Recognition: 2 theorem links
· Lean TheoremTempered Sequential Monte Carlo for Trajectory and Policy Optimization with Differentiable Dynamics
Pith reviewed 2026-05-12 00:56 UTC · model grok-4.3
The pith
Tempered sequential Monte Carlo samples optimal controllers by annealing particles from prior to low-cost target distributions using exact gradients from differentiable rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that tempered sequential Monte Carlo provides an effective sampling scheme for the Boltzmann-tilted distribution arising from KL-regularized trajectory-cost minimization. Particles begin from a prior and are adaptively reweighted and resampled along a tempering schedule toward the target; Hamiltonian Monte Carlo rejuvenation steps, which use gradients obtained by automatic differentiation through the dynamics, maintain diversity even as the distribution sharpens. For policy optimization the construction is enlarged by treating initial states deterministically and rollout noise as auxiliary variables, allowing the same annealed particle filter to optimize stochastic or un
What carries the argument
Tempered sequential Monte Carlo (TSMC) annealing with Hamiltonian Monte Carlo rejuvenation that exploits exact gradients from differentiating through trajectory rollouts.
If this is right
- The same TSMC procedure applies without change to both open-loop trajectory optimization and closed-loop policy optimization.
- Policy optimization receives a deterministic empirical approximation of the initial-state distribution and an extended-space treatment of rollout randomness as auxiliary variables.
- Experiments across standard trajectory- and policy-optimization benchmarks indicate that TSMC performs at least as well as current state-of-the-art baselines.
- The combination of adaptive tempering and gradient-informed rejuvenation keeps particle diversity high even for sharp multimodal targets.
Where Pith is reading between the lines
- The approach could be combined with existing automatic-differentiation simulators to reduce the need for hand-crafted policy gradients in control tasks.
- If the tempering schedule can be learned rather than hand-tuned, sample efficiency might improve further on problems with varying degrees of multimodality.
- The method's reliance on differentiability through rollouts points to natural integration with learned dynamics models that themselves admit gradients.
Load-bearing premise
Hamiltonian Monte Carlo rejuvenation continues to mix effectively inside the high-dimensional, potentially stiff distributions produced by long-horizon differentiable rollouts.
What would settle it
On a long-horizon benchmark with stiff dynamics, the particle set collapses to a single mode or the sampled controllers fail to reach lower costs than standard gradient-based methods.
Figures


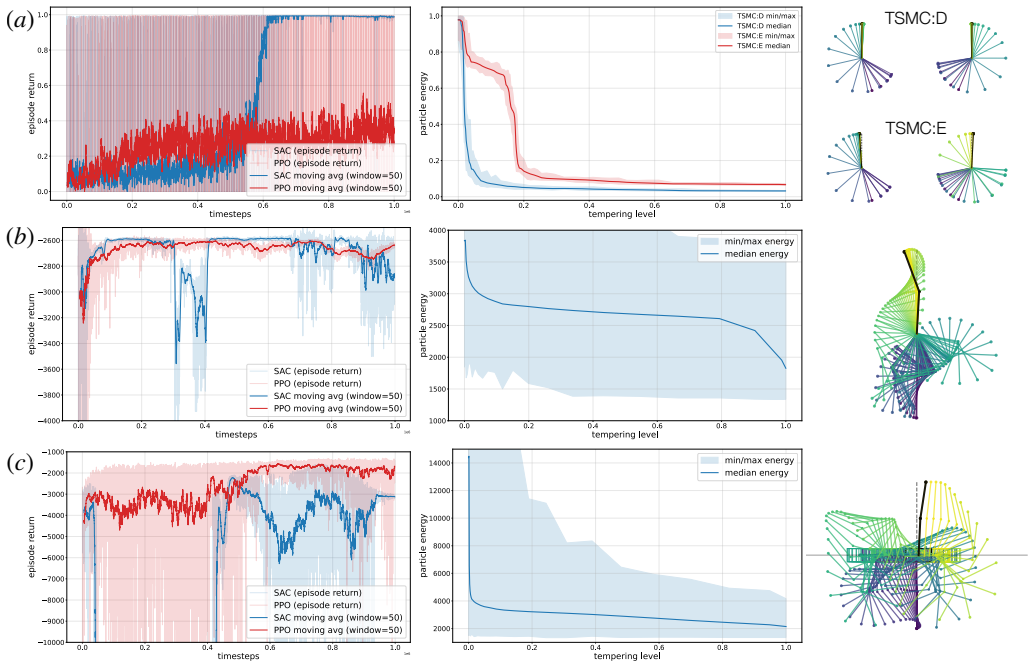
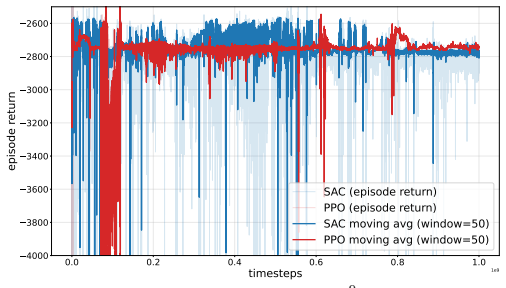
read the original abstract
We propose a sampling-based framework for finite-horizon trajectory and policy optimization under differentiable dynamics by casting controller design as inference. Specifically, we minimize a KL-regularized expected trajectory cost, which yields an optimal "Boltzmann-tilted" distribution over controller parameters that concentrates on low-cost solutions as temperature decreases. To sample efficiently from this sharp, potentially multimodal target, we introduce tempered sequential Monte Carlo (TSMC): an annealing scheme that adaptively reweights and resamples particles along a tempering path from a prior to the target distribution, while using Hamiltonian Monte Carlo rejuvenation to maintain diversity and exploit exact gradients obtained by differentiating through trajectory rollouts. For policy optimization, we extend TSMC via (i) a deterministic empirical approximation of the initial-state distribution and (ii) an extended-space construction that treats rollout randomness as auxiliary variables. Experiments across trajectory- and policy-optimization benchmarks show that TSMC is broadly applicable and compares favorably to state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tempered Sequential Monte Carlo (TSMC) for finite-horizon trajectory and policy optimization under differentiable dynamics by casting controller design as inference. It minimizes a KL-regularized expected trajectory cost to obtain a Boltzmann-tilted target distribution over controller parameters that concentrates on low-cost solutions at low temperature. TSMC performs adaptive annealing from a prior via reweighting and resampling, with HMC rejuvenation steps that exploit exact gradients obtained by differentiating through trajectory rollouts. Extensions handle policy optimization via empirical initial-state approximation and auxiliary variables for rollout randomness. Benchmark experiments indicate that TSMC is broadly applicable and compares favorably to state-of-the-art baselines.
Significance. If the empirical results hold and HMC mixing is reliable, the work provides a principled sampling framework that bridges SMC tempering with gradient-based rejuvenation for control problems exhibiting multimodality. A clear strength is the use of exact autodiff gradients inside HMC and the adaptive tempering construction built from standard, independently justified components.
major comments (1)
- [§3] §3 (TSMC construction) and the HMC rejuvenation description: the central claim that HMC rejuvenation maintains particle diversity along the tempering path is load-bearing, yet the manuscript supplies no analysis of leapfrog stability, mass-matrix choice, acceptance rates, or autocorrelation times when applied to the high-dimensional, potentially stiff distributions induced by long-horizon differentiable rollouts. If acceptance rates collapse, the adaptive reweighting/resampling step degenerates and the method cannot reliably reach the claimed low-temperature modes.
minor comments (2)
- [Abstract] The abstract states that experiments show favorable performance but supplies no quantitative metrics, error bars, or ablation details; including at least one representative table or figure reference in the abstract would strengthen the summary.
- [§2] The Boltzmann-tilted target is referenced as arising from the KL-regularized cost, but an explicit one-paragraph derivation (including the role of temperature) would improve accessibility for readers unfamiliar with the inference framing.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the manuscript. We address the major comment on the HMC rejuvenation analysis point by point below.
read point-by-point responses
-
Referee: [§3] §3 (TSMC construction) and the HMC rejuvenation description: the central claim that HMC rejuvenation maintains particle diversity along the tempering path is load-bearing, yet the manuscript supplies no analysis of leapfrog stability, mass-matrix choice, acceptance rates, or autocorrelation times when applied to the high-dimensional, potentially stiff distributions induced by long-horizon differentiable rollouts. If acceptance rates collapse, the adaptive reweighting/resampling step degenerates and the method cannot reliably reach the claimed low-temperature modes.
Authors: We agree that the manuscript would benefit from additional empirical diagnostics on the HMC rejuvenation steps, as these are central to maintaining particle diversity during tempering. The current version emphasizes the overall TSMC construction, adaptive annealing, and benchmark performance rather than a dedicated mixing study. In practice, the gradual tempering schedule combined with resampling helps prevent degeneracy even when individual HMC steps are imperfect. For the revised manuscript, we will add an appendix that reports observed acceptance rates (typically tuned to 0.6-0.8), autocorrelation times, and effective sample sizes from the trajectory- and policy-optimization experiments. We will also document the leapfrog integrator settings and mass-matrix choice (a diagonal matrix scaled by per-parameter gradient variances). These additions will allow readers to evaluate mixing behavior on the high-dimensional, rollout-induced distributions without altering the core claims. revision: yes
Circularity Check
No circularity: target distribution and TSMC sampler built from external cost and standard components
full rationale
The paper defines the target as the Boltzmann-tilted distribution induced by a KL-regularized expected trajectory cost (external to the sampler). TSMC is assembled by combining tempered SMC reweighting/resampling, HMC rejuvenation steps, and automatic differentiation through rollouts; none of these steps is shown to reduce to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The system dynamics are differentiable with respect to controller parameters.
- domain assumption Hamiltonian Monte Carlo mixes sufficiently well on the tempered distributions encountered in trajectory rollouts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTSMC introduces a tempering path … reweights and resamples particles … Hamiltonian Monte Carlo rejuvenation … Vk(θ) ≜ βk/λ E(θ) − log p0(θ)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 1 … p⋆(θ) = 1/Z p0(θ) exp(−E(θ)/λ)
Reference graph
Works this paper leans on
-
[1]
[MJX] jax.lax.while_loop in solver.py prevents computation of backward gradients (#2259) . https://github. com/google-deepmind/mujoco/issues/2259. 2024
work page 2024
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. “Cosmos world foundation model platform for physical ai”. In: arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A review of learning-based dynamics models for robotic manipulation
Bo Ai, Stephen Tian, Haochen Shi, Yixuan Wang, Tobias Pfaff, Cheston Tan, Henrik I Christensen, Hao Su, Jiajun Wu, and Yunzhu Li. “A review of learning-based dynamics models for robotic manipulation”. In: Science Robotics 10.106 (2025), eadt1497
work page 2025
-
[4]
Iterated denoising energy matching for sampling from boltzmann densities
Tara Akhound-Sadegh, Jarrid Rector-Brooks, Avishek Joey Bose, Sarthak Mittal, Pablo Lemos, Cheng-Hao Liu, Marcin Sendera, Siamak Ravanbakhsh, Gauthier Gidel, Yoshua Bengio, et al. “Iterated denoising energy matching for sampling from boltzmann densities”. In: arXiv preprint arXiv:2402.06121 (2024)
-
[5]
Flow-based generative models for Markov chain Monte Carlo in lattice field theory
Michael S Albergo, Gurtej Kanwar, and Phiala E Shanahan. “Flow-based generative models for Markov chain Monte Carlo in lattice field theory”. In: Physical Review D 100.3 (2019), p. 034515
work page 2019
-
[6]
Pseudo-Marginal Hamiltonian Monte Carlo
Johan Alenlöv, Arnaud Doucet, and Fredrik Lindsten. “Pseudo-Marginal Hamiltonian Monte Carlo”. In: Journal of Machine Learning Research 22.141 (2021), pp. 1–45
work page 2021
-
[7]
First order model- based rl through decoupled backpropagation
Joseph Amigo, Rooholla Khorrambakht, Elliot Chane-Sane, Nicolas Mansard, and Ludovic Righetti. “First order model- based rl through decoupled backpropagation”. In: Conference on Robot Learning (CoRL) . 2025
work page 2025
-
[8]
On the model-based stochastic value gradient for continuous reinforcement learning
Brandon Amos, Samuel Stanton, Denis Yarats, and Andrew Gordon Wilson. “On the model-based stochastic value gradient for continuous reinforcement learning”. In: Annual Learning for Dynamics and Control Conference (L4DC) . PMLR. 2021, pp. 6–20
work page 2021
-
[9]
CasADi: a software framework for nonlinear optimization and optimal control
Joel AE Andersson, Joris Gillis, Greg Horn, James B Rawlings, and Moritz Diehl. “CasADi: a software framework for nonlinear optimization and optimal control”. In: Mathematical Programming Computation 11.1 (2019), pp. 1–36
work page 2019
-
[10]
Particle Markov Chain Monte Carlo Methods
Christophe Andrieu, Arnaud Doucet, and Roman Holenstein. “Particle Markov Chain Monte Carlo Methods”. In: Journal of the American Statistical Association 105.491 (2010), pp. 1541–1554
work page 2010
-
[11]
The Pseudo-Marginal Approach for Efficient Monte Carlo Computations
Christophe Andrieu and Gareth O. Roberts. “The Pseudo-Marginal Approach for Efficient Monte Carlo Computations”. In: The Annals of Statistics 37.2 (2009), pp. 697–725
work page 2009
-
[12]
Julian Besag. “Comments on "Representations of knowledge in complex systems" by U. Grenander and M. I. Miller”. In: Journal of the Royal Statistical Society Series B: Statistical Methodology (1994)
work page 1994
-
[13]
On the convergence of adaptive sequential Monte Carlo methods
Alexandros Beskos, Ajay Jasra, Nikolas Kantas, and Alexandre Thiery. “On the convergence of adaptive sequential Monte Carlo methods”. In: The Annals of Applied Probability 26.2 (2016), pp. 1111–1146
work page 2016
-
[14]
A Conceptual Introduction to Hamiltonian Monte Carlo
Michael Betancourt. “A conceptual introduction to Hamiltonian Monte Carlo”. In: arXiv preprint arXiv:1701.02434 (2017)
work page Pith review arXiv 2017
-
[15]
JAX: composable transformations of Python+NumPy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs. Version 0.3.13. 2018
work page 2018
-
[16]
Arthur E. Bryson and Yu-Chi Ho. Applied Optimal Control: Optimization, Estimation, and Control . Waltham, MA: Blaisdell Pub. Co., 1969
work page 1969
-
[17]
BlackJAX: composable Bayesian inference in JAX
Alberto Cabezas, Adrien Corenflos, Junpeng Lao, Rémi Louf, Antoine Carnec, Kaustubh Chaudhari, Reuben Cohn- Gordon, Jeremie Coullon, Wei Deng, Sam Duffield, et al. “BlackJAX: composable Bayesian inference in JAX”. In: arXiv preprint arXiv:2402.10797 (2024)
-
[18]
Stochastic gradient hamiltonian monte carlo
Tianqi Chen, Emily Fox, and Carlos Guestrin. “Stochastic gradient hamiltonian monte carlo”. In: International Conference on Machine Learning (ICML) . PMLR. 2014, pp. 1683–1691
work page 2014
-
[19]
SMC 2: An Efficient Algorithm for Sequential Analysis of State Space Models
Nicolas Chopin, Pierre E. Jacob, and Omiros Papaspiliopoulos. “SMC 2: An Efficient Algorithm for Sequential Analysis of State Space Models”. In: Journal of the Royal Statistical Society: Series B (Statistical Methodology) 75.3 (2013), pp. 397–426
work page 2013
-
[20]
Model-augmented actor-critic: Backpropagating through paths
Ignasi Clavera, Violet Fu, and Pieter Abbeel. “Model-augmented actor-critic: Backpropagating through paths”. In: International Conference on Learning Representations (ICLR) . 2020
work page 2020
-
[21]
Spacecraft trajectory optimization
Bruce A Conway. Spacecraft trajectory optimization . V ol. 29. Cambridge University Press, 2010
work page 2010
-
[22]
An invitation to sequential Monte Carlo samplers
Chenguang Dai, Jeremy Heng, Pierre E Jacob, and Nick Whiteley. “An invitation to sequential Monte Carlo samplers”. In: Journal of the American Statistical Association 117.539 (2022), pp. 1587–1600
work page 2022
-
[23]
A tutorial on the cross-entropy method
Pieter-Tjerk De Boer, Dirk P Kroese, Shie Mannor, and Reuven Y Rubinstein. “A tutorial on the cross-entropy method”. In: Annals of operations research 134.1 (2005), pp. 19–67
work page 2005
-
[24]
Efficient mixed-integer planning for UA Vs in cluttered environments
Robin Deits and Russ Tedrake. “Efficient mixed-integer planning for UA Vs in cluttered environments”. In: IEEE International Conference on Robotics and Automation (ICRA) . IEEE. 2015, pp. 42–49
work page 2015
-
[25]
Feynman-Kac formulae: genealogical and interacting particle systems with applications
Pierre Del Moral. Feynman-Kac formulae: genealogical and interacting particle systems with applications . Springer, 2004
work page 2004
-
[26]
Sequential Monte Carlo samplers
Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. “Sequential Monte Carlo samplers”. In: Journal of the Royal Statistical Society: Series B 68.3 (2006), pp. 411–436
work page 2006
-
[27]
Sequential Monte Carlo methods in practice
Arnaud Doucet, Nando De Freitas, Neil James Gordon, et al. Sequential Monte Carlo methods in practice . V ol. 1. 2. Springer, 2001
work page 2001
-
[28]
Simon Duane, Anthony D Kennedy, Brian J Pendleton, and Duncan Roweth. “Hybrid monte carlo”. In: Physics letters B 195.2 (1987), pp. 216–222
work page 1987
-
[29]
Brax–a differentiable physics engine for large scale rigid body simulation
C Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. “Brax–a differentiable physics engine for large scale rigid body simulation”. In: arXiv preprint arXiv:2106.13281 (2021)
-
[30]
SNOPT: An SQP algorithm for large-scale constrained optimization
Philip E Gill, Walter Murray, and Michael A Saunders. “SNOPT: An SQP algorithm for large-scale constrained optimization”. In: SIAM review 47.1 (2005), pp. 99–131
work page 2005
-
[31]
Riemann manifold Langevin and Hamiltonian Monte Carlo methods
Mark Girolami and Ben Calderhead. “Riemann manifold Langevin and Hamiltonian Monte Carlo methods”. In: Journal of the Royal Statistical Society: Series B (Statistical Methodology) 73.2 (2011), pp. 123–214
work page 2011
-
[32]
Knut Graichen, Michael Treuer, and Michael Zeitz. “Swing-up of the double pendulum on a cart by feedforward and feedback control with experimental validation”. In: Automatica 43.1 (2007), pp. 63–71
work page 2007
-
[33]
Variance reduction techniques for gradient estimates in reinforcement learning
Evan Greensmith, Peter L Bartlett, and Jonathan Baxter. “Variance reduction techniques for gradient estimates in reinforcement learning”. In: Journal of Machine Learning Research (JMLR) 5 (2004), pp. 1471–1530
work page 2004
-
[34]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. “Reinforcement learning with deep energy-based policies”. In: International Conference on Machine Learning (ICML) . PMLR. 2017, pp. 1352–1361
work page 2017
-
[35]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor”. In: International Conference on Machine Learning (ICML) . 2018, pp. 1861–1870
work page 2018
-
[36]
Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations
Ernst Hairer, Christian Lubich, and Gerhard Wanner. Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations . 2nd ed. V ol. 31. Springer Series in Computational Mathematics. Springer, 2006
work page 2006
-
[37]
James D Hamilton. Time series analysis . Princeton university press, 2020
work page 2020
-
[38]
Building Rome with Convex Optimization
Haoyu Han and Heng Yang. “Building Rome with Convex Optimization”. In: Robotics: Science and Systems (RSS) . 2025
work page 2025
-
[39]
Non-Uniform Noise-to-Signal Ratio in the REINFORCE Policy-Gradient Estimator
Haoyu Han and Heng Yang. “Non-Uniform Noise-to-Signal Ratio in the REINFORCE Policy-Gradient Estimator”. In: arXiv preprint arXiv:2602.01460 (2026)
-
[40]
Haoyu Han and Heng Yang. “On the nonsmooth geometry and neural approximation of the optimal value function of infinite-horizon pendulum swing-up”. In: Annual Learning for Dynamics and Control Conference (L4DC) . PMLR. 2024, pp. 654–666
work page 2024
-
[41]
Adjoint sampling: Highly scalable diffusion samplers via adjoint matching
Aaron Havens, Benjamin Kurt Miller, Bing Yan, Carles Domingo-Enrich, Anuroop Sriram, Brandon Wood, Daniel Levine, Bin Hu, Brandon Amos, Brian Karrer, et al. “Adjoint sampling: Highly scalable diffusion samplers via adjoint matching”. In: arXiv preprint arXiv:2504.11713 (2025)
-
[42]
The No-U-Turn Sampler: adaptively setting path lengths in Hamiltonian Monte Carlo
Matthew D. Hoffman and Andrew Gelman. “The No-U-Turn Sampler: adaptively setting path lengths in Hamiltonian Monte Carlo”. In: Journal of Machine Learning Research 15.1 (2014), pp. 1593–1623
work page 2014
-
[43]
Feedback control of the pusher-slider system: A story of hybrid and underactuated contact dynamics
François Robert Hogan and Alberto Rodriguez. “Feedback control of the pusher-slider system: A story of hybrid and underactuated contact dynamics”. In: International Workshop on the Algorithmic Foundations of Robotics (WAFR) . Springer. 2020, pp. 800–815
work page 2020
-
[44]
Predictive sampling: Real-time behaviour synthesis with mujoco,
Taylor Howell, Nimrod Gileadi, Saran Tunyasuvunakool, Kevin Zakka, Tom Erez, and Yuval Tassa. “Predictive sampling: Real-time behaviour synthesis with mujoco”. In: arXiv preprint arXiv:2212.00541 (2022)
-
[45]
ALTRO: A fast solver for constrained trajectory optimization
Taylor A Howell, Brian E Jackson, and Zachary Manchester. “ALTRO: A fast solver for constrained trajectory optimization”. In: IEEE. 2019, pp. 7674–7679
work page 2019
-
[46]
Dojo: A differentiable simulator for robotics
Taylor A Howell, Simon Le Cleach, J Zico Kolter, Mac Schwager, and Zachary Manchester. “Dojo: A differentiable simulator for robotics”. In: arXiv preprint arXiv:2203.00806 9.2 (2022), p. 4
-
[47]
Diff- taichi: Differentiable programming for physical simulation
Yuanming Hu, Luke Anderson, Tzu-Mao Li, Qi Sun, Nathan Carr, Jonathan Ragan-Kelley, and Frédo Durand. “Diff- taichi: Differentiable programming for physical simulation”. In: International Conference on Learning Representations (ICLR). 2019
work page 2019
-
[48]
On Nonnegative Unbiased Estimators
Pierre E. Jacob and Alexandre H. Thiéry. “On Nonnegative Unbiased Estimators”. In: The Annals of Statistics 43.2 (2015), pp. 769–784
work page 2015
-
[49]
David H. Jacobson. “Optimal Stochastic Linear Systems with Exponential Performance Criteria and Their Relation to Deterministic Differential Games”. In: IEEE Transactions on Automatic Control 18.2 (1973), pp. 124–131
work page 1973
-
[50]
Proxnlp: a primal-dual augmented lagrangian solver for nonlinear programming in robotics and beyond
Wilson Jallet, Antoine Bambade, Nicolas Mansard, and Justin Carpentier. “Proxnlp: a primal-dual augmented lagrangian solver for nonlinear programming in robotics and beyond”. In: arXiv preprint arXiv:2210.02109 (2022)
-
[51]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. “Categorical reparameterization with gumbel-softmax”. In: International Conference on Learning Representations (ICLR) . 2017
work page 2017
-
[52]
Information Theory and Statistical Mechanics
E. T. Jaynes. “Information Theory and Statistical Mechanics”. In: Phys. Rev. (1957)
work page 1957
-
[53]
Sham M. Kakade. “A Natural Policy Gradient”. In: Conference on Neural Information Processing Systems (NeurIPS) . 2001
work page 2001
-
[54]
Global Contact-Rich Planning with Sparsity-Rich Semidefinite Relaxations
Shucheng Kang, Guorui Liu, and Heng Yang. “Global Contact-Rich Planning with Sparsity-Rich Semidefinite Relaxations”. In: Robotics: Science and Systems (RSS) . 2025
work page 2025
-
[55]
Fast and certifiable trajectory optimization
Shucheng Kang, Xiaoyang Xu, Jay Sarva, Ling Liang, and Heng Yang. “Fast and certifiable trajectory optimization”. In: International Workshop on the Algorithmic Foundations of Robotics (WAFR) . 2024
work page 2024
-
[56]
Path integrals and symmetry breaking for optimal control theory
Hilbert J Kappen. “Path integrals and symmetry breaking for optimal control theory”. In: Journal of statistical mechanics: theory and experiment 2005.11 (2005), P11011
work page 2005
-
[57]
Optimization by Simulated Annealing
S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi. “Optimization by Simulated Annealing”. In: Science 220.4598 (1983), pp. 671–680
work page 1983
-
[58]
Monte Carlo Methods for Motion Planning and Goal Inference
Jovana Kondic. “Monte Carlo Methods for Motion Planning and Goal Inference”. PhD thesis. Massachusetts Institute of Technology, 2024
work page 2024
-
[59]
A debiased Bernoulli factory and unbiased estimation of a probability
Jere Koskela, Toni Karvonen, et al. “A debiased Bernoulli factory and unbiased estimation of a probability”. In: arXiv preprint arXiv:2510.01941 (2025)
-
[60]
End- to-end and highly-efficient differentiable simulation for robotics,
Quentin Le Lidec, Louis Montaut, Yann de Mont-Marin, Fabian Schramm, and Justin Carpentier. “Highly-Efficient Differentiable Simulation for Robotics”. In: arXiv preprint arXiv:2409.07107 (2025)
-
[61]
Computational geometric mechanics and control of rigid bodies
Taeyoung Lee. “Computational geometric mechanics and control of rigid bodies”. PhD thesis. University of Michigan, 2008
work page 2008
-
[62]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. “Reinforcement learning and control as probabilistic inference: Tutorial and review”. In: arXiv preprint arXiv:1805.00909 (2018)
work page internal anchor Pith review arXiv 2018
-
[63]
Chenhao Li, Andreas Krause, and Marco Hutter. “Robotic world model: A neural network simulator for robust policy optimization in robotics”. In: arXiv preprint arXiv:2501.10100 (2025)
-
[64]
On the Surprising Robustness of Sequential Convex Optimization for Contact-Implicit Motion Planning
Yulin Li, Haoyu Han, Shucheng Kang, Jun Ma, and Heng Yang. “On the Surprising Robustness of Sequential Convex Optimization for Contact-Implicit Motion Planning”. In: Robotics: Science and Systems (RSS) . 2025
work page 2025
-
[65]
Stable pushing: Mechanics, controllability, and planning
Kevin M Lynch and Matthew T Mason. “Stable pushing: Mechanics, controllability, and planning”. In: International Journal of Robotics Research (IJRR) 15.6 (1996), pp. 533–556
work page 1996
-
[66]
Efficient Online Reinforcement Learning for Diffusion Policy
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. “Efficient Online Reinforcement Learning for Diffusion Policy”. In: International Conference on Machine Learning (ICML) . 2025
work page 2025
-
[67]
Information theory, inference and learning algorithms
David JC MacKay. Information theory, inference and learning algorithms . Cambridge university press, 2003
work page 2003
-
[68]
Successive convexification of non-convex optimal control problems and its convergence properties
Yuanqi Mao, Michael Szmuk, and Behçet Açıkme¸ se. “Successive convexification of non-convex optimal control problems and its convergence properties”. In: IEEE Conference on Decision and Control (CDC) . 2016, pp. 3636–3641
work page 2016
-
[69]
Shortest paths in graphs of convex sets
Tobia Marcucci, Jack Umenberger, Pablo Parrilo, and Russ Tedrake. “Shortest paths in graphs of convex sets”. In: SIAM Journal on Optimization 34.1 (2024), pp. 507–532
work page 2024
-
[70]
Mechanics and planning of manipulator pushing operations
Matthew T Mason. “Mechanics and planning of manipulator pushing operations”. In: International Journal of Robotics Research (IJRR) 5.3 (1986), pp. 53–71
work page 1986
-
[71]
Radford M Neal. “Annealed importance sampling”. In: Statistics and computing 11.2 (2001), pp. 125–139
work page 2001
-
[72]
Sampling from multimodal distributions using tempered transitions
Radford M Neal. “Sampling from multimodal distributions using tempered transitions”. In: Statistics and computing 6.4 (1996), pp. 353–366
work page 1996
-
[73]
MCMC Using Hamiltonian Dynamics
Radford M. Neal. “MCMC Using Hamiltonian Dynamics”. In: Handbook of Markov Chain Monte Carlo . Ed. by Steve Brooks, Andrew Gelman, Galin Jones, and Xiao-Li Meng. Chapman and Hall/CRC, 2011. Chap. 5
work page 2011
-
[74]
A review of differentiable simulators
Rhys Newbury, Jack Collins, Kerry He, Jiahe Pan, Ingmar Posner, David Howard, and Akansel Cosgun. “A review of differentiable simulators”. In: IEEE Access (2024)
work page 2024
-
[75]
Jorge Nocedal and Stephen J. Wright. Numerical Optimization. 2nd ed. New York, NY: Springer, 2006
work page 2006
-
[76]
Model-based diffusion for trajectory optimization
Chaoyi Pan, Zeji Yi, Guanya Shi, and Guannan Qu. “Model-based diffusion for trajectory optimization”. In: Conference on Neural Information Processing Systems (NeurIPS) . V ol. 37. 2024, pp. 57914–57943
work page 2024
-
[77]
Hard Contacts with Soft Gradients: Refining Differentiable Simulators for Learning and Control
Anselm Paulus, A René Geist, Pierre Schumacher, Vít Musil, and Georg Martius. “Hard Contacts with Soft Gradients: Refining Differentiable Simulators for Learning and Control”. In: arXiv preprint arXiv:2506.14186 (2025)
-
[78]
A direct method for trajectory optimization of rigid bodies through contact
Michael Posa, Cecilia Cantu, and Russ Tedrake. “A direct method for trajectory optimization of rigid bodies through contact”. In: The International Journal of Robotics Research 33.1 (2014), pp. 69–81
work page 2014
-
[79]
Inference-time enhancement of generative robot policies via predictive world modeling, 2026
Han Qi, Haocheng Yin, Aris Zhu, Yilun Du, and Heng Yang. “Strengthening generative robot policies through predictive world modeling”. In: arXiv preprint arXiv:2502.00622 (2025)
-
[80]
Stable- baselines3: Reliable reinforcement learning implementations
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. “Stable- baselines3: Reliable reinforcement learning implementations”. In: Journal of machine learning research 22.268 (2021), pp. 1–8
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.