipeline' (placed after the data model description) that reports: (i) success rates for cross-source identifier matching (e.g., percentage of markets successfully linked between off-chain metadata and on-chain records), (ii) observed mismatch frequencies and resolution procedures, (iii) missing-record detection rates via on-chain recovery, and (iv) results of ground-truth completeness audits on sampled subsets (e.g., manual verification of 500–1,000 randomly selected markets and oracle events). We will also discuss any residual limitations and their potential impact on the NBA and CPI case studies. These additions will make the load-bearing assumptions explicit and verifiable. revision: yes
Circularity Check
No circularity: data construction paper with no derivations or fitted predictions
full rationale
The paper presents a dataset construction pipeline for Polymarket prediction markets, integrating metadata, trades, and oracle events via identifier resolution and incremental updates. No mathematical derivations, equations, fitted parameters, or 'predictions' are claimed that could reduce to the input data by construction. The output is the dataset and descriptive analyses, not a result forced by self-definition or self-citation chains. The work is self-contained as a data engineering effort without load-bearing theoretical steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-chain and on-chain data sources share consistent identifiers that allow accurate linkage without substantial loss or duplication.
Reference graph
Works this paper leans on
-
[1]
Kalshi and the rise of macro markets
Anthony M Diercks, Jared Dean Katz, and Jonathan H Wright. Kalshi and the rise of macro markets. Technical report, National Bureau of Economic Research, 2026
2026
-
[2]
Price discovery and trading in modern prediction markets.A vailable at SSRN 5331995, 2026
Hunter Ng, Lin Peng, Yubo Tao, and Dexin Zhou. Price discovery and trading in modern prediction markets.A vailable at SSRN 5331995, 2026
2026
-
[3]
Financial and informa- tional integration through oracle networks
Lin William Cong, Eswar S Prasad, and Daniel Rabetti. Financial and informa- tional integration through oracle networks. Technical report, National Bureau of Economic Research, 2025
2025
-
[4]
Ex-graph: A pioneering dataset bridging ethereum and x.arXiv preprint arXiv:2310.01015, 2023
Qian Wang, Zhen Zhang, Zemin Liu, Shengliang Lu, Bingqiao Luo, and Bingsheng He. Ex-graph: A pioneering dataset bridging ethereum and x.arXiv preprint arXiv:2310.01015, 2023
-
[5]
Nft1000: A cross-modal dataset for non- fungible token retrieval
Shuxun Wang, Yunfei Lei, Ziqi Zhang, Wei Liu, Haowei Liu, Li Yang, Bing Li, Wenjuan Li, Jin Gao, and Weiming Hu. Nft1000: A cross-modal dataset for non- fungible token retrieval. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2214–2222, 2024
2024
-
[6]
Token spammers, rug pulls, and sniper bots: An analysis of the ecosystem of tokens in ethereum and in the binance smart chain ({ { { { {BNB} } } } })
Federico Cernera, Massimo La Morgia, Alessandro Mei, and Francesco Sassi. Token spammers, rug pulls, and sniper bots: An analysis of the ecosystem of tokens in ethereum and in the binance smart chain ({ { { { {BNB} } } } }). In32nd USENIX security symposium (USENIX security 23), pages 3349–3366, 2023
2023
-
[7]
Alberto Maria Mongardini and Alessandro Mei. A midsummer meme’s dream: Investigating market manipulations in the meme coin ecosystem.arXiv preprint arXiv:2507.01963, 2025
-
[8]
SoK : Market microstructure for decentralized prediction markets ( DePMs )
Nahid Rahman, Joseph Al-Chami, and Jeremy Clark. Sok: Market microstructure for decentralized prediction markets (depms).arXiv preprint arXiv:2510.15612, 2025
-
[9]
Laurie E Cutting, Sarah S Hughes-Berheim, Paul M Johnson, Hiba Baroud, and Brett Goldstein. Are betting markets better than polling in predicting political elections?arXiv preprint arXiv:2507.08921, 2025
-
[10]
Political uncertainty and credit risk: The role of event markets in forecasting ukraine’s sovereign spreads.A vailable at SSRN 5163719, 2025
Zachary McGurk and Mary J Becker. Political uncertainty and credit risk: The role of event markets in forecasting ukraine’s sovereign spreads.A vailable at SSRN 5163719, 2025
2025
-
[11]
Under pressure? central bank independence meets blockchain prediction markets
Barry Eichengreen, Ganesh Viswanath-Natraj, Junxuan Wang, and Zijie Wang. Under pressure? central bank independence meets blockchain prediction markets. Central Bank Independence Meets Blockchain Prediction Markets (July 26, 2025), 2025
2025
-
[12]
arXiv preprint arXiv:2508.03474 , year =
Oriol Saguillo, Vahid Ghafouri, Lucianna Kiffer, and Guillermo Suarez-Tangil. Unravelling the probabilistic forest: Arbitrage in prediction markets.arXiv preprint arXiv:2508.03474, 2025
-
[13]
Agostino Capponi, Alfio Gliozzo, and Brian Zhu. Semantic trading: Agentic ai for clustering and relationship discovery in prediction markets.arXiv preprint arXiv:2512.02436, 2025
-
[14]
Onchain reputation: Introducing dynamic incentives into distributed networks.A vailable at SSRN 4540862, 2023
Lin William Cong and Luofeng Zhou. Onchain reputation: Introducing dynamic incentives into distributed networks.A vailable at SSRN 4540862, 2023
2023
-
[15]
A primer on oracle economics.Journal of Corporate Finance, 94:102800, 2025
Lin William Cong, Liam Fox, Siguang Li, and Luofeng Zhou. A primer on oracle economics.Journal of Corporate Finance, 94:102800, 2025
2025
-
[16]
A brief introduction to blockchain economics
Long Chen, Lin William Cong, and Yizhou Xiao. A brief introduction to blockchain economics. InInformation for efficient decision making: Big data, blockchain and relevance, pages 1–40. World Scientific, 2021
2021
-
[17]
Diablo: A benchmark suite for blockchains
Vincent Gramoli, Rachid Guerraoui, Andrei Lebedev, Chris Natoli, and Gauthier Voron. Diablo: A benchmark suite for blockchains. InProceedings of the Eighteenth European Conference on Computer Systems, pages 540–556, 2023
2023
-
[18]
Multi-chain graphs of graphs: A new approach to analyzing blockchain datasets.Advances in Neural Information Processing Systems, 37:28490–28514, 2024
Bingqiao Luo, Zhen Zhang, Qian Wang, and Bingsheng He. Multi-chain graphs of graphs: A new approach to analyzing blockchain datasets.Advances in Neural Information Processing Systems, 37:28490–28514, 2024
2024
-
[19]
Zipzap: Efficient training of language models for large-scale fraud detection on blockchain
Sihao Hu, Tiansheng Huang, Ka-Ho Chow, Wenqi Wei, Yanzhao Wu, and Ling Liu. Zipzap: Efficient training of language models for large-scale fraud detection on blockchain. InProceedings of the ACM Web Conference 2024, pages 2807–2816, 2024
2024
-
[20]
Graph neural networks for bridge swap link prediction in uniswap v3
Qingran Zhou, Eric Liu, and Alessio Brini. Graph neural networks for bridge swap link prediction in uniswap v3. InProceedings of the 6th ACM International Conference on AI in Finance, pages 247–255, 2025
2025
-
[21]
Money never sleeps: Maximizing liquidity mining yields in decentralized finance
Wangze Ni, Zhao Yiwei, Weijie Sun, Lei Chen, Peng Cheng, Chen Jason Zhang, and Xuemin Lin. Money never sleeps: Maximizing liquidity mining yields in decentralized finance. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2248–2259, 2024
2024
-
[22]
Sok: Decentralized finance (defi) attacks
Liyi Zhou, Xihan Xiong, Jens Ernstberger, Stefanos Chaliasos, Zhipeng Wang, Ye Wang, Kaihua Qin, Roger Wattenhofer, Dawn Song, and Arthur Gervais. Sok: Decentralized finance (defi) attacks. In2023 IEEE Symposium on Security and Privacy (SP), pages 2444–2461. IEEE, 2023
2023
-
[23]
Security perceptions of users in stablecoins: Advantages and risks within the cryptocurrency ecosystem
Maggie Yongqi Guan, Yaman Yu, Tanusree Sharma, Molly Zhuangtong Huang, Kaihua Qin, Yang Wang, and Kanye Ye Wang. Security perceptions of users in stablecoins: Advantages and risks within the cryptocurrency ecosystem. In2025 IEEE Symposium on Security and Privacy (SP), pages 2753–2771. IEEE, 2025
2025
-
[24]
The Price of Interoperability: Exploring Cross-Chain Bridges and Their Economic Consequences
Yiyue Cao, Mingzhe Zheng, Lin William Cong, Siguang Li, and Xuechao Wang. The price of interoperability: Exploring cross-chain bridges and their economic consequences.arXiv preprint arXiv:2604.03083, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Stop pulling my rug: Exposing rug pull risks in crypto token to investors
Yuanhang Zhou, Jingxuan Sun, Fuchen Ma, Yuanliang Chen, Zhen Yan, and Yu Jiang. Stop pulling my rug: Exposing rug pull risks in crypto token to investors. InProceedings of the 46th International Conference on Software Engi- neering: Software Engineering in Practice, pages 228–239, 2024
2024
-
[26]
Sok: A taxonomic analysis of defi rug pulls: Types, dataset, and tool assessment.Proceedings of the ACM on Software Engineering, 2(ISSTA):550–572, 2025
Dianxiang Sun, Wei Ma, Liming Nie, and Yang Liu. Sok: A taxonomic analysis of defi rug pulls: Types, dataset, and tool assessment.Proceedings of the ACM on Software Engineering, 2(ISSTA):550–572, 2025
2025
-
[27]
Characterizing ethereum address poisoning attack
Shixuan Guan and Kai Li. Characterizing ethereum address poisoning attack. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communi- cations Security, pages 986–1000, 2024
2024
-
[28]
Polymarket Documentation
Polymarket. Polymarket Documentation. https://docs.polymarket.com/, 2026. Accessed: 2026-04-07
2026
-
[29]
Polygon pos chain explorer, 2026
Polygonscan. Polygon pos chain explorer, 2026. Accessed: 2026-04-07
2026
-
[30]
Polymarket CTF exchange
Polymarket. Polymarket CTF exchange. https://github.com/polymarket/ctf- exchange, 2022. Accessed: 2026-04-13
2022
-
[31]
Negrisk CTF adapter: Multi-outcome market contracts
Polymarket. Negrisk CTF adapter: Multi-outcome market contracts. https: //github.com/polymarket/neg-risk-ctf-adapter, 2023. Accessed: 2026-04-13; Re- lease v2.0.0
2023
-
[32]
UMA: A decentralized optimistic oracle
Risk Labs Foundation. UMA: A decentralized optimistic oracle. https://uma.xyz/,
-
[33]
Accessed: 2026-04-13
2026
-
[34]
Polymarket. Fees. https://docs.polymarket.com/trading/fees, 2026. Polymarket Documentation, accessed April 10, 2026
2026
-
[35]
Polygon transaction record for the first observed non-zero fee trade on polymarket, 2026
PolygonScan. Polygon transaction record for the first observed non-zero fee trade on polymarket, 2026. Transaction hash: 0xb05478...f8fd88c. Accessed: 2026-04-10
2026
-
[36]
Live sports prediction markets
Polymarket. Live sports prediction markets. https://polymarket.com/sports/live,
-
[37]
Accessed: 2026-04-13; Real-time market data subject to change
2026
-
[38]
The isotonic regression problem and its dual.Journal of the American Statistical Association, 67(337):140–147, 1972
Richard E Barlow and Hugh D Brunk. The isotonic regression problem and its dual.Journal of the American Statistical Association, 67(337):140–147, 1972
1972
-
[39]
Consumer price index (cpi)
International Monetary Fund. Consumer price index (cpi). https://data.imf.org/ en/datasets/IMF.STA:CPI, 2026. IMF Data dataset page. Accessed: 2026-04-13
2026
-
[40]
Inflation nowcasting
Federal Reserve Bank of Cleveland. Inflation nowcasting. https://www. clevelandfed.org/indicators-and-data/inflation-nowcasting, 2026. Center for Inflation Research; updated each business day. Accessed: 2026-04-07
2026
-
[41]
Bureau of Labor Statistics
U.S. Bureau of Labor Statistics. Schedule of releases for the consumer price index. https://www.bls.gov/schedule/news_release/cpi.htm, 2026. Accessed: 2026-04-13. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.