Recognition: unknown
RPG: Robust Policy Gating for Smooth Multi-Skill Transitions in Humanoid Fighting
Pith reviewed 2026-05-09 22:10 UTC · model grok-4.3
The pith
Randomizing skill transitions and timings during training lets one policy produce stable, smooth multi-skill humanoid fighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
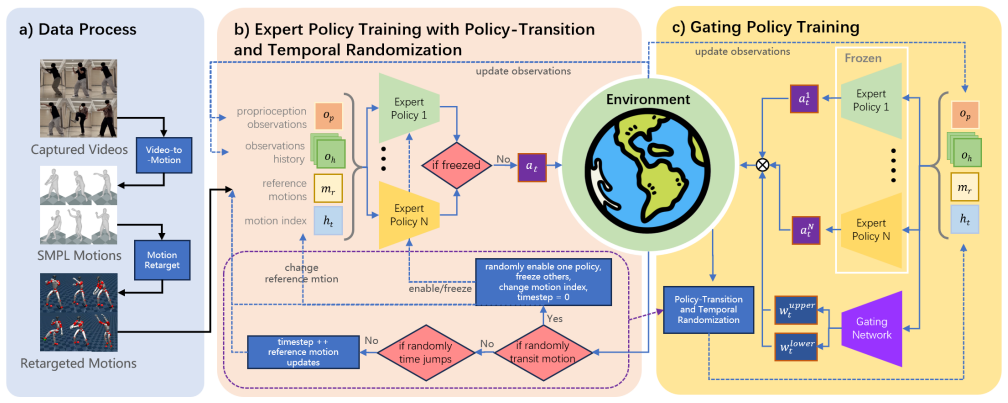
By training a hybrid expert policy with motion transition randomization and temporal randomization, a single unified policy generates agile fighting actions that maintain stability and smoothness across skill changes, removing the out-of-domain disturbances caused by state mismatches and supporting a control pipeline that integrates locomotion for humanlike combat of any duration.
What carries the argument
Motion transition randomization and temporal randomization inside a hybrid expert policy framework that trains one unified policy instead of switching among separate skill policies.
If this is right
- A single policy can chain any number of fighting skills without separate switching logic or recovery steps.
- Fighting sequences can be started, stopped, or altered at arbitrary times while the robot remains balanced.
- Locomotion and fighting skills can be combined so the robot can move into position and fight without pausing.
- The same randomization approach supports long-duration combat that continues until explicitly interrupted.
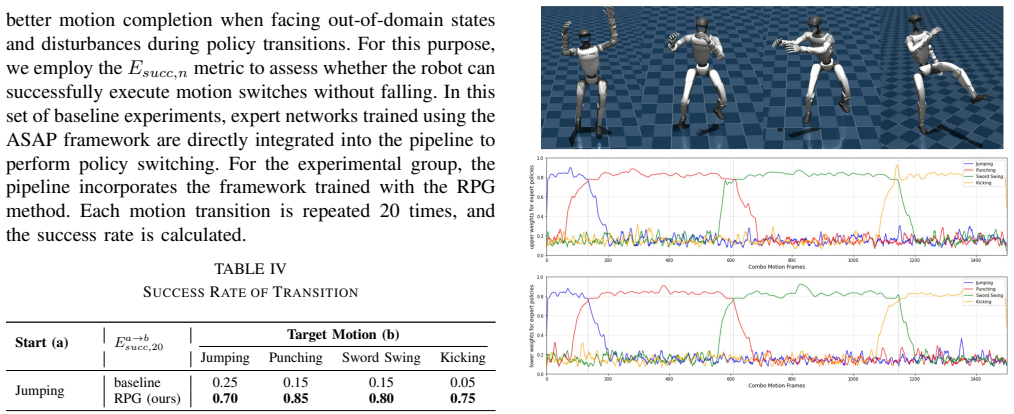
- Real-robot experiments on the Unitree G1 confirm that the trained policy transfers without additional fine-tuning for transitions.
Where Pith is reading between the lines
- The same randomization of connection points and timing could be applied to other multi-skill robotic tasks such as manipulation or navigation.
- Training-time randomization may reduce the need for explicit state-alignment modules when composing learned behaviors.
- If the randomization distribution is widened further, the policy might handle entirely novel skill combinations without retraining.
Load-bearing premise
Randomizing transitions and timings in training will be enough to remove all state-mismatch disturbances that appear when the same skills are executed on the physical robot.
What would settle it
Frequent falls or visible jerks during skill changes when the trained policy is deployed on the Unitree G1 performing a sequence of fighting moves that was never seen exactly in training.
Figures


read the original abstract
Humanoid robots have demonstrated impressive motor skills in a wide range of tasks, yet whole-body control for humanlike long-time, dynamic fighting remains particularly challenging due to the stringent requirements on agility and stability. While imitation learning enables robots to execute human-like fighting skills, existing approaches often rely on switching among multiple single-skill policies or employing a general policy to imitate input reference motions. These strategies suffer from instability when transitioning between skills, as the mismatch of initial and terminal states across skills or reference motions introduces out-of-domain disturbances, resulting in unsmooth or unstable behaviors. In this work, we propose RPG, a hybrid expert policy framework, for smooth and stable humanoid multi-skills transition. Our approach incorporates motion transition randomization and temporal randomization to train a unified policy that generates agile fighting actions with stability and smoothness during skill transitions. Furthermore, we design a control pipeline that integrates walking/running locomotion with fighting skills, allowing humanlike long-time combat of arbitrary duration that can be seamlessly interrupted or transit action policies at any time. Extensive experiments in simulation demonstrate the effectiveness of the proposed framework, and real-world deployment on the Unitree G1 humanoid robot further validates its robustness and applicability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RPG, a hybrid expert policy framework for humanoid robots to achieve smooth and stable transitions between multiple fighting skills. It trains a unified policy via motion transition randomization and temporal randomization to mitigate out-of-domain disturbances from state mismatches across skills. The approach further integrates locomotion (walking/running) with fighting skills to enable long-duration, arbitrarily interruptible combat sequences. Effectiveness is asserted via simulation experiments and real-world deployment on the Unitree G1 humanoid.
Significance. If the empirical results hold with proper quantification, the work would meaningfully advance whole-body control for dynamic, multi-skill humanoid tasks by reducing reliance on explicit policy switching. The real-world hardware validation on the Unitree G1 is a concrete strength that helps bridge sim-to-real gaps, which is valuable in this domain.
major comments (1)
- Abstract: The central claim that motion transition randomization plus temporal randomization produces a unified policy with stability and smoothness during skill transitions is asserted without any metrics, baselines, ablation studies, or failure-mode discussion. This is load-bearing for the claim, as it leaves unaddressed whether the randomization distributions are dense enough over posture, velocity, and contact-force mismatches to eliminate out-of-domain disturbances both in simulation and on hardware.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the single major comment below and will revise the manuscript to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: Abstract: The central claim that motion transition randomization plus temporal randomization produces a unified policy with stability and smoothness during skill transitions is asserted without any metrics, baselines, ablation studies, or failure-mode discussion. This is load-bearing for the claim, as it leaves unaddressed whether the randomization distributions are dense enough over posture, velocity, and contact-force mismatches to eliminate out-of-domain disturbances both in simulation and on hardware.
Authors: We agree that the abstract, in its current form, presents the benefits of motion transition randomization and temporal randomization at a high level without embedding quantitative metrics, explicit baseline comparisons, ablation results, or failure-mode analysis. The full manuscript reports extensive simulation experiments (Section 4) that include metrics for transition stability (e.g., center-of-mass deviation and success rates) and smoothness, comparisons against policy-switching and single-policy baselines, ablations isolating each randomization component, and discussion of failure cases under large state mismatches. These results support that the randomization covers relevant posture, velocity, and contact variations sufficiently for robust performance in both simulation and hardware deployment. To make the abstract self-contained and directly responsive to this concern, we will revise it to incorporate concise references to the key quantitative findings, ablations, and failure-mode observations from the experimental sections. revision: yes
Circularity Check
No significant circularity; empirical training procedure is self-contained
full rationale
The manuscript describes a hybrid expert policy trained via motion transition randomization and temporal randomization, with performance evaluated through external simulation rollouts and hardware deployment on the Unitree G1. No equations, fitted parameters, or self-citations are invoked as load-bearing steps that reduce the central claim to its own inputs by construction. The randomization is presented as an input design choice whose effectiveness is measured against independent benchmarks rather than being tautologically redefined as the output. This is the standard non-circular pattern for an empirical robotics policy paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning Hu- manoid Locomotion over Challenging Terrain,
I. Radosavovic, S. Kamat, T. Darrell, and J. Malik, “Learning Hu- manoid Locomotion over Challenging Terrain,” Oct. 2024
2024
-
[2]
Z. Zhuang, S. Yao, and H. Zhao, “Humanoid parkour learning,”arXiv preprint arXiv:2406.10759, 2024
-
[3]
Dribble Master: Learning Agile Humanoid Dribbling Through Legged Locomotion,
Z. Wang, J. Zhou, and Q. Wu, “Dribble Master: Learning Agile Humanoid Dribbling Through Legged Locomotion,” May 2025
2025
-
[4]
A Unified and General Humanoid Whole-Body Controller for Fine-Grained Loco- motion,
Y . Xue, W. Dong, M. Liu, W. Zhang, and J. Pang, “A Unified and General Humanoid Whole-Body Controller for Fine-Grained Loco- motion,” Feb. 2025
2025
-
[5]
Learning Robust Motion Skills via Critical Adversarial Attacks for Humanoid Robots,
Y . Zhang, Z. Cao, B. Nie, H. Li, and Y . Gao, “Learning Robust Motion Skills via Critical Adversarial Attacks for Humanoid Robots,” Jul. 2025
2025
-
[6]
Homie: Humanoid loco- manipulation with isomorphic exoskeleton cockpit,
Q. Ben, F. Jia, J. Zeng, J. Dong, D. Lin, and J. Pang, “Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit,” arXiv preprint arXiv:2502.13013, 2025
-
[7]
Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning,
Z. Gu, J. Li, W. Shen, W. Yu, Z. Xie, S. McCrory, X. Cheng, A. Shamsah, R. Griffin, C. K. Liu, A. Kheddar, X. B. Peng, Y . Zhu, G. Shi, Q. Nguyen, G. Cheng, H. Gao, and Y . Zhao, “Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning,” Jan. 2025
2025
-
[8]
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space,
Y . Liu, Z. Zhang, H. Wang, and L. Yi, “Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space,” May 2025
2025
-
[9]
Hierarchical Vision-Language Planning for Multi-Step Humanoid Manipulation,
A. Schakkal, B. Zandonati, Z. Yang, and N. Azizan, “Hierarchical Vision-Language Planning for Multi-Step Humanoid Manipulation,” Jun. 2025
2025
-
[10]
ULC: A Unified and Fine-Grained Controller for Humanoid Loco-Manipulation,
W. Sun, L. Feng, B. Cao, Y . Liu, Y . Jin, and Z. Xie, “ULC: A Unified and Fine-Grained Controller for Humanoid Loco-Manipulation,” Jul. 2025
2025
-
[11]
MaskedManipulator: Versatile Whole-Body Control for Loco- Manipulation,
C. Tessler, Y . Jiang, E. Coumans, Z. Luo, G. Chechik, and X. B. Peng, “MaskedManipulator: Versatile Whole-Body Control for Loco- Manipulation,” May 2025
2025
-
[12]
Human-humanoid collaborative carrying,
D. J. Agravante, A. Cherubini, A. Sherikov, P.-B. Wieber, and A. Kheddar, “Human-humanoid collaborative carrying,”IEEE Trans- actions on Robotics, vol. 35, no. 4, pp. 833–846, 2019
2019
-
[13]
Available: https://arxiv.org/abs/2502.01143
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Panet al., “Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,”arXiv preprint arXiv:2502.01143, 2025
-
[14]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion,
T. E. Truong, Q. Liao, X. Huang, G. Tevet, C. K. Liu, and K. Sreenath, “BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion,” Aug. 2025
2025
-
[15]
KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills,
W. Xie, J. Han, J. Zheng, H. Li, X. Liu, J. Shi, W. Zhang, C. Bai, and X. Li, “KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills,” Jun. 2025
2025
-
[16]
Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning,
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi, “Omnih2o: Universal and dexterous human- to-humanoid whole-body teleoperation and learning,”arXiv preprint arXiv:2406.08858, 2024
-
[17]
HuB: Learning Extreme Humanoid Balance,
T. Zhang, B. Zheng, R. Nai, Y . Hu, Y .-J. Wang, G. Chen, F. Lin, J. Li, C. Hong, K. Sreenath, and Y . Gao, “HuB: Learning Extreme Humanoid Balance,” May 2025
2025
-
[18]
Learning human-to-humanoid real-time whole-body teleoperation,
T. He, Z. Luo, W. Xiao, C. Zhang, K. Kitani, C. Liu, and G. Shi, “Learning human-to-humanoid real-time whole-body teleoperation,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 8944–8951
2024
-
[19]
GMT: General Motion Tracking for Humanoid Whole-Body Control,
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang, “GMT: General Motion Tracking for Humanoid Whole-Body Control,” Jun. 2025
2025
-
[20]
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning,
Z. Su, B. Zhang, N. Rahmanian, Y . Gao, Q. Liao, C. Regan, K. Sreenath, and S. S. Sastry, “HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning,” Aug. 2025
2025
-
[21]
Robust and versatile bipedal jumping control through reinforcement learning,
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Robust and versatile bipedal jumping control through reinforcement learning,”arXiv preprint arXiv:2302.09450, 2023
-
[22]
Expressive whole-body control for humanoid robots,
X. Cheng, Y . Ji, J. Chen, R. Yang, G. Yang, and X. Wang, “Ex- pressive whole-body control for humanoid robots,”arXiv preprint arXiv:2402.16796, 2024
-
[23]
ExBody2: Advanced expressive humanoid whole-body control,
M. Ji, X. Peng, F. Liu, J. Li, G. Yang, X. Cheng, and X. Wang, “Exbody2: Advanced expressive humanoid whole-body control,”arXiv preprint arXiv:2412.13196, 2024
-
[24]
Embrace collisions: Humanoid shad- owing for deployable contact-agnostics motions,
Z. Zhuang and H. Zhao, “Embrace collisions: Humanoid shad- owing for deployable contact-agnostics motions,”arXiv preprint arXiv:2502.01465, 2025
-
[25]
Z. Zhuang, Z. Fu, J. Wang, C. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao, “Robot parkour learning,”arXiv preprint arXiv:2309.05665, 2023
-
[26]
Visual Imitation Enables Contextual Humanoid Control,
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa, “Visual Imitation Enables Contextual Humanoid Control,” May 2025
2025
-
[27]
From Experts to a Generalist: Toward General Whole-Body Control for Humanoid Robots,
Y . Wang, M. Yang, W. Zeng, Y . Zhang, X. Xu, H. Jiang, Z. Ding, and Z. Lu, “From Experts to a Generalist: Toward General Whole-Body Control for Humanoid Robots,” Jun. 2025
2025
-
[28]
Okami: Teaching humanoid robots manipulation skills through single video imitation,
J. Li, Y . Zhu, Y . Xie, Z. Jiang, M. Seo, G. Pavlakos, and Y . Zhu, “Okami: Teaching humanoid robots manipulation skills through single video imitation,” in8th Annual Conference on Robot Learning, 2024
2024
-
[29]
Humanplus: Humanoid shadowing and imitation from humans,
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn, “Humanplus: Humanoid shadowing and imitation from humans,”arXiv preprint arXiv:2406.10454, 2024
-
[30]
Discovery of skill switching criteria for learning agile quadruped locomotion,
W. Yu, F. Acero, V . Atanassov, C. Yang, I. Havoutis, D. Kanoulas, and Z. Li, “Discovery of skill switching criteria for learning agile quadruped locomotion,” Feb. 2025
2025
-
[31]
Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler, “Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,”ACM Transactions On Graphics (TOG), vol. 41, no. 4, pp. 1–17, 2022
2022
-
[32]
Evaluation-Time Policy Switching for Offline Reinforcement Learning,
N. S. Neggatu, J. Houssineau, and G. Montana, “Evaluation-Time Policy Switching for Offline Reinforcement Learning,” Mar. 2025
2025
-
[33]
Robust Policy Switching for Antifragile Reinforcement Learning for UA V Deconfliction in Adversarial Envi- ronments,
D. K. Panda and W. Guo, “Robust Policy Switching for Antifragile Reinforcement Learning for UA V Deconfliction in Adversarial Envi- ronments,” Jun. 2025
2025
-
[34]
Expert Composer Policy: Scalable Skill Repertoire for Quadruped Robots,
G. Christmann, Y .-S. Luo, and W.-C. Chen, “Expert Composer Policy: Scalable Skill Repertoire for Quadruped Robots,” Mar. 2024
2024
-
[35]
Learning Humanoid Standing-up Control across Diverse Postures,
T. Huang, J. Ren, H. Wang, Z. Wang, Q. Ben, M. Wen, X. Chen, J. Li, and J. Pang, “Learning Humanoid Standing-up Control across Diverse Postures,” Feb. 2025
2025
-
[36]
End-to-End Humanoid Robot Safe and Comfortable Locomotion Policy,
Z. Wang, X. Yang, J. Zhao, J. Zhou, T. Ma, Z. Gao, A. Ajoudani, and J. Liang, “End-to-End Humanoid Robot Safe and Comfortable Locomotion Policy,” Aug. 2025
2025
-
[37]
Amass: Archive of motion capture as surface shapes,
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black, “Amass: Archive of motion capture as surface shapes,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5442–5451
2019
-
[38]
World-Grounded Human Motion Recovery via Gravity- View Coordinates,
Z. Shen, H. Pi, Y . Xia, Z. Cen, S. Peng, Z. Hu, H. Bao, R. Hu, and X. Zhou, “World-Grounded Human Motion Recovery via Gravity- View Coordinates,” inSIGGRAPH Asia 2024 Conference Papers, Dec. 2024, pp. 1–11
2024
-
[39]
Perpetual Humanoid Control for Real-time Simulated Avatars,
Z. Luo, J. Cao, A. Winkler, K. Kitani, and W. Xu, “Perpetual Humanoid Control for Real-time Simulated Avatars,” Sep. 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.