Recognition: unknown
DiariZen Explained: A Tutorial for the Open Source State-of-the-Art Speaker Diarization Pipeline
Pith reviewed 2026-05-08 13:29 UTC · model grok-4.3
The pith
A tutorial breaks the leading open-source speaker diarization pipeline into seven explicit processing stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiariZen achieves leading open-source performance by chaining a structurally pruned WavLM-Large encoder, a Conformer network that performs powerset classification over speaker activity, and VBx clustering that uses PLDA scores; the tutorial renders this pipeline transparent by decomposing it into the seven stages of audio loading with sliding windows, layer-weighted WavLM feature extraction, Conformer backend processing, overlap-add segmentation aggregation, overlap-excluded embedding extraction, VBx clustering, and final RTTM reconstruction, each accompanied by source references and intermediate outputs on a 30-second AMI excerpt.
What carries the argument
The seven-stage sequential decomposition that moves audio from raw waveform through feature extraction, neural powerset classification, embedding extraction, and clustering to produce labeled speaker timelines.
If this is right
- The full pipeline becomes executable from the provided standalone scripts and notebook without external dependencies beyond those listed.
- Any single stage can be replaced or inspected while keeping the rest of the flow intact.
- Benchmark results on standard corpora can be regenerated and compared stage by stage using the supplied visualizations.
Where Pith is reading between the lines
- Similar stage-wise tutorials could be written for other hybrid neural audio systems to lower the barrier to replication.
- The explicit handling of overlap segments in stages four and five suggests a general pattern for improving diarization accuracy in meetings with frequent speaker turns.
- Making tensor shapes and example outputs public for each block offers a template for verifying implementation fidelity in future open-source releases.
Load-bearing premise
The seven-stage split and the accompanying code references together capture the actual DiariZen implementation completely and without mistakes in the described data flows or clustering mechanics.
What would settle it
Running the tutorial notebook on the same 30-second AMI excerpt and checking whether the intermediate tensor shapes, layer-weight vectors, and final RTTM labels match the paper's reported values would confirm or refute the accuracy of the breakdown.
Figures






read the original abstract
Speaker diarization (SD) is the task of answering "who spoke when" in a multi-speaker audio stream. Classically, an SD system clusters segments of speech belonging to an individual speaker's identity. Recent years have seen substantial progress in SD through end-to-end neural diarization (EEND) approaches. DiariZen, a hybrid SD pipeline built upon a structurally pruned WavLM-Large encoder, a Conformer backend with powerset classification, and VBx clustering, represents the leading open-source state of the art at the time of writing across multiple benchmarks. Despite its strong performance, the DiariZen architecture spans several repositories and frameworks, making it difficult for researchers and practitioners to understand, reproduce, or extend the system as a whole. This tutorial paper provides a self-contained, block-by-block explanation of the complete DiariZen pipeline, decomposing it into seven stages: (1) audio loading and sliding window segmentation, (2) WavLM feature extraction with learned layer weighting, (3) Conformer backend and powerset classification, (4) segmentation aggregation via overlap-add, (5) speaker embedding extraction with overlap exclusion, (6) VBx clustering with PLDA scoring, and (7) reconstruction and RTTM output. For each block, we provide the conceptual motivation, source code references, intermediate tensor shapes, and annotated visualizations of the actual outputs on a 30s excerpt from the AMI Meeting Corpus. The implementation is available at https://github.com/nikhilraghav29/diarizen-tutorial, which includes standalone executable scripts for each block and a Jupyter notebook that runs the complete pipeline end-to-end.
Editorial analysis
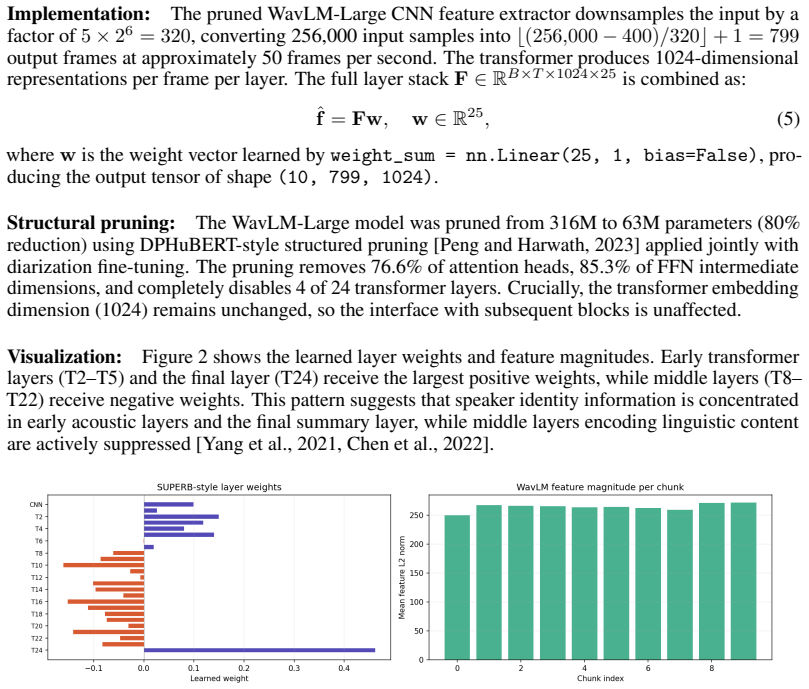
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to offer a tutorial explanation of the DiariZen speaker diarization system by breaking it down into seven distinct stages, including audio segmentation, WavLM feature extraction, Conformer powerset classification, overlap-add aggregation, embedding extraction, VBx clustering, and RTTM output. It supplies code references, tensor shapes, and visualizations from the AMI corpus along with a GitHub repository for the implementation.
Significance. This tutorial has the potential to be significant in the speaker diarization field by providing a unified, accessible explanation of a high-performing open-source pipeline that was previously scattered across repositories. The inclusion of practical code, tensor dimensions, and real data visualizations supports reproducibility and could accelerate research and application of advanced SD techniques.
major comments (2)
- [Stage 4 and Stage 5] The overlap-add aggregation and subsequent overlap-excluded embedding extraction steps require more precise mapping to the source code functions to confirm that the tensor flows and segment handling match the original DiariZen implementation exactly, as any discrepancy here would undermine the tutorial's claim of being a complete and accurate block-by-block account.
- [Stage 6] In the VBx clustering description, the handling of PLDA scoring on the extracted embeddings is outlined conceptually, but the paper should specify the exact input format expected by the VBx module from the previous stages to ensure seamless integration as described.
minor comments (2)
- [Abstract] Consider adding a brief mention of the specific performance metrics or benchmarks where DiariZen excels to substantiate the 'state-of-the-art' claim.
- [Code and visualizations] The Jupyter notebook and scripts are referenced, but the paper could include a table listing all provided resources and their purposes for better organization.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our tutorial and the constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Stage 4 and Stage 5] The overlap-add aggregation and subsequent overlap-excluded embedding extraction steps require more precise mapping to the source code functions to confirm that the tensor flows and segment handling match the original DiariZen implementation exactly, as any discrepancy here would undermine the tutorial's claim of being a complete and accurate block-by-block account.
Authors: We agree that explicit function-level mapping is necessary to maintain the tutorial's accuracy. In the revised version, we will expand Sections 4 and 5 with direct references to the specific functions and classes in the accompanying GitHub repository (e.g., the overlap_add function in aggregation.py and the embedding extraction logic with overlap exclusion in embedding_extractor.py). We will also include step-by-step tensor shape transitions and segment boundary handling details to verify exact correspondence with the original DiariZen pipeline. revision: yes
-
Referee: [Stage 6] In the VBx clustering description, the handling of PLDA scoring on the extracted embeddings is outlined conceptually, but the paper should specify the exact input format expected by the VBx module from the previous stages to ensure seamless integration as described.
Authors: We will revise the Stage 6 description to explicitly state the input format required by the VBx module, including the precise tensor or array structure (e.g., a list or numpy array of embeddings with shape (num_segments, embedding_dim) along with corresponding segment timestamps). This will be supported by a code reference to the VBx integration script in the repository and a brief note on how PLDA scoring is invoked on these inputs. revision: yes
Circularity Check
No circularity: purely descriptive tutorial with no derivations or predictions
full rationale
The paper presents no derivation chain, predictions, first-principles results, or quantitative claims that could reduce to inputs by construction. It is a self-contained tutorial decomposing an existing external pipeline (DiariZen) into seven stages, with code references, tensor shapes, and visualizations. No self-definitional steps, fitted inputs called predictions, or load-bearing self-citations appear. The central claim of accurate decomposition rests on fidelity to referenced code rather than any internal mathematical reduction, making the paper self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
pyannote.audio 2.1 speaker diarization pipeline: Principle, benchmark, and recipe
Hervé Bredin. pyannote.audio 2.1 speaker diarization pipeline: Principle, benchmark, and recipe. In Proc. INTERSPEECH, pages 1983–1987,
1983
-
[2]
Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Kenji Nagamatsu, and Shinji Watanabe
URL https://arxiv.org/ abs/2603.02813. Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Kenji Nagamatsu, and Shinji Watanabe. End-to-end neural speaker diarization with permutation-free objectives. InProc. INTERSPEECH, pages 4300–4304,
-
[3]
Leveraging self-supervised learning for speaker diarization
12 Jiangyu Han, Federico Landini, Johan Rohdin, Anna Silnova, Mireia Diez, and Lukáš Burget. Leveraging self-supervised learning for speaker diarization. InProc. ICASSP, 2025a. Jiangyu Han, Federico Landini, Johan Rohdin, Anna Silnova, Mireia Diez, Jan Cernocky, and Lukas Burget. Fine-tune before structured pruning: Towards compact and accurate self-super...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.