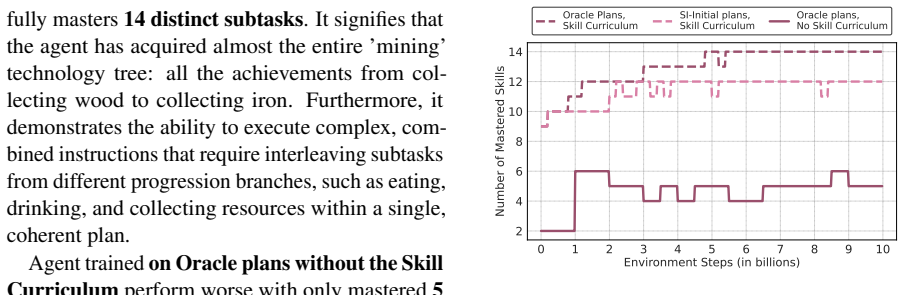
Recognition: unknown
Self-Guided Plan Extraction for Instruction-Following Tasks with Goal-Conditional Reinforcement Learning
Pith reviewed 2026-05-10 00:00 UTC · model grok-4.3
The pith
A co-training loop lets a language model and RL agent jointly improve plans for following instructions without manual labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
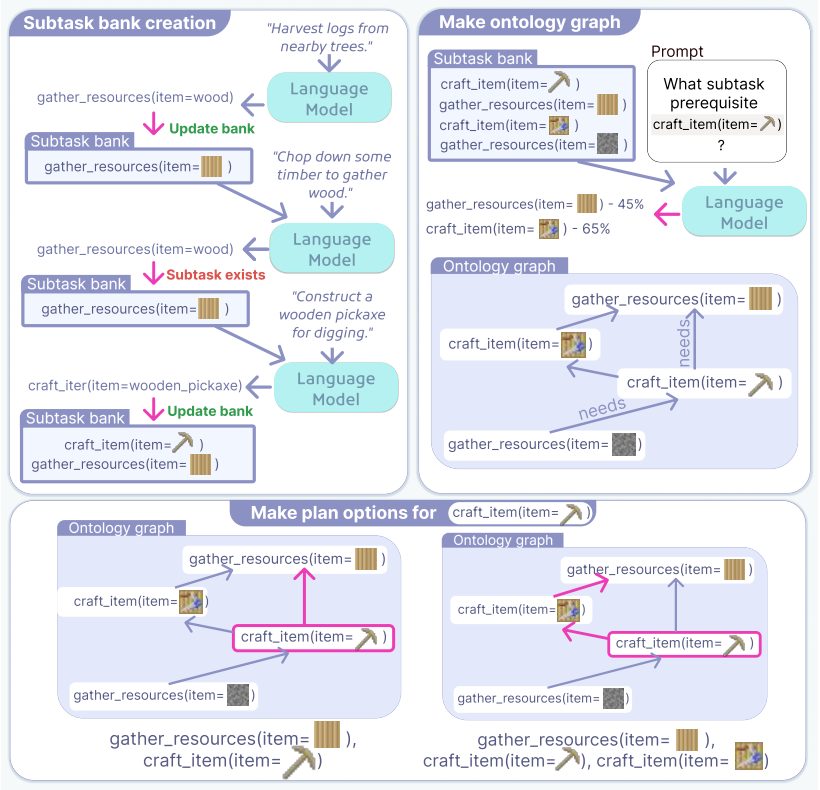
SuperIgor uses iterative co-training in which an RL agent learns to follow plans generated by a language model, and the language model then adapts those plans based on the agent's feedback and preferences. This mutual improvement process allows the system to produce effective high-level plans without predefined subtasks or manual annotation, leading to agents that adhere more strictly to given instructions and generalize better to unseen ones in stochastic environments.
What carries the argument
The iterative co-training loop in which the goal-conditional RL agent executes language-model plans and supplies feedback that lets the model revise the plans.
If this is right
- Agents trained under this loop adhere to instructions more strictly than those trained with baseline methods.
- The resulting agents generalize effectively to previously unseen instructions.
- High-level plans can be generated and refined without requiring manual dataset annotation or predefined subtasks.
- The framework operates successfully in environments that contain rich dynamics and stochasticity.
Where Pith is reading between the lines
- The same feedback-driven refinement might be applied to other planning domains where execution outcomes can be observed directly.
- Reducing reliance on labeled data could make instruction-following systems easier to deploy in new environments.
- Longer training loops might reveal whether the improvements continue or plateau after several rounds of co-training.
Load-bearing premise
The iterative co-training loop between the RL agent and language model produces reliable improvements in plan quality without external supervision or manual annotation.
What would settle it
Running SuperIgor agents and baseline agents side by side in the same stochastic environments and finding no measurable gain in instruction adherence or generalization to new instructions would show the claimed advantage does not hold.
Figures








read the original abstract
We introduce SuperIgor, a framework for instruction-following tasks. Unlike prior methods that rely on predefined subtasks, SuperIgor enables a language model to generate and refine high-level plans through a self-learning mechanism, reducing the need for manual dataset annotation. Our approach involves iterative co-training: an RL agent is trained to follow the generated plans, while the language model adapts and modifies these plans based on RL feedback and preferences. This creates a feedback loop where both the agent and the planner improve jointly. We validate our framework in environments with rich dynamics and stochasticity. Results show that SuperIgor agents adhere to instructions more strictly than baseline methods, while also demonstrating strong generalization to previously unseen instructions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SuperIgor, a framework for instruction-following tasks in which a language model generates and iteratively refines high-level plans via a self-guided co-training loop with a goal-conditional RL agent. The RL agent is trained to execute the LM-generated plans while supplying feedback and preferences that allow the LM to adapt the plans, reducing reliance on manual annotation. The authors claim that the resulting agents adhere more strictly to instructions than baselines and generalize better to previously unseen instructions in environments with rich dynamics and stochasticity.
Significance. If the central claims hold, the work would demonstrate a viable path toward annotation-light instruction following by closing the loop between plan generation and execution feedback. The joint improvement of planner and policy is a potentially useful direction for scaling RL-LM hybrids in stochastic settings.
major comments (3)
- [Abstract] Abstract: the claims of stricter instruction adherence and strong generalization to unseen instructions are asserted without any reported metrics, baselines, statistical tests, error bars, or ablation results, so it is impossible to evaluate whether the improvements are load-bearing or merely apparent.
- [Method] Method description of the co-training loop: the manuscript does not specify whether the RL reward contains an auxiliary term for plan fidelity, coverage, or preference alignment beyond raw task completion. Without such a term (or a held-out preference model), the feedback loop risks rewarding short or degenerate plans that the current policy can execute easily rather than genuinely higher-quality plans, undermining the self-improvement claim.
- [Experiments] Experimental validation section: no details are supplied on environment stochasticity levels, number of trials, how 'unseen instructions' were constructed, or how plan quality was measured independently of task success, making it impossible to assess whether reported gains reflect true generalization or training-loop artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to provide the requested clarifications and details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of stricter instruction adherence and strong generalization to unseen instructions are asserted without any reported metrics, baselines, statistical tests, error bars, or ablation results, so it is impossible to evaluate whether the improvements are load-bearing or merely apparent.
Authors: We agree that the abstract, being a high-level summary, does not include quantitative metrics. The full manuscript reports these results in the Experiments section, including baseline comparisons, adherence and generalization metrics, and statistical details. In the revision, we have updated the abstract to concisely reference the key quantitative improvements (e.g., adherence rates and generalization gains) while preserving brevity. All claims remain grounded in the reported experiments. revision: yes
-
Referee: [Method] Method description of the co-training loop: the manuscript does not specify whether the RL reward contains an auxiliary term for plan fidelity, coverage, or preference alignment beyond raw task completion. Without such a term (or a held-out preference model), the feedback loop risks rewarding short or degenerate plans that the current policy can execute easily rather than genuinely higher-quality plans, undermining the self-improvement claim.
Authors: This is a valid concern. The original description focused on the goal-conditional reward for task completion, with LM adaptation driven by RL-derived preferences. We have revised the Method section to explicitly define the reward function, adding an auxiliary term for plan fidelity and coverage derived from the preference signals. This term penalizes degenerate plans and encourages alignment with high-quality plans. We have also added pseudocode and a diagram of the co-training loop for clarity. revision: yes
-
Referee: [Experiments] Experimental validation section: no details are supplied on environment stochasticity levels, number of trials, how 'unseen instructions' were constructed, or how plan quality was measured independently of task success, making it impossible to assess whether reported gains reflect true generalization or training-loop artifacts.
Authors: We acknowledge that additional experimental details are needed for reproducibility and assessment. The revised Experiments section now specifies the stochasticity levels (e.g., transition noise parameters), number of trials with error bars across random seeds, the construction of unseen instructions (novel goal-constraint combinations held out from training), and independent plan quality metrics (coverage and fidelity scores computed separately from task success). We have included ablations confirming that gains arise from the co-training loop rather than artifacts. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents SuperIgor as an iterative co-training framework in which an RL agent follows LM-generated plans and supplies feedback for plan refinement. The reported gains in instruction adherence and generalization to unseen instructions are framed as empirical outcomes from this joint process, benchmarked against baselines in stochastic environments. No equations, parameter fits, or self-citations are exhibited in the provided text that reduce the performance claims to the training loop by construction; the loop is offered as a method whose effectiveness is measured externally rather than presupposed. The derivation therefore remains self-contained against the stated validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2403.12037 , year=
Minedreamer: Learning to follow instructions via chain-of-imagination for simulated-world control , author=. arXiv preprint arXiv:2403.12037 , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Minedojo: Building open-ended embodied agents with internet-scale knowledge , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Proceedings of ECAI 2024, the 27th European Conference on Artificial Intelligence , series=
Instruction Following with Goal-Conditioned Reinforcement Learning in Virtual Environments , author=. Proceedings of ECAI 2024, the 27th European Conference on Artificial Intelligence , series=. 2024 , doi=
2024
-
[4]
Advances in Neural Information Processing Systems , volume=
Video pretraining (vpt): Learning to act by watching unlabeled online videos , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Steve-1: A generative model for text-to-behavior in minecraft , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
2025 , doi=
Li, Muyao and Wang, Zihao and He, Kaichen and Ma, Xiaojian and Liang, Yitao , booktitle=. 2025 , doi=
2025
-
[7]
Sawyer, Daniel Slater, David Reichert, Davide Vercelli, Demis Hassabis, Drew A
SIMA 2: A Generalist Embodied Agent for Virtual Worlds , author=. arXiv preprint arXiv:2512.04797 , year=
-
[8]
International Conference on Learning Representations , year=
Grounded Language Learning Fast and Slow , author=. International Conference on Learning Representations , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
STEVE-1: A Generative Model for Text-to-Behavior in Minecraft , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[10]
Foundation Models for Decision Making Workshop at NeurIPS 2023 , year=
Skill Reinforcement Learning and Planning for Open-World Long-Horizon Tasks , author=. Foundation Models for Decision Making Workshop at NeurIPS 2023 , year=
2023
-
[11]
Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory , author=. arXiv preprint arXiv:2305.17144 , year=
-
[12]
International Conference on Learning Representations , year=
GROOT: Learning to Follow Instructions by Watching Gameplay Videos , author=. International Conference on Learning Representations , year=
-
[13]
Forty-second International Conference on Machine Learning , year=
Founder: Grounding foundation models in world models for open-ended embodied decision making , author=. Forty-second International Conference on Machine Learning , year=
-
[14]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Alfred: A benchmark for interpreting grounded instructions for everyday tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[15]
Advances in Neural Information Processing Systems , volume=
SILG: The Multi-environment Symbolic Interactive Language Grounding Benchmark , author=. Advances in Neural Information Processing Systems , volume=. 2021 , url=
2021
-
[16]
C raf T ext Benchmark: Advancing Instruction Following in Complex Multimodal Open-Ended World
Volovikova, Zoya and Gorbov, Gregory and Kuderov, Petr and Panov, Aleksandr and Skrynnik, Alexey. C raf T ext Benchmark: Advancing Instruction Following in Complex Multimodal Open-Ended World. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1267
-
[17]
Manolis Savva and Jitendra Malik and Devi Parikh and Dhruv Batra and Abhishek Kadian and Oleksandr Maksymets and Yili Zhao and Erik Wijmans and Bhavana Jain and Julian Straub and Jia Liu and Vladlen Koltun , title =. 2019. 2019 , url =. doi:10.1109/ICCV.2019.00943 , timestamp =
-
[18]
arXiv preprint arXiv:2510.23148 , year=
Adapting Interleaved Encoders with PPO for Language-Guided Reinforcement Learning in BabyAI , author=. arXiv preprint arXiv:2510.23148 , year=
-
[19]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[20]
2019 , eprint=
CraftAssist: A Framework for Dialogue-enabled Interactive Agents , author=. 2019 , eprint=
2019
-
[21]
Proceedings of the NeurIPS 2022 Competitions Track , pages =
Interactive Grounded Language Understanding in a Collaborative Environment: Retrospective on Iglu 2022 Competition , author =. Proceedings of the NeurIPS 2022 Competitions Track , pages =. 2022 , editor =
2022
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Touchdown: Natural Language Navigation and Spatial Reasoning in Visual Street Environments , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2019 , doi=
2019
-
[23]
Executing Instructions in Situated Collaborative Interactions , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=. 2019 , doi=
2019
-
[24]
Proceedings of the 41st International Conference on Machine Learning , series=
Learning to Model the World With Language , author=. Proceedings of the 41st International Conference on Machine Learning , series=. 2024 , url=
2024
-
[25]
BabyAI: A platform to study the sample efficiency of grounded language learning
Babyai: A platform to study the sample efficiency of grounded language learning , author=. arXiv preprint arXiv:1810.08272 , year=
-
[26]
Proceedings of the 38th International Conference on Machine Learning , series=
Grounding Language to Entities and Dynamics for Generalization in Reinforcement Learning , author=. Proceedings of the 38th International Conference on Machine Learning , series=. 2021 , url=
2021
-
[27]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[28]
Advances in Neural Information Processing Systems , volume=
Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Semantic HELM: A Human-Readable Memory for Reinforcement Learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[30]
IEEE Robotics and Automation Letters , pages=
Interactive Language: Talking to Robots in Real Time , author=. IEEE Robotics and Automation Letters , pages=. 2024 , month=. doi:10.1109/LRA.2023.3295255 , url=
-
[31]
International Conference on Learning Representations , year=
RTFM: Generalising to New Environment Dynamics via Reading , author=. International Conference on Learning Representations , year=
-
[32]
EMNLP 2021 Workshop on Novel Ideas in Learning-to-Learn through Interaction , year=
Embodied BERT: A Transformer Model for Embodied, Language-guided Visual Task Completion , author=. EMNLP 2021 Workshop on Novel Ideas in Learning-to-Learn through Interaction , year=
2021
-
[33]
Nature , volume=
Mastering diverse control tasks through world models , author=. Nature , volume=. 2025 , doi=
2025
-
[34]
arXiv preprint arXiv:2409.03402 , year=
Game On: Towards Language Models as RL Experimenters , author=. arXiv preprint arXiv:2409.03402 , year=
-
[35]
International Conference on Learning Representations , year=
Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks , author=. International Conference on Learning Representations , year=
-
[36]
International conference on machine learning , pages=
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[37]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Few-shot Subgoal Planning with Language Models , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[38]
Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=
Pragmatic Instruction Following and Goal Assistance via Cooperative Language-Guided Inverse Planning , author=. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=. 2024 , doi=
2024
-
[39]
Proceedings of The 8th Conference on Robot Learning , series=
Autonomous Improvement of Instruction Following Skills via Foundation Models , author=. Proceedings of The 8th Conference on Robot Learning , series=. 2025 , url=
2025
-
[40]
Proceedings of The 6th Conference on Robot Learning , series=
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author=. Proceedings of The 6th Conference on Robot Learning , series=. 2023 , url=
2023
-
[41]
and Bell, Peter and Storkey, Amos , booktitle=
Han, Dongge and McInroe, Trevor and Jelley, Adam and Albrecht, Stefano V. and Bell, Peter and Storkey, Amos , booktitle=. 2025 , url=
2025
-
[42]
Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
Visually-Grounded Planning without Vision: Language Models Infer Detailed Plans from High-level Instructions , author=. Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=. 2020 , doi=
2020
-
[43]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
DANLI: Deliberative Agent for Following Natural Language Instructions , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=. 2022 , doi=
2022
-
[44]
International Conference on Learning Representations , year=
True Knowledge Comes from Practice: Aligning Large Language Models with Embodied Environments via Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[45]
Advances in Neural Information Processing Systems , volume=
Describe, Explain, Plan and Select: Interactive Planning with LLMs Enables Open-World Multi-Task Agents , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.