Recognition: unknown
Coverage, Not Averages: Semantic Stratification for Trustworthy Retrieval Evaluation
Pith reviewed 2026-05-09 23:06 UTC · model grok-4.3
The pith
Retrieval evaluation metrics are unreliable unless query sets cover the full semantic structure of the corpus instead of averaging over incomplete samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
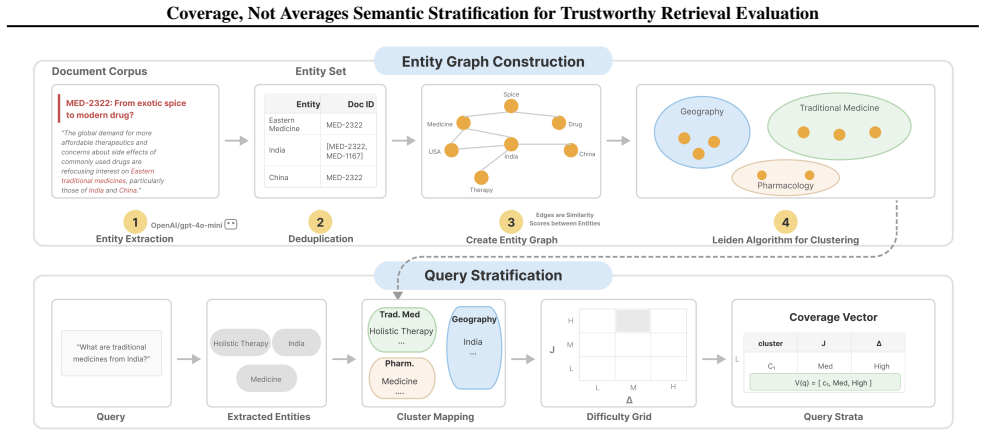
Retrieval evaluation is a statistical estimation task whose accuracy is bounded by the semantic coverage of the query set. Semantic stratification solves the coverage problem by partitioning the corpus into an interpretable global space of entity-based document clusters and systematically generating queries for every missing stratum, thereby delivering formal semantic coverage guarantees across retrieval regimes together with interpretable visibility into failure modes.
What carries the argument
Semantic stratification, which organizes documents into entity-based clusters to create an interpretable global semantic space and generates queries for the missing strata.
If this is right
- Stratified evaluation supplies formal semantic coverage guarantees that hold across different retrieval methods and regimes.
- Cluster-level analysis identifies structural signals that explain observed variance in retrieval performance.
- The new metrics are more stable than aggregate averages computed on heuristically chosen queries.
- Decision-making about which retrieval method to use in RAG pipelines becomes more trustworthy because failure modes are localized.
Where Pith is reading between the lines
- Evaluation benchmarks could be generated automatically from any target corpus rather than relying on fixed external query collections.
- The same stratification approach might be extended to track how coverage changes when the corpus is updated over time.
- Similar coverage-based diagnostics could be applied to other stages of retrieval-augmented pipelines such as passage ranking or answer generation.
Load-bearing premise
That grouping documents by entities produces a complete, unbiased semantic space that captures all relevant retrieval variations and allows query generation without introducing new selection biases.
What would settle it
A large independently drawn sample of queries from the full corpus on which the performance ranking or variance obtained from the stratified set does not match the ranking or variance from the independent sample.
Figures









read the original abstract
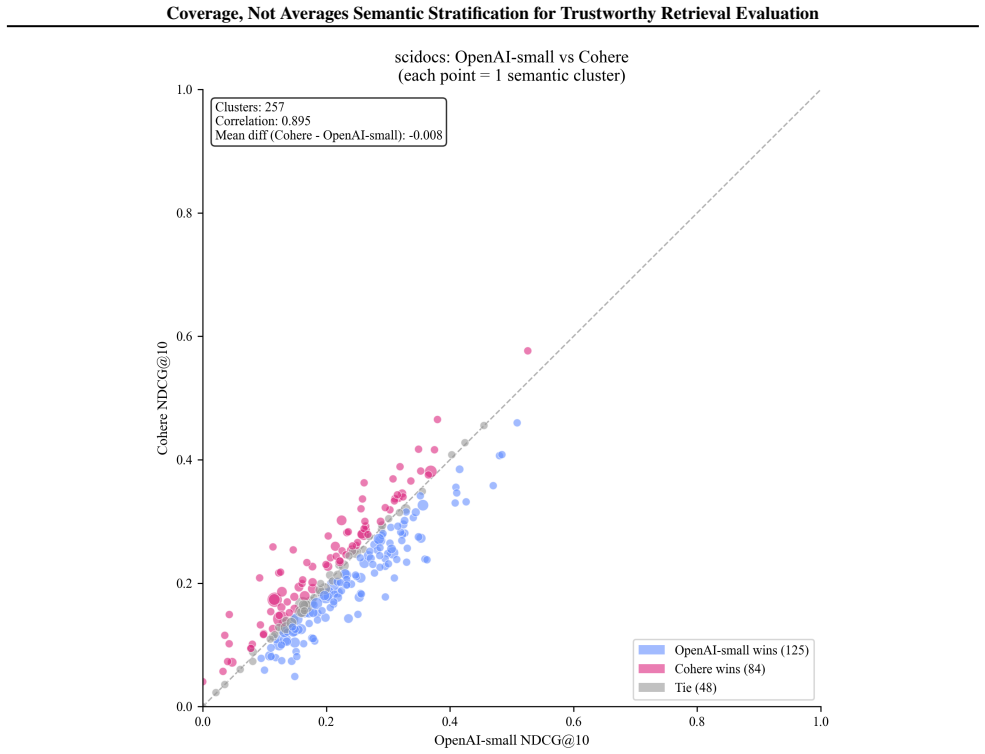
Retrieval quality is the primary bottleneck for accuracy and robustness in retrieval-augmented generation (RAG). Current evaluation relies on heuristically constructed query sets, which introduce a hidden intrinsic bias. We formalize retrieval evaluation as a statistical estimation problem, showing that metric reliability is fundamentally limited by the evaluation-set construction. We further introduce \emph{semantic stratification}, which grounds evaluation in corpus structure by organizing documents into an interpretable global space of entity-based clusters and systematically generating queries for missing strata. This yields (1) formal semantic coverage guarantees across retrieval regimes and (2) interpretable visibility into retrieval failure modes. Experiments across multiple benchmarks and retrieval methods validate our framework. The results expose systematic coverage gaps, identify structural signals that explain variance in retrieval performance, and show that stratified evaluation yields more stable and transparent assessments while supporting more trustworthy decision-making than aggregate metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that heuristic query sets introduce intrinsic bias in retrieval evaluation, formalizes evaluation as a statistical estimation problem whose reliability is limited by evaluation-set construction, and introduces semantic stratification: documents are organized into an interpretable global space of entity-based clusters, queries are systematically generated for missing strata, yielding formal semantic coverage guarantees across retrieval regimes plus interpretable visibility into failure modes. Experiments across multiple benchmarks and retrieval methods are said to validate the framework by exposing coverage gaps, identifying structural signals for performance variance, and showing more stable assessments than aggregate metrics.
Significance. If the entity-based clustering construction indeed supplies an interpretable global semantic space that supports systematic query generation and formal coverage guarantees without introducing new selection biases, the work would strengthen evaluation methodology in information retrieval and RAG by shifting from opaque averages to coverage-aware, diagnostically transparent protocols. The statistical-estimation framing and the emphasis on corpus-grounded strata are positive contributions that could support more trustworthy decision-making.
major comments (2)
- [Abstract / semantic stratification construction] Abstract and the description of semantic stratification: the central claim that entity-based clusters produce an interpretable global semantic space sufficient for formal coverage guarantees rests on the unexamined assumption that entity co-occurrence or similarity captures all relevant retrieval dimensions; non-entity factors (temporal ordering, causal relations, sentiment polarity, discourse structure) are not shown to align with the clusters, so strata labeled 'complete' may still omit critical query variations and the claimed bias reduction does not follow.
- [Abstract] Abstract: the statement that 'experiments across multiple benchmarks and retrieval methods validate our framework' is unsupported by any description of experimental design, baselines, statistical tests, or the concrete procedure used to compute coverage guarantees, rendering the empirical support for the central claim unverifiable from the provided text.
minor comments (1)
- [Abstract] The abstract introduces 'semantic strata' and 'entity-based clusters' without a brief definitional sentence, which reduces immediate clarity for readers unfamiliar with the approach.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the scope and presentation of our work. We respond to each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / semantic stratification construction] Abstract and the description of semantic stratification: the central claim that entity-based clusters produce an interpretable global semantic space sufficient for formal coverage guarantees rests on the unexamined assumption that entity co-occurrence or similarity captures all relevant retrieval dimensions; non-entity factors (temporal ordering, causal relations, sentiment polarity, discourse structure) are not shown to align with the clusters, so strata labeled 'complete' may still omit critical query variations and the claimed bias reduction does not follow.
Authors: We agree that entity-based clustering does not exhaustively capture every retrieval dimension. The framework defines semantic strata and coverage guarantees explicitly with respect to the entity space, which we selected because entities provide an interpretable, corpus-grounded partitioning that aligns with many knowledge-intensive retrieval tasks. Experiments demonstrate that this already exposes substantial gaps in standard query sets. We will add a new subsection in the discussion that explicitly states the scope of the entity-based approach, lists non-entity factors as orthogonal dimensions not covered by the current strata, and outlines how the stratification procedure could be extended (e.g., by adding temporal or sentiment-based partitions). This revision will make the assumptions and limitations transparent without altering the core technical contribution. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'experiments across multiple benchmarks and retrieval methods validate our framework' is unsupported by any description of experimental design, baselines, statistical tests, or the concrete procedure used to compute coverage guarantees, rendering the empirical support for the central claim unverifiable from the provided text.
Authors: The abstract is a high-level summary; the full experimental design, benchmark details, retrieval methods, statistical tests, and exact procedure for computing coverage guarantees appear in Sections 4 and 5 of the manuscript. Nevertheless, the current abstract phrasing is too terse and could mislead readers who read only the abstract. We will revise the abstract to qualify the validation statement (e.g., “Experiments across multiple benchmarks and retrieval methods expose systematic coverage gaps and demonstrate more stable assessments than aggregate metrics”) and add a brief parenthetical reference to the methodology sections. revision: yes
Circularity Check
Semantic coverage guarantees reduce to definitional property of the stratification
specific steps
-
self definitional
[Abstract]
"organizing documents into an interpretable global space of entity-based clusters and systematically generating queries for missing strata. This yields (1) formal semantic coverage guarantees across retrieval regimes and (2) interpretable visibility into retrieval failure modes."
The coverage guarantees are yielded directly by the act of organizing into clusters and generating queries for missing strata, making the guarantee hold by the definition of the strata rather than through an independent mathematical derivation or empirical validation separate from the construction.
full rationale
The paper's formalization of retrieval evaluation as a statistical estimation problem and its experimental results across benchmarks stand as independent content. However, the central yield of 'formal semantic coverage guarantees' is presented as following directly from the definition and construction of entity-based strata plus query generation for missing ones, without an external derivation or benchmark that would make the guarantee non-tautological. This is a self-definitional element in the load-bearing claim but does not collapse the entire argument.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entity-based clusters form an interpretable global semantic space that captures the relevant variations for systematic query generation across retrieval regimes.
invented entities (1)
-
semantic strata
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026. Cormack, G. V ., Clarke, C. L. A., and Buettcher, S. Re- ciprocal rank fusion outperforms condorcet and indi- vidual rank learning methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’09, pp. 758–759, New York, NY , USA, 2009. Associa- tion for Computing Machiner...
-
[2]
Association for Computational Linguistics. ISBN 9 Coverage, Not Averages Semantic Stratification for Trustworthy Retrieval Evaluation 979-8-89176-288-6. doi: 10.18653/v1/2025.acl-industry
-
[3]
URL https://aclanthology.org/2025. acl-industry.33/. Guti´errez, B. J., Shu, Y ., Gu, Y ., Yasunaga, M., and Su, Y . Hipporag: Neurobiologically inspired long-term memory for large language models. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Advances in Neural Information Pro- cessing Systems, volume ...
-
[4]
URL https://aclanthology.org/2024. findings-emnlp.279/. Rahman, M. M., Kutlu, M., Elsayed, T., and Lease, M. Effi- cient test collection construction via active learning. In Proceedings of the 2020 ACM SIGIR on International Conference on Theory of Information Retrieval, ICTIR ’20, pp. 177–184, New York, NY , USA, 2020. Associa- tion for Computing Machine...
-
[5]
URL https://openreview.net/forum? id=t4eB3zYWBK. Teixeira de Lima, R., Gupta, S., Berrospi Ramis, C., Mishra, L., Dolfi, M., Staar, P., and Vagenas, P. Know your RAG: Dataset taxonomy and generation strategies for evaluating RAG systems. In Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B. D., Schock- aert, S., Darwish, K., and Agarwal, ...
-
[6]
doi: 10.18653/v1/2025.acl-long.418. URL https: //aclanthology.org/2025.acl-long.418/. 11 Coverage, Not Averages Semantic Stratification for Trustworthy Retrieval Evaluation A. Semantic Structure Construction A.1. Entity Extraction Model: GPT-4o-mini EXTRACTION_PROMPT = """Extract key entities from this document. For each entity provide: - name: the entity...
-
[7]
AUTHENTICITY: Generate queries that real users would actually type, not artificial constructs
-
[8]
SPECIFICITY CONTROL: Match the requested query type precisely (short/long, ambiguous/specific)
-
[9]
ANSWERABILITY: The query MUST be answerable by the provided document
-
[10]
NO LEAKAGE: Do not copy exact phrases from the document title
-
[11]
BERT embeddings
INFORMATION NEED: Express a genuine information need, not just keywords WHAT TO AVOID: - Queries that are too generic to meaningfully match the document - Queries that require information NOT in the document - Forced or unnatural combinations of keywords --- USER: Generate a search query that this document would answer. Query Type: {query_type_description...
-
[12]
DIRECT MENTION: The entity or a synonym appears in the query
-
[13]
heart disease prevention
IMPLICIT REFERENCE: The query is about this entity even if not named explicitly Example: "heart disease prevention" -> relevant: "cardiovascular disease", "heart health", "coronary artery"
-
[14]
CRISPR applications
REQUIRED KNOWLEDGE: Answering the query requires knowing about this entity Example: "CRISPR applications" -> relevant: "gene editing", "Cas9", "genetic engineering"
-
[15]
--- USER: Identify which entities from the candidate list are relevant to the search query
SEMANTIC OVERLAP: The entity’s domain strongly overlaps with the query’s information need WHAT IS NOT RELEVANT: - Entities that are merely topically adjacent but not needed to answer the query - Entities from the same broad field but addressing different specific aspects - Entities that might appear in the same document but aren’t query-relevant PRECISION...
-
[16]
It appears in or is directly referenced by the query
-
[17]
It represents a key concept the query is asking about
-
[18]
Understanding this entity is necessary to answer the query
-
[19]
{query_text}
It’s a person, organization, place, or technical term central to the query An entity is NOT RELEVANT if: - It’s from the same general field but addresses a different aspect - It might co-occur with query terms but isn’t about the query topic - It’s too broad or too specific relative to the query’s need Search Query: "{query_text}" Candidate Entities: {ent...
-
[20]
machine learning
TOPICAL SIMILARITY != RELEVANCE Two documents about "machine learning" may address completely different aspects. The query might be about "ML for medical imaging" but doc is about "ML for NLP"
-
[21]
Context and the specific information need matter
KEYWORD MATCHING != RELEVANCE Matching keywords doesn’t mean the document answers the query. Context and the specific information need matter
-
[22]
If I were the user, would this document satisfy my search?
DOCUMENT QUALITY != RELEVANCE A poorly written document can still be relevant. A high-quality document on a different topic is not relevant. WHEN IN DOUBT: - Re-read the query and identify the core information need - Ask: "If I were the user, would this document satisfy my search?" - Lean toward precision: it’s better to miss a marginally relevant doc tha...
-
[23]
Does this document contain information the user is looking for?
-
[24]
Would returning this document be helpful for this specific query?
-
[25]
0, 2, 5"). If none are relevant, respond with
Is the relevance substantive or merely superficial keyword overlap? Respond with ONLY the document numbers that are RELEVANT, 17 Coverage, Not Averages Semantic Stratification for Trustworthy Retrieval Evaluation comma-separated (e.g., "0, 2, 5"). If none are relevant, respond with "NONE". D. Examples and Coverage Analysis D.1. Example Semantic Cluster Ta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.