Recognition: unknown
Serialisation Strategy Matters: How FHIR Data Format Affects LLM Medication Reconciliation
Pith reviewed 2026-05-10 00:13 UTC · model grok-4.3
The pith
Serialisation strategy has a large effect on LLM performance for medication reconciliation from FHIR data, with clinical narrative best for smaller models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
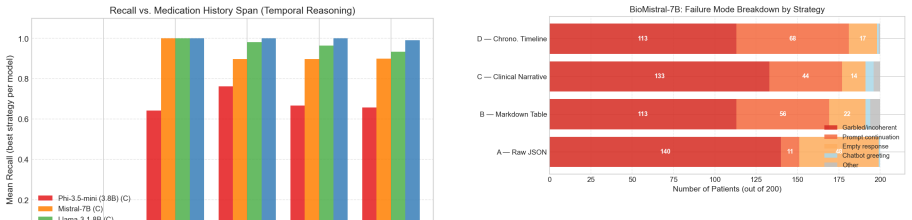
Serialisation strategy has a large, statistically significant effect on performance for models up to 8B parameters: Clinical Narrative outperforms Raw JSON by up to 19 F1 points for Mistral-7B. This advantage reverses at 70B, where Raw JSON achieves the best mean F1 of 0.9956. In all cases, precision exceeds recall, with omission as the dominant error.
What carries the argument
Comparison of four FHIR serialisation strategies (Raw JSON, Markdown Table, Clinical Narrative, and Chronological Timeline) evaluated across five open-weight LLMs on 200 synthetic patient records.
Load-bearing premise
The 200 synthetic patient records sufficiently capture the distribution, noise, and edge cases of real clinical FHIR data.
What would settle it
Evaluating the same models and strategies on a set of real, de-identified clinical FHIR records would test whether the performance differences hold outside the synthetic benchmark.
Figures




read the original abstract
Medication reconciliation at clinical handoffs is a high-stakes, error-prone process. Large language models are increasingly proposed to assist with this task using FHIR-structured patient records, but a fundamental and largely unstudied variable is how the FHIR data is serialised before being passed to the model. We present the first systematic comparison of four FHIR serialisation strategies (Raw JSON, Markdown Table, Clinical Narrative, and Chronological Timeline) across five open-weight models (Phi-3.5-mini, Mistral-7B, BioMistral-7B, Llama-3.1-8B, Llama-3.3-70B) on a controlled benchmark of 200 synthetic patients, totalling 4,000 inference runs. We find that serialisation strategy has a large, statistically significant effect on performance for models up to 8B parameters: Clinical Narrative outperforms Raw JSON by up to 19 F1 points for Mistral-7B (r = 0.617, p < 10^{-10}). This advantage reverses at 70B, where Raw JSON achieves the best mean F1 of 0.9956. In all 20 model and strategy combinations, mean precision exceeds mean recall: omission is the dominant failure mode, with models more often missing an active medication than fabricating one, which changes how clinical safety auditing priorities should be set. Smaller models plateau at roughly 7-10 concurrent active medications, leaving polypharmacy patients, the patients most at risk from reconciliation errors, systematically underserved. BioMistral-7B, a domain-pretrained model without instruction tuning, produces zero usable output in all conditions, showing that domain pretraining alone is not sufficient for structured extraction. These results offer practical, evidence-based format recommendations for clinical LLM deployment: Clinical Narrative for models up to 8B, Raw JSON for 70B and above. The complete pipeline is reproducible on open-source tools running on an AWS g6e.xlarge instance (NVIDIA L40S, 48 GB VRAM).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic empirical comparison of four FHIR serialization strategies (Raw JSON, Markdown Table, Clinical Narrative, Chronological Timeline) across five open-weight LLMs on medication reconciliation using a controlled benchmark of 200 synthetic patients and 4000 inference runs. It claims that serialization strategy has a large, statistically significant effect on performance for models up to 8B parameters (e.g., Clinical Narrative outperforms Raw JSON by up to 19 F1 points for Mistral-7B with r=0.617, p<10^{-10}), with the advantage reversing at 70B where Raw JSON achieves the highest mean F1 of 0.9956; omissions are the dominant error mode in all conditions, smaller models plateau at 7-10 concurrent medications, and BioMistral-7B produces no usable output.
Significance. If the results hold, this work provides actionable, evidence-based guidance for clinical LLM deployment by quantifying the impact of input formatting and its interaction with model scale, supported by statistical rigor and full reproducibility on open-source tools. The observation that domain pretraining without instruction tuning is insufficient is a useful negative result for the field.
major comments (1)
- [Abstract and Methods] Abstract and Methods: The deployment recommendations (Clinical Narrative for models ≤8B, Raw JSON for 70B+) rest on performance differences measured exclusively on 200 synthetic patient records. The manuscript provides no details on the synthetic data generator's construction, validation against real FHIR distributions, or coverage of documentation variability, missing fields, and polypharmacy edge cases. This assumption is load-bearing for generalizability, as the reported F1 gaps, precision-recall patterns, and polypharmacy limitations may not transfer to real clinical data.
minor comments (2)
- [Abstract] Abstract: The statement that 'the complete pipeline is reproducible on open-source tools running on an AWS g6e.xlarge instance' should include an explicit link to the code repository to facilitate verification.
- [Results] Results: The consistent finding that mean precision exceeds mean recall across all 20 model-strategy combinations would benefit from a brief discussion of how this affects clinical safety auditing priorities, as noted in the abstract.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive evaluation of the work's significance. We address the major comment point by point below, with plans to revise the manuscript to improve clarity on the synthetic benchmark.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The deployment recommendations (Clinical Narrative for models ≤8B, Raw JSON for 70B+) rest on performance differences measured exclusively on 200 synthetic patient records. The manuscript provides no details on the synthetic data generator's construction, validation against real FHIR distributions, or coverage of documentation variability, missing fields, and polypharmacy edge cases. This assumption is load-bearing for generalizability, as the reported F1 gaps, precision-recall patterns, and polypharmacy limitations may not transfer to real clinical data.
Authors: We agree that explicit details on the synthetic data generator are necessary to evaluate the scope of our findings. The current manuscript describes the benchmark as a controlled set of 200 synthetic patients but does not elaborate on its construction. In the revised manuscript we will add a new subsection in Methods that specifies: (1) the generator's design, including sampling from empirical distributions for demographics, medication counts, and common polypharmacy patterns drawn from publicly available clinical literature; (2) explicit simulation of missing fields, documentation variability, and edge cases such as duplicate entries or inactive medications; and (3) the rationale for the 7–10 medication plateau observed. We will also add a dedicated Limitations paragraph acknowledging that, while the synthetic data were constructed to reflect realistic clinical distributions, we did not conduct formal statistical validation against a specific real-world FHIR corpus. This controlled synthetic design was chosen precisely to isolate serialization effects from the confounding variability of real EHR data; we will clarify that the reported F1 differences and error patterns are therefore best interpreted as evidence of format sensitivity under standardized conditions rather than direct predictions for live clinical deployment. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with no derivations or self-referential reductions
full rationale
The paper reports results from a controlled set of 4,000 inference runs comparing four serialization formats on 200 synthetic patients across five LLMs. All performance claims (F1 differences, precision-recall patterns, model-size reversals) are direct empirical measurements with no equations, fitted parameters renamed as predictions, or load-bearing self-citations. The central findings rest on observable output statistics rather than any derivation that reduces to the authors' own modeling choices or prior work by the same team.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
JACC: Advances , volume =
Schmiedmayer, Paul and Rao, Adrit and Zagar, Philipp and Aalami, Lauren and Ravi, Vishnu and Zahedivash, Aydin and Yao, Dong-han and Fereydooni, Arash and Aalami, Oliver , title =. JACC: Advances , volume =. 2025 , doi =
2025
-
[2]
and Shinagawa, Yoshihisa and Luo, Yuan , title =
Li, Yikuan and Wang, Hanyin and Yerebakan, Halid Z. and Shinagawa, Yoshihisa and Luo, Yuan , title =. NEJM AI , year =
-
[3]
Clinical Safety and Hallucination Framework for
Asgari, Elham and Monta. Clinical Safety and Hallucination Framework for. npj Digital Medicine , year =
-
[4]
2024 , eprint =
Schmiedmayer, Paul and Rao, Adrit and Zagar, Philipp and Ravi, Vishnu and Zahedivash, Aydin and Fereydooni, Arash and Aalami, Oliver , title =. 2024 , eprint =
2024
-
[5]
Applied Sciences , volume =
Delaunay, Julien and Girbes, Daniel and Cusido, Jordi , title =. Applied Sciences , volume =. 2025 , doi =
2025
-
[6]
2025 , eprint =
Kim, Yubin and Jeong, Hyewon and Chen, Shan and others , title =. 2025 , eprint =
2025
-
[7]
2025 , eprint =
Zeba, Musarrat and Al Mamun, Abdullah and Tithee, Kishoar Jahan and Sutradhar, Debopom and Raiaan, Mohaimenul Azam Khan and Mukta, Saddam , title =. 2025 , eprint =
2025
-
[8]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
Kruse, Maya and Hu, Shiyue and Derby, Nicholas and Wu, Yifu and Stonbraker, Samantha and Yao, Bingsheng and Wang, Dakuo and Goldberg, Elizabeth and Gao, Yanjun , title =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
2025
-
[9]
2026 , eprint =
Wu, Kaiyuan and Nagori, Aditya and Kamaleswaran, Rishikesan , title =. 2026 , eprint =
2026
-
[10]
2024 , eprint =
Abdin, Marah and others , title =. 2024 , eprint =
2024
-
[11]
and Sablayrolles, Alexandre and Mensch, Arthur and others , title =
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and others , title =. 2023 , eprint =
2023
-
[12]
2024 , eprint =
The. 2024 , eprint =
2024
-
[13]
2024 , eprint =
Labrak, Yanis and Bazoge, Adrien and Morin, Emmanuel and Gourraud, Pierre-Antoine and Rouvier, Mickael and Dufour, Richard , title =. 2024 , eprint =
2024
-
[14]
Journal of the American Medical Informatics Association , volume =
Walonoski, Jason and Kramer, Mark and Nichols, Joseph and Quina, Andre and Moesel, Chris and Hall, Dylan and Duffett, Carlton and Dube, Kudakwashe and Gallagher, Thomas and McLachlan, Scott , title =. Journal of the American Medical Informatics Association , volume =. 2018 , doi =
2018
-
[15]
Biometrics Bulletin , volume =
Wilcoxon, Frank , title =. Biometrics Bulletin , volume =. 1945 , doi =
1945
-
[16]
Field, Andy , title =
-
[17]
and Lichtenstein, Richard L
Lantz, Paula M. and Lichtenstein, Richard L. , title =. 2020 , publisher =
2020
-
[18]
Ollama: Get Up and Running with Large Language Models Locally , year =
-
[19]
Marah Abdin and 1 others. 2024. https://arxiv.org/abs/2404.14219 Phi-3 technical report: A highly capable language model locally on your phone . Preprint, arXiv:2404.14219
work page internal anchor Pith review arXiv 2024
-
[20]
Elham Asgari, Nina Monta \ n a-Brown, Magda Dubois, Saleh Khalil, Jasmine Balloch, Joshua Au Yeung, and Dominic Pimenta. 2025. https://doi.org/10.1038/s41746-025-01670-7 Clinical safety and hallucination framework for LLMs in medical text summarisation . npj Digital Medicine
-
[21]
Julien Delaunay, Daniel Girbes, and Jordi Cusido. 2025. https://doi.org/10.3390/app15063379 Evaluating the effectiveness of large language models in converting clinical data to FHIR format . Applied Sciences, 15(6):3379
-
[22]
Andy Field. 2009. Discovering Statistics Using SPSS , 3rd edition. SAGE Publications
2009
-
[23]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, and 1 others. 2023. https://arxiv.org/abs/2310.06825 Mistral 7B . Preprint, arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [24]
-
[25]
Maya Kruse, Shiyue Hu, Nicholas Derby, Yifu Wu, Samantha Stonbraker, Bingsheng Yao, Dakuo Wang, Elizabeth Goldberg, and Yanjun Gao. 2025. Large language models with temporal reasoning for longitudinal clinical summarisation and prediction. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 20715--20735
2025
- [26]
-
[27]
Lantz and Richard L
Paula M. Lantz and Richard L. Lichtenstein. 2020. Prescription drug use among older adults: National Poll on Healthy Aging . National Poll on Healthy Aging
2020
-
[28]
Yikuan Li, Hanyin Wang, Halid Z. Yerebakan, Yoshihisa Shinagawa, and Yuan Luo. 2024. https://doi.org/10.1056/aics2300301 FHIR-GPT enhances health interoperability with large language models . NEJM AI
-
[29]
Llama Team, AI @ Meta . 2024. https://arxiv.org/abs/2407.21783 The Llama 3 herd of models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Paul Schmiedmayer, Adrit Rao, Philipp Zagar, Lauren Aalami, Vishnu Ravi, Aydin Zahedivash, Dong-han Yao, Arash Fereydooni, and Oliver Aalami. 2025. https://doi.org/10.1016/j.jacadv.2025.101780 LLMonFHIR : A physician-validated, LLM -based mobile application for querying patient EHR data . JACC: Advances, 4(6)
- [31]
-
[32]
Jason Walonoski, Mark Kramer, Joseph Nichols, Andre Quina, Chris Moesel, Dylan Hall, Carlton Duffett, Kudakwashe Dube, Thomas Gallagher, and Scott McLachlan. 2018. https://doi.org/10.1093/jamia/ocx079 Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health record . Journal of the American ...
-
[33]
Frank Wilcoxon. 1945. https://doi.org/10.2307/3001968 Individual comparisons by ranking methods . Biometrics Bulletin, 1(6):80--83
- [34]
-
[35]
Musarrat Zeba, Abdullah Al Mamun, Kishoar Jahan Tithee, Debopom Sutradhar, Mohaimenul Azam Khan Raiaan, and Saddam Mukta. 2025. https://arxiv.org/abs/2512.16189 Mitigating hallucinations in healthcare LLMs with granular fact-checking and domain-specific adaptation . Preprint, arXiv:2512.16189
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.