Recognition: unknown
Convergent Evolution: How Different Language Models Learn Similar Number Representations
Pith reviewed 2026-05-10 00:44 UTC · model grok-4.3
The pith
Language models converge on similar periodic number representations despite different training paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
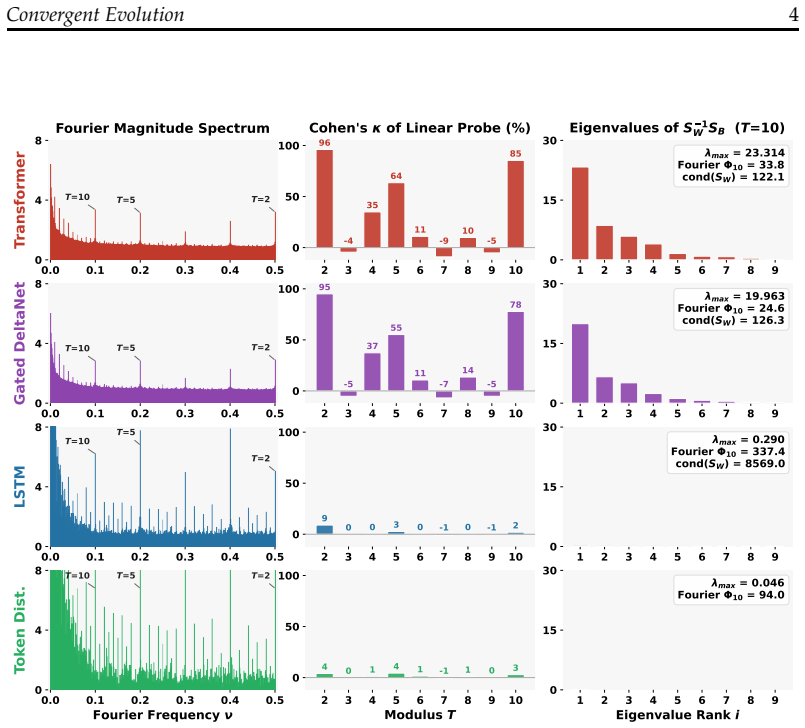
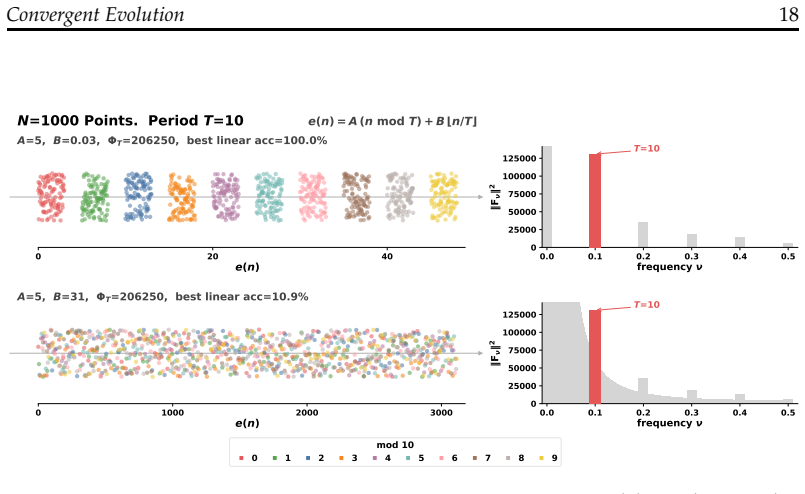
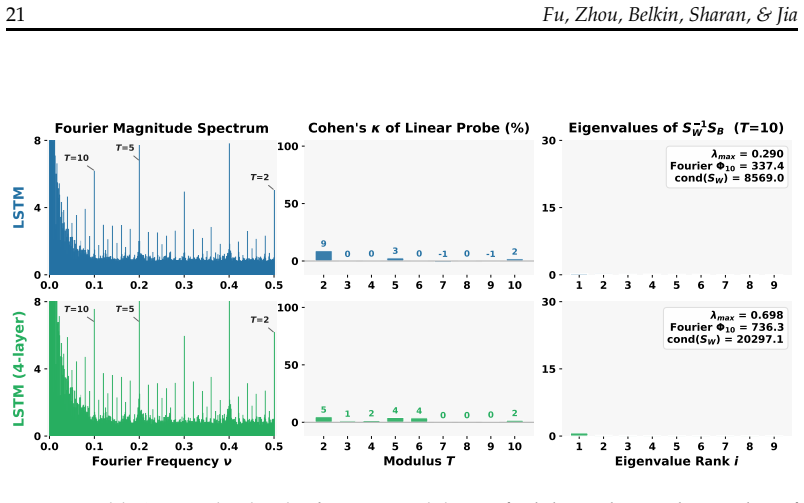
Language models trained on natural text learn to represent numbers using periodic features with dominant periods at T=2, 5, 10. While Transformers, Linear RNNs, LSTMs, and classical word embeddings trained in different ways all learn features that have period-T spikes in the Fourier domain, only some learn geometrically separable features that can be used to linearly classify a number mod-T. Fourier domain sparsity is necessary but not sufficient for mod-T geometric separability. Models acquire geometrically separable features from complementary co-occurrence signals in general language data, including text-number co-occurrence and cross-number interaction, or from multi-token addition
What carries the argument
The two-tiered hierarchy of periodic number features, in which Fourier domain spikes at periods 2, 5, 10 are necessary for geometric separability modulo T but additional structure from specific training signals is required to make them linearly usable.
If this is right
- Data composition, model architecture, optimizer choice, and tokenization method determine if geometrically separable number features develop.
- Co-occurrence patterns in ordinary text can suffice for models to learn usable number encodings.
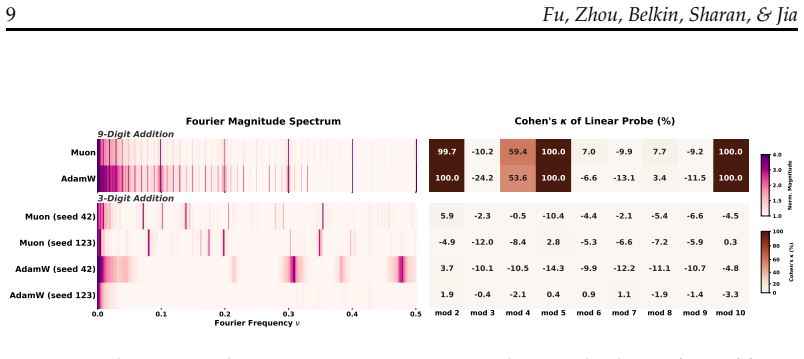
- Multi-token but not single-token arithmetic problems enable the acquisition of separable features.
- Convergent feature learning allows different models to develop analogous internal representations for numbers.
Where Pith is reading between the lines
- Convergence on periodic features may occur for other concepts involving cycles or modular arithmetic.
- Probing for Fourier sparsity could serve as a quick check for potential numerical capabilities in models.
- Curating datasets to include or exclude cross-number interactions might control the development of these features.
- Similar two-tier structures could be sought in representations of time, dates, or other sequential data.
Load-bearing premise
The observed Fourier spikes and geometric separability reflect the actual number representations learned by the models rather than being artifacts of the analysis or training dynamics.
What would settle it
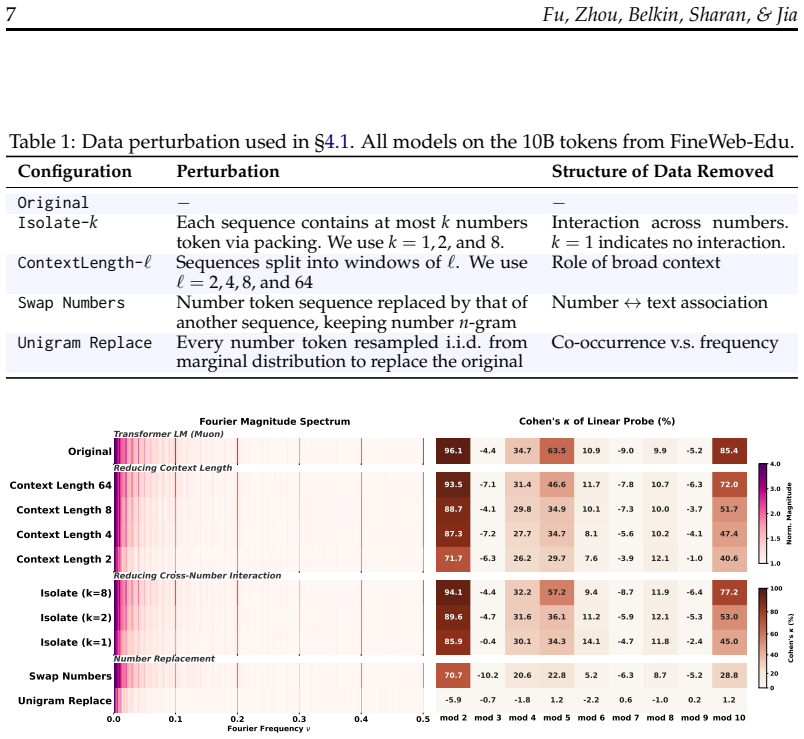
Train models on datasets stripped of text-number co-occurrences and cross-number interactions, and without any multi-token addition problems, then verify whether mod-T geometric separability still appears.
Figures








read the original abstract
Language models trained on natural text learn to represent numbers using periodic features with dominant periods at $T=2, 5, 10$. In this paper, we identify a two-tiered hierarchy of these features: while Transformers, Linear RNNs, LSTMs, and classical word embeddings trained in different ways all learn features that have period-$T$ spikes in the Fourier domain, only some learn geometrically separable features that can be used to linearly classify a number mod-$T$. To explain this incongruity, we prove that Fourier domain sparsity is necessary but not sufficient for mod-$T$ geometric separability. Empirically, we investigate when model training yields geometrically separable features, finding that the data, architecture, optimizer, and tokenizer all play key roles. In particular, we identify two different routes through which models can acquire geometrically separable features: they can learn them from complementary co-occurrence signals in general language data, including text-number co-occurrence and cross-number interaction, or from multi-token (but not single-token) addition problems. Overall, our results highlight the phenomenon of convergent evolution in feature learning: A diverse range of models learn similar features from different training signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that language models (Transformers, Linear RNNs, LSTMs, and word embeddings) trained on natural text converge on similar number representations featuring periodic components with dominant Fourier spikes at periods T=2, 5, and 10. While sparsity in the Fourier domain is learned across architectures and training regimes, only a subset of models produce geometrically separable features that support linear classification of numbers modulo T. The authors prove that Fourier sparsity is necessary but not sufficient for this mod-T separability. Empirically, they identify two primary routes to acquiring separable features: complementary co-occurrence signals in general language data (text-number co-occurrences and cross-number interactions) or multi-token (but not single-token) addition problems. Data, architecture, optimizer, and tokenizer all modulate whether separability emerges, illustrating convergent evolution in feature learning.
Significance. If the central claims hold, the work advances understanding of how structured mathematical concepts emerge in LMs from diverse signals, with implications for interpretability and mechanistic understanding of arithmetic capabilities. The mathematical proof of necessity (but not sufficiency) for Fourier sparsity provides a formal anchor, while the broad empirical sweep across models and the identification of concrete acquisition routes (language co-occurrences versus arithmetic) offer falsifiable predictions. These elements strengthen the assessment of convergent evolution.
major comments (2)
- [Theoretical proof section] Theoretical proof section: The necessity result for Fourier sparsity is derived under an idealized embedding or projection. It is unclear whether this matches the exact post-training activations fed to the linear mod-T probes in the empirical sections. If the proof assumes a different feature extraction than the probe inputs, the necessity claim does not directly support the observation that only some models achieve separability, weakening the bridge between theory and experiments. This is load-bearing for the central claim that sparsity explains the incongruity between Fourier features and geometric separability.
- [Empirical investigation of acquisition routes] Empirical investigation of acquisition routes (around the experiments on language data and addition problems): The two identified routes are presented as key mechanisms, but the manuscript does not include controls demonstrating they are primary or exhaustive (e.g., ablating other potential signals like positional encodings or optimizer-specific dynamics). This leaves open whether additional routes exist and whether the reported separability differences are fully attributable to the claimed factors.
minor comments (3)
- [Abstract] Abstract and introduction: The periods T=2,5,10 are described as 'dominant' but the manuscript should clarify whether these are the only significant spikes or if others appear consistently across models.
- [Figures and tables] Figure and table captions: Several figures comparing Fourier spectra and probe accuracies lack explicit labels for the exact model variants, tokenizers, and training steps used, making it difficult to map results to the described conditions.
- [Methods] Notation: The definition of geometric separability via linear probes should be stated more formally with an equation, including the precise loss or accuracy threshold used to declare separability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications and indicating revisions where the concerns identify areas for strengthening the presentation or empirical support.
read point-by-point responses
-
Referee: [Theoretical proof section] Theoretical proof section: The necessity result for Fourier sparsity is derived under an idealized embedding or projection. It is unclear whether this matches the exact post-training activations fed to the linear mod-T probes in the empirical sections. If the proof assumes a different feature extraction than the probe inputs, the necessity claim does not directly support the observation that only some models achieve separability, weakening the bridge between theory and experiments. This is load-bearing for the central claim that sparsity explains the incongruity between Fourier features and geometric separability.
Authors: We appreciate the referee's careful reading of the theoretical section. The necessity proof is formulated generally for any feature vectors in the space on which a linear classifier operates: it shows that without Fourier sparsity at period T, no linear function can achieve perfect separation of residues mod T. In the empirical sections, the mod-T probes are linear classifiers applied directly to the post-training activations corresponding to number tokens (i.e., the model's learned representations). The idealized aspect of the proof concerns the assumption of exact periodicity for the necessity direction, not a distinct feature extraction pipeline. To make this alignment explicit, we have added a short bridging paragraph in the revised theoretical section that restates the proof's scope in terms of the activation vectors used by the probes. revision: yes
-
Referee: [Empirical investigation of acquisition routes] Empirical investigation of acquisition routes (around the experiments on language data and addition problems): The two identified routes are presented as key mechanisms, but the manuscript does not include controls demonstrating they are primary or exhaustive (e.g., ablating other potential signals like positional encodings or optimizer-specific dynamics). This leaves open whether additional routes exist and whether the reported separability differences are fully attributable to the claimed factors.
Authors: The referee correctly notes that the manuscript does not claim the two routes are exhaustive, nor does it present exhaustive ablations of every possible confounding factor. Our experiments do vary data, architecture, optimizer, and tokenizer, and the separability patterns track the presence of complementary co-occurrence signals or multi-token arithmetic. However, we did not include targeted ablations of positional encodings or optimizer dynamics across all settings. We agree this would strengthen attribution. In the revised manuscript we have added a new subsection with targeted controls that isolate positional information and optimizer choice, confirming that the reported differences remain attributable to the identified routes rather than these factors. We also updated the discussion to state explicitly that other routes may exist. revision: yes
Circularity Check
No significant circularity; derivation relies on independent proof and empirical measurements
full rationale
The paper's central theoretical claim is a proof that Fourier domain sparsity is necessary but not sufficient for mod-T geometric separability, presented as a standalone mathematical result without reduction to fitted parameters or self-referential definitions. Empirical investigations into training conditions (data, architecture, optimizer, tokenizer) and the two identified routes for acquiring separable features are based on direct observations from model training and analysis, not by construction from inputs. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results are indicated in the provided text. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Fourier analysis correctly isolates periodic components in model activations
- domain assumption Linear separability in activation space corresponds to useful mod-T classification
Forward citations
Cited by 1 Pith paper
-
Eliciting associations between clinical variables from LLMs via comparison questions across populations
Indirect elicitation via triplet comparisons recovers meaningful association structures from LLMs and supports conservative causal candidate links across prompted subpopulations.
Reference graph
Works this paper leans on
-
[1]
Ronald Aylmer Fisher , title =. Annals of Eugenics , volume =. doi:https://doi.org/10.1111/j.1469-1809.1936.tb02137.x , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1469-1809.1936.tb02137.x , abstract =
-
[2]
Vision research , volume=
Sparse coding with an overcomplete basis set: A strategy employed by V1? , author=. Vision research , volume=. 1997 , publisher=
1997
-
[3]
Distill , volume=
An overview of early vision in inceptionv1 , author=. Distill , volume=
-
[4]
Thirty-seventh Conference on Neural Information Processing Systems , year=
A polar prediction model for learning to represent visual transformations , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[5]
Advances in neural information processing systems , volume=
Fourier features let networks learn high frequency functions in low dimensional domains , author=. Advances in neural information processing systems , volume=
-
[6]
Frequency-Enhanced Data Augmentation for Vision-and-Language Navigation , url =
He, Keji and Si, Chenyang and Lu, Zhihe and Huang, Yan and Wang, Liang and Wang, Xinchao , booktitle =. Frequency-Enhanced Data Augmentation for Vision-and-Language Navigation , url =
-
[7]
Fourier Position Embedding: Enhancing Attention’s Periodic Extension for Length General- ization
Fourier Position Embedding: Enhancing Attention's Periodic Extension for Length Generalization , author=. arXiv preprint arXiv:2412.17739 , year=
-
[8]
The Eleventh International Conference on Learning Representations , year=
Progress measures for grokking via mechanistic interpretability , author=. The Eleventh International Conference on Learning Representations , year=
-
[9]
arXiv preprint arXiv:2402.09469 , year=
Fourier circuits in neural networks: Unlocking the potential of large language models in mathematical reasoning and modular arithmetic , author=. arXiv preprint arXiv:2402.09469 , year=
-
[10]
Advances in neural information processing systems , volume=
The clock and the pizza: Two stories in mechanistic explanation of neural networks , author=. Advances in neural information processing systems , volume=
-
[11]
arXiv preprint arXiv:2301.02679 , year=
Grokking modular arithmetic , author=. arXiv preprint arXiv:2301.02679 , year=
-
[12]
doi: 10.18653/ v1/2021.naacl-main.381
Language Models Use Trigonometry to Do Addition , author=. arXiv preprint arXiv:2502.00873 , year=
-
[13]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Pre-trained Large Language Models Use Fourier Features to Compute Addition , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[14]
Language models encode numbers using digit representations in base 10 , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2025
-
[15]
FoNE: Precise Single-Token Number Embeddings via Fourier Features
Fone: Precise single-token number embeddings via fourier features , author=. arXiv preprint arXiv:2502.09741 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
The Thirteenth International Conference on Learning Representations , year=
Not All Language Model Features Are One-Dimensionally Linear , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
McGhee , publisher =
George R. McGhee , publisher =. Convergent Evolution: Limited Forms Most Beautiful , urldate =
-
[18]
Language Models are Unsupervised Multitask Learners , author=
-
[19]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[20]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[21]
2025 , url =
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation , author =. 2025 , url =
2025
-
[22]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
2024 , eprint=
Falcon Mamba: The First Competitive Attention-free 7B Language Model , author=. 2024 , eprint=
2024
-
[24]
2024 , eprint=
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. 2024 , eprint=
2024
-
[25]
2024 , eprint=
xLSTM: Extended Long Short-Term Memory , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
Kimi Linear: An Expressive, Efficient Attention Architecture , author=. 2025 , eprint=
2025
-
[27]
G lo V e: Global Vectors for Word Representation
Pennington, Jeffrey and Socher, Richard and Manning, Christopher. G lo V e: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ). 2014. doi:10.3115/v1/D14-1162
-
[28]
Enriching Word Vectors with Subword Information
Bojanowski, Piotr and Grave, Edouard and Joulin, Armand and Mikolov, Tomas. Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics. 2017. doi:10.1162/tacl_a_00051
-
[29]
Lozhkov, Anton and Ben Allal, Loubna and von Werra, Leandro and Wolf, Thomas , title =. doi:10.57967/hf/2497 , publisher =
-
[30]
Emergent introspective awareness in large language models.arXiv preprint arXiv:2601.01828, 2025
Emergent introspective awareness in large language models , author=. arXiv preprint arXiv:2601.01828 , year=
-
[31]
arXiv preprint arXiv:2602.20031 , year=
Latent Introspection: Models Can Detect Prior Concept Injections , author=. arXiv preprint arXiv:2602.20031 , year=
-
[32]
How does transformer learn implicit reasoning? arXiv preprint arXiv:2505.23653, 2025
How do Transformers Learn Implicit Reasoning? , author=. arXiv preprint arXiv:2505.23653 , year=
-
[33]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[34]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Grokking: Generalization beyond overfitting on small algorithmic datasets , author=. arXiv preprint arXiv:2201.02177 , year=
work page internal anchor Pith review arXiv
-
[35]
Physics of language models: Part 4.1, architecture design and the magic of canon layers, 2025
Physics of Language Models: Part 4.1, Architecture design and the magic of Canon layers , author=. arXiv preprint arXiv:2512.17351 , year=
-
[36]
interpreting GPT: the logit lens , author=
-
[37]
and Nava, Andres and Wyart, Matthieu and Bahri, Yasaman , title =
Symmetry in language statistics shapes the geometry of model representations , author=. arXiv preprint arXiv:2602.15029 , year=
-
[38]
2025 , url=
Hadas Orgad and Michael Toker and Zorik Gekhman and Roi Reichart and Idan Szpektor and Hadas Kotek and Yonatan Belinkov , booktitle=. 2025 , url=
2025
- [39]
-
[40]
2024 , eprint=
Linear Recursive Feature Machines provably recover low-rank matrices , author=. 2024 , eprint=
2024
-
[41]
International Conference on Machine Learning , pages=
Data Shapley: Equitable Valuation of Data for Machine Learning , author=. International Conference on Machine Learning , pages=
-
[42]
Proceedings of the 34th International Conference on Machine Learning , pages =
Understanding Black-box Predictions via Influence Functions , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[43]
Causal Representation Learning Workshop at NeurIPS 2023 , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Causal Representation Learning Workshop at NeurIPS 2023 , year=
2023
-
[44]
arXiv preprint arXiv:2308.03296 , year=
Studying large language model generalization with influence functions , author=. arXiv preprint arXiv:2308.03296 , year=
-
[45]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[46]
The Thirteenth International Conference on Learning Representations , year=
Gated Delta Networks: Improving Mamba2 with Delta Rule , author=. The Thirteenth International Conference on Learning Representations , year=
-
[47]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[48]
Hochreiter, Sepp and Schmidhuber, Jürgen , title =. Neural Computation , volume =. 1997 , month =. doi:10.1162/neco.1997.9.8.1735 , url =
-
[49]
Transformers are
Tri Dao and Albert Gu , booktitle=. Transformers are. 2024 , url=
2024
-
[50]
Proceedings of the 41st International Conference on Machine Learning , pages =
Position: The Platonic Representation Hypothesis , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.