ERA: Evidence-based Reliability Alignment for Honest Retrieval-Augmented Generation
Pith reviewed 2026-05-15 20:17 UTC · model grok-4.3
The pith
ERA shifts RAG confidence estimation to evidence distributions to handle knowledge conflicts and improve abstention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing knowledge sources as independent Dirichlet belief masses and measuring their conflict with Dempster-Shafer Theory, ERA disentangles epistemic uncertainty from aleatoric uncertainty in RAG, enabling conflict-modulated optimization that yields superior calibration and abstention behavior compared to scalar baselines.
What carries the argument
Contextual Evidence Quantification using Dirichlet distributions combined with Quantifying Knowledge Conflict via Dempster-Shafer Theory to compute geometric discordance between internal and external knowledge.
If this is right
- Systems can explicitly detect when retrieved information conflicts with model parameters.
- Abstention decisions improve by focusing on epistemic uncertainty rather than total uncertainty.
- Calibration of reliability estimates becomes more accurate in hybrid knowledge settings.
- Performance holds on both standard benchmarks and held-out generalization sets.
Where Pith is reading between the lines
- Similar conflict quantification could apply to multi-modal or multi-agent systems with conflicting information.
- Developers might use this to create RAG pipelines that are more transparent about their uncertainty sources.
- Further research could test whether DST-based methods scale better than ensemble methods for uncertainty in large models.
Load-bearing premise
That internal and external knowledge can be modeled as independent belief masses with the Dirichlet distribution and that their conflicts can be measured by geometric discordance in Dempster-Shafer Theory to separate the two types of uncertainty.
What would settle it
A replication study on the same benchmarks and generalization dataset that finds no improvement in the coverage-abstention trade-off or calibration metrics would disprove the performance advantage.
Figures






read the original abstract
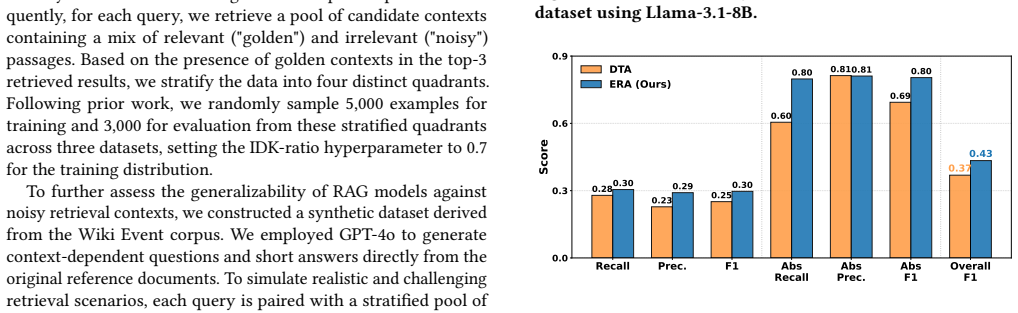
Retrieval-Augmented Generation (RAG) grounds language models in factual evidence but introduces critical challenges regarding knowledge conflicts between internalized parameters and retrieved information. However, existing reliability methods, typically relying on scalar confidence, fail to explicitly distinguish between epistemic uncertainty and inherent data ambiguity in such hybrid scenarios. In this paper, we propose a new framework called ERA (Evidence-based Reliability Alignment) to enhance abstention behavior in RAG systems by shifting confidence estimation from scalar probabilities to explicit evidence distributions. Our method consists of two main components: (1) Contextual Evidence Quantification, which models internal and external knowledge as independent belief masses via the Dirichlet distribution, and (2) Quantifying Knowledge Conflict, which leverages Dempster-Shafer Theory (DST) to rigorously measure the geometric discordance between information sources. These components are used to disentangle epistemic uncertainty from aleatoric uncertainty and modulate the optimization objective based on detected conflicts. Experiments on standard benchmarks and a curated generalization dataset demonstrate that our approach significantly outperforms baselines, optimizing the trade-off between answer coverage and abstention with superior calibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ERA, a framework for honest RAG that models internal parametric knowledge and retrieved external evidence as independent belief masses under a Dirichlet distribution, then applies Dempster-Shafer Theory to compute geometric discordance between sources. This is used to disentangle epistemic from aleatoric uncertainty and modulate the optimization objective to improve the coverage-abstention trade-off and calibration. Experiments on standard benchmarks and a curated generalization dataset are claimed to demonstrate significant outperformance over baselines.
Significance. If the independence assumption holds and the DST-based discordance metric correctly separates uncertainty types without distortion, the approach could provide a principled, parameter-free way to handle knowledge conflicts in hybrid RAG settings using established tools. This would strengthen reliability methods beyond scalar confidence scores. The absence of new invented entities or free parameters in the core derivation is a strength.
major comments (2)
- [Contextual Evidence Quantification] Contextual Evidence Quantification section: The framework requires internal and external knowledge sources to be modeled as independent belief masses under the Dirichlet distribution so that DST can rigorously measure geometric discordance and separate epistemic from aleatoric uncertainty. In RAG, however, retrieved passages are typically produced or filtered by models whose parameters overlap with the generator's training distribution, inducing dependence that violates the premise and can distort the DST combination rule.
- [Experiments] Experiments section and abstract: The central claim is that ERA 'significantly outperforms baselines' while optimizing coverage-abstention with superior calibration, yet the provided description supplies no concrete metrics (e.g., accuracy, abstention rate, ECE), baseline names, dataset sizes, or statistical tests. Without these details it is impossible to verify whether the data support the performance assertions.
minor comments (1)
- [Abstract] Abstract: 'Standard benchmarks' and 'curated generalization dataset' are referenced without naming the specific datasets or providing sizes; these should be stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Contextual Evidence Quantification section: The framework requires internal and external knowledge sources to be modeled as independent belief masses under the Dirichlet distribution so that DST can rigorously measure geometric discordance and separate epistemic from aleatoric uncertainty. In RAG, however, retrieved passages are typically produced or filtered by models whose parameters overlap with the generator's training distribution, inducing dependence that violates the premise and can distort the DST combination rule.
Authors: We model the internal parametric knowledge and external retrieved evidence as independent Dirichlet belief masses by construction to enable the DST combination rule and geometric discordance computation. While we acknowledge that real-world RAG pipelines may introduce some statistical dependence due to shared training data, the framework treats the two sources as separate evidence streams for the purpose of uncertainty disentanglement. This is a deliberate modeling choice that preserves the parameter-free nature of the approach. In the revision we will add a dedicated paragraph discussing the independence assumption, its potential violations, and supporting empirical checks on discordance sensitivity. revision: partial
-
Referee: Experiments section and abstract: The central claim is that ERA 'significantly outperforms baselines' while optimizing coverage-abstention with superior calibration, yet the provided description supplies no concrete metrics (e.g., accuracy, abstention rate, ECE), baseline names, dataset sizes, or statistical tests. Without these details it is impossible to verify whether the data support the performance assertions.
Authors: The full manuscript contains the requested quantitative details, including accuracy, abstention rates, ECE, specific baselines (e.g., vanilla RAG, entropy-based abstention, and prior DST variants), dataset sizes, and statistical significance tests across standard benchmarks and the generalization set. We will revise the abstract and Experiments section to explicitly report the key numerical results and statistical tests so that the performance claims are self-contained and verifiable without requiring the full tables. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper applies standard Dirichlet distributions and Dempster-Shafer Theory as off-the-shelf tools to represent belief masses and measure discordance between internal and external knowledge sources. No equations reduce by construction to fitted parameters renamed as predictions, no self-definitional loops appear in the modeling steps, and no load-bearing uniqueness claims or ansatzes are smuggled via self-citation. The independence premise is an explicit modeling choice rather than a derived result, and the central claims rest on benchmark experiments that remain externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Internal and external knowledge can be modeled as independent belief masses using the Dirichlet distribution
- domain assumption Dempster-Shafer Theory can rigorously measure geometric discordance between information sources
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique Through Self-Reflection. InProceedings of the International Conference on Learning Representations
work page 2024
-
[2]
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic Parsing on Freebase from Question-Answer Pairs. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 1533–1544
work page 2013
-
[3]
Bertrand Charpentier, Daniel Zügner, and Stephan Günnemann. 2020. Posterior Network: Uncertainty Estimation Without OOD Samples via Density-Based Pseudo-Counts. InAdvances in Neural Information Processing Systems, Vol. 33. 1356–1367
work page 2020
-
[4]
Lu Chen, Ruqing Zhang, Jiafeng Guo, Yixing Fan, and Xueqi Cheng. 2024. Con- trolling Risk of Retrieval-Augmented Generation: A Counterfactual Prompting Framework. InFindings of the Association for Computational Linguistics: EMNLP. 2380–2393
work page 2024
-
[5]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R Glass, and Pengcheng He. 2024. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. InProceedings of the International Conference on Learning Representations
work page 2024
-
[6]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Feiteng Fang, Yuelin Bai, Shiwen Ni, Min Yang, Xiaojun Chen, and Ruifeng Xu
-
[8]
InProceedings of the Annual Meeting of the Association for Computational Linguistics
Enhancing Noise Robustness of Retrieval-Augmented Language Models with Adaptive Adversarial Training. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 10028–10039
-
[9]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a Bayesian Approxima- tion: Representing Model Uncertainty in Deep Learning. InProceedings of the International Conference on Machine Learning. PMLR, 1050–1059
work page 2016
-
[10]
Nuno M Guerreiro, Elena Voita, and André FT Martins. 2023. Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation. InProceedings of the Conference of the European Chapter of the Association for Computational Linguistics. 1059–1075
work page 2023
-
[11]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On Calibration of Modern Neural Networks. InProceedings of the International Conference on Machine Learning. PMLR, 1321–1330
work page 2017
-
[12]
Avelina A Hadji-Kyriacou and Ognjen Arandjelović. 2024. Would I Lie to You? Inference Time Alignment of Language Models Using Direct Preference Heads. InAdvances in Neural Information Processing Systems, Vol. 37. 95380–95405
work page 2024
-
[13]
Zongbo Han, Changqing Zhang, Huazhu Fu, and Joey Tianyi Zhou. 2022. Trusted Multi-View Classification with Dynamic Evidential Fusion.IEEE Transactions on Pattern Analysis and Machine Intelligence45, 2 (2022), 2551–2566
work page 2022
-
[14]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi- Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Augmented Generation. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 7969–7992
work page 2023
-
[15]
Mingyu Jin, Weidi Luo, Sitao Cheng, Xinyi Wang, Wenyue Hua, Ruixiang Tang, William Yang Wang, and Yongfeng Zhang. 2025. Disentangling Memory and Rea- soning Ability in Large Language Models. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 1681–1701
work page 2025
-
[16]
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehen- sion.arXiv preprint arXiv:1705.03551(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
2018.Subjective Logic: A Formalism for Reasoning Under Uncertainty
Audun Jsang. 2018.Subjective Logic: A Formalism for Reasoning Under Uncertainty. Springer Publishing Company, Incorporated
work page 2018
-
[18]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, et al. 2022. Language Models (Mostly) Know What They Know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. 2025. Why Language Models Hallucinate.arXiv preprint arXiv:2509.04664(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 6769–6781
work page 2020
-
[21]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic Uncertainty: Lin- guistic Invariances for Uncertainty Estimation in Natural Language Generation. InProceedings of the International Conference on Learning Representations
work page 2023
-
[22]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics7 (2019), 453–466
work page 2019
-
[23]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Sim- ple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles. In Advances in Neural Information Processing Systems, Vol. 30
work page 2017
-
[24]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, Vol. 33. 9459– 9474
work page 2020
-
[25]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring How Models Mimic Human Falsehoods. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 3214–3252
work page 2022
-
[26]
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2021. Entity-Based Knowledge Conflicts in Question Answer- ing. InProceedings of the Conference on Empirical Methods in Natural Language Processing
work page 2021
-
[27]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 9802–9822
work page 2023
-
[28]
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On Faithfulness and Factuality in Abstractive Summarization. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 1906–1919
work page 2020
-
[29]
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. 2024. RagTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 10862– 10878
work page 2024
-
[30]
Sungwon Park, Sungwon Han, and Meeyoung Cha. 2025. Enhancing Domain Generalization for Robust Machine-Generated Text Detection.IEEE Transactions on Knowledge and Data Engineering(2025)
work page 2025
-
[31]
Sungwon Park, Sungwon Han, Sundong Kim, Danu Kim, Sungkyu Park, Se- unghoon Hong, and Meeyoung Cha. 2021. Improving unsupervised image clustering with robust learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12278–12287
work page 2021
-
[32]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InAdvances in Neural Information Processing Systems, Vol. 36. 53728–53741
work page 2023
-
[33]
Murat Sensoy, Lance Kaplan, and Melih Kandemir. 2018. Evidential Deep Learn- ing to Quantify Classification Uncertainty. InAdvances in Neural Information Processing Systems, Vol. 31
work page 2018
-
[34]
Murat Sensoy, Maryam Saleki, Simon Julier, Reyhan Aydogan, and John Reid
-
[35]
InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Misclassification Risk and Uncertainty Quantification in Deep Classifiers. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2484–2492
-
[36]
SungUk Shin and Youngjoon Kim. 2025. Enhancing graph of thought: Enhancing prompts with LLM rationales and dynamic temperature control. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[37]
Xin Sun, Jianan Xie, Zhongqi Chen, Qiang Liu, Shu Wu, Yuehe Chen, Bowen Song, Zilei Wang, Weiqiang Wang, and Liang Wang. 2025. Divide-Then-Align: Honest Alignment Based on the Knowledge Boundary of RAG. InProceedings of the Annual Meeting of the Association for Computational Linguistics. 11461–11480
work page 2025
-
[38]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InProceedings of the International Conference on Learning Representations
work page 2023
-
[39]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-Thought Prompting Elicits Rea- soning in Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 35. 24824–24837
work page 2022
- [40]
-
[41]
Di Wu, Jia-Chen Gu, Fan Yin, Nanyun Peng, and Kai-Wei Chang. 2024. Synchro- nous Faithfulness Monitoring for Trustworthy Retrieval-Augmented Generation. InProceedings of the Conference on Empirical Methods in Natural Language Pro- cessing. 9390–9406
work page 2024
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A Smith. 2024. How Language Model Hallucinations Can Snowball. InProceedings of the International Conference on Machine Learning. 59670–59684. Sunguk Shin, Meeyoung Cha, Byung-Jun Lee, and Sungwon Park A Appendix A.1 Training Details We release the source code and dataset forERAat https://anonym...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.