Recognition: unknown
Working Memory Constraints Scaffold Learning in Transformers under Data Scarcity
Pith reviewed 2026-05-10 00:52 UTC · model grok-4.3
The pith
Fixed-width attention constraints improve grammatical accuracy in Transformers trained on limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
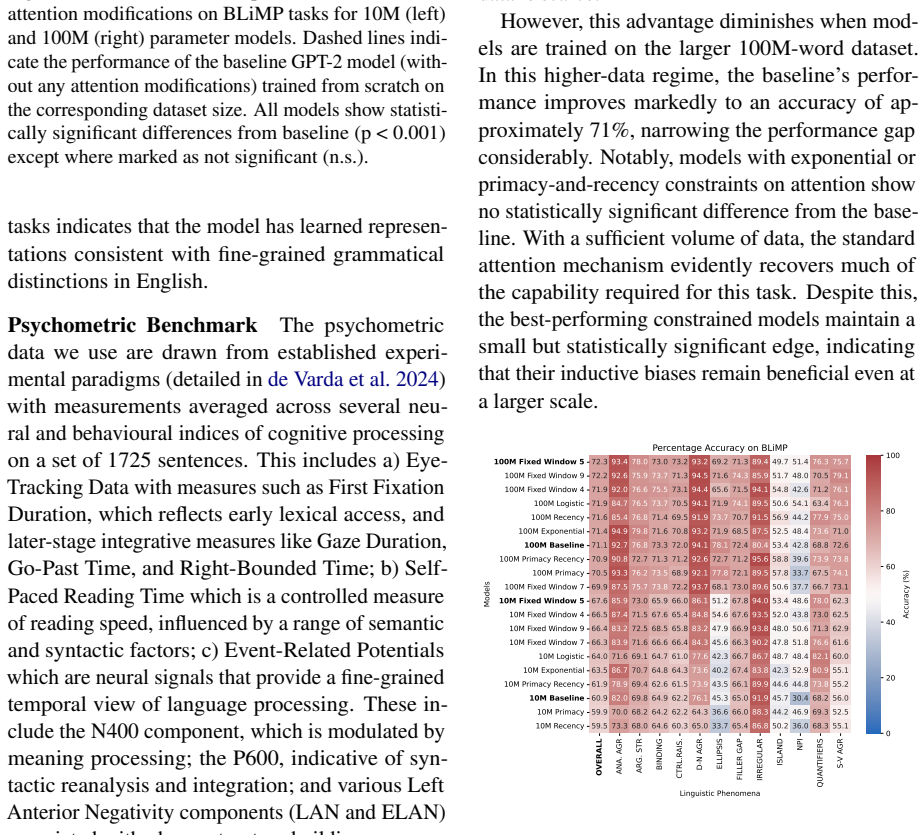
Incorporating fixed-width attention windows, which limit each position to attend only within a small preceding context, produces higher accuracy on BLiMP grammatical judgment tasks than standard Transformers, with the largest gains appearing on the 10M-word training set; the same models also exhibit closer alignment with human reading-time measurements.
What carries the argument
Fixed-width attention windows restrict each token's attention to a bounded number of recent tokens, functioning as a working-memory limit that reduces long-range distraction during learning.
If this is right
- Fixed-width models achieve measurably higher grammatical accuracy than unconstrained Transformers on the same small datasets.
- The constrained models produce internal representations that correlate more strongly with human sentence-reading durations.
- The benefit of the memory limit is larger when training data is smaller, indicating an efficiency advantage in low-resource settings.
- The constraints guide the model toward more robust linguistic knowledge rather than superficial pattern matching.
Where Pith is reading between the lines
- The same bounded-attention approach might yield similar efficiency gains on non-English languages or on tasks such as parsing and question answering.
- Architectures that embed explicit memory limits could reduce the data volume needed for acceptable performance across a wider range of NLP benchmarks.
- Testing whether these models retain their advantage when fine-tuned on larger data or transferred to new domains would clarify the scope of the inductive bias.
Load-bearing premise
The measured gains in grammar accuracy and human alignment are caused by the added memory constraints rather than by incidental differences in training procedure or model implementation.
What would settle it
Identically trained pairs of models that differ only in the presence of the fixed-width window, yet show no reliable difference in BLiMP scores on the 10M-word regime, would falsify the claim.
Figures





read the original abstract
We investigate the integration of human-like working memory constraints into the Transformer architecture and implement several cognitively inspired attention variants, including fixed-width windows based and temporal decay based attention mechanisms. Our modified GPT-2 models are trained from scratch on developmentally plausible datasets (10M and 100M words). Performance is evaluated on grammatical judgment tasks (BLiMP) and alignment with human reading time data. Our results indicate that these cognitively-inspired constraints, particularly fixed-width attention, can significantly improve grammatical accuracy especially when training data is scarce. These constrained models also tend to show a stronger alignment with human processing metrics. The findings suggest that such constraints may serve as a beneficial inductive bias, guiding models towards more robust linguistic representations, especially in data-limited settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates integrating human-like working memory constraints into the Transformer architecture via fixed-width window and temporal decay attention mechanisms in GPT-2 models. These are trained from scratch on developmentally plausible small datasets (10M and 100M words) and evaluated on BLiMP grammatical judgment tasks plus alignment with human reading time data. The central claim is that these constraints, especially fixed-width attention, provide a beneficial inductive bias that significantly improves grammatical accuracy under data scarcity and yields stronger human alignment.
Significance. If the results hold after isolating the effect of the constraints, the work would demonstrate that cognitively motivated architectural biases can improve sample efficiency and robustness in language models, offering a bridge between cognitive science and NLP with potential implications for low-resource training regimes.
major comments (2)
- [Abstract / Results] Abstract and Results sections: the headline claim that fixed-width attention 'significantly improve[s] grammatical accuracy especially when training data is scarce' rests on empirical gains whose causality is not isolated. The manuscript does not report whether constrained variants are matched to the GPT-2 baseline on total parameter count, effective receptive field size, optimizer schedule, or random seed; without these controls, gains could arise from capacity reduction (e.g., zeroing distant keys) rather than the working-memory inductive bias.
- [Methods] Methods / Experimental Setup: no details are provided on statistical significance testing, error bars, or exact training procedures for the BLiMP evaluations. This prevents verification that observed improvements are robust and attributable to the proposed constraints rather than implementation variations.
minor comments (2)
- [Methods] Clarify the precise definition and hyperparameter choices for 'fixed-width windows based' and 'temporal decay based' attention (e.g., window size per layer, decay rate schedule) so that the mechanisms can be reproduced.
- [Results] If tables or figures report BLiMP scores, add standard deviations or confidence intervals and label all baselines explicitly.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which help clarify the need for stronger experimental controls and reproducibility details. We address each major comment below and have revised the manuscript to incorporate the suggested improvements, thereby strengthening the evidence for our claims about working memory constraints as an inductive bias.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results sections: the headline claim that fixed-width attention 'significantly improve[s] grammatical accuracy especially when training data is scarce' rests on empirical gains whose causality is not isolated. The manuscript does not report whether constrained variants are matched to the GPT-2 baseline on total parameter count, effective receptive field size, optimizer schedule, or random seed; without these controls, gains could arise from capacity reduction (e.g., zeroing distant keys) rather than the working-memory inductive bias.
Authors: We agree that demonstrating the causality of the working-memory inductive bias requires careful controls. All model variants share the identical GPT-2 base architecture (same number of layers, hidden size, and feed-forward dimensions), so total parameter counts are matched at approximately 124M parameters; the attention modifications change only the computation pattern without adding or removing parameters. We did not, however, report effective receptive field sizes or explicitly fix random seeds across conditions in the original submission. In the revised manuscript we have added a dedicated subsection in Methods that reports exact parameter counts, confirms identical AdamW optimizer schedules and hyperparameters, and specifies the random seeds used. We also include an analysis of effective receptive fields for each variant and an additional control experiment that compares against a baseline with random (non-structured) masking of distant keys. These revisions isolate the benefit of the cognitively motivated structure from mere capacity reduction. revision: yes
-
Referee: [Methods] Methods / Experimental Setup: no details are provided on statistical significance testing, error bars, or exact training procedures for the BLiMP evaluations. This prevents verification that observed improvements are robust and attributable to the proposed constraints rather than implementation variations.
Authors: We acknowledge that the original manuscript omitted these critical details, limiting reproducibility. The revised version now reports error bars as standard deviation across three independent runs with distinct random seeds, includes p-values from paired t-tests on BLiMP accuracy differences, and adds a new appendix with the complete training protocol (exact learning rate, batch size, number of epochs, data preprocessing, and tokenization) together with the precise BLiMP evaluation procedure. These additions allow readers to verify that the reported gains are statistically robust and attributable to the architectural constraints. revision: yes
Circularity Check
No circularity; purely empirical claims with no derivations
full rationale
The paper reports results from training modified GPT-2 variants with fixed-width and decay attention on 10M/100M-word corpora and evaluating grammatical accuracy on BLiMP plus human reading-time alignment. No equations, first-principles derivations, or parameter-fitting steps are present that could reduce a claimed prediction to its own inputs by construction. All load-bearing statements are experimental comparisons whose validity depends on controls (parameter count, optimization, etc.) rather than any self-referential logic or self-citation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alan Baddeley. 2000. The episodic buffer: a new component of working memory? Trends in cognitive sciences, 4(11):417--423
2000
-
[2]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150
work page internal anchor Pith review arXiv 2020
-
[3]
Roger Brown. 1973. A first language: The early stages. Harvard University Press
1973
-
[4]
Bradley R Buchsbaum and Mark D'Esposito. 2019. A sensorimotor view of verbal working memory. Cortex, 112:134--148
2019
-
[5]
David Caplan and Gloria Waters. 2013. Memory mechanisms supporting syntactic comprehension. Psychonomic bulletin & review, 20:243--268
2013
-
[6]
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 2019. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509. arXiv preprint arXiv:2009.14794
work page internal anchor Pith review arXiv 2019
-
[7]
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, and David Belanger, Lucy Colwell, and Adrian Weller. 2020. Rethinking attention with performers. arXiv preprint arXiv:2009.14794
work page internal anchor Pith review arXiv 2020
-
[8]
Morten H Christiansen and Nick Chater. 2016. The now-or-never bottleneck: A fundamental constraint on language. Behavioral and brain sciences, 39:e62
2016
-
[9]
Christian Clark, Byung-Doh Oh, and William Schuler. 2025. https://aclanthology.org/2025.coling-main.517/ Linear recency bias during training improves transformers' fit to reading times . In Proceedings of the 31st International Conference on Computational Linguistics, pages 7735--7747, Abu Dhabi, UAE. Association for Computational Linguistics
2025
-
[10]
Nelson Cowan. 2001. The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and brain sciences, 24(1):87--114
2001
-
[11]
Andrea De Varda and Marco Marelli. 2024. https://doi.org/10.18653/v1/2024.cmcl-1.3 Locally biased transformers better align with human reading times . In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, pages 30--36, Bangkok, Thailand. Association for Computational Linguistics
-
[12]
Andrea Gregor de Varda, Marco Marelli, and Simona Amenta. 2024. Cloze probability, predictability ratings, and computational estimates for 205 english sentences, aligned with existing eeg and reading time data. Behavior Research Methods, 56(5):5190--5213
2024
-
[13]
Richard Futrell, Edward Gibson, and Roger P Levy. 2020. Lossy-context surprisal: An information-theoretic model of memory effects in sentence processing. Cognitive science, 44(3):e12814
2020
-
[14]
Richard Futrell, Kyle Mahowald, and Edward Gibson. 2015. Large-scale evidence of dependency length minimization in 37 languages. Proceedings of the National Academy of Sciences, 112(33):10336--10341
2015
-
[15]
Edward Gibson. 1998. Linguistic complexity: Locality of syntactic dependencies. Cognition, 68(1):1--76
1998
-
[16]
Murray Glanzer and Anita R Cunitz. 1966. Two storage mechanisms in free recall. Journal of verbal learning and verbal behavior, 5(4):351--360
1966
-
[17]
Adam Goodkind and Klinton Bicknell. 2018. https://doi.org/10.18653/v1/W18-0102 Predictive power of word surprisal for reading times is a linear function of language model quality . In Proceedings of the 8th Workshop on Cognitive Modeling and Computational Linguistics ( CMCL 2018) , pages 10--18, Salt Lake City, Utah. Association for Computational Linguistics
-
[18]
Michael Hahn, Richard Futrell, Roger Levy, and Edward Gibson. 2022. A resource-rational model of human processing of recursive linguistic structure. Proceedings of the National Academy of Sciences, 119(43):e2122602119
2022
-
[19]
John Hewitt and Christopher D. Manning. 2019. https://doi.org/10.18653/v1/N19-1419 A structural probe for finding syntax in word representations . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4129--4138, Minneapol...
-
[20]
Judith Holler and Stephen C Levinson. 2019. Multimodal language processing in human communication. Trends in cognitive sciences, 23(8):639--652
2019
- [21]
-
[22]
Marcel A Just and Patricia A Carpenter. 1992. A capacity theory of comprehension: individual differences in working memory. Psychological review, 99(1):122
1992
-
[23]
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Fran c ois Fleuret. 2020. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156--5165. PMLR
2020
-
[24]
Simon Kirby. 1999. Function, selection, and innateness: The emergence of language universals. OUP Oxford
1999
-
[25]
Tatsuki Kuribayashi, Yohei Oseki, Ana Brassard, and Kentaro Inui. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.712 Context limitations make neural language models more human-like . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10421--10436, Abu Dhabi, United Arab Emirates. Association for Computation...
-
[26]
Roger Levy. 2008. Expectation-based syntactic comprehension. Cognition, 106(3):1126--1177
2008
-
[27]
Steven G Luke and Kiel Christianson. 2018. The provo corpus: A large eye-tracking corpus with predictability norms. Behavior research methods, 50:826--833
2018
-
[28]
Maryellen C MacDonald. 2016. Speak, act, remember: The language-production basis of serial order and maintenance in verbal memory. Current Directions in Psychological Science, 25(1):47--53
2016
- [29]
-
[30]
George A Miller. 1956. The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological review, 63(2):81
1956
-
[31]
Alexandra B Morrison, Andrew RA Conway, and Jason M Chein. 2014. Primacy and recency effects as indices of the focus of attention. Frontiers in human neuroscience, 8:6
2014
-
[32]
Byung-Doh Oh and William Schuler. 2023. Why does surprisal from larger transformer-based language models provide a poorer fit to human reading times? Transactions of the Association for Computational Linguistics, 11:336--350
2023
-
[33]
Ofir Press, Noah A Smith, and Mike Lewis. 2021. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409
work page internal anchor Pith review arXiv 2021
-
[34]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9
2019
-
[35]
Soo Hyun Ryu and Richard Lewis. 2021. https://doi.org/10.18653/v1/2021.cmcl-1.6 Accounting for agreement phenomena in sentence comprehension with transformer language models: Effects of similarity-based interference on surprisal and attention . In Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics, pages 61--71, Online. Associ...
-
[36]
Steven C Schwering and Maryellen C MacDonald. 2020. Verbal working memory as emergent from language comprehension and production. Frontiers in human neuroscience, 14:68
2020
-
[37]
Cory Shain, Clara Meister, Tiago Pimentel, Ryan Cotterell, and Roger Levy. 2024. Large-scale evidence for logarithmic effects of word predictability on reading time. Proceedings of the National Academy of Sciences, 121(10):e2307876121
2024
- [38]
-
[39]
Nathaniel J Smith and Roger Levy. 2013. The effect of word predictability on reading time is logarithmic. Cognition, 128(3):302--319
2013
- [40]
-
[41]
Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. 2021. https://arxiv.org/abs/2104.09864 Roformer: Enhanced transformer with rotary position embedding . Preprint, arXiv:2104.09864
work page internal anchor Pith review arXiv 2021
- [42]
-
[43]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. https://doi.org/10.18653/v1/P19-1452 BERT rediscovers the classical NLP pipeline . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593--4601, Florence, Italy. Association for Computational Linguistics
- [44]
-
[45]
Julie A Van Dyke and Richard L Lewis. 2003. Distinguishing effects of structure and decay on attachment and repair: A cue-based parsing account of recovery from misanalyzed ambiguities. Journal of Memory and Language, 49(3):285--316
2003
-
[46]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf Attention is all you need . In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc
2017
-
[47]
Alex Warstadt, Aaron Mueller, Leshem Choshen, Ethan Wilcox, Chengxu Zhuang, Juan Ciro, Rafael Mosquera, Bhargavi Paranjabe, Adina Williams, Tal Linzen, and Ryan Cotterell. 2023. https://doi.org/10.18653/v1/2023.conll-babylm.1 Findings of the B aby LM challenge: Sample-efficient pretraining on developmentally plausible corpora . In Proceedings of the BabyL...
-
[48]
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R Bowman. 2020. Blimp: The benchmark of linguistic minimal pairs for english. Transactions of the Association for Computational Linguistics, 8:377--392
2020
-
[49]
Ethan Wilcox, Peng Qian, Richard Futrell, Ryosuke Kohita, Roger Levy, and Miguel Ballesteros. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.375 Structural supervision improves few-shot learning and syntactic generalization in neural language models . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pag...
-
[50]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
-
[51]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283--17297
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.