Recognition: unknown
A Hybridizable Neural Time Integrator for Stable Autoregressive Forecasting
Pith reviewed 2026-05-10 00:09 UTC · model grok-4.3
The pith
Embedding an autoregressive transformer in a shooting-based mixed finite element scheme yields provable energy preservation and bounded gradients for stable long-horizon forecasting of chaotic systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
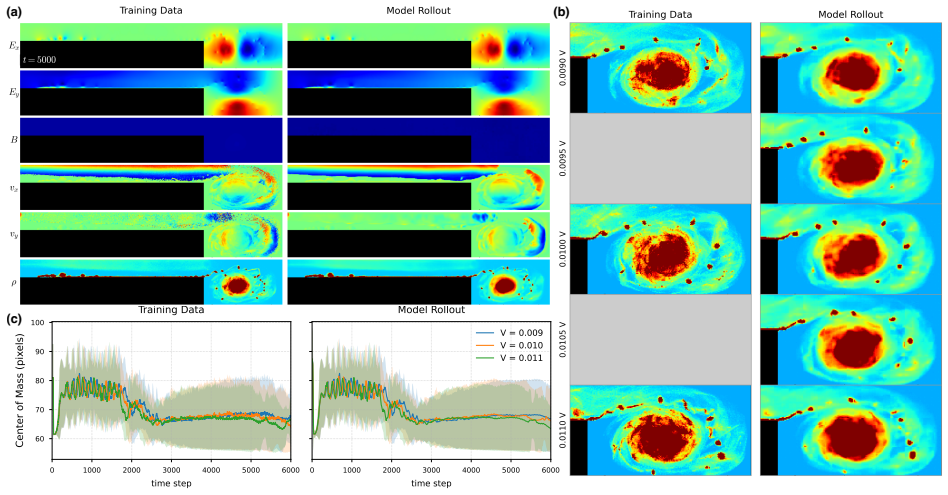
The central claim is that embedding an autoregressive transformer inside a shooting-based mixed finite element scheme exposes topological structure sufficient for rigorous stability guarantees. The scheme preserves discrete energies in forward integration of chaotic systems and enforces uniform gradient bounds during training, thereby eliminating exploding gradients. The same construction allows vision-transformer latent tokens to inherit structure-preserving dynamics, producing compact models that achieve accurate long-horizon forecasts with a 65-fold reduction in parameter count and enable real-time surrogates trained on as few as twelve simulations.
What carries the argument
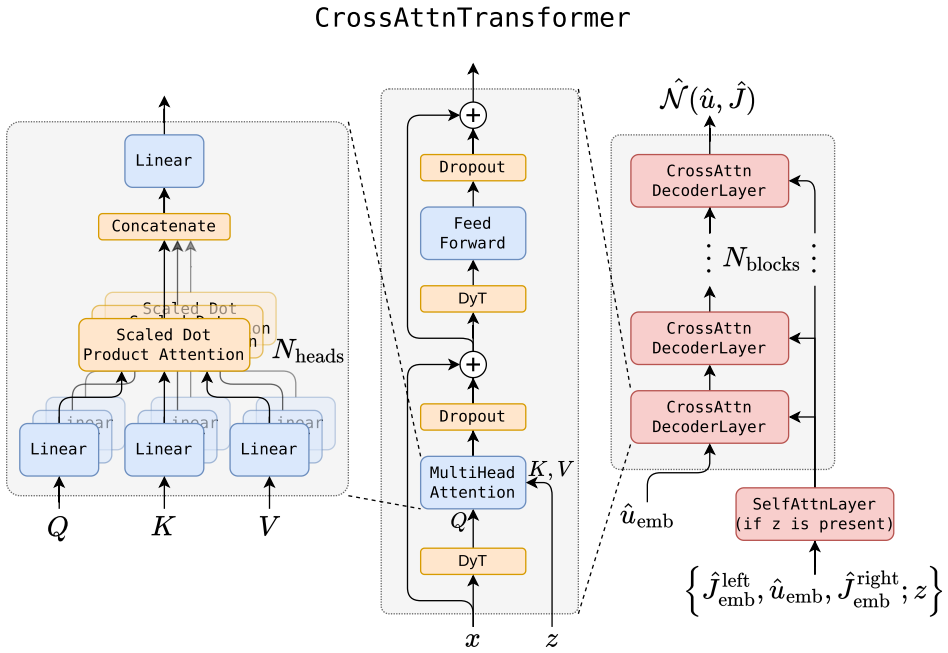
The shooting-based mixed finite element scheme that embeds the autoregressive transformer and thereby preserves the topological structure required for energy and gradient proofs.
Load-bearing premise
That placing the trained autoregressive transformer inside the shooting-based mixed finite element scheme still preserves the topological structure needed for the energy-preservation and gradient-bound proofs to hold.
What would settle it
A long-horizon simulation or training run of the hybrid model on a chaotic system that exhibits either measurable energy drift or gradient explosion would falsify the stability guarantees.
Figures




read the original abstract
For autoregressive modeling of chaotic dynamical systems over long time horizons, the stability of both training and inference is a major challenge in building scientific foundation models. We present a hybrid technique in which an autoregressive transformer is embedded within a novel shooting-based mixed finite element scheme, exposing topological structure that enables provable stability. For forward problems, we prove preservation of discrete energies, while for training we prove uniform bounds on gradients, provably avoiding the exploding gradient problem. Combined with a vision transformer, this yields latent tokens admitting structure-preserving dynamics. We outperform modern foundation models with a $65\times$ reduction in model parameters and long-horizon forecasting of chaotic systems. A "mini-foundation" model of a fusion component shows that 12 simulations suffice to train a real-time surrogate, achieving a $9{,}000\times$ speedup over particle-in-cell simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes embedding an autoregressive transformer inside a novel shooting-based mixed finite element scheme to create a hybridizable neural time integrator. This construction is claimed to expose topological structure that yields provable discrete energy preservation for forward integration of chaotic systems and uniform gradient bounds during training (avoiding explosion). The method is paired with a vision transformer to produce latent tokens with structure-preserving dynamics, and is demonstrated to outperform larger foundation models while using 65x fewer parameters; a mini-foundation surrogate for a fusion component is trained from only 12 simulations and achieves a 9,000x speedup over particle-in-cell codes.
Significance. If the central stability proofs hold after the neural embedding and training, the work would be significant: it offers a concrete route to marry data-driven autoregressive models with structure-preserving discretizations, delivering reliable long-horizon forecasts of chaotic dynamics at far lower parameter counts than current foundation-model baselines. The reported efficiency gains on a real fusion surrogate further suggest immediate applicability in scientific computing.
major comments (2)
- [Abstract / hybrid scheme] Abstract and hybrid-scheme section: the proofs of discrete energy preservation and uniform gradient bounds are asserted to follow directly from the topological structure exposed by the mixed finite-element / shooting framework once the transformer is embedded. No explicit verification is supplied that the trained neural map respects the algebraic properties (exact-sequence preservation, bounded Lipschitz constant, or symplectic structure) on which those proofs rely; training can alter the effective operator and thereby invalidate the claims.
- [Hybrid technique description] The weakest assumption—that the embedding of the trained autoregressive transformer preserves the topological structure required for the energy and gradient results—is load-bearing for the entire stability narrative. Without a concrete check (e.g., post-training verification of the discrete energy or a Lipschitz bound on the learned map), the “provable” guarantees remain conditional on an unverified step.
minor comments (2)
- The abstract states that the method “outperforms modern foundation models” but does not name the baselines or report the precise metrics (e.g., forecast horizon, error norms) used for the comparison.
- Clarify how the 12 simulations are split between training and validation for the mini-foundation model and whether any hold-out chaotic trajectories were used to test long-horizon stability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The concerns about explicit verification of structure preservation after neural embedding are well-taken. We clarify the design of the hybrid scheme below and agree to strengthen the manuscript with additional post-training diagnostics.
read point-by-point responses
-
Referee: [Abstract / hybrid scheme] Abstract and hybrid-scheme section: the proofs of discrete energy preservation and uniform gradient bounds are asserted to follow directly from the topological structure exposed by the mixed finite-element / shooting framework once the transformer is embedded. No explicit verification is supplied that the trained neural map respects the algebraic properties (exact-sequence preservation, bounded Lipschitz constant, or symplectic structure) on which those proofs rely; training can alter the effective operator and thereby invalidate the claims.
Authors: The hybrid construction embeds the autoregressive transformer as a correction step inside the shooting-based mixed finite-element scheme. The variational formulation and exact-sequence properties of the underlying discretization are enforced at the level of the discrete operator, independent of the specific weights learned by the transformer. Consequently the energy-preservation and gradient-bound proofs apply to the composite map by construction. We nevertheless agree that an explicit numerical check on the trained model would remove any ambiguity. In the revision we will add a new subsection reporting discrete-energy drift over long autoregressive rollouts and empirical Lipschitz bounds on the learned map for the fusion surrogate. revision: partial
-
Referee: [Hybrid technique description] The weakest assumption—that the embedding of the trained autoregressive transformer preserves the topological structure required for the energy and gradient results—is load-bearing for the entire stability narrative. Without a concrete check (e.g., post-training verification of the discrete energy or a Lipschitz bound on the learned map), the “provable” guarantees remain conditional on an unverified step.
Authors: The embedding is realized by restricting the transformer output to the appropriate finite-element spaces and incorporating it into the mixed variational form; this restriction is hard-coded in the architecture and is not altered by training. The stability results therefore hold for any weights obtained by the training procedure. To make this explicit we will insert, in the revised hybrid-technique section, a short verification paragraph together with the numerical checks described above. revision: partial
Circularity Check
No circularity; stability proofs derive from hybrid scheme topology without reduction to inputs
full rationale
The paper's central claims rest on mathematical proofs of discrete energy preservation (forward problems) and uniform gradient bounds (training) that are asserted to follow directly from the topological structure of the shooting-based mixed finite element scheme once the autoregressive transformer is embedded. No equations, definitions, or steps in the provided abstract or claims reduce a derived result to a fitted parameter, self-referential definition, or load-bearing self-citation by construction. The derivation chain is presented as self-contained and independent of the specific learned neural map beyond the embedding step, with no renaming of empirical patterns or ansatz smuggling visible.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard properties of mixed finite element methods allow discrete energy preservation under the shooting scheme
- domain assumption The hybrid embedding preserves sufficient topological structure to yield uniform gradient bounds during training
invented entities (1)
-
Hybridizable neural time integrator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vaswani, A.et al.Attention Is All You Need.arXiv e-printsarXiv:1706.03762 (2017). 1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A.et al.An image is worth 16x16 words: Transformers for image recogni- tion at scale. InInternational Conference on Learning Representations (ICLR)(2021). ArXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Message passing neural pde solvers
Brandstetter, J., Worrall, D. & Welling, M. Message passing neural pde solvers. InIn- ternational Conference on Learning Representations (ICLR)(2022). ArXiv:2202.03376. 25
-
[4]
Poseidon: Efficient Foundation Models for PDEs,
Herde, M.et al.Poseidon: Efficient foundation models for PDEs.Advances in Neural Information Processing Systems (NeurIPS)(2024). ArXiv:2405.19101
-
[5]
Multiple physics pretraining for physical surrogate models.arXiv preprint arXiv:2310.02994, 2023
McCabe, M.et al.Multiple physics pretraining for physical surrogate models.Advances in Neural Information Processing Systems (NeurIPS)(2024). ArXiv:2310.02994
-
[6]
Subramanian, S.et al.Towards foundation models for scientific machine learning: Char- acterizing scaling and transfer behavior.Advances in Neural Information Processing Systems (NeurIPS)(2024). ArXiv:2306.00258
-
[7]
Lam, R.et al.Learning skillful medium-range global weather forecasting.Science382, 1416–1421 (2023)
2023
-
[8]
Bodnar, C.et al.A foundation model for the Earth system.Nature(2025)
2025
-
[9]
Carter, J.et al.Advanced research directions on AI for science, energy, and secu- rity: Report on summer 2022 workshops. Tech. Rep. ANL-22/91, Argonne National Laboratory (2023)
2022
- [10]
-
[11]
& Brandstetter, J
Lippe, P., Veeling, B., Perdikaris, P., Turner, R. & Brandstetter, J. PDE-refiner: Achieving accurate long rollouts with neural PDE solvers.Advances in Neural In- formation Processing Systems36(2023)
2023
-
[12]
R., Byeon, W., Wan, Z
Vlachas, P. R., Byeon, W., Wan, Z. Y., Sapsis, T. P. & Koumoutsakos, P. Data-driven forecasting of high-dimensional chaotic systems with long short-term memory networks. Proceedings of the Royal Society A474, 20170844 (2018)
2018
-
[13]
& Ott, E
Pathak, J., Hunt, B., Girvan, M., Lu, Z. & Ott, E. Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach.Physical Review Letters120, 024102 (2018)
2018
-
[14]
& Ruthotto, L
Haber, E. & Ruthotto, L. Stable architectures for deep neural networks.Inverse Prob- lems34, 014004 (2018)
2018
-
[15]
A proposal on machine learning via dynamical systems.Communications in Mathematics and Statistics5, 1–11 (2017)
E, W. A proposal on machine learning via dynamical systems.Communications in Mathematics and Statistics5, 1–11 (2017)
2017
-
[16]
T., Rubanova, Y., Bettencourt, J
Chen, R. T., Rubanova, Y., Bettencourt, J. & Duvenaud, D. K. Neural ordinary differential equations.Advances in neural information processing systems31(2018)
2018
-
[17]
& Zabaras, N
Geneva, N. & Zabaras, N. Transformers for modeling physical systems.Neural Networks 146, 272–289 (2022)
2022
-
[18]
VideoGPT: Video Generation using VQ-VAE and Transformers
Yan, W., Zhang, Y., Abbeel, P. & Srinivas, A. Videogpt: Video generation using VQ-VAE and transformers.arXiv preprint arXiv:2104.10157(2021). 26
work page internal anchor Pith review arXiv 2021
-
[19]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 10012–10022 (2021)
Liu, Z.et al.Swin transformer: Hierarchical vision transformer using shifted windows. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 10012–10022 (2021)
2021
-
[20]
G., Lee, D
Kim, J., Kim, H., Kim, H. G., Lee, D. & Yoon, S. A comprehensive survey of deep learning for time series forecasting: architectural diversity and open challenges.Artificial Intelligence Review58, 1–47 (2025)
2025
-
[21]
Bommasani, R.et al.On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258(2021)
work page internal anchor Pith review arXiv 2021
-
[22]
Foundation models for scientific discovery and innovation: Opportunities across the department of energy and the scientific enterprise
National Academies of Sciences, Engineering, and Medicine. Foundation models for scientific discovery and innovation: Opportunities across the department of energy and the scientific enterprise. Tech. Rep., The National Academies Press, Washington, DC (2025)
2025
-
[23]
& Wanner, G.Geometric Numerical Integration: Structure- Preserving Algorithms for Ordinary Differential Equations, vol
Hairer, E., Lubich, C. & Wanner, G.Geometric Numerical Integration: Structure- Preserving Algorithms for Ordinary Differential Equations, vol. 31 ofSpringer Series in Computational Mathematics(Springer, 2006), 2nd edn
2006
-
[24]
Hulbert, G. M. & Hughes, T. J. Space-time finite element methods for second-order hyperbolic equations.Computer Methods in Applied Mechanics and Engineering84, 327–348 (1990)
1990
-
[25]
& van der Vegt, J
Rhebergen, S., Cockburn, B. & van der Vegt, J. J. A space–time hybridizable discon- tinuous Galerkin method for incompressible flows on deforming domains.Journal of Computational Physics231, 4185–4204 (2013)
2013
-
[26]
& Yang, H
Langer, U., Steinbach, O., Tr¨ oltzsch, F. & Yang, H. Unstructured space-time finite element methods for optimal control of parabolic equations.SIAM Journal on Scientific Computing43, A744–A771 (2021)
2021
-
[27]
V.et al.Foundations of space-time finite element methods: polytopes, interpolation, and integration.Applied Numerical Mathematics166, 92–113 (2021)
Frontin, C. V.et al.Foundations of space-time finite element methods: polytopes, interpolation, and integration.Applied Numerical Mathematics166, 92–113 (2021)
2021
-
[28]
& Patera, A
Bernardi, C., Maday, Y. & Patera, A. T. Domain decomposition by the mortar element method. InAsymptotic and numerical methods for partial differential equations with critical parameters, 269–286 (Springer, 1993)
1993
-
[29]
Arbogast, T., Pencheva, G., Wheeler, M. F. & Yotov, I. A multiscale mortar mixed finite element method.Multiscale Modeling & Simulation6, 319–346 (2007)
2007
-
[30]
& Valli, A.Domain Decomposition Methods for Partial Differential Equations(Oxford University Press, 1999)
Quarteroni, A. & Valli, A.Domain Decomposition Methods for Partial Differential Equations(Oxford University Press, 1999)
1999
-
[31]
& Lazarov, R
Cockburn, B., Gopalakrishnan, J. & Lazarov, R. Unified hybridization of discontinuous Galerkin, mixed, and continuous Galerkin methods for second order elliptic problems. SIAM Journal on Numerical Analysis47, 1319–1365 (2009). 27
2009
-
[32]
Jiang, S., Actor, J., Roberts, S. & Trask, N. A structure-preserving domain decompo- sition method for data-driven modeling.arXiv preprint arXiv:2406.05571(2024)
-
[33]
M., Mattheij, R
Ascher, U. M., Mattheij, R. M. M. & Russell, R. D.Numerical Solution of Boundary Value Problems for Ordinary Differential Equations. Classics in Applied Mathematics (SIAM, 1995)
1995
-
[34]
N.Finite element exterior calculus(SIAM, 2018)
Arnold, D. N.Finite element exterior calculus(SIAM, 2018)
2018
-
[35]
D., Farber, A
Witherden, F. D., Farber, A. M. & Vincent, P. E. PyFR: An open source framework for solving advection–diffusion type problems on streaming architectures using the flux reconstruction approach.Computer Physics Communications185, 3028–3040 (2014)
2014
-
[36]
Computer Vision – ECCV 2022 Workshops205–218 (2023)
Cao, H.et al.Swin-unet: Unet-like pure transformer for medical image segmentation. Computer Vision – ECCV 2022 Workshops205–218 (2023)
2022
-
[37]
Ohana, R.et al.The well: a large-scale collection of diverse physics simulations for machine learning.Advances in Neural Information Processing Systems37, 44989–45037 (2024)
2024
-
[38]
T.et al.EMPIRE-PIC: a performance portable unstructured particle- in-cell code.Communications in Computational Physics30(2021)
Bettencourt, M. T.et al.EMPIRE-PIC: a performance portable unstructured particle- in-cell code.Communications in Computational Physics30(2021)
2021
-
[39]
Kinch, B.et al.Structure-preserving digital twins via conditional neural whitney forms. arXiv preprint arXiv:2508.06981(2025)
-
[40]
Wu, H., Luo, H., Wang, H., Wang, J. & Long, M. Transolver: A fast transformer solver for pdes on general geometries.arXiv preprint arXiv:2402.02366(2024)
-
[41]
Shaffer, B. D., Koohy, S., Kinch, B., Hsieh, M. A. & Trask, N. Structure- preserving learning improves geometry generalization in neural pdes.arXiv preprint arXiv:2602.02788(2026)
-
[42]
& Fix, G
Strang, G. & Fix, G. J.An analysis of the finite element method(Prentice-Hall, Engle- wood Cliffs, NJ, 1973)
1973
-
[43]
Bochev, P. B. & Hyman, J. M. Principles of mimetic discretizations of differential operators. InCompatible spatial discretizations, 89–119 (Springer, 2006)
2006
-
[44]
A., Hu, X., Huang, A., Roberts, S
Actor, J. A., Hu, X., Huang, A., Roberts, S. A. & Trask, N. Data-driven whitney forms for structure-preserving control volume analysis.Journal of Computational Physics496, 112520 (2024)
2024
-
[45]
& Liu, Z
Zhu, J., Chen, X., He, K., LeCun, Y. & Liu, Z. Transformers without normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 14901–14911 (2025). 28
2025
-
[46]
In Yue, Y., Garg, A., Peng, N., Sha, F
Vyas, N.et al.Soap: Improving and stabilizing shampoo using adam for language modeling. In Yue, Y., Garg, A., Peng, N., Sha, F. & Yu, R. (eds.)International Conference on Learning Representations, vol. 2025, 93423– 93444 (2025). URLhttps://proceedings.iclr.cc/paper_files/paper/2025/file/ e988664070e9591f93fdcf605f7dc623-Paper-Conference.pdf
2025
-
[47]
D., Evstatiev, E
Sirajuddin, D., Hamlin, N. D., Evstatiev, E. G., Hess, M. H. & Cartwright, K. MRT 7365 power flow physics and key physics phenomena: EMPIRE verification suite. Tech. Rep., Sandia National Lab. (SNL-NM), Albuquerque, NM (United States) (2023). 29
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.