Recognition: unknown
Exploiting LLM-as-a-Judge Disposition on Free Text Legal QA via Prompt Optimization
Pith reviewed 2026-05-10 01:06 UTC · model grok-4.3
The pith
Automatic prompt optimization with lenient LLM judge feedback outperforms human design and transfers better to strict judges on legal QA tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Algorithmically optimizing task prompts on training data using LLM-as-a-Judge feedback can outperform human-centered prompt design for free-text legal question answering, and the judge's disposition during optimization determines prompt generalizability: lenient judges supply permissive feedback that produces broadly applicable prompts, while strict judges supply restrictive feedback that leads to judge-specific overfitting.
What carries the argument
The iterative prompt refinement process driven by feedback from LLM judges, which refines task instructions to maximize alignment with judge scores on the LEXam benchmark.
If this is right
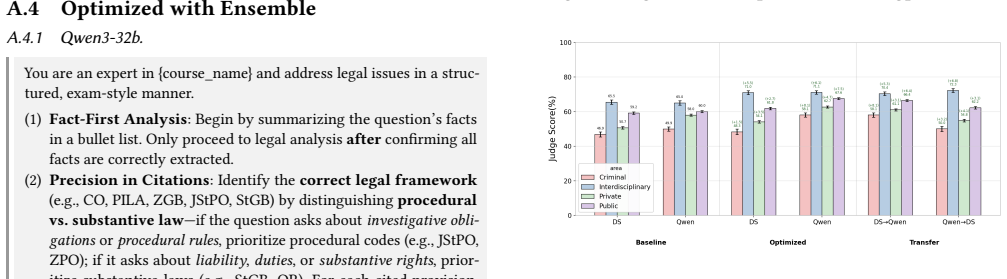
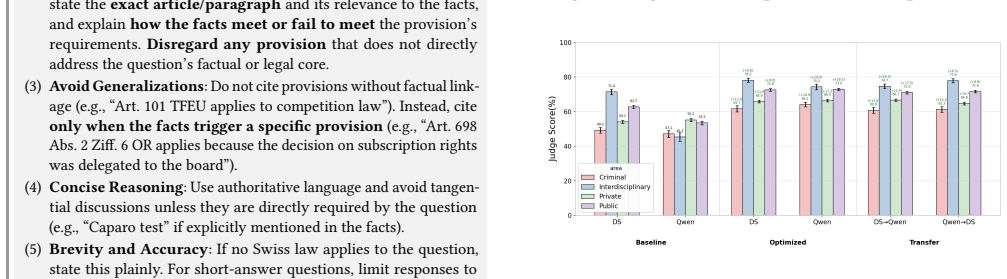
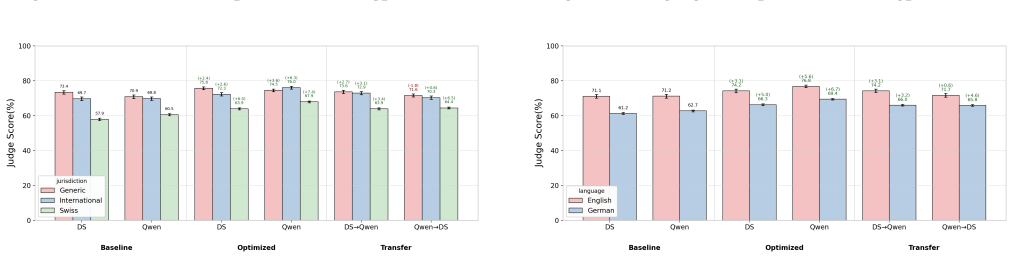
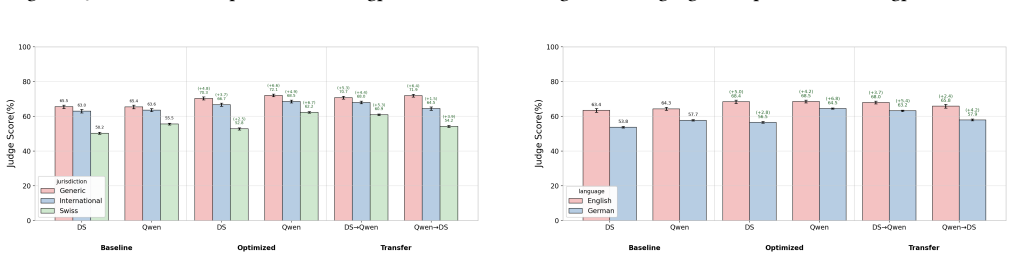
- Optimized prompts achieve higher evaluation scores on the LEXam benchmark than the human-designed baseline across the tested task models.
- Lenient judge feedback during optimization produces higher and more consistent performance gains than strict feedback.
- Prompts refined with lenient feedback transfer more successfully when evaluated by strict judges than prompts refined with strict feedback do when evaluated by lenient judges.
- Lenient feedback yields prompts with broader applicability while strict feedback produces prompts that overfit to the optimizing judge.
Where Pith is reading between the lines
- The same optimization strategy could reduce reliance on human prompt engineering in other domains that use LLM judges for open-ended answers.
- Selecting a lenient judge for the optimization phase may be a practical default when the goal is prompt reuse across multiple evaluators.
- Combining feedback from both lenient and strict judges in a single optimization run might balance specificity and transferability.
Load-bearing premise
Results obtained by applying the optimization process to the LEXam benchmark with the two specific judges and task models will generalize to other judges, models, and legal QA tasks.
What would settle it
Applying the same optimization process to a different legal QA dataset or with new LLM judges and finding that the resulting prompts no longer outperform the human baseline or lose their cross-judge transfer advantage.
Figures






read the original abstract
This work explores the role of prompt design and judge selection in LLM-as-a-Judge evaluations of free text legal question answering. We examine whether automatic task prompt optimization improves over human-centered design, whether optimization effectiveness varies by judge feedback style, and whether optimized prompts transfer across judges. We systematically address these questions on the LEXam benchmark by optimizing task prompts using the ProTeGi method with feedback from two judges (Qwen3-32B, DeepSeek-V3) across four task models, and then testing cross-judge transfer. Automatic optimization consistently outperforms the baseline, with lenient judge feedback yielding higher and more consistent gains than strict judge feedback. Prompts optimized with lenient feedback transfer better to strict judges than the reverse direction. Analysis reveals that lenient judges provide permissive feedback, yielding prompts with broader applicability, whereas strict judges produce restrictive feedback, leading to judge-specific overfitting. Our findings demonstrate algorithmically optimizing prompts on training data can outperform human-centered prompt design and that judges' dispositions during optimization shape prompt generalizability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that automatic prompt optimization via ProTeGi on the LEXam legal QA benchmark outperforms human-designed baselines across four task models. It further claims that optimization using lenient judge feedback (Qwen3-32B, DeepSeek-V3) produces higher and more consistent gains than strict feedback, and that lenient-optimized prompts transfer better to strict judges than the reverse, because lenient judges supply permissive feedback enabling broader applicability while strict judges induce restrictive feedback and judge-specific overfitting.
Significance. If the empirical patterns hold under statistical scrutiny, the work is significant for LLM-as-a-Judge research and prompt engineering in specialized domains. It supplies concrete evidence that judge disposition during optimization affects downstream prompt robustness and cross-judge transfer, which has direct implications for reliable evaluation pipelines in legal AI. The systematic transfer experiments and use of an existing optimization method are strengths.
major comments (2)
- [§4.2 and Table 2] §4.2 and Table 2: the central claim that lenient feedback yields 'higher and more consistent gains' and better transfer rests on results from only two judges (Qwen3-32B, DeepSeek-V3); without additional judges or an ablation varying judge strictness independently of model identity, the disposition-transfer asymmetry risks being idiosyncratic to these two models on LEXam rather than a general property of LLM-as-a-Judge systems.
- [§4.3 and Table 3] §4.3 and Table 3: the reported performance deltas and transfer asymmetries lack error bars, number of optimization runs, random seeds, or statistical significance tests; without these controls the assertions of 'consistent outperformance' and 'more consistent gains' cannot be evaluated for reliability.
minor comments (3)
- [Abstract] Abstract: the four task models are not named, hindering reproducibility.
- [§3.1] §3.1: the operational definitions of 'lenient' versus 'strict' judge feedback would benefit from concrete example feedback snippets.
- [Figure 1] Figure 1: the optimization pipeline diagram is clear but omits the exact prompt templates passed to ProTeGi.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which helps strengthen the robustness of our empirical claims. We address each major comment below and commit to revisions that directly incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4.2 and Table 2] §4.2 and Table 2: the central claim that lenient feedback yields 'higher and more consistent gains' and better transfer rests on results from only two judges (Qwen3-32B, DeepSeek-V3); without additional judges or an ablation varying judge strictness independently of model identity, the disposition-transfer asymmetry risks being idiosyncratic to these two models on LEXam rather than a general property of LLM-as-a-Judge systems.
Authors: We acknowledge that experiments limited to two judges constrain the generalizability of the observed asymmetry. Qwen3-32B and DeepSeek-V3 were selected specifically because preliminary evaluations on LEXam showed they produce distinctly lenient feedback relative to other models tested. To address the concern, the revised manuscript will add results from at least two additional judges exhibiting contrasting feedback dispositions. We will also expand the discussion of judge selection criteria and include an analysis attempting to isolate strictness effects from model identity where feasible. revision: yes
-
Referee: [§4.3 and Table 3] §4.3 and Table 3: the reported performance deltas and transfer asymmetries lack error bars, number of optimization runs, random seeds, or statistical significance tests; without these controls the assertions of 'consistent outperformance' and 'more consistent gains' cannot be evaluated for reliability.
Authors: We agree that the current presentation lacks the statistical controls needed to substantiate claims of consistency. In the revised version we will update §4.3 and Table 3 to report means and standard deviations computed over multiple independent optimization runs, explicitly state the number of runs and random seeds used, and include statistical significance tests (e.g., paired t-tests with p-values) for all reported performance deltas and transfer asymmetries. revision: yes
Circularity Check
No circularity: empirical comparison on fixed benchmark
full rationale
The paper is a purely experimental study comparing prompt optimization performance on the LEXam benchmark using the ProTeGi method with two fixed judges (Qwen3-32B, DeepSeek-V3) and four task models. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. Central claims rest on direct empirical measurements of accuracy gains and transfer, which are falsifiable against the reported runs and independent of any self-referential loop. This is the expected non-finding for an applied empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Callison-Burch, Miles Osborne, and Philipp Koehn
C. Callison-Burch, Miles Osborne, and Philipp Koehn. 2006. Re-evaluating the Role of Bleu in Machine Translation Research. 249–256 pages. https: //aclanthology.org/E06-1032/
2006
-
[2]
Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, et al
I. Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, et al. 2022. LexGLUE: A Benchmark Dataset for Legal Language Understanding in English. 4310– 4330 pages. doi:10.18653/v1/2022.acl-long.297
-
[3]
Can Large Language Models Be an Alternative to Human Evaluations?
C. Chiang and Hung-yi Lee. 2023. Can Large Language Models Be an Alternative to Human Evaluations? 15607–15631 pages. doi:10.18653/v1/2023.acl-long.870
-
[4]
arXiv preprint arXiv:2505.12864 , year=
Y. Fan, Jingwei Ni, Jakob Merane, Yang Tian, et al. 2026. LEXam: Benchmarking Legal Reasoning on 340 Law Exams. arXiv:2505.12864 [cs.CL] https://arxiv.org/ abs/2505.12864
-
[5]
Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, et al
Z. Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, et al . 2024. LawBench: Benchmarking Legal Knowledge of Large Language Models. 7933–7962 pages. doi:10.18653/v1/2024.emnlp-main.452
-
[6]
N. Guha, Julian Nyarko, Daniel Ho, Christopher Ré, et al . 2023. LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models. arXiv:2308.11462 [cs.CL] https://arxiv.org/abs/2308.11462
-
[7]
S. Han, Gilberto Titericz Junior, Tom Balough, and Wenfei Zhou. 2025. Judge’s Verdict: A Comprehensive Analysis of LLM Judge Capability Through Human Agreement. arXiv:2510.09738 [cs.CL] https://arxiv.org/abs/2510.09738
-
[8]
Kim, Jamin Shin, Yejin Cho, Joel Jang, et al
S. Kim, Jamin Shin, Yejin Cho, Joel Jang, et al. 2024. Prometheus: Inducing Fine- Grained Evaluation Capability in Language Models. https://openreview.net/ forum?id=8euJaTveKw
2024
-
[9]
C. Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. 74– 81 pages. https://aclanthology.org/W04-1013/
2004
-
[11]
Niklaus, Veton Matoshi, Pooja Rani, Andrea Galassi, et al
J. Niklaus, Veton Matoshi, Pooja Rani, Andrea Galassi, et al. 2023. LEXTREME: A Multi-Lingual and Multi-Task Benchmark for the Legal Domain. 3016–3054 pages. doi:10.18653/v1/2023.findings-emnlp.200
-
[12]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting on Association for Computational Linguistics(Philadelphia, Penn- sylvania)(ACL ’02). Association for Computational Linguistics, USA, 311–318. doi:10.3115/1073083.1073135
-
[13]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
R. Pryzant, Dan Iter, Jerry Li, Yin Lee, et al. 2023. Automatic Prompt Optimization with “Gradient Descent” and Beam Search. 7957–7968 pages. doi:10.18653/v1/ 2023.emnlp-main.494
-
[14]
Rakotonirina, Roberto Dessì, et al
N. Rakotonirina, Roberto Dessì, et al. 2023. Can discrete information extraction prompts generalize across language models? arXiv:2302.09865 [cs.CL] https: //arxiv.org/abs/2302.09865
-
[15]
Ramnath, Kang Zhou, Sheng Guan, Soumya Smruti Mishra, et al
K. Ramnath, Kang Zhou, Sheng Guan, Soumya Smruti Mishra, et al . 2025. A Systematic Survey of Automatic Prompt Optimization Techniques. 33078– 33110 pages. doi:10.18653/v1/2025.emnlp-main.1681
-
[16]
Shalawati, Arbi Haza Nasution, Winda Monika, Tatum Derin, et al
S. Shalawati, Arbi Haza Nasution, Winda Monika, Tatum Derin, et al. 2025. Be- yond BLEU: GPT-5, Human Judgment, and Classroom Validation for Multidimen- sional Machine Translation Evaluation. doi:10.20944/preprints202511.1292.v1
-
[17]
Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, et al
L. Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, et al. 2025. Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge. 292–314 pages. https: //aclanthology.org/2025.ijcnlp-long.18/
2025
- [18]
-
[19]
Large Language Models are not Fair Evaluators
P. Wang, Lei Li, Liang Chen, Zefan Cai, et al. 2024. Large Language Models are not Fair Evaluators. 9440–9450 pages. doi:10.18653/v1/2024.acl-long.511
-
[20]
Wang, Quan Liu, Zhenting Wang, Zichao Li, et al
Y. Wang, Quan Liu, Zhenting Wang, Zichao Li, et al. 2025. PromptBridge: Cross- Model Prompt Transfer for Large Language Models. arXiv:2512.01420 [cs.CL] https://arxiv.org/abs/2512.01420
-
[21]
Wataoka, Tsubasa Takahashi, and Ryokan Ri
K. Wataoka, Tsubasa Takahashi, and Ryokan Ri. 2024. Self-Preference Bias in LLM-as-a-Judge. https://openreview.net/forum?id=tLZZZIgPJX
2024
-
[22]
Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, et al
C. Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, et al . 2024. Large Language Models as Optimizers. https://openreview.net/forum?id=Bb4VGOWELI
2024
-
[23]
Zhang, Varsha Kishore, Felix Wu, Kilian Q
T. Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, et al. 2020. BERTScore: Evaluating Text Generation with BERT. https://openreview.net/forum?id= SkeHuCVFDr
2020
-
[24]
Zhen, Ervine Zheng, Jilong Kuang, and Geoffrey Jay Tso
C. Zhen, Ervine Zheng, Jilong Kuang, and Geoffrey Jay Tso. 2025. Enhancing LLM- as-a-Judge through Active-Sampling-based Prompt Optimization. 960–970 pages. doi:10.18653/v1/2025.acl-industry.67
-
[25]
Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, et al
L. Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, et al . 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. https://openreview.net/ forum?id=uccHPGDlao
2023
-
[26]
8 Daniel Yang, Yao-Hung Hubert Tsai, and Makoto Yamada
L. Zheng, Neel Guha, Javokhir Arifov, Sarah Zhang, et al. 2025. A Reasoning- Focused Legal Retrieval Benchmark. 169–193 pages. doi:10.1145/3709025.3712219
-
[27]
Art. 74 Abs. 2 Ziff. 2 OR
Y. Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, et al. 2023. Large Language Models are Human-Level Prompt Engineers. https://openreview.net/ forum?id=92gvk82DE- A Optimized Task Prompts All prompts use {course_name} and {question} as placehold- ers. The baseline prompt is presented once, followed by optimized prompts grouped by optimization judge...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.