Recognition: unknown
Nonparametric Point Identification of Treatment Effect Distributions via Rank Stickiness
Pith reviewed 2026-05-08 13:06 UTC · model grok-4.3
The pith
A single scalar called rank stickiness point-identifies the full treatment effect distribution while allowing rank violations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The joint distribution of potential outcomes is identified as the unique Bregman-Sinkhorn copula that maximizes average rank correlation subject to a relative-entropy constraint whose strength is controlled by the scalar rank-stickiness parameter. This copula is completely determined by the two marginal distributions and the stickiness value; its conditional distributions are exponential tilts of the marginals with a Bregman divergence in the exponent, yielding explicit formulas for conditional moments and rank-violation probabilities.
What carries the argument
The Bregman-Sinkhorn copula: the unique coupling of two marginal distributions that maximizes average rank correlation subject to a relative-entropy constraint parameterized by rank stickiness.
If this is right
- Conditional moments and probabilities of rank violations are available in closed form as functions of the marginals and the stickiness parameter.
- The empirical copula estimator converges at the parametric sqrt(n) rate and obeys a Gaussian-process limit despite the infinite-dimensional parameter space.
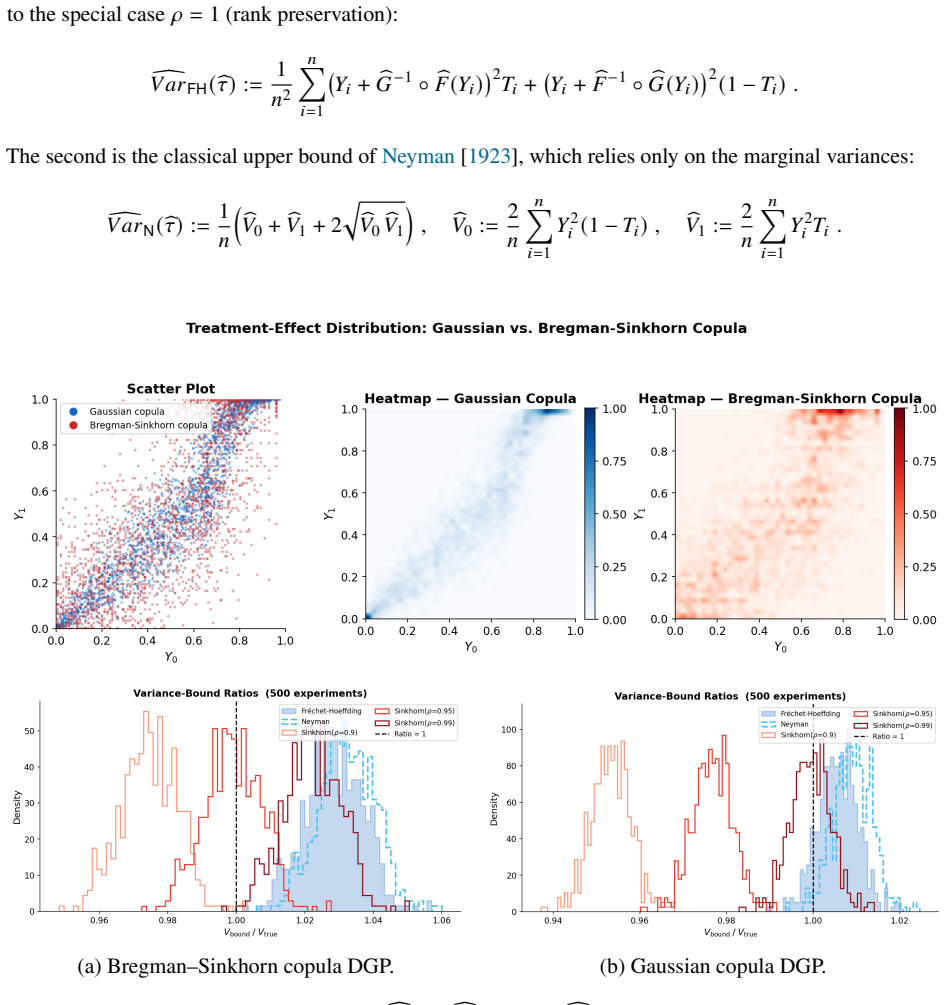
- The variance estimator for the average treatment effect is strictly tighter than both the Fréchet-Hoeffding and Neyman bounds.
- The same identification argument extends directly to observational studies under the unconfoundedness assumption.
Where Pith is reading between the lines
- Varying the stickiness parameter across a plausible range would produce a sensitivity band around the entire treatment-effect distribution rather than only around the average treatment effect.
- Because the copula nests both the comonotonic and Gaussian copulas, existing point-identification results in the literature become special cases of the new framework.
- The rank-stickiness parameter itself could serve as a primitive for comparing dependence strength across different subpopulations or policy regimes.
Load-bearing premise
The true joint distribution of potential outcomes must be exactly the unique maximizer of average rank correlation under the given relative-entropy constraint rather than some other coupling that shares the same marginals and the same scalar stickiness value.
What would settle it
In an experiment where both potential outcomes are observed, any joint distribution whose marginals and average rank correlation match those implied by the estimated stickiness parameter but whose conditional distributions deviate from the predicted exponential-tilt form would falsify the identification claim.
Figures

read the original abstract
Treatment effect distributions are not identified without restrictions on the joint distribution of potential outcomes. Existing approaches either impose rank preservation -- a strong assumption -- or derive partial identification bounds that are often wide. We show that a single scalar parameter, rank stickiness, suffices for nonparametric point identification while permitting rank violations. The identified joint distribution -- the coupling that maximizes average rank correlation subject to a relative entropy constraint, which we call the Bregman-Sinkhorn copula -- is uniquely determined by the marginals and rank stickiness. Its conditional distribution is an exponential tilt of the marginal with a Bregman divergence as the exponent, yielding closed-form conditional moments and rank violation probabilities; the copula nests the comonotonic and Gaussian copulas as special cases. The empirical Bregman-Sinkhorn copula converges at the parametric $\sqrt{n}$-rate with a Gaussian process limit, despite the infinite-dimensional parameter space. We apply the framework to estimate the full treatment effect distribution, derive a variance estimator for the average treatment effect tighter than the Fr\'{e}chet--Hoeffding and Neyman bounds, and extend to observational studies under unconfoundedness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a single scalar parameter called rank stickiness suffices for nonparametric point identification of the joint distribution of potential outcomes (and thus treatment effect distributions). The identified joint is the Bregman-Sinkhorn copula: the unique coupling that maximizes average rank correlation subject to a relative-entropy constraint whose tightness is governed by rank stickiness. This construction yields closed-form conditional distributions as exponential tilts of the marginals, closed-form rank-violation probabilities and moments, nests the comonotonic and Gaussian copulas as special cases, and delivers sqrt(n) convergence of the empirical copula despite the infinite-dimensional parameter space. Applications include estimation of the full treatment-effect distribution, a tighter variance estimator for the ATE than Frechet-Hoeffding or Neyman bounds, and an extension to observational data under unconfoundedness.
Significance. If the identification result holds, the framework supplies a middle ground between the strong rank-preservation assumption and the often-wide partial-identification bounds that currently dominate the literature. The parametric convergence rate for an infinite-dimensional object, the closed-form expressions, and the potential for tighter ATE inference are attractive features that could be adopted in applied work on treatment effects.
major comments (2)
- [Identification result / abstract] The central point-identification claim (abstract and identification theorem) rests on the assumption that the true joint distribution is exactly the Bregman-Sinkhorn copula, i.e., the unique maximizer of average rank correlation subject to the relative-entropy constraint parameterized by rank stickiness. The manuscript must clarify whether rank stickiness is recovered from data via an external moment (e.g., a rank-preservation probability) or is defined internally as the Lagrange multiplier of the same optimization; in the latter case the uniqueness is tautological and other couplings consistent with the same marginals and scalar value are not ruled out.
- [Asymptotic theory section] The sqrt(n) convergence claim with Gaussian-process limit (abstract) is load-bearing for the empirical applicability. The proof must verify that the Bregman divergence and relative-entropy constraint supply the requisite regularity to achieve the parametric rate; without explicit conditions on the marginals or the stickiness parameter, it is unclear whether the rate survives when the constraint is only approximately satisfied in finite samples.
minor comments (2)
- [Abstract] The abstract introduces the Bregman-Sinkhorn copula without a one-sentence intuition for the relative-entropy constraint; a brief parenthetical definition would improve readability for readers outside copula theory.
- [Copula properties] The nesting statements for the comonotonic and Gaussian copulas should specify the exact limiting values of rank stickiness that recover each case.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recommendation for major revision. We address the two major comments point by point below. Both comments identify areas where the manuscript can be clarified and strengthened without altering the core identification and asymptotic results.
read point-by-point responses
-
Referee: The central point-identification claim (abstract and identification theorem) rests on the assumption that the true joint distribution is exactly the Bregman-Sinkhorn copula, i.e., the unique maximizer of average rank correlation subject to the relative-entropy constraint parameterized by rank stickiness. The manuscript must clarify whether rank stickiness is recovered from data via an external moment (e.g., a rank-preservation probability) or is defined internally as the Lagrange multiplier of the same optimization; in the latter case the uniqueness is tautological and other couplings consistent with the same marginals and scalar value are not ruled out.
Authors: Rank stickiness is an external scalar parameter chosen by the researcher or recovered from data via an auxiliary moment condition (such as the probability of rank preservation or another observable dependence measure). Given the marginal distributions of the potential outcomes and a fixed value of this parameter, the identification theorem shows that the optimization problem admits a unique solution: the Bregman-Sinkhorn copula. Uniqueness follows from the strict convexity of the average-rank-correlation objective and the relative-entropy constraint in the space of couplings with fixed marginals. The parameter is not an internal Lagrange multiplier; it indexes the family of admissible copulas by controlling the tightness of the entropy constraint. Different values of rank stickiness produce distinct joints, so the construction is not tautological. We will revise the identification section and the statement of the main theorem to make this distinction explicit and to describe how the parameter can be calibrated or estimated from data. revision: partial
-
Referee: The sqrt(n) convergence claim with Gaussian-process limit (abstract) is load-bearing for the empirical applicability. The proof must verify that the Bregman divergence and relative-entropy constraint supply the requisite regularity to achieve the parametric rate; without explicit conditions on the marginals or the stickiness parameter, it is unclear whether the rate survives when the constraint is only approximately satisfied in finite samples.
Authors: The appendix derives the parametric rate under the maintained assumption that the data-generating process lies exactly in the Bregman-Sinkhorn family for a fixed interior value of the stickiness parameter. The proof relies on the smoothness induced by the Bregman divergence and the compactness of the constraint set to obtain the necessary Donsker properties and to control the remainder terms. We agree that the main text does not list the required regularity conditions (bounded marginal densities away from zero and the stickiness parameter bounded away from the comonotonic and independence boundaries) with sufficient prominence. In the revision we will state these conditions explicitly in the main text, add a remark on the behavior under approximate satisfaction of the constraint, and include a brief misspecification analysis showing that the rate remains sqrt(n) when the approximation error is o_p(n^{-1/2}). revision: yes
Circularity Check
Point identification holds by construction once the scalar rank stickiness parameterizes the unique maximizer (Bregman-Sinkhorn copula)
specific steps
-
self definitional
[Abstract]
"We show that a single scalar parameter, rank stickiness, suffices for nonparametric point identification while permitting rank violations. The identified joint distribution -- the coupling that maximizes average rank correlation subject to a relative entropy constraint, which we call the Bregman-Sinkhorn copula -- is uniquely determined by the marginals and rank stickiness."
The joint is defined to be exactly the unique solution of the optimization whose constraint level is the scalar parameter; therefore the claim that the scalar 'suffices for point identification' holds tautologically by the definition of the Bregman-Sinkhorn copula rather than from any additional identifying restriction on the joint distribution of potential outcomes.
full rationale
The paper defines the identified joint distribution explicitly as the coupling that solves the stated optimization problem (maximize average rank correlation subject to relative-entropy constraint whose tightness is set by the scalar). This yields uniqueness by the definition of the object rather than from independent restrictions on the dependence structure. The abstract presents this as nonparametric point identification, but the result reduces to the modeling assumption that the true DGP coincides with the defined maximizer. No external economic justification or falsifiability check is supplied in the provided text for excluding other couplings that share the same marginals and scalar value. The construction is self-contained and yields closed forms, but the central identification claim is definitional.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank stickiness
Reference graph
Works this paper leans on
-
[1]
Athey and G
S. Athey and G. W. Imbens. Identification and inference in nonlinear difference-in-differences models. Econometrica, 74 0 (2): 0 431--497, 2006
2006
-
[2]
Athey and G
S. Athey and G. W. Imbens. The state of applied econometrics: Causality and policy evaluation. Journal of Economic perspectives, 31 0 (2): 0 3--32, 2017
2017
-
[3]
Athey and G
S. Athey and G. W. Imbens. Machine learning methods that economists should know about. Annual Review of Economics, 11 0 (1): 0 685--725, 2019
2019
-
[4]
Athey and S
S. Athey and S. Wager. Policy learning with observational data. Econometrica, 89 0 (1): 0 133--161, 2021
2021
-
[5]
Blundell, A
R. Blundell, A. Gosling, H. Ichimura, and C. Meghir. Changes in the distribution of male and female wages accounting for employment composition using bounds. Econometrica, 75 0 (2): 0 323--363, 2007
2007
-
[6]
Y. Brenier. Polar factorization and monotone rearrangement of vector-valued functions. Communications on pure and applied mathematics, 44 0 (4): 0 375--417, 1991
1991
-
[7]
Chernozhukov and C
V. Chernozhukov and C. Hansen. An IV model of quantile treatment effects. Econometrica, 73 0 (1): 0 245--261, 2005
2005
-
[8]
Chetty, N
R. Chetty, N. Hendren, P. Kline, E. Saez, and N. Turner. Is the united states still a land of opportunity? recent trends in intergenerational mobility. American economic review, 104 0 (5): 0 141--147, 2014
2014
-
[9]
I. Csisz \'a r. I-divergence geometry of probability distributions and minimization problems. The Annals of Probability, 3 0 (1): 0 146--158, 1975. doi:10.1214/aop/1176996454
-
[10]
Deb and T
N. Deb and T. Liang. No-regret generative modeling via parabolic monge-amp\`ere pde. The Annals of Statistics, 2025. forthcoming
2025
-
[11]
Fan and S
Y. Fan and S. S. Park. Sharp bounds on the distribution of treatment effects and their statistical inference. Econometric Theory, 26 0 (3): 0 931--951, 2010
2010
-
[12]
M. H. Farrell, T. Liang, and S. Misra. Deep neural networks for estimation and inference. Econometrica, 89 0 (1): 0 181--213, 2021
2021
-
[13]
S. Firpo. Efficient semiparametric estimation of quantile treatment effects. Econometrica, 75 0 (1): 0 259--276, 2007
2007
-
[14]
Firpo and G
S. Firpo and G. Ridder. Partial identification of the treatment effect distribution and its functionals. Journal of Econometrics, 213 0 (1): 0 210--234, 2019
2019
-
[15]
Goldfeld, K
Z. Goldfeld, K. Kato, G. Rioux, and R. Sadhu. Limit theorems for entropic optimal transport maps and sinkhorn divergence. Electronic Journal of Statistics, 18 0 (1): 0 980--1041, 2024
2024
-
[16]
arXiv preprint arXiv:2207.07427 , year=
A. Gonzalez-Sanz, J.-M. Loubes, and J. Niles-Weed. Weak limits of entropy regularized optimal transport; potentials, plans and divergences. arXiv preprint arXiv:2207.07427, 2022
-
[17]
J. J. Heckman, J. Smith, and N. Clements. Making the most out of programme evaluations and social experiments: Accounting for heterogeneity in programme impacts. The Review of Economic Studies, 64 0 (4): 0 487--535, 1997
1997
- [18]
-
[19]
Kopczuk, E
W. Kopczuk, E. Saez, and J. Song. Earnings inequality and mobility in the united states: Evidence from social security data since 1937. The Quarterly Journal of Economics, 125 0 (1): 0 91--128, 2010
1937
- [20]
- [21]
-
[22]
C. F. Manski. Nonparametric bounds on treatment effects. The American Economic Review, 80 0 (2): 0 319--323, 1990
1990
-
[23]
C. F. Manski. Monotone treatment response. Econometrica, 65 0 (6): 0 1311--1334, 1997
1997
-
[24]
J. Neyman. On the application of probability theory to agricultural experiments. essay on principles. Ann. Agricultural Sciences, pages 1--51, 1923
1923
-
[25]
M. Nutz. Introduction to entropic optimal transport. Lecture notes, Columbia University, 2021
2021
-
[26]
A. W. van der Vaart and J. A. Wellner. Weak convergence and empirical processes: with applications to statistics. Springer, New York, 1996
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.