Recognition: unknown
GS-Quant: Granular Semantic and Generative Structural Quantization for Knowledge Graph Completion
Pith reviewed 2026-05-09 22:09 UTC · model grok-4.3
The pith
GS-Quant generates hierarchical and causally structured discrete codes for knowledge graph entities to enable language models to complete graphs like generating text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By grounding quantization in the insight that entity representations should follow a linguistic coarse-to-fine logic, GS-Quant uses a Granular Semantic Enhancement module to ensure earlier codes capture global semantic categories while later codes refine specific attributes, and a Generative Structural Reconstruction module to impose causal dependencies transforming independent units into structured semantic descriptors, thereby enabling LLMs to reason over graph structures isomorphically to natural language generation.
What carries the argument
The pair of Granular Semantic Enhancement and Generative Structural Reconstruction modules that create semantically coherent and structurally stratified discrete codes from knowledge graph entities.
If this is right
- LLMs expanded with these codes can perform knowledge graph completion by treating codes as tokens in generation.
- Codes provide a hierarchical view where global semantics precede attribute refinements.
- Causal dependencies in the code sequence create structured rather than independent descriptors.
- The method yields better results than existing text-based and embedding-based approaches on completion benchmarks.
Where Pith is reading between the lines
- Such codes might allow LLMs to handle other structured data tasks by similar quantization aligned to language principles.
- Applying this to dynamic or multi-relational graphs could test the robustness of the causal reconstruction.
- The approach implies that future quantization techniques could benefit from incorporating domain-specific hierarchies beyond flat compression.
Load-bearing premise
Entity representations should follow a linguistic coarse-to-fine logic and the modules will generate codes that preserve the graph's structure without loss or artifacts inside LLMs.
What would settle it
Running the knowledge graph completion task with flat, non-hierarchical quantization codes instead and finding equivalent or superior performance would indicate that the granular semantic and generative structural aspects are not essential.
Figures






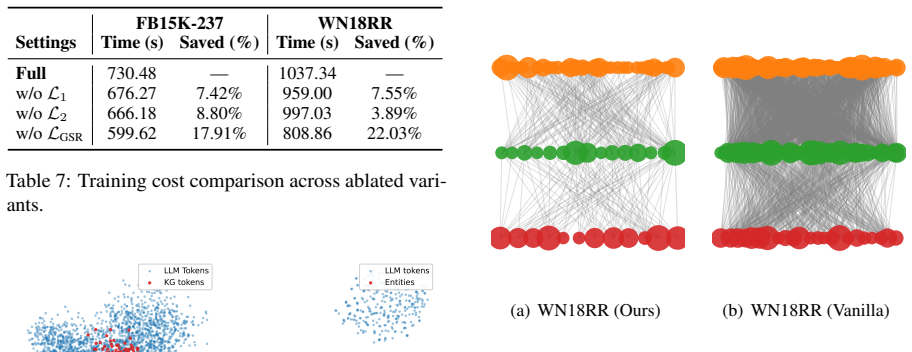
read the original abstract
Large Language Models (LLMs) have shown immense potential in Knowledge Graph Completion (KGC), yet bridging the modality gap between continuous graph embeddings and discrete LLM tokens remains a critical challenge. While recent quantization-based approaches attempt to align these modalities, they typically treat quantization as flat numerical compression, resulting in semantically entangled codes that fail to mirror the hierarchical nature of human reasoning. In this paper, we propose GS-Quant, a novel framework that generates semantically coherent and structurally stratified discrete codes for KG entities. Unlike prior methods, GS-Quant is grounded in the insight that entity representations should follow a linguistic coarse-to-fine logic. We introduce a Granular Semantic Enhancement module that injects hierarchical knowledge into the codebook, ensuring that earlier codes capture global semantic categories while later codes refine specific attributes. Furthermore, a Generative Structural Reconstruction module imposes causal dependencies on the code sequence, transforming independent discrete units into structured semantic descriptors. By expanding the LLM vocabulary with these learned codes, we enable the model to reason over graph structures isomorphically to natural language generation. Experimental results demonstrate that GS-Quant significantly outperforms existing text-based and embedding-based baselines. Our code is publicly available at https://github.com/mikumifa/GS-Quant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GS-Quant, a quantization framework for knowledge graph completion (KGC) that generates discrete codes for entities by grounding them in a linguistic coarse-to-fine hierarchy. It introduces a Granular Semantic Enhancement module to inject hierarchical knowledge into the codebook (earlier codes for global semantics, later for attributes) and a Generative Structural Reconstruction module to impose causal dependencies on the code sequence. By expanding the LLM vocabulary with these codes, the approach claims to enable isomorphic reasoning over graph structures as natural language generation, with experimental results showing significant outperformance over text-based and embedding-based baselines.
Significance. If the empirical claims hold with proper validation, the work could meaningfully advance modality alignment between continuous KG embeddings and discrete LLM tokens by enforcing hierarchical and causal structure in quantization, rather than flat compression. This has potential implications for improving KGC accuracy and interpretability in LLM-based systems, particularly if the modules preserve graph structure without artifacts.
major comments (3)
- [Abstract] Abstract: The central claim of significant outperformance over baselines is stated without any derivation details, experimental setup (datasets, metrics, splits), error bars, ablation studies, or validation of the two modules, rendering the soundness of the results impossible to assess from the provided text.
- [Abstract] The core premise that entity representations should follow linguistic coarse-to-fine logic via the Granular Semantic Enhancement and Generative Structural Reconstruction modules is presented as an insight but lacks any equations, pseudocode, or formal definition showing how these modules avoid information loss or introduce artifacts when codes are used in LLMs.
- [Abstract] No equations or derivations are shown for the codebook learning, causal dependencies, or vocabulary expansion process, which makes it impossible to evaluate whether the approach is parameter-free or depends on post-hoc fitted choices as noted in the circularity assessment.
minor comments (1)
- [Abstract] The GitHub link for code availability is a positive step toward reproducibility but should be accompanied by specific instructions on reproducing the reported results.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the abstract and the overall framework. We have revised the manuscript to address the concerns about missing details in the abstract while maintaining its conciseness. Below we respond to each major comment point by point, indicating changes made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of significant outperformance over baselines is stated without any derivation details, experimental setup (datasets, metrics, splits), error bars, ablation studies, or validation of the two modules, rendering the soundness of the results impossible to assess from the provided text.
Authors: We agree that the original abstract was too condensed to include these specifics. The full experimental setup (datasets WN18RR and FB15k-237, metrics MRR and Hits@K, standard splits, error bars from 5 runs, and ablation studies validating both modules) appears in Sections 4 and 5. In the revised version we have added a sentence to the abstract briefly noting the key datasets and statistically significant gains over baselines. revision: yes
-
Referee: [Abstract] The core premise that entity representations should follow linguistic coarse-to-fine logic via the Granular Semantic Enhancement and Generative Structural Reconstruction modules is presented as an insight but lacks any equations, pseudocode, or formal definition showing how these modules avoid information loss or introduce artifacts when codes are used in LLMs.
Authors: The formal definitions, equations, and pseudocode for both modules, together with analysis showing preservation of hierarchical semantics and causal structure without introducing reconstruction artifacts, are provided in Section 3. We have added a short clause to the revised abstract that explicitly references the coarse-to-fine linguistic grounding and causal reconstruction to better signal these properties. revision: partial
-
Referee: [Abstract] No equations or derivations are shown for the codebook learning, causal dependencies, or vocabulary expansion process, which makes it impossible to evaluate whether the approach is parameter-free or depends on post-hoc fitted choices as noted in the circularity assessment.
Authors: Equations and derivations for codebook learning, the causal dependency modeling, and vocabulary expansion are given in Sections 3.2–3.4; the training is end-to-end and does not rely on post-hoc fitting. We have inserted a brief parenthetical note in the abstract clarifying that the codes are learned jointly with the LLM vocabulary expansion. We do not believe a circularity issue exists, as the quantization objective is independent of downstream LLM fine-tuning. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces GS-Quant as a framework with two named modules (Granular Semantic Enhancement and Generative Structural Reconstruction) motivated by a coarse-to-fine linguistic logic for entity codes. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described text. Claims rest on design intent and reported empirical outperformance against baselines rather than any load-bearing mathematical reduction that could be circular by construction. The derivation chain is therefore self-contained as a proposed architecture without internal equivalence to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entity representations should follow a linguistic coarse-to-fine logic
invented entities (2)
-
Granular Semantic Enhancement module
no independent evidence
-
Generative Structural Reconstruction module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Garima Agrawal, Tharindu Kumarage, Zeyad Alghamdi, and Huan Liu. 2024. https://aclanthology.org/2024.naacl-long.219/ Can knowledge graphs reduce hallucinations in llms?: A survey . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages...
2024
-
[3]
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Dur\' a n, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS'13, page 2787–2795
2013
-
[6]
Zhe Chen, Yuehan Wang, Bin Zhao, Jing Cheng, Xin Zhao, and Zongtao Duan. 2020. Knowledge graph completion: A review. Ieee Access, 8:192435--192456
2020
-
[7]
Bonggeun Choi, Daesik Jang, and Youngjoong Ko. 2021. https://doi.org/10.1109/ACCESS.2021.3113329 Mem-kgc: Masked entity model for knowledge graph completion with pre-trained language model . IEEE Access, 9:132025--132032
-
[8]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement lea...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Lingbing Guo, Zhongpu Bo, Zhuo Chen, Yichi Zhang, Jiaoyan Chen, Lan Yarong, Mengshu Sun, Zhiqiang Zhang, Yangyifei Luo, Qian Li, and 1 others. 2024. Mkgl: mastery of a three-word language. Advances in Neural Information Processing Systems, 37:140509--140534
2024
-
[10]
Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, and Qing He. 2020. A survey on knowledge graph-based recommender systems. IEEE Transactions on Knowledge and Data Engineering, 34(8):3549--3568
2020
- [11]
-
[12]
Zeyuan Guo, Enmao Diao, Cheng Yang, and Chuan Shi. 2026. https://openreview.net/forum?id=jCctxI1BGF Graph tokenization for bridging graphs and transformers . In The Fourteenth International Conference on Learning Representations
2026
-
[13]
Bernal Jim\' e nez Guti\' e rrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. https://doi.org/10.52202/079017-1902 Hipporag: Neurobiologically inspired long-term memory for large language models . In Advances in Neural Information Processing Systems, volume 37, pages 59532--59569. Curran Associates, Inc
-
[14]
Yuan He, Moy Yuan, Jiaoyan Chen, and Ian Horrocks. 2024. https://openreview.net/forum?id=GJMYvWzjE1 Language models as hierarchy encoders . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[15]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
-
[16]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. https://doi.org/10.1109/CVPR52688.2022.01123 Autoregressive image generation using residual quantization . In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11513--11522
-
[19]
Dawei Li, Zhen Tan, Tianlong Chen, and Huan Liu. 2024. https://aclanthology.org/2024.findings-eacl.32/ Contextualization distillation from large language model for knowledge graph completion . In Findings of the Association for Computational Linguistics: EACL 2024, pages 458--477. Association for Computational Linguistics
2024
-
[22]
Ben Liu, Jihai Zhang, Fangquan Lin, Cheng Yang, and Min Peng. 2025 a . https://aclanthology.org/2025.coling-main.740/ Filter-then-generate: Large language models with structure-text adapter for knowledge graph completion . In Proceedings of the 31st International Conference on Computational Linguistics, pages 11181--11195
2025
-
[27]
Yueen Ma, Zixing Song, Xuming Hu, Jingjing Li, Yifei Zhang, and Irwin King. 2023. Graph component contrastive learning for concept relatedness estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 13362--13370
2023
-
[30]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human fee...
2022
-
[31]
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. 2024. https://doi.org/10.1109/TKDE.2024.3352100 Unifying large language models and knowledge graphs: A roadmap . IEEE Transactions on Knowledge and Data Engineering, pages 1--20
-
[32]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. 2024. Graph retrieval-augmented generation: A survey. ACM Transactions on Information Systems
2024
-
[33]
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In European semantic web conference, pages 593--607. Springer
2018
-
[34]
Zixing Song, Yueen Ma, and Irwin King. 2022. Individual fairness in dynamic financial networks. In NeurIPS 2022 Workshop: New Frontiers in Graph Learning
2022
-
[35]
Zixing Song, Ziqiao Meng, and Irwin King. 2024. A diffusion-based pre-training framework for crystal property prediction. In AAAI , pages 8993--9001. AAAI Press
2024
-
[36]
Zixing Song, Yifei Zhang, and Irwin King. 2023 a . No change, no gain: Empowering graph neural networks with expected model change maximization for active learning. In NeurIPS
2023
-
[37]
Zixing Song, Yifei Zhang, and Irwin King. 2023 b . Optimal block-wise asymmetric graph construction for graph-based semi-supervised learning. In NeurIPS
2023
-
[38]
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. 2024. https://openreview.net/forum?id=nnVO1PvbTv Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph . In The Twelfth International Conference on Learning Representations
2024
-
[39]
Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. 2019. Rotate: Knowledge graph embedding by relational rotation in complex space. In International Conference on Learning Representations
2019
-
[40]
Joshua B Tenenbaum, Charles Kemp, Thomas L Griffiths, and Noah D Goodman. 2011. https://www.science.org/doi/10.1126/science.1192788 How to grow a mind: Statistics, structure, and abstraction . science, 331(6022):1279--1285
-
[41]
Théo Trouillon, Johannes Welbl, Sebastian Riedel, Eric Gaussier, and Guillaume Bouchard. 2016. https://proceedings.mlr.press/v48/trouillon16.html Complex embeddings for simple link prediction . In Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 2071--2080, New York, New Yor...
2016
-
[42]
Aaron van den Oord, Oriol Vinyals, and koray kavukcuoglu. 2017. https://proceedings.neurips.cc/paper_files/paper/2017/file/7a98af17e63a0ac09ce2e96d03992fbc-Paper.pdf Neural discrete representation learning . In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc
2017
-
[43]
Laurens van der Maaten and Geoffrey Hinton. 2008. http://jmlr.org/papers/v9/vandermaaten08a.html Visualizing data using t-sne . Journal of Machine Learning Research, 9(86):2579--2605
2008
-
[44]
Shikhar Vashishth, Soumya Sanyal, Vikram Nitin, and Partha Talukdar. 2020. https://openreview.net/forum?id=BylA_C4tPr Composition-based multi-relational graph convolutional networks . In International Conference on Learning Representations
2020
-
[48]
Derong Xu, Ziheng Zhang, Zhenxi Lin, Xian Wu, Zhihong Zhu, Tong Xu, Xiangyu Zhao, Yefeng Zheng, and Enhong Chen. 2024. https://aclanthology.org/2024.lrec-main.1044/ Multi-perspective improvement of knowledge graph completion with large language models . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resour...
2024
-
[49]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, and 43 others. 2024. https://arxiv.org/abs/2407.10671 Qwen2 technical report . Preprint, arXiv:2407.10671
work page internal anchor Pith review arXiv 2024
-
[50]
Bishan Yang, Wen - tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2015. Embedding entities and relations for learning and inference in knowledge bases. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings
2015
- [52]
-
[53]
Yichi Zhang, Zhuo Chen, Lingbing Guo, yajing Xu, Wen Zhang, and Huajun Chen. 2024. https://openreview.net/forum?id=HHzHRuIyaW Making large language models perform better in knowledge graph completion . In ACM Multimedia 2024
2024
-
[56]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://arxiv.org/abs/2306.05685 Judging llm-as-a-judge with mt-bench and chatbot arena . Preprint, arXiv:2306.05685
work page internal anchor Pith review arXiv 2023
-
[58]
Zhaocheng Zhu, Xinyu Yuan, Michael Galkin, Louis-Pascal Xhonneux, Ming Zhang, Maxime Gazeau, and Jian Tang. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/b9e98316cb72fee82cc1160da5810abc-Paper-Conference.pdf Aast net: A scalable path-based reasoning approach for knowledge graphs . In Advances in Neural Information Processing Systems, vo...
2023
-
[59]
Zhaocheng Zhu, Zuobai Zhang, Louis-Pascal Xhonneux, and Jian Tang. 2021. https://proceedings.neurips.cc/paper_files/paper/2021/file/f6a673f09493afcd8b129a0bcf1cd5bc-Paper.pdf Neural bellman-ford networks: A general graph neural network framework for link prediction . In Advances in Neural Information Processing Systems, volume 34
2021
-
[60]
The Fourteenth International Conference on Learning Representations , year=
Graph Tokenization for Bridging Graphs and Transformers , author=. The Fourteenth International Conference on Learning Representations , year=
-
[61]
science , volume=
How to Grow a Mind: Statistics, Structure, and Abstraction , author=. science , volume=. 2011 , url=
2011
-
[62]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Language Models as Hierarchy Encoders , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[63]
Bollacker, Kurt and Evans, Colin and Paritosh, Praveen and Sturge, Tim and Taylor, Jamie , title =. 2008 , isbn =. doi:10.1145/1376616.1376746 , booktitle =
-
[64]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Bringing light into the dark: A large-scale evaluation of knowledge graph embedding models under a unified framework , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2021 , publisher=
2021
-
[65]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey on knowledge graph-based recommender systems , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2020 , publisher=
2020
-
[66]
Ieee Access , volume=
Knowledge graph completion: A review , author=. Ieee Access , volume=. 2020 , publisher=
2020
-
[67]
Knowledge Graph Retrieval-Augmented Generation for LLM -based Recommendation
Wang, Shijie and Fan, Wenqi and Feng, Yue and Shanru, Lin and Ma, Xinyu and Wang, Shuaiqiang and Yin, Dawei. Knowledge Graph Retrieval-Augmented Generation for LLM -based Recommendation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1317
-
[68]
Association for Computational Linguistics
Can knowledge graphs reduce hallucinations in llms?: A survey , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2024.naacl-long.219/", pages=
2024
-
[69]
The Twelfth International Conference on Learning Representations , year=
Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph , author=. The Twelfth International Conference on Learning Representations , year=
-
[70]
Enhancing Large Language Model for Knowledge Graph Completion via Structure-Aware Alignment-Tuning
Liu, Yu and Cao, Yanan and Lin, Xixun and Shang, Yanmin and Wang, Shi and Pan, Shirui. Enhancing Large Language Model for Knowledge Graph Completion via Structure-Aware Alignment-Tuning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1061
-
[71]
QA - GNN : Reasoning with Language Models and Knowledge Graphs for Question Answering
Yasunaga, Michihiro and Ren, Hongyu and Bosselut, Antoine and Liang, Percy and Leskovec, Jure. QA - GNN : Reasoning with Language Models and Knowledge Graphs for Question Answering. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naac...
-
[72]
Tele-Knowledge Pre-training for Fault Analysis , year=
Chen, Zhuo and Zhang, Wen and Huang, Yufeng and Chen, Mingyang and Geng, Yuxia and Yu, Hongtao and Bi, Zhen and Zhang, Yichi and Yao, Zhen and Song, Wenting and Wu, Xinliang and Yang, Yi and Chen, Mingyi and Lian, Zhaoyang and Li, Yingying and Cheng, Lei and Chen, Huajun , booktitle=. Tele-Knowledge Pre-training for Fault Analysis , year=
-
[73]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages =
Wang, Hongwei and Ren, Hongyu and Leskovec, Jure , title =. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages =. 2021 , url =
2021
-
[74]
Translating embeddings for modeling multi-relational data , year =
Bordes, Antoine and Usunier, Nicolas and Garcia-Dur\'. Translating embeddings for modeling multi-relational data , year =. Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 , pages =
-
[75]
Ge, Xiou and Wang, Yun Cheng and Wang, Bin and Kuo, C.-C. Jay. Compounding Geometric Operations for Knowledge Graph Completion. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.384
-
[76]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Complex Embeddings for Simple Link Prediction , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
2016
-
[77]
International Conference on Learning Representations , year=
RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space , author=. International Conference on Learning Representations , year=
-
[78]
Unifying Large Language Models and Knowledge Graphs: A Roadmap , year=
Pan, Shirui and Luo, Linhao and Wang, Yufei and Chen, Chen and Wang, Jiapu and Wu, Xindong , journal=. Unifying Large Language Models and Knowledge Graphs: A Roadmap , year=
-
[79]
Contextualization Distillation from Large Language Model for Knowledge Graph Completion
Li, Dawei and Tan, Zhen and Chen, Tianlong and Liu, Huan. Contextualization Distillation from Large Language Model for Knowledge Graph Completion. Findings of the Association for Computational Linguistics: EACL 2024. 2024
2024
-
[80]
S im KGC : Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models
Wang, Liang and Zhao, Wei and Wei, Zhuoyu and Liu, Jingming. S im KGC : Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.295
-
[81]
2019 , eprint=
KG-BERT: BERT for Knowledge Graph Completion , author=. 2019 , eprint=
2019
-
[82]
Embedding Entities and Relations for Learning and Inference in Knowledge Bases , booktitle =
Bishan Yang and Wen. Embedding Entities and Relations for Learning and Inference in Knowledge Bases , booktitle =
-
[83]
Dettmers, Tim and Minervini, Pasquale and Stenetorp, Pontus and Riedel, Sebastian , title =. Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence , articleno =. 2018 , isbn =
2018
-
[84]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Geometry Interaction Knowledge Graph Embeddings , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2022 , month=. doi:10.1609/aaai.v36i5.20491 , abstractNote=
-
[85]
Wang, Xiaozhi and Gao, Tianyu and Zhu, Zhaocheng and Zhang, Zhengyan and Liu, Zhiyuan and Li, Juanzi and Tang, Jian , title = ". Transactions of the Association for Computational Linguistics , volume =. 2021 , month =. doi:10.1162/tacl_a_00360 , url =
-
[86]
KICGPT : Large Language Model with Knowledge in Context for Knowledge Graph Completion
Wei, Yanbin and Huang, Qiushi and Zhang, Yu and Kwok, James. KICGPT : Large Language Model with Knowledge in Context for Knowledge Graph Completion. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.580
-
[87]
Multi-perspective Improvement of Knowledge Graph Completion with Large Language Models
Xu, Derong and Zhang, Ziheng and Lin, Zhenxi and Wu, Xian and Zhu, Zhihong and Xu, Tong and Zhao, Xiangyu and Zheng, Yefeng and Chen, Enhong. Multi-perspective Improvement of Knowledge Graph Completion with Large Language Models. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-CO...
2024
-
[88]
Liu, Yang and Tian, Xiaobin and Sun, Zequn and Hu, Wei , title =. 2024 , isbn =. doi:10.1007/978-3-031-77844-5_11 , booktitle =
-
[89]
Retrieval, Reasoning, Re-ranking: A Context-Enriched Framework for Knowledge Graph Completion
Li, Muzhi and Yang, Cehao and Xu, Chengjin and Jiang, Xuhui and Qi, Yiyan and Guo, Jian and Leung, Ho-fung and King, Irwin. Retrieval, Reasoning, Re-ranking: A Context-Enriched Framework for Knowledge Graph Completion. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language...
-
[90]
Filter-then-Generate: Large Language Models with Structure-Text Adapter for Knowledge Graph Completion
Liu, Ben and Zhang, Jihai and Lin, Fangquan and Yang, Cheng and Peng, Min. Filter-then-Generate: Large Language Models with Structure-Text Adapter for Knowledge Graph Completion. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[91]
ACM Multimedia 2024 , year=
Making Large Language Models Perform Better in Knowledge Graph Completion , author=. ACM Multimedia 2024 , year=
2024
-
[92]
Luo, Kangyang and Bai, Yuzhuo and Gao, Cheng and Si, Shuzheng and Liu, Zhu and Shen, Yingli and Wang, Zhitong and Kong, Cunliang and Li, Wenhao and Huang, Yufei and Tian, Ye and Xiong, Xuantang and Han, Lei and Sun, Maosong. GLTW : Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion. Findings of the Association ...
-
[93]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[94]
Lin, Qika and Zhao, Tianzhe and He, Kai and Peng, Zhen and Xu, Fangzhi and Huang, Ling and Ma, Jingying and Feng, Mengling. Self-supervised Quantized Representation for Seamlessly Integrating Knowledge Graphs with Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. d...
-
[95]
2022 , eprint=
NodePiece: Compositional and Parameter-Efficient Representations of Large Knowledge Graphs , author=. 2022 , eprint=
2022
-
[96]
Neural Discrete Representation Learning , url =
van den Oord, Aaron and Vinyals, Oriol and kavukcuoglu, koray , booktitle =. Neural Discrete Representation Learning , url =
-
[97]
Taming Transformers for High-Resolution Image Synthesis , year=
Esser, Patrick and Rombach, Robin and Ommer, Björn , booktitle=. Taming Transformers for High-Resolution Image Synthesis , year=
-
[98]
2025 , eprint=
ReaLM: Residual Quantization Bridging Knowledge Graph Embeddings and Large Language Models , author=. 2025 , eprint=
2025
-
[99]
Autoregressive Image Generation using Residual Quantization , year=
Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin , booktitle=. Autoregressive Image Generation using Residual Quantization , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.