Recognition: unknown
Optimizing Diffusion Priors in Image Reconstruction from a Single Observation
Pith reviewed 2026-05-10 00:17 UTC · model grok-4.3
The pith
A product-of-experts combination of diffusion priors can be tuned from a single observation by maximizing Bayesian evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that by forming a product-of-experts prior from several diffusion models and optimizing the exponents through maximization of the Bayesian evidence computed on a lone observation, one obtains a more generalizable prior suitable for reconstructing images in challenging inverse problems where the ground-truth distribution is unknown.
What carries the argument
The product-of-experts prior whose exponents are chosen to maximize the evidence of a single measurement under the combined model.
If this is right
- Posterior sampling becomes possible from both tempered and combined diffusion models.
- The approach produces priors that extend beyond those trained on any single dataset.
- Image reconstructions gain trustworthiness in settings like black hole imaging with unknown true priors.
- Text-conditioned deblurring benefits from the exponent-weighted combination.
- No large collection of observations with different forward operators is required for prior tuning.
Where Pith is reading between the lines
- The technique may extend to selecting among other types of generative priors in data-scarce Bayesian inference.
- Evidence-based exponent tuning could reduce overfitting risks when adapting models to new domains with minimal data.
- It opens the possibility of dynamically weighting priors based on how well they explain the available observation.
Load-bearing premise
That the exponent values maximizing the Bayesian evidence on one observation will produce a prior whose induced posterior reliably approximates the true solution distribution.
What would settle it
A test where synthetic data is generated from a known ground-truth distribution, a single observation is created, the exponents are optimized, and the sampled posteriors are compared to the known true distribution for accuracy and calibration.
Figures












read the original abstract
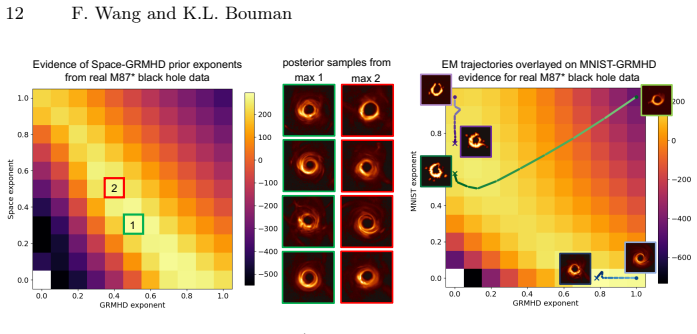
While diffusion priors generate high-quality posterior samples across many inverse problems, they are often trained on limited training sets or purely simulated data, thus inheriting the errors and biases of these underlying sources. Current approaches to finetuning diffusion models rely on a large number of observations with varying forward operators, which can be difficult to collect for many applications, and thus lead to overfitting when the measurement set is small. We propose a method for tuning a prior from only a single observation by combining existing diffusion priors into a single product-of-experts prior and identifying the exponents that maximize the Bayesian evidence. We validate our method on real-world inverse problems, including black hole imaging, where the true prior is unknown a priori, and image deblurring with text-conditioned priors. We find that the evidence is often maximized by priors that extend beyond those trained on a single dataset. By generalizing the prior through exponent weighting, our approach enables posterior sampling from both tempered and combined diffusion models, yielding more flexible priors that improve the trustworthiness of the resulting posterior image distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a method for tuning diffusion priors from a single observation by forming a product-of-experts combination of existing diffusion models and selecting the combination exponents that maximize the Bayesian evidence p(y|alpha). It asserts that this yields more flexible priors (including tempered and multi-dataset combinations) that improve the trustworthiness of posterior samples in inverse problems, with validation on black-hole imaging (where the true prior is unknown) and text-conditioned image deblurring.
Significance. If the central claim holds, the work would be significant for data-scarce inverse problems in computer vision and scientific imaging, where collecting multiple observations or large training sets is impractical. It offers a principled, evidence-based route to adapt and combine pre-trained diffusion priors without additional data collection, potentially reducing biases from limited training distributions while enabling posterior sampling from hybrid models.
major comments (3)
- [Abstract / Method] The core procedure for estimating the marginal likelihood p(y | alpha) = integral p(y|x) p(x|alpha) dx in high-dimensional image space is load-bearing for the claim, yet the abstract supplies no equations, approximation scheme (e.g., variational or Monte-Carlo), or variance analysis; high-variance estimates from a single y can favor exponents that fit noise realizations rather than the data distribution.
- [Experiments] Validation on black-hole imaging and deblurring does not include a stability test: whether the argmax_alpha remains consistent or optimal when a second independent observation y' drawn from the same forward model is substituted. This directly tests the generalizability of the evidence-maximized prior and is required to address the overfitting risk.
- [Abstract / Results] The claim that 'evidence is often maximized by priors that extend beyond those trained on a single dataset' is central but unsupported by any reported quantitative metrics, baselines, or error bars in the abstract; without these, it is impossible to judge whether the improvement in posterior trustworthiness is statistically meaningful or merely anecdotal.
minor comments (2)
- [Method] Clarify the precise definition of the product-of-experts prior (including how the exponents enter the joint density) and any normalization constants that may be required for proper Bayesian evidence computation.
- [Abstract] The abstract mentions 'tempered and combined diffusion models' without a brief reference or equation; a short parenthetical or citation would improve readability for readers unfamiliar with tempering in diffusion literature.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of clarity, validation, and evidence presentation. We address each major comment below and will revise the manuscript accordingly to strengthen the work while preserving its core contributions.
read point-by-point responses
-
Referee: [Abstract / Method] The core procedure for estimating the marginal likelihood p(y | alpha) = integral p(y|x) p(x|alpha) dx in high-dimensional image space is load-bearing for the claim, yet the abstract supplies no equations, approximation scheme (e.g., variational or Monte-Carlo), or variance analysis; high-variance estimates from a single y can favor exponents that fit noise realizations rather than the data distribution.
Authors: We agree that the abstract would benefit from greater specificity on the marginal likelihood estimation. The method section describes a Monte Carlo approximation to p(y|alpha) that leverages samples drawn from the product-of-experts diffusion prior, together with importance weighting to reduce variance. We will revise the abstract to include the defining integral, a concise statement of the Monte Carlo scheme, and a brief note on variance control. This addition will make the procedure transparent without changing the technical approach. revision: yes
-
Referee: [Experiments] Validation on black-hole imaging and deblurring does not include a stability test: whether the argmax_alpha remains consistent or optimal when a second independent observation y' drawn from the same forward model is substituted. This directly tests the generalizability of the evidence-maximized prior and is required to address the overfitting risk.
Authors: We acknowledge the value of an explicit stability test for assessing overfitting risk. In the black-hole imaging experiment only a single real observation exists, precluding a second independent y'; this is the motivating data-scarce regime. For the synthetic deblurring experiments we can generate additional independent observations under the same forward model. We will add a stability analysis in the revised manuscript that reports the consistency of the selected exponents across multiple y' draws and quantifies any variation in downstream posterior metrics. This will directly address the generalizability concern for the cases where it is feasible. revision: partial
-
Referee: [Abstract / Results] The claim that 'evidence is often maximized by priors that extend beyond those trained on a single dataset' is central but unsupported by any reported quantitative metrics, baselines, or error bars in the abstract; without these, it is impossible to judge whether the improvement in posterior trustworthiness is statistically meaningful or merely anecdotal.
Authors: We agree that the abstract should convey the quantitative support for this claim. The results section already contains comparisons against single-dataset baselines together with error bars obtained from repeated posterior sampling runs. We will revise the abstract to include concise quantitative statements (e.g., average improvement in a trustworthiness metric with standard deviation) that summarize the evidence-maximization findings. This will allow readers to assess statistical meaningfulness directly from the abstract while retaining the full details in the main text. revision: yes
Circularity Check
Exponents for product-of-experts prior are fitted by maximizing evidence on the single observation y itself
specific steps
-
fitted input called prediction
[Abstract]
"We propose a method for tuning a prior from only a single observation by combining existing diffusion priors into a single product-of-experts prior and identifying the exponents that maximize the Bayesian evidence."
The exponents are identified by maximizing evidence on the single observation y; the resulting prior is then applied to reconstruct from that same y. The optimization step therefore fits the prior parameters directly to the target data, making the 'tuned prior' and its posterior samples statistically dependent on y by construction rather than independently derived.
full rationale
The paper's central procedure selects the exponents alpha by maximizing Bayesian evidence p(y|alpha) on the identical single observation y that is later used for posterior sampling p(x|y,alpha). This matches the fitted-input-called-prediction pattern: the prior is tuned directly to the target data rather than derived from independent sources or held-out statistics. While the abstract presents this as a generalizable tuning method, the load-bearing step reduces the prior choice to a fit on y, creating partial circularity in the claim that the resulting posterior is trustworthy. No other self-citation or self-definitional reductions are evident from the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- exponents for each prior
axioms (1)
- domain assumption Product-of-experts combination of diffusion priors forms a valid and flexible joint prior
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2403.08728 , year=
Aali, A., Daras, G., Levac, B., Kumar, S., Dimakis, A.G., Tamir, J.I.: Ambient diffusionposteriorsampling:Solvinginverseproblemswithdiffusionmodelstrained on corrupted data. arXiv preprint arXiv:2403.08728 (2024)
-
[2]
Alam, M.T., Imam, R., Guizani, M., Karray, F.: Flare up your data: Diffusion- based augmentation method in astronomical imaging (2024)
2024
-
[3]
Advances in Neural Information Processing Systems37, 19447–19471 (2024)
Bai, W., Wang, Y., Chen, W., Sun, H.: An expectation-maximization algorithm for training clean diffusion models from corrupted observations. Advances in Neural Information Processing Systems37, 19447–19471 (2024)
2024
-
[4]
The Astrophysical Journal980(1), 108 (2025)
Barco, G.M., Adam, A., Stone, C., Hezaveh, Y., Perreault-Levasseur, L.: Tack- ling the problem of distributional shifts: Correcting misspecified, high-dimensional data-driven priors for inverse problems. The Astrophysical Journal980(1), 108 (2025)
2025
-
[5]
The Astrophysical Journal894(1), 31 (2020)
Blackburn, L., Pesce, D.W., Johnson, M.D., Wielgus, M., Chael, A.A., Christian, P., Doeleman, S.S.: Closure statistics in interferometric data. The Astrophysical Journal894(1), 31 (2020)
2020
-
[6]
arXiv preprint arXiv:2310.06721 , year=
Boys, B., Girolami, M., Pidstrigach, J., Reich, S., Mosca, A., Akyildiz, O.D.: Tweedie moment projected diffusions for inverse problems. arXiv preprint arXiv:2310.06721 (2023)
-
[7]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sam- pling for general noisy inverse problems. arXiv preprint arXiv:2209.14687 (2022)
work page internal anchor Pith review arXiv 2022
-
[8]
arXiv preprint arXiv:2310.01110 (2023)
Chung, H., Ye, J.C., Milanfar, P., Delbracio, M.: Prompt-tuning latent diffusion models for inverse problems. arXiv preprint arXiv:2310.01110 (2023)
-
[9]
IEEE Transactions on Image Processing33, 3496–3507 (2024)
Coeurdoux, F., Dobigeon, N., Chainais, P.: Plug-and-play split gibbs sampler: em- bedding deep generative priors in bayesian inference. IEEE Transactions on Image Processing33, 3496–3507 (2024)
2024
-
[10]
arXiv preprint arXiv:2404.10177 (2024)
Daras, G., Dimakis, A.G., Daskalakis, C.: Consistent diffusion meets tweedie: Training exact ambient diffusion models with noisy data. arXiv preprint arXiv:2404.10177 (2024)
-
[11]
Advances in Neural Information Processing Systems36, 288–313 (2023)
Daras, G., Shah, K., Dagan, Y., Gollakota, A., Dimakis, A., Klivans, A.: Ambient diffusion: Learning clean distributions from corrupted data. Advances in Neural Information Processing Systems36, 288–313 (2023)
2023
-
[12]
Journal of the Royal Statistical Society Series B: Statistical Methodology68(3), 411–436 (2006)
Del Moral, P., Doucet, A., Jasra, A.: Sequential monte carlo samplers. Journal of the Royal Statistical Society Series B: Statistical Methodology68(3), 411–436 (2006)
2006
-
[13]
IEEE signal processing magazine29(6), 141–142 (2012)
Deng, L.: The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE signal processing magazine29(6), 141–142 (2012)
2012
-
[14]
In: International confer- ence on machine learning
Du, Y., Durkan, C., Strudel, R., Tenenbaum, J.B., Dieleman, S., Fergus, R., Sohl- Dickstein, J., Doucet, A., Grathwohl, W.S.: Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc. In: International confer- ence on machine learning. pp. 8489–8510. PMLR (2023)
2023
-
[15]
Wang and K.L
EHTC: First m87 eht results: Calibrated data (2019) 16 F. Wang and K.L. Bouman
2019
-
[16]
EHTC: First m87 event horizon telescope results. i. the shadow of the supermassive black hole. The Astrophysical Journal Letters875(1) (2019)
2019
-
[17]
The Astrophysical Journal975(2), 201 (2024)
Feng, B.T., Bouman, K.L., Freeman, W.T.: Event-horizon-scale imaging of m87* under different assumptions via deep generative image priors. The Astrophysical Journal975(2), 201 (2024)
2024
-
[18]
In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Gao, A.F., Leong, O., Sun, H., Bouman, K.L.: Image reconstruction without ex- plicit priors. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
-
[19]
Geffner, T., Didi, K., Zhang, Z., Reidenbach, D., Cao, Z., Yim, J., Geiger, M., Dallago, C., Kucukbenli, E., Vahdat, A., et al.: Proteina: Scaling flow-based protein structure generative models. arXiv preprint arXiv:2503.00710 (2025)
-
[20]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[21]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review arXiv 2022
-
[22]
Communications in Statistics-Simulation and Com- putation18(3), 1059–1076 (1989)
Hutchinson, M.F.: A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines. Communications in Statistics-Simulation and Com- putation18(3), 1059–1076 (1989)
1989
-
[23]
Li, X., Kwon, S.M., Liang, S., Alkhouri, I.R., Ravishankar, S., Qu, Q.: Decoupled data consistency with diffusion purification for image restoration. arXiv preprint arXiv:2403.06054 (2024)
-
[24]
Universe8(2), 85 (2022)
Mizuno, Y.: Grmhd simulations and modeling for jet formation and acceleration region in agns. Universe8(2), 85 (2022)
2022
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[26]
Advances in Neural Information Processing Systems37, 87647–87682 (2024)
Rozet, F., Andry, G., Lanusse, F., Louppe, G.: Learning diffusion priors from obser- vations by expectation maximization. Advances in Neural Information Processing Systems37, 87647–87682 (2024)
2024
-
[27]
arXiv preprint arXiv:2503.02819 (2025)
Skreta, M., Akhound-Sadegh, T., Ohanesian, V., Bondesan, R., Aspuru-Guzik, A., Doucet, A., Brekelmans, R., Tong, A., Neklyudov, K.: Feynman-kac correc- tors in diffusion: Annealing, guidance, and product of experts. arXiv preprint arXiv:2503.02819 (2025)
-
[28]
arXiv preprint arXiv:2412.17762 (2024)
Skreta, M., Atanackovic, L., Bose, A.J., Tong, A., Neklyudov, K.: The super- position of diffusion models using the it\ˆ o density estimator. arXiv preprint arXiv:2412.17762 (2024)
-
[29]
In: International Conference on Learning Representations (2023)
Song, J., Vahdat, A., Mardani, M., Kautz, J.: Pseudoinverse-guided diffusion mod- els for inverse problems. In: International Conference on Learning Representations (2023)
2023
-
[30]
Advances in neural information processing systems34, 1415–1428 (2021)
Song, Y., Durkan, C., Murray, I., Ermon, S.: Maximum likelihood training of score- based diffusion models. Advances in neural information processing systems34, 1415–1428 (2021)
2021
-
[31]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[32]
Acta numerica19, 451–559 (2010)
Stuart, A.M.: Inverse problems: a bayesian perspective. Acta numerica19, 451–559 (2010)
2010
-
[33]
Springer Nature (2017)
Thompson, A.R., Moran, J.M., Swenson, G.W.: Interferometry and synthesis in radio astronomy. Springer Nature (2017)
2017
-
[34]
Sample-efficient evidence estimation of score based priors for model selection
Wang, F., Bouman, K.L.: Sample-efficient evidence estimation of score based priors for model selection. arXiv preprint arXiv:2602.20549 (2026) Optimizing Diffusion Priors with a Single Observation 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Advances in Neural Infor- mation Processing Systems36, 31372–31403 (2023)
Wu, L., Trippe, B., Naesseth, C., Blei, D., Cunningham, J.P.: Practical and asymp- totically exact conditional sampling in diffusion models. Advances in Neural Infor- mation Processing Systems36, 31372–31403 (2023)
2023
-
[36]
Advances in Neural Information Processing Systems37, 118389–118427 (2024)
Wu, Z., Sun, Y., Chen, Y., Zhang, B., Yue, Y., Bouman, K.: Principled proba- bilistic imaging using diffusion models as plug-and-play priors. Advances in Neural Information Processing Systems37, 118389–118427 (2024)
2024
-
[37]
arXiv preprint arXiv:2510.01184 (2025) 14
Xu, Y., Wu, Y., Park, S., Zhou, Z., Tulsiani, S.: Temporal score rescaling for tem- perature sampling in diffusion and flow models. arXiv preprint arXiv:2510.01184 (2025)
-
[38]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, B., Chu, W., Berner, J., Meng, C., Anandkumar, A., Song, Y.: Improving diffusion inverse problem solving with decoupled noise annealing. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20895–20905 (2025)
2025
-
[39]
arXiv preprint arXiv:2506.08894 , year=
Zhang, Y., Murtuza-Lanier, C., Li, Z., Du, Y., Wu, J.: Product of experts for visual generation. arXiv preprint arXiv:2506.08894 (2025)
-
[40]
arXiv preprint arXiv:2503.11043 , year=
Zheng, H., Chu, W., Zhang, B., Wu, Z., Wang, A., Feng, B.T., Zou, C., Sun, Y., Ko- vachki, N., Ross, Z.E., et al.: Inversebench: Benchmarking plug-and-play diffusion priors for inverse problems in physical sciences. arXiv preprint arXiv:2503.11043 (2025)
-
[41]
Zhu, Y., Dou, Z., Zheng, H., Zhang, Y., Wu, Y.N., Gao, R.: Think twice before you act: Improving inverse problem solving with mcmc, 2024. URL https://arxiv. org/abs/2409.085511(2)
-
[42]
Optimizing Diffusion Priors in Image Reconstruction from a Single Observation
Zhu, Y., Zhang, K., Liang, J., Cao, J., Wen, B., Timofte, R., Van Gool, L.: De- noising diffusion models for plug-and-play image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1219–1229 (2023) 18 F. Wang and K.L. Bouman Supplemental for "Optimizing Diffusion Priors in Image Reconstruction from a Sin...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.