Recognition: unknown
S1-VL: Scientific Multimodal Reasoning Model with Thinking-with-Images
Pith reviewed 2026-05-09 22:23 UTC · model grok-4.3
The pith
S1-VL enables models to reason about scientific images by generating and executing Python code to manipulate them iteratively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
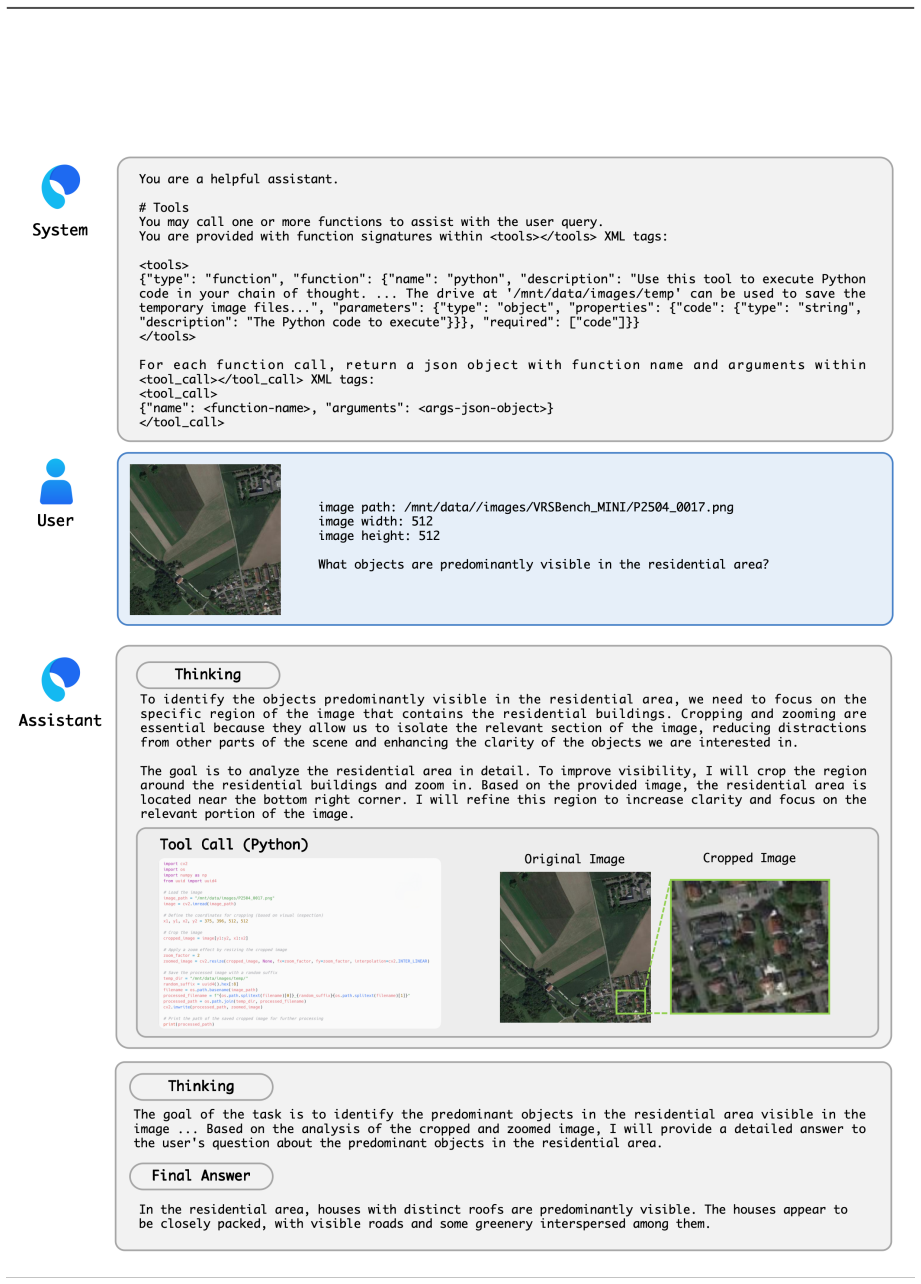
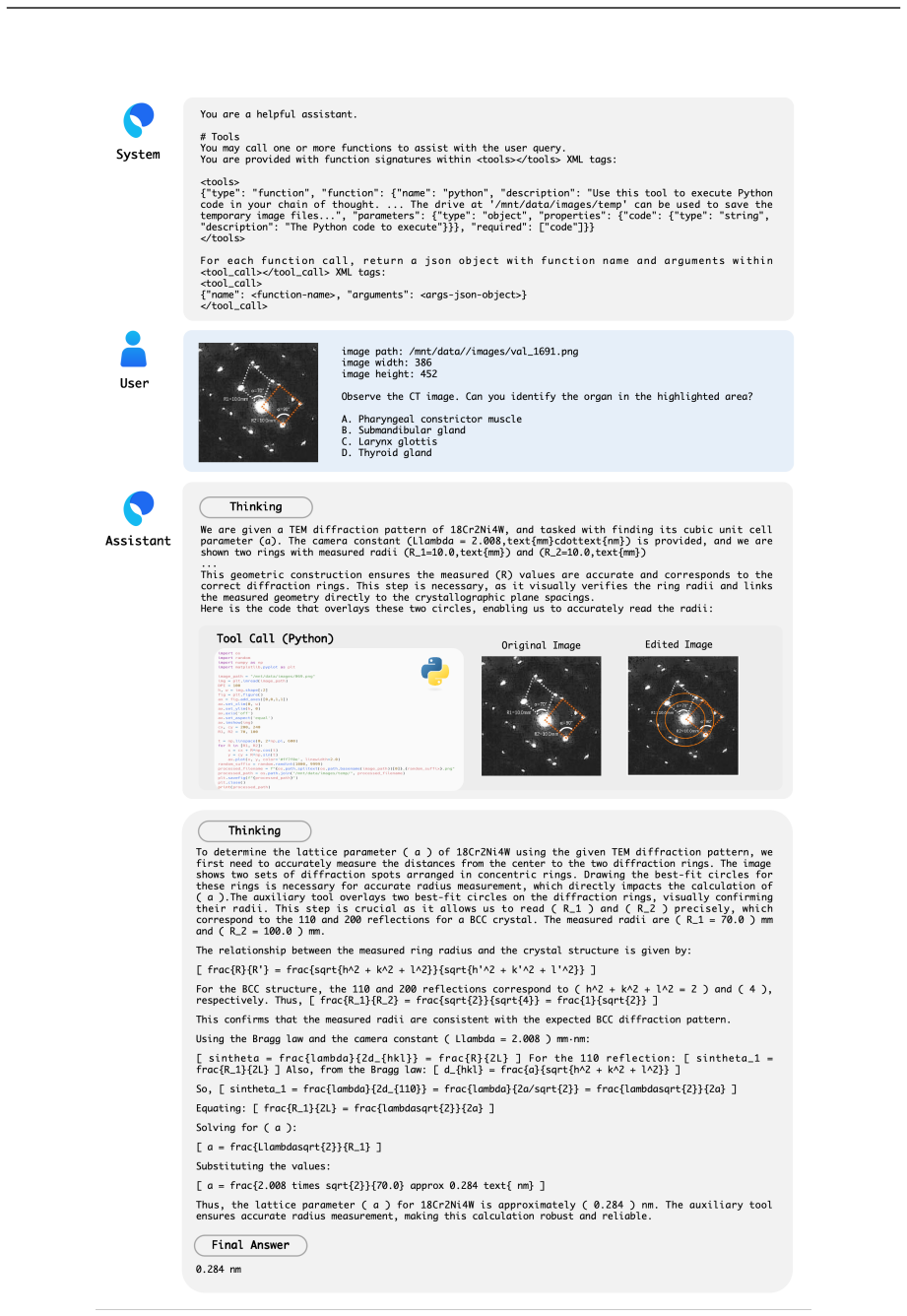
S1-VL natively combines Scientific Reasoning with Thinking-with-Images, in which the model outputs Python code for image operations, runs it in a sandbox to receive intermediate visual results, and continues multi-turn reasoning; the 32B version trained this way reaches state-of-the-art results on all five Thinking-with-Images benchmarks and leads on scientific reasoning sets such as Physics and VRSBench.
What carries the argument
The Thinking-with-Images mode together with the adaptive data routing strategy, which converts samples that yield little visual gain into pure Reasoning-mode data so the model learns when code-based image operations are actually required.
If this is right
- The model outperforms prior systems on HRBench-4K, HRBench-8K, MME-RealWorld-CN, MME-RealWorld-Lite, and V*.
- It also leads on scientific reasoning benchmarks such as Physics and VRSBench.
- Training teaches the model to choose pure reasoning for some inputs instead of always invoking image operations.
- The progressive four-stage pipeline of scientific SFT, cold-start Thinking-with-Images SFT, and two RL stages produces the observed gains.
Where Pith is reading between the lines
- This code-in-the-loop design could transfer to other visual domains that need verifiable intermediate steps, such as medical image analysis.
- It implies that hybrid symbolic and visual reasoning may be more effective than either alone when images contain precise quantitative information.
- Future tests could measure whether the routing strategy reduces unnecessary computation on simple visual questions.
Load-bearing premise
The six-dimensional quality filtering framework and adaptive routing strategy correctly identify and repurpose low visual-information-gain samples without discarding useful signal or introducing bias.
What would settle it
Run S1-VL on a held-out set of scientific images that require exact pixel measurements or geometric transformations only possible through code, and check whether accuracy drops below text-only baselines or prior multimodal systems.
Figures










read the original abstract
We present S1-VL, a multimodal reasoning model for scientific domains that natively supports two complementary reasoning paradigms: Scientific Reasoning, which relies on structured chain-of-thought, and Thinking-with-Images, which enables the model to actively manipulate images through Python code execution during reasoning. In the Thinking-with-Images mode, the model generates and executes image-processing code in a sandbox environment, obtains intermediate visual results, and continues reasoning in a multi-turn iterative manner. This design is particularly effective for challenging scenarios such as high-resolution scientific chart interpretation, microscopic image understanding, and geometry-assisted reasoning. To construct the training data, we collect scientific multimodal datasets spanning six disciplines: mathematics, physics, chemistry, astronomy, geography, and biology. We further develop a six-dimensional quality filtering framework for reasoning trajectories. To mitigate redundant, ineffective, and erroneous visual operations commonly found in existing datasets, we propose a multi-stage filtering pipeline together with an adaptive data routing strategy. This strategy converts samples with low visual information gain into pure Reasoning-mode data, enabling the model to learn when image operations are truly necessary. S1-VL is trained through a four-stage progressive pipeline: scientific multimodal SFT, Thinking-with-Images cold-start SFT, and two stages of reinforcement learning with SAPO. We build S1-VL-32B on top of Qwen3-VL-32B-Thinking and evaluate it on 13 benchmarks. Experimental results show that S1-VL-32B achieves state-of-the-art performance on all five Thinking-with-Images benchmarks, including HRBench-4K, HRBench-8K, MME-RealWorld-CN, MME-RealWorld-Lite, and V*, and outperforms compared systems on scientific reasoning benchmarks such as Physics and VRSBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces S1-VL, a 32B multimodal model for scientific domains supporting two reasoning modes: structured chain-of-thought (Scientific Reasoning) and Thinking-with-Images, in which the model generates/executes Python code for image manipulation in a sandbox to enable iterative visual reasoning on tasks like high-resolution charts and geometry. Data are collected across six disciplines (math, physics, chemistry, astronomy, geography, biology); a six-dimensional quality filter plus multi-stage pipeline and adaptive routing convert low visual-information-gain samples to pure text reasoning. Training follows a four-stage pipeline (scientific multimodal SFT, Thinking-with-Images cold-start SFT, two SAPO RL stages) starting from Qwen3-VL-32B-Thinking. On 13 benchmarks, S1-VL-32B claims SOTA on all five Thinking-with-Images tasks (HRBench-4K/8K, MME-RealWorld-CN/Lite, V*) and outperforms baselines on scientific reasoning benchmarks such as Physics and VRSBench.
Significance. If the performance deltas are shown to be robust, the work would advance multimodal scientific reasoning by demonstrating that explicit code-based visual manipulation can be learned and routed effectively, addressing a gap in handling complex visual scientific data. The adaptive routing mechanism to avoid ineffective image operations and the progressive SFT-to-RL pipeline are practical contributions that could generalize. The approach of turning low-gain samples into reasoning-only data is a sensible engineering response to training noise, though its net benefit remains unquantified.
major comments (2)
- [Data Construction section] Data Construction section: The six-dimensional quality filtering framework and adaptive data routing strategy are presented as central to producing effective training data and mitigating ineffective visual operations, yet the manuscript supplies no ablation studies that isolate their effect on the final benchmark suite. Without controlled comparisons (e.g., training the same backbone with vs. without the routing threshold on HRBench-4K, MME-RealWorld variants, and V*), it is impossible to determine whether the reported SOTA margins arise from the Thinking-with-Images cold-start and SAPO RL stages or from data selection alone. This directly undermines attribution of the central performance claims.
- [Experimental Results section] Experimental Results section: The claims of SOTA performance on all five Thinking-with-Images benchmarks and outperformance on Physics/VRSBench are stated without accompanying details on the exact baselines, statistical significance tests, ablation results for the four training stages, or error analysis. In the absence of these controls, the robustness of the gains versus Qwen3-VL-32B-Thinking cannot be assessed, leaving the effectiveness of the overall pipeline unverified.
minor comments (1)
- [Data Construction section] The six dimensions of the quality filtering framework are referenced but not enumerated with explicit criteria or a summary table; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the manuscript would benefit from additional ablation studies and expanded experimental details to strengthen attribution of results and verify robustness. We address each major comment below and commit to revisions accordingly.
read point-by-point responses
-
Referee: [Data Construction section] Data Construction section: The six-dimensional quality filtering framework and adaptive data routing strategy are presented as central to producing effective training data and mitigating ineffective visual operations, yet the manuscript supplies no ablation studies that isolate their effect on the final benchmark suite. Without controlled comparisons (e.g., training the same backbone with vs. without the routing threshold on HRBench-4K, MME-RealWorld variants, and V*), it is impossible to determine whether the reported SOTA margins arise from the Thinking-with-Images cold-start and SAPO RL stages or from data selection alone. This directly undermines attribution of the central performance claims.
Authors: We appreciate the referee highlighting this gap in experimental validation. The manuscript describes the six-dimensional quality filtering and adaptive routing but does not include isolating ablations. We will add controlled comparisons in the revised manuscript: training the same backbone with versus without the routing threshold, evaluated specifically on HRBench-4K, MME-RealWorld-CN, MME-RealWorld-Lite, and V*. These results will quantify the contribution of data selection relative to the Thinking-with-Images cold-start SFT and SAPO RL stages. revision: yes
-
Referee: [Experimental Results section] Experimental Results section: The claims of SOTA performance on all five Thinking-with-Images benchmarks and outperformance on Physics/VRSBench are stated without accompanying details on the exact baselines, statistical significance tests, ablation results for the four training stages, or error analysis. In the absence of these controls, the robustness of the gains versus Qwen3-VL-32B-Thinking cannot be assessed, leaving the effectiveness of the overall pipeline unverified.
Authors: We acknowledge that the current Experimental Results section reports aggregate SOTA and outperformance claims without the full set of requested controls. In the revision we will expand this section to: explicitly list all baseline models with configurations; report statistical significance tests (e.g., paired t-tests or bootstrap p-values) for gains over Qwen3-VL-32B-Thinking; provide stage-wise ablations for the four training stages; and include error analysis on representative failure cases. These additions will allow direct assessment of pipeline robustness. revision: yes
Circularity Check
No significant circularity detected in derivation chain or performance claims
full rationale
The paper's central claims consist of empirical performance gains on held-out external benchmarks (HRBench-4K/8K, MME-RealWorld variants, V*, Physics, VRSBench) after a described four-stage training pipeline on collected scientific multimodal data. The six-dimensional filtering and adaptive routing are methodological choices for data preparation, not quantities that the final results reduce to by definition or construction. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation chain (data collection → filtering/routing → SFT/RL stages → evaluation) remains self-contained against independent test sets, with no reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard multimodal SFT and RL training stages improve performance when applied to the described data and modes.
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv:2308.12966,
work page internal anchor Pith review arXiv
-
[2]
Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
Lei Bai, Zhongrui Cai, Yuhang Cao, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, et al. Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025a. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Q...
-
[3]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.arXiv preprint arXiv:2312.14238,
work page internal anchor Pith review arXiv
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yihe Deng et al. Openvlthinker: An early exploration to complex vision-language reasoning via iterative self-refinement.arXiv preprint arXiv:2503.17352,
-
[6]
Physics: Benchmarking foundation models on university-level physics problem solving
Kaiyue Feng, Yilun Zhao, Yixin Liu, Tianyu Yang, Chen Zhao, John Sous, and Arman Cohan. Physics: Benchmarking foundation models on university-level physics problem solving. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 11717–11743,
2025
-
[7]
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347,
-
[8]
19 Tiechuan Hu, Wenbo Zhu, and Yuqi Yan
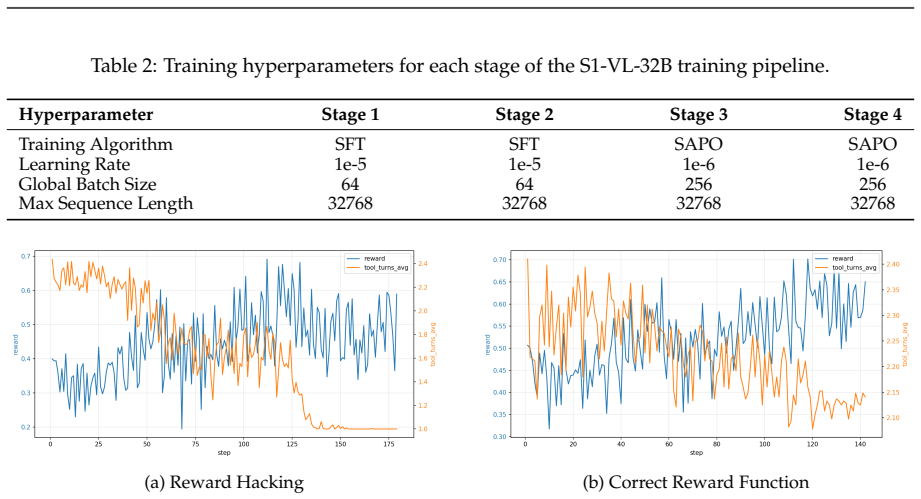
URLhttps://github.com/henrysky/Galaxy10. 19 Tiechuan Hu, Wenbo Zhu, and Yuqi Yan. Reward hacking in reinforcement learning and rlhf: A multidisciplinary examination of vulnerabilities, mitigation strategies, and alignment challenges. In 2025 5th Intelligent Cybersecurity Conference (ICSC), pp. 272–275. IEEE,
2025
-
[9]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review arXiv
-
[10]
Visual agentic reinforcement fine-tuning
Ziyu Liu, Yuhang Zang, Yushan Zou, Zijian Liang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual agentic reinforcement fine-tuning.arXiv preprint arXiv:2505.14246,
-
[11]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255,
work page internal anchor Pith review arXiv
-
[12]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng et al. Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning.arXiv preprint arXiv:2503.07365,
-
[13]
URL https://openai.com/index/ introducing-openai-o1-preview/. OpenAI. Gpt-5, 2025a. URLhttps://openai.com/zh-Hans-CN/index/introducing-gpt-5/. OpenAI. Introducing openai o3 and o4-mini, 2025b. URL https://openai.com/zh-Hans-CN/index/ introducing-o3-and-o4-mini/. OpenAI. Thinking with images, 2025c. URLhttps://openai.com/index/thinking-with-images/. Chris ...
-
[14]
V-thinker: Interactive thinking with images.arXiv preprint arXiv:2511.04460, 2025
Runqi Qiao, Qiuna Tan, Minghan Yang, Guanting Dong, Peiqing Yang, Shiqiang Lang, Enhui Wan, Xiaowan Wang, Yida Xu, Lan Yang, et al. V-thinker: Interactive thinking with images.arXiv preprint arXiv:2511.04460,
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025a. Zhaochen Su et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning. ...
work page internal anchor Pith review arXiv
-
[17]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025a. 20 Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and...
work page internal anchor Pith review arXiv
-
[19]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 7907–7915, 2025b. Lai Wei, Liangbo He, Jun Lan, Lingzhong Dong, ...
-
[20]
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257,
-
[22]
Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025a. Yifan Zhang, Liang Hu, Haofeng Sun, Peiyu Wang, Yichen Wei, Shukang Yin, Jiangbo Pei, Wei Shen, Peng Xia, Yi Peng, et al. Skywork-r1v4: Toward agentic multimodal int...
-
[23]
arXiv preprint arXiv:2408.05517 (2024),https://arxiv.org/abs/ 2408.05517
URLhttps://arxiv.org/abs/2408.05517. Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362,
-
[24]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.