Recognition: unknown
Zero-Shot Detection of LLM-Generated Text via Implicit Reward Model
Pith reviewed 2026-05-09 22:27 UTC · model grok-4.3
The pith
Implicit reward models from existing LLMs detect generated text zero-shot without training or preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
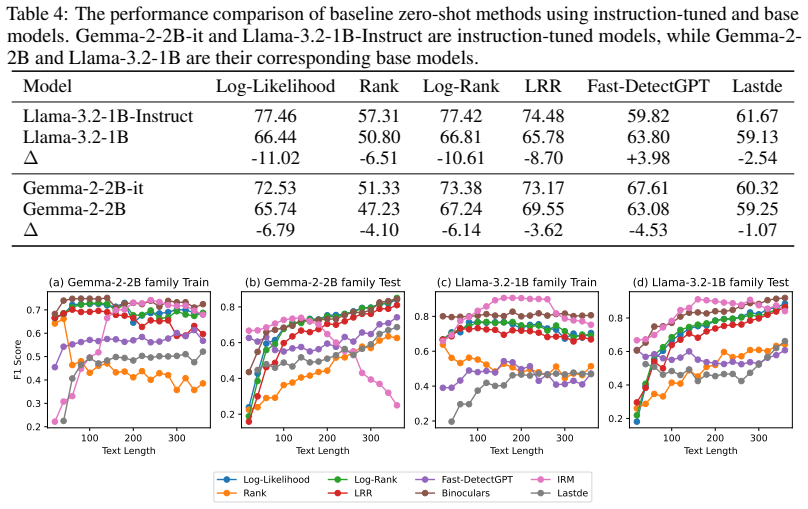
IRM extracts an implicit reward model from any publicly available instruction-tuned or base LLM and uses it as a zero-shot detector that distinguishes human-written text from LLM-generated text, delivering superior performance on the DetectRL benchmark compared with prior zero-shot and supervised detectors.
What carries the argument
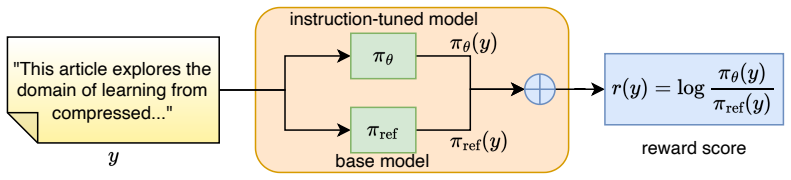
The implicit reward model, derived directly from instruction-tuned and base LLMs, that supplies a training-free signal for separating human text from model-generated text.
If this is right
- Any publicly available instruction-tuned LLM can serve as the source for an effective detector with no extra training.
- Preference collection and fine-tuning steps are unnecessary for competitive detection accuracy.
- IRM generalizes across different generation models because it relies on signals already embedded in base and tuned LLMs.
- Deployment cost drops because the same model weights used for generation can be reused for detection.
Where Pith is reading between the lines
- This result suggests that the preference information learned during instruction tuning already contains enough structure to support downstream detection tasks.
- Choosing different base models for the implicit reward could allow targeted detection of text from specific LLM families.
- Real-world content platforms could integrate the approach immediately after each new model release without waiting for labeled training sets.
Load-bearing premise
That implicit reward models derived directly from publicly available instruction-tuned and base models encode a reliable, generalizable signal for distinguishing human-written from LLM-generated text without any task-specific adaptation or data.
What would settle it
IRM failing to exceed simple zero-shot baselines such as perplexity scoring on DetectRL or on a fresh collection of texts from newer LLMs would undermine the central performance claim.
Figures


read the original abstract
Large language models (LLMs) have demonstrated remarkable capabilities across various tasks. However, their ability to generate human-like text has raised concerns about potential misuse. This underscores the need for reliable and effective methods to detect LLM-generated text. In this paper, we propose IRM, a novel zero-shot approach that leverages Implicit Reward Models for LLM-generated text detection. Such implicit reward models can be derived from publicly available instruction-tuned and base models. Previous reward-based method relies on preference construction and task-specific fine-tuning. In comparison, IRM requires neither preference collection nor additional training. We evaluate IRM on the DetectRL benchmark and demonstrate that IRM can achieve superior detection performance, outperforms existing zero-shot and supervised methods in LLM-generated text detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IRM, a zero-shot method for detecting LLM-generated text that derives implicit reward models directly from publicly available base and instruction-tuned LLMs. It claims this requires neither preference data collection nor task-specific training or fine-tuning, and reports that IRM achieves superior detection performance on the DetectRL benchmark compared to existing zero-shot and supervised methods.
Significance. If the central empirical claims hold after addressing the noted gaps, the work would be significant: it presents a fully training-free, parameter-free detector that reportedly outperforms supervised baselines, which is a strong practical advantage for deployment. The explicit use of off-the-shelf public models is a reproducible strength that could be leveraged for further falsifiable tests across generators.
major comments (2)
- Abstract: the claim of superior performance on DetectRL is stated without any metrics, baselines, AUC/F1 values, statistical tests, or even a high-level description of the reward-difference formula; this is load-bearing for the central claim of outperformance over both zero-shot and supervised methods.
- Method (implicit reward construction): the paper does not provide the exact computation of the implicit reward difference between base and instruction-tuned models, nor any ablation or analysis showing that the signal isolates source (human vs. LLM) rather than stylistic confounders such as length, fluency, or instruction-following; without this, the generalizability asserted in the abstract cannot be assessed.
minor comments (1)
- Abstract: adding one sentence with the key quantitative result (e.g., AUC on DetectRL) would make the contribution clearer without lengthening the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: Abstract: the claim of superior performance on DetectRL is stated without any metrics, baselines, AUC/F1 values, statistical tests, or even a high-level description of the reward-difference formula; this is load-bearing for the central claim of outperformance over both zero-shot and supervised methods.
Authors: We agree that the abstract should be more informative. In the revised version, we will include specific AUC and F1 scores from the DetectRL benchmark, reference the primary baselines (both zero-shot and supervised), provide a concise high-level description of the reward-difference computation, and note statistical significance where applicable. This will make the central empirical claim self-contained. revision: yes
-
Referee: Method (implicit reward construction): the paper does not provide the exact computation of the implicit reward difference between base and instruction-tuned models, nor any ablation or analysis showing that the signal isolates source (human vs. LLM) rather than stylistic confounders such as length, fluency, or instruction-following; without this, the generalizability asserted in the abstract cannot be assessed.
Authors: We acknowledge the need for greater precision here. The manuscript describes deriving implicit rewards from publicly available base and instruction-tuned models without preference data or fine-tuning, but we will add the exact mathematical formulation of the reward difference in the Method section. We will also include targeted ablations and analyses to isolate the contribution of source (human vs. LLM) from potential confounders such as length, fluency, and instruction-following, thereby supporting the asserted generalizability. revision: yes
Circularity Check
No circularity; derivation uses off-the-shelf models without fitting or self-referential steps
full rationale
The paper's central method derives an implicit reward model directly from publicly available base and instruction-tuned LLMs with no preference data collection, no task-specific fine-tuning, and no parameters fitted to detection targets. The abstract and summary describe this as a zero-shot approach that requires neither of the elements used in prior reward-based methods. No equations, ansatzes, uniqueness theorems, or self-citations are shown that would reduce the claimed detection signal to a fit or renaming of the input models themselves. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Implicit reward models can be derived from publicly available instruction-tuned and base LLMs and used directly for detection
Reference graph
Works this paper leans on
-
[1]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page internal anchor Pith review arXiv 2020
-
[2]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, 9 Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Be...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Defending against neural fake news.Advances in neural information processing systems, 32, 2019
Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. Defending against neural fake news.Advances in neural information processing systems, 32, 2019
2019
-
[4]
Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri Chatterji, Annie Chen, Kathleen Creel, Jared Quincy Davis, Dora Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stef...
-
[5]
URLhttps://arxiv.org/abs/2108.07258
work page internal anchor Pith review arXiv
-
[6]
Sebastian Gehrmann, Hendrik Strobelt, and Alexander Rush. GLTR: Statistical detection and visualization of generated text. In Marta R. Costa-jussà and Enrique Alfonseca, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 111–116, Florence, Italy, July 2019. Association for Com- pu...
-
[7]
Real or fake? learning to discriminate machine from human generated text, 2019
Anton Bakhtin, Sam Gross, Myle Ott, Yuntian Deng, Marc’Aurelio Ranzato, and Arthur Szlam. Real or fake? learning to discriminate machine from human generated text, 2019. URL https://arxiv.org/abs/1906.03351
-
[8]
Authorship attribution for neural text generation
Adaku Uchendu, Thai Le, Kai Shu, and Dongwon Lee. Authorship attribution for neural text generation. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8384–8395, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/...
2020
-
[9]
Manning, and Chelsea Finn
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D. Manning, and Chelsea Finn. Detectgpt: zero-shot machine-generated text detection using probability curvature. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[10]
Tatsunori B. Hashimoto, Hugh Zhang, and Percy Liang. Unifying human and statistical evaluation for natural language generation. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume1 (Long and Shor...
-
[11]
Emma Strubell, Ananya Ganesh, and Andrew McCallum
Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-V oss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, and Jasmine Wang. Release strategies and the social impacts of language models, 2019. URLhttps://arxiv.org/abs/1908.09203
-
[12]
Remodetect: Reward models recognize aligned LLM’s generations
Hyunseok Lee, Jihoon Tack, and Jinwoo Shin. Remodetect: Reward models recognize aligned LLM’s generations. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=pW9Jwim918
2024
-
[13]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=HPuSIXJaa9
2023
-
[14]
Wong, Shu Yang, Xinyi Yang, Yulin Yuan, and Lidia S
Junchao Wu, Runzhe Zhan, Derek F. Wong, Shu Yang, Xinyi Yang, Yulin Yuan, and Lidia S. Chao. DetectRL: Benchmarking LLM-generated text detection in real-world scenarios. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/forum?id=ZGMkOikEyv
2024
-
[15]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020. 11
2020
-
[16]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[17]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39:324, 1952
1952
-
[18]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, Nino Vieillard, Piotr Stanczyk, Sertan Girgin, ...
work page internal anchor Pith review arXiv 2024
-
[19]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, Léonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro-Ros, Ambrose Slone, Amélie Héliou, Andrea Tacchetti, Anna Bulanova, Anto...
work page internal anchor Pith review arXiv 2024
-
[20]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei...
work page internal anchor Pith review arXiv 2024
-
[21]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Spotting LLMs with binoculars: Zero- shot detection of machine-generated text
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Spotting LLMs with binoculars: Zero- shot detection of machine-generated text. In Forty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=axl3FAkpik
2024
-
[23]
Training-free LLM-generated text detection by mining token probability sequences
Yihuai Xu, Yongwei Wang, Yifei Bi, Huangsen Cao, Zhouhan Lin, Yu Zhao, and Fei Wu. Training-free LLM-generated text detection by mining token probability sequences. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=vo4AHjowKi
2025
-
[24]
DetectLLM: Leveraging log rank information for zero-shot detection of machine-generated text
Jinyan Su, Terry Zhuo, Di Wang, and Preslav Nakov. DetectLLM: Leveraging log rank information for zero-shot detection of machine-generated text. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412, Singapore, December 2023. Association for Computational Linguistics...
-
[25]
Fast-detectGPT: Efficient zero-shot detection of machine-generated text via conditional probability curvature
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. Fast-detectGPT: Efficient zero-shot detection of machine-generated text via conditional probability curvature. In The Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=Bpcgcr8E8Z
2024
-
[26]
Rewardbench: Evaluating reward models for language modeling.arXiv preprint arXiv:2403.13787, 2024
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, and Hannaneh Hajishirzi. Rewardbench: Evaluating reward models for language modeling, 2024. URL https://arxiv.org/abs/2403.13787
-
[27]
Regularizing hidden states enables learning generalizable reward model for LLMs
Rui Yang, Ruomeng Ding, Yong Lin, Huan Zhang, and Tong Zhang. Regularizing hidden states enables learning generalizable reward model for LLMs. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview. net/forum?id=jwh9MHEfmY
2024
-
[28]
RADAR: Robust AI-text detection via adversar- ial learning
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. RADAR: Robust AI-text detection via adversar- ial learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=QGrkbaan79. 13
2023
-
[29]
Vivek Verma, Eve Fleisig, Nicholas Tomlin, and Dan Klein. Ghostbuster: Detecting text ghost- written by large language models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume1: Long Papers), pages...
-
[30]
Rethinking tabular data understanding with large language models
Yang Xu, Yu Wang, Hao An, Zhichen Liu, and Yongyuan Li. Detecting subtle differences between human and model languages using spectrum of relative likelihood. In Yaser Al- Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10108–10121, Miami, Florida, USA, Novembe...
-
[31]
Glimpse: Enabling white- box methods to use proprietary models for zero-shot LLM-generated text detection
Guangsheng Bao, Yanbin Zhao, Juncai He, and Yue Zhang. Glimpse: Enabling white- box methods to use proprietary models for zero-shot LLM-generated text detection. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=an3fugFA23
2025
-
[32]
DNA-GPT: Divergent n-gram analysis for training-free detection of GPT-generated text
Xianjun Yang, Wei Cheng, Yue Wu, Linda Ruth Petzold, William Yang Wang, and Haifeng Chen. DNA-GPT: Divergent n-gram analysis for training-free detection of GPT-generated text. In The Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=Xlayxj2fWp
2024
-
[33]
Raidar: generative AI detection via rewriting
Chengzhi Mao, Carl V ondrick, Hao Wang, and Junfeng Yang. Raidar: generative AI detection via rewriting. In The Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=bQWE2UqXmf
2024
-
[34]
Zero-shot detection of LLM-generated text using token cohesive- ness
Shixuan Ma and Quan Wang. Zero-shot detection of LLM-generated text using token cohesive- ness. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17538–17553, Mi- ami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.186...
2024
-
[35]
Free process rewards without process labels.arXiv preprint arXiv:2412.01981, 2024
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels, 2024. URL https: //arxiv.org/abs/2412.01981
-
[36]
RAID: A shared benchmark for robust evalua- tion of machine-generated text detectors
Liam Dugan, Alyssa Hwang, Filip Trhlík, Andrew Zhu, Josh Magnus Ludan, Hainiu Xu, Daphne Ippolito, and Chris Callison-Burch. RAID: A shared benchmark for robust evalua- tion of machine-generated text detectors. In Lun-Wei Ku, Andre Martins, and Vivek Sriku- mar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguisti...
-
[37]
Divscore: Zero-shot detection of llm-generated text in specialized domains, 2025
Zhihui Chen, Kai He, Yucheng Huang, Yunxiao Zhu, and Mengling Feng. Divscore: Zero-shot detection of llm-generated text in specialized domains, 2025. URL https://arxiv.org/ abs/2506.06705
-
[38]
Limitations
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, Yang Liu, and Yahui Zhou. Skywork-reward-v2: Scaling preference data curation via human-ai synergy, 2025. URL https://arxiv.org/abs/2507. 01352. 14 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract a...
2025
-
[39]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.