Recognition: unknown
DiffNR: Diffusion-Enhanced Neural Representation Optimization for Sparse-View 3D Tomographic Reconstruction
Pith reviewed 2026-05-08 13:21 UTC · model grok-4.3
The pith
A single-step diffusion model supplies perceptual supervision to optimize neural representations for accurate sparse-view CT reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
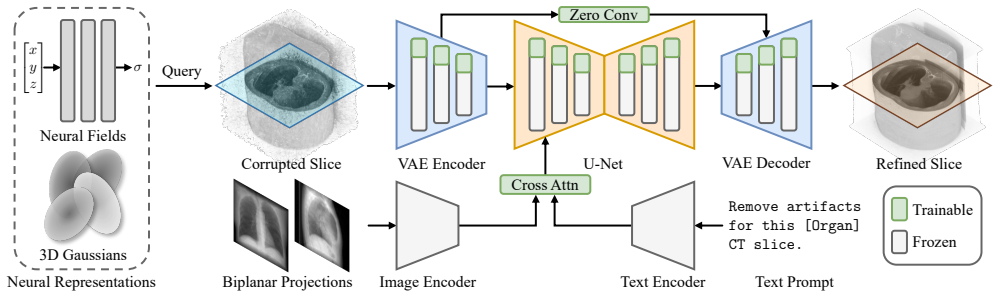
DiffNR integrates SliceFixer, a single-step diffusion model with added conditioning layers and domain-specific finetuning, into the neural representation optimization loop. SliceFixer repairs artifacted slices from the evolving volume and outputs pseudo-reference volumes that supply perceptual supervision to fix underconstrained anatomy. This repair-and-augment strategy improves reconstruction fidelity while avoiding the cost of repeated full diffusion runs inside the solver.
What carries the argument
SliceFixer, a single-step diffusion model with specialized conditioning and curated-data finetuning that generates pseudo-reference volumes to provide 3D perceptual supervision during neural representation optimization.
If this is right
- Neural representations reach higher fidelity in sparse-view tomographic reconstruction without needing dense projections.
- The method maintains efficient optimization by restricting diffusion model use to periodic corrections.
- Reconstruction quality improves consistently across different imaging domains and scanner types.
- Clinical CT could operate with fewer views while retaining diagnostic detail.
Where Pith is reading between the lines
- If the pseudo-references capture fine anatomical detail reliably, the same supervision pattern could support reconstruction from even fewer views than tested.
- The periodic repair approach may transfer to other underconstrained inverse problems such as limited-angle tomography or sparse MRI.
- Faster adaptation of SliceFixer to new scanner protocols could enable on-site model updates in clinical settings.
Load-bearing premise
The finetuned single-step diffusion model produces pseudo-reference volumes that accurately represent true anatomy in underconstrained regions without introducing new artifacts or biases.
What would settle it
Compare the pseudo-reference volumes produced by SliceFixer against ground-truth full-view reconstructions on the same sparse-view inputs; if structural accuracy or perceptual quality falls sharply in regions with missing projections, the claimed supervision benefit does not hold.
Figures





read the original abstract
Neural representations (NRs), such as neural fields and 3D Gaussians, effectively model volumetric data in computed tomography (CT) but suffer from severe artifacts under sparse-view settings. To address this, we propose DiffNR, a novel framework that enhances NR optimization with diffusion priors. At its core is SliceFixer, a single-step diffusion model designed to correct artifacts in degraded slices. We integrate specialized conditioning layers into the network and develop tailored data curation strategies to support model finetuning. During reconstruction, SliceFixer periodically generates pseudo-reference volumes, providing auxiliary 3D perceptual supervision to fix underconstrained regions. Compared to prior methods that embed CT solvers into time-consuming iterative denoising, our repair-and-augment strategy avoids frequent diffusion model queries, leading to better runtime performance. Extensive experiments show that DiffNR improves PSNR by 3.99 dB on average, generalizes well across domains, and maintains efficient optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiffNR, a framework for sparse-view 3D CT tomographic reconstruction that augments neural representation (NR) optimization with diffusion priors. At its core is SliceFixer, a single-step diffusion model with specialized conditioning layers and tailored data curation for finetuning; during optimization, SliceFixer periodically generates pseudo-reference volumes to supply auxiliary 3D perceptual supervision to underconstrained regions. The method emphasizes efficiency by avoiding repeated full diffusion iterations, and the abstract reports an average 3.99 dB PSNR gain plus cross-domain generalization.
Significance. If the pseudo-reference volumes prove accurate and unbiased, the repair-and-augment strategy could provide an efficient route to perceptual guidance in underconstrained NR reconstructions without the runtime cost of embedding solvers inside iterative denoising loops. The single-step diffusion design and periodic supervision mechanism represent a potentially useful contribution to hybrid diffusion-NR pipelines for tomography, provided the empirical claims are substantiated with controls.
major comments (3)
- [Abstract] Abstract: the central empirical claim of a 3.99 dB average PSNR improvement and cross-domain generalization is presented without any information on datasets, number of views, baseline methods, number of runs, or statistical tests, rendering the quantitative result unverifiable and the generalization statement unsupported.
- [Method (SliceFixer and supervision)] Method description of SliceFixer and supervision integration: the 3.99 dB gain and artifact-correction claims rest on the assumption that SliceFixer pseudo-references are closer to ground truth than the evolving NR estimate in underconstrained regions and do not inject new hallucinations or domain biases; however, no PSNR/SSIM/perceptual metrics on the generated pseudo-references versus ground truth are reported, and no ablation removing the perceptual supervision term is shown.
- [Experiments] Experiments section: the generalization claim across domains is load-bearing for the paper's contribution, yet no analysis of failure cases when the finetuned diffusion prior mismatches the target anatomy or acquisition protocol is provided, leaving open the possibility that reported gains are domain-specific artifacts rather than robust improvements.
minor comments (3)
- Define all acronyms (NR, CT, PSNR, SSIM) on first use and ensure consistent notation for neural fields versus 3D Gaussians throughout.
- Clarify the precise form of the specialized conditioning layers and the data curation pipeline used to finetune SliceFixer; a diagram or pseudocode would improve reproducibility.
- Add runtime comparisons (wall-clock time or diffusion queries per reconstruction) against the iterative baselines mentioned in the abstract to substantiate the efficiency advantage.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive suggestions. Below we respond to each major comment in detail. We will revise the manuscript to provide additional details, metrics, and analyses as outlined.
read point-by-point responses
-
Referee: Abstract: the central empirical claim of a 3.99 dB average PSNR improvement and cross-domain generalization is presented without any information on datasets, number of views, baseline methods, number of runs, or statistical tests, rendering the quantitative result unverifiable and the generalization statement unsupported.
Authors: We agree that the abstract should provide more context to support the empirical claims. In the revised version, we will modify the abstract to briefly indicate the datasets employed, the number of views considered, the primary baseline methods, and that the improvement is averaged over multiple runs with statistical support. The full experimental details and analyses are already present in the Experiments section. revision: yes
-
Referee: Method description of SliceFixer and supervision integration: the 3.99 dB gain and artifact-correction claims rest on the assumption that SliceFixer pseudo-references are closer to ground truth than the evolving NR estimate in underconstrained regions and do not inject new hallucinations or domain biases; however, no PSNR/SSIM/perceptual metrics on the generated pseudo-references versus ground truth are reported, and no ablation removing the perceptual supervision term is shown.
Authors: The referee correctly identifies a gap in the direct validation of the pseudo-reference quality. Although the end-to-end improvements and qualitative results indicate that the pseudo-references aid reconstruction without introducing severe artifacts, we will add in the revision: (1) quantitative evaluation of SliceFixer outputs against ground truth using PSNR, SSIM, and perceptual metrics on validation slices, and (2) an ablation experiment that disables the perceptual supervision term to quantify its specific contribution to the observed gains. revision: yes
-
Referee: Experiments section: the generalization claim across domains is load-bearing for the paper's contribution, yet no analysis of failure cases when the finetuned diffusion prior mismatches the target anatomy or acquisition protocol is provided, leaving open the possibility that reported gains are domain-specific artifacts rather than robust improvements.
Authors: We recognize the importance of discussing potential limitations in generalization. In the revised manuscript, we will expand the Experiments section to include a new analysis of failure cases, such as scenarios involving significant domain shifts in anatomy or acquisition parameters, and report the corresponding performance metrics to provide a more complete picture of the method's robustness. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces DiffNR as an empirical framework that augments neural representation optimization with periodic pseudo-reference volumes generated by a separately finetuned single-step diffusion model (SliceFixer). All performance claims (e.g., 3.99 dB PSNR gain) rest on experimental comparisons rather than any closed-form derivation, self-referential definition, or fitted parameter that is then relabeled as a prediction. No load-bearing uniqueness theorems, ansatzes, or prior results are imported via self-citation; the method's core steps (conditioning layers, data curation, repair-and-augment schedule) are described as design choices validated externally. The derivation is therefore self-contained and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single-step diffusion model can be conditioned and finetuned to correct artifacts in degraded CT slices and generate useful pseudo-reference volumes.
invented entities (1)
-
SliceFixer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.05754 , year=
TIGRE: a MATLAB-GPU toolbox for CBCT image reconstruction.Biomedical Physics & Engineering Express, 2(5): 055010. Cai, Y .; Wang, J.; Yuille, A.; Zhou, Z.; and Wang, A. 2024. Structure-aware sparse-view x-ray 3d reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, 11174–11183. Chu, J.; Du, C.; Lin, X.; Zh...
-
[2]
Adam: A Method for Stochastic Optimization
3d gaussian splatting for real-time radiance field ren- dering.ACM Trans. Graph., 42(4): 139–1. Kingma, D. P. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980. Li, Y .; Fu, X.; Li, H.; Zhao, S.; Jin, R.; and Zhou, S. K
work page internal anchor Pith review arXiv 2014
-
[3]
Lin, Y .; Yang, J.; Wang, H.; Ding, X.; Zhao, W.; and Li, X
3DGR-CT: Sparse-view CT reconstruction with a 3D Gaussian representation.Medical Image Analysis, 103585. Lin, Y .; Yang, J.; Wang, H.; Ding, X.; Zhao, W.; and Li, X. 2024. Cˆ 2rv: Cross-regional and cross-view learn- ing for sparse-view cbct reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11205–11214. L...
2024
-
[4]
arXiv preprint arXiv:2403.12036 (2024)
One-step image translation with text-to-image mod- els.arXiv preprint arXiv:2403.12036. P´erez-Garc´ıa, F.; Sharma, H.; Bond-Taylor, S.; Bouzid, K.; Salvatelli, V .; Ilse, M.; Bannur, S.; Castro, D. C.; Schwaighofer, A.; Lungren, M. P.; Wetscherek, M. T.; Codella, N.; Hyland, S. L.; Alvarez-Valle, J.; and Oktay, O
-
[5]
Radford, A.; Kim, J
Exploring scalable medical image encoders beyond text supervision.Nature Machine Intelligence. Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. 2021. Learning transferable visual models from nat- ural language supervision. InInternational conference on machine learning, 8748–876...
2021
-
[6]
Score-Based Generative Modeling through Stochastic Differential Equations
Adversarial diffusion distillation. InEuropean Con- ference on Computer Vision, 87–103. Springer. Setio, A. A. A.; Traverso, A.; De Bel, T.; Berens, M. S.; Van Den Bogaard, C.; Cerello, P.; Chen, H.; Dou, Q.; Fan- tacci, M. E.; Geurts, B.; et al. 2017. Validation, compari- son, and combination of algorithms for automatic detection of pulmonary nodules in ...
work page internal anchor Pith review arXiv 2017
-
[7]
Warburg, F.; Weber, E.; Tancik, M.; Holynski, A.; and Kanazawa, A
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image process- ing, 13(4): 600–612. Warburg, F.; Weber, E.; Tancik, M.; Holynski, A.; and Kanazawa, A. 2023. Nerfbusters: Removing ghostly arti- facts from casually captured nerfs. InProceedings of the IEEE/CVF International Conference on Computer Vision, 18120–1...
2023
-
[8]
InAdvances in Neu- ral Information Processing Systems (NeurIPS)
R 2-Gaussian: Rectifying Radiative Gaussian Splat- ting for Tomographic Reconstruction. InAdvances in Neu- ral Information Processing Systems (NeurIPS). Zha, R.; Zhang, Y .; and Li, H. 2022. NAF: neural atten- uation fields for sparse-view CBCT reconstruction. InIn- ternational Conference on Medical Image Computing and Computer-Assisted Intervention, 442–...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.