Recognition: unknown
Fine-Grained Perspectives: Modeling Explanations with Annotator-Specific Rationales
Pith reviewed 2026-05-09 21:24 UTC · model grok-4.3
The pith
Jointly modeling annotator labels and their specific rationales improves predictive performance and captures fine-grained disagreement in NLI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating explanation modeling substantially improves predictive performance over a baseline annotator-aware classifier. The prefixed bridge explainer achieves more stable label alignment and higher semantic consistency, while the post-hoc explainer yields stronger lexical similarity. These results indicate that modeling explanations as expressions of fine-grained perspective provides a richer and more faithful representation of disagreement. The approaches advance perspectivist modeling by integrating annotator-specific rationales into both predictive and generative components.
What carries the argument
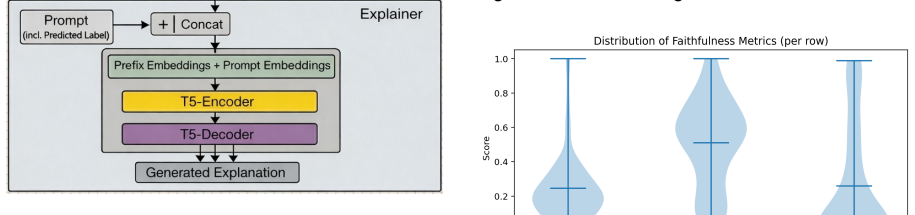
The User Passport mechanism conditions predictions on annotator identity and demographic metadata at the representation level, combined with a prefixed bridge explainer that transfers annotator-conditioned classifier representations directly into a generative model and a post-hoc prompt-based explainer.
If this is right
- Predictive accuracy on annotator-specific labels rises when explanations are modeled jointly rather than treated as a separate task.
- The prefixed bridge design produces explanations whose labels align more stably with the classifier output and show higher semantic consistency.
- The post-hoc design generates explanations that match the lexical content of human rationales more closely.
- Disagreement among annotators is represented more faithfully once rationales are treated as part of the modeling objective.
- Perspectivist systems gain from embedding annotator rationales inside both the classification and generation pipelines.
Where Pith is reading between the lines
- The same joint-modeling pattern could be applied to other subjective tasks such as toxicity detection or stance classification to test whether explanation conditioning reduces label variance.
- Because the passport encodes demographic metadata, the approach might be extended to measure whether generated explanations surface demographic-specific reasoning patterns.
- If the generated rationales prove reliable, they could serve as training signals for future annotators to reduce inconsistency across labeling rounds.
Load-bearing premise
Annotator-provided rationales are faithful and consistent expressions of individual perspectives that transfer into model representations without introducing misalignment or noise.
What would settle it
A controlled experiment on a fresh disaggregated NLI dataset in which adding either explainer architecture fails to raise predictive accuracy or produce measurable alignment gains between labels and generated explanations.
Figures



read the original abstract
Beyond exploring disaggregated labels for modeling perspectives, annotator rationales provide fine-grained signals of individual perspectives. In this work, we propose a framework for jointly modeling annotator-specific label prediction and corresponding explanations, fine-tuned on the annotators' provided rationales. Using a dataset with disaggregated natural language inference (NLI) annotations and annotator-provided explanations, we condition predictions on both annotator identity and demographic metadata through a representation-level User Passport mechanism. We further introduce two explainer architectures: a post-hoc prompt-based explainer and a prefixed bridge explainer that transfers annotator-conditioned classifier representations directly into a generative model. This design enables explanation generation aligned with individual annotator perspectives. Our results show that incorporating explanation modeling substantially improves predictive performance over a baseline annotator-aware classifier, with the prefixed bridge approach achieving more stable label alignment and higher semantic consistency, while the post-hoc approach yields stronger lexical similarity. These findings indicate that modeling explanations as expressions of fine-grained perspective provides a richer and more faithful representation of disagreement. The proposed approaches advance perspectivist modeling by integrating annotator-specific rationales into both predictive and generative components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for jointly modeling annotator-specific label prediction and explanation generation on disaggregated NLI data. It conditions both tasks on annotator identity and demographics via a representation-level User Passport mechanism and introduces two explainer architectures: a post-hoc prompt-based explainer and a prefixed bridge explainer that transfers annotator-conditioned classifier representations into a generative model. The central claim is that incorporating explanation modeling substantially improves predictive performance over a baseline annotator-aware classifier, with the prefixed bridge approach achieving more stable label alignment and higher semantic consistency while the post-hoc approach yields stronger lexical similarity; this is presented as advancing perspectivist modeling by treating rationales as fine-grained expressions of individual perspectives.
Significance. If the empirical gains and underlying assumptions hold, the work would meaningfully advance perspectivist NLP by showing how annotator rationales can be integrated into both predictive and generative components to better capture disagreement. The User Passport conditioning and the prefixed bridge transfer mechanism represent concrete architectural contributions that could generalize to other subjective annotation settings.
major comments (2)
- Abstract: the claim that 'incorporating explanation modeling substantially improves predictive performance over a baseline annotator-aware classifier' is load-bearing for the entire contribution, yet the abstract (and the provided text) supplies no quantitative metrics, statistical tests, dataset sizes, or ablation results to support the magnitude or reliability of the reported gains.
- Methods / Evaluation: the joint-modeling benefits rest on the assumption that annotator-provided rationales are faithful, consistent signals of individual perspectives that transfer cleanly into the User Passport representations; no per-annotator rationale-label alignment metrics, consistency checks, or noise analysis are described, leaving open the possibility that the prefixed bridge and post-hoc mechanisms propagate misalignment rather than enrich the conditioning.
minor comments (1)
- Abstract: the term 'User Passport mechanism' is used without a one-sentence definition or pointer to its prior introduction, which would aid readers unfamiliar with the conditioning technique.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below, agreeing where revisions are warranted and outlining specific changes to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the claim that 'incorporating explanation modeling substantially improves predictive performance over a baseline annotator-aware classifier' is load-bearing for the entire contribution, yet the abstract (and the provided text) supplies no quantitative metrics, statistical tests, dataset sizes, or ablation results to support the magnitude or reliability of the reported gains.
Authors: We agree that the abstract would be strengthened by including quantitative support for this central claim. In the revised manuscript, we will update the abstract to report specific metrics from our experiments, including accuracy improvements over the annotator-aware baseline, the dataset size (number of instances and annotators), and references to the statistical tests and ablation results presented in the evaluation section. This will make the magnitude and reliability of the gains immediately evident to readers. revision: yes
-
Referee: Methods / Evaluation: the joint-modeling benefits rest on the assumption that annotator-provided rationales are faithful, consistent signals of individual perspectives that transfer cleanly into the User Passport representations; no per-annotator rationale-label alignment metrics, consistency checks, or noise analysis are described, leaving open the possibility that the prefixed bridge and post-hoc mechanisms propagate misalignment rather than enrich the conditioning.
Authors: This concern about the faithfulness assumption is well-taken. While our current evaluation reports overall label alignment and semantic consistency metrics that support the benefits of joint modeling, we acknowledge the absence of granular per-annotator rationale-label alignment analysis. In the revision, we will add a new subsection with per-annotator alignment metrics, consistency checks across rationales and labels, and a discussion of potential noise sources. This addition will directly address whether the mechanisms enrich conditioning or risk propagating misalignment. revision: yes
Circularity Check
No circularity: empirical framework relies on held-out evaluation
full rationale
The paper describes a standard ML pipeline: conditioning a classifier on annotator identity and demographics via a User Passport representation, then fine-tuning two explainer architectures (post-hoc prompt-based and prefixed bridge) on provided rationales, followed by evaluation on held-out label prediction and explanation quality metrics. No equations or derivations are presented that reduce predictions to fitted inputs by construction, no self-definitional loops appear in the modeling choices, and no load-bearing claims rest on self-citations that themselves presuppose the target result. The reported gains in predictive performance and alignment are measured against external benchmarks (baseline annotator-aware classifier and held-out data), rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Annotator rationales faithfully capture individual perspectives
- domain assumption Conditioning on identity and demographics transfers effectively to explanation generation
Reference graph
Works this paper leans on
-
[3]
Simona Frenda, Gavin Abercrombie, Valerio Basile, Alessandro Pedrani, Raffaella Panizzon, Alessandra Teresa Cignarella, Cristina Marco, and Davide Bernardi. 2025. https://doi.org/10.1007/s10579-024-09766-4 Perspectivist approaches to natural language processing: a survey . Language Resources and Evaluation, 59:1719--1746
-
[9]
Matteo Mastromattei, Leonardo Ranaldi, Francesca Fallucchi, and Fabio Massimo Zanzotto. 2022 a . https://doi.org/10.7717/peerj-cs.859 Syntax and prejudice: ethically-charged biases of a syntax-based hate speech recognizer unveiled . PeerJ Computer Science, 8:e859
-
[10]
Michele Mastromattei, Valerio Basile, and Fabio Massimo Zanzotto. 2022 b . https://aclanthology.org/2022.nlperspectives-1.15/ Change my mind: How syntax-based hate speech recognizer can uncover hidden motivations based on different viewpoints . In Proceedings of the 1st Workshop on Perspectivist Approaches to NLP @LREC2022, pages 117--125, Marseille, Fran...
2022
-
[21]
Jin Xu, Mari \"e t Theune, and Daniel Braun. 2024. https://aclanthology.org/2024.icnlsp-1.1/ Leveraging annotator disagreement for text classification . In Proceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024), pages 1--10, Trento. Association for Computational Linguistics
2024
-
[22]
and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V
Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tai, Yi and Fedus, William and Li, Yunxuan and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Castro-Ros, Alex and Pellat, Marie and Robinson, Kevin and V...
2024
-
[23]
Pengcheng He and Jianfeng Gao and Weizhu Chen. 2023. http://arxiv.org/abs/2111.09543 DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
work page internal anchor Pith review arXiv 2023
-
[24]
Elisa Leonardelli and Silvia Casola and Siyao Peng and Giulia Rizzi and Valerio Basile and Elisabetta Fersini and Diego Frassinelli and Hyewon Jang and Maja Pavlovic and Barbara Plank and Massimo Poesio. 2026. http://arxiv.org/abs/2510.08460 LeWiDi-2025 at NLPerspectives: Third Edition of the Learning with Disagreements Shared Task
-
[26]
Toward a perspectivist turn in ground truthing for predictive computing
Cabitza, Federico and Campagner, Andrea and Basile, Valerio , year=. Toward a Perspectivist Turn in Ground Truthing for Predictive Computing , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , publisher=. doi:10.1609/aaai.v37i6.25840 , number=
-
[27]
M ulti PIC o: Multilingual Perspectivist Irony Corpus
Casola, Silvia and Frenda, Simona and Lo, Soda Marem and Sezerer, Erhan and Uva, Antonio and Basile, Valerio and Bosco, Cristina and Pedrani, Alessandro and Rubagotti, Chiara and Patti, Viviana and Bernardi, Davide. M ulti PIC o: Multilingual Perspectivist Irony Corpus. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistic...
-
[28]
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=. doi:10.1162/tacl_a_00449 , url=
-
[29]
Language Resources and Evaluation , volume =
Frenda, Simona and Abercrombie, Gavin and Basile, Valerio and Pedrani, Alessandro and Panizzon, Raffaella and Cignarella, Alessandra Teresa and Marco, Cristina and Bernardi, Davide , title =. Language Resources and Evaluation , volume =. 2025 , doi =
2025
-
[30]
How Far Can We Extract Diverse Perspectives from Large Language Models?
Hayati, Shirley Anugrah and Lee, Minhwa and Rajagopal, Dheeraj and Kang, Dongyeop. How Far Can We Extract Diverse Perspectives from Large Language Models?. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.306
-
[31]
Semeval-2023 task 11: Learning with disagreements (lewidi),
Leonardelli, Elisa and Abercrombie, Gavin and Almanea, Dina and Basile, Valerio and Fornaciari, Tommaso and Plank, Barbara and Rieser, Verena and Uma, Alexandra and Poesio, Massimo. S em E val-2023 Task 11: Learning with Disagreements ( L e W i D i). Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023). 2023. doi:10.18653/v...
-
[32]
Li, Maxwell Nye, and Jacob Andreas
Li, Belinda Z. and Nye, Maxwell and Andreas, Jacob. Implicit Representations of Meaning in Neural Language Models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.143
-
[33]
Li, Lei and Zhang, Yongfeng and Chen, Li , title =. Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM '20) , year =. doi:10.1145/3340531.3411992 , url =
-
[34]
Personalized Transformer for Explainable Recommendation
Li, Lei and Zhang, Yongfeng and Chen, Li. Personalized Transformer for Explainable Recommendation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.383
-
[35]
Lutz, Marlene and Sen, Indira and Ahnert, Georg and Rogers, Elisa and Strohmaier, Markus. The Prompt Makes the Person(a): A Systematic Evaluation of Sociodemographic Persona Prompting for Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1261
-
[36]
Change My Mind: How Syntax-based Hate Speech Recognizer Can Uncover Hidden Motivations Based on Different Viewpoints
Mastromattei, Michele and Basile, Valerio and Zanzotto, Fabio Massimo. Change My Mind: How Syntax-based Hate Speech Recognizer Can Uncover Hidden Motivations Based on Different Viewpoints. Proceedings of the 1st Workshop on Perspectivist Approaches to NLP @LREC2022. 2022
2022
-
[37]
PeerJ Computer Science , volume =
Mastromattei, Matteo and Ranaldi, Leonardo and Fallucchi, Francesca and Zanzotto, Fabio Massimo , title =. PeerJ Computer Science , volume =. 2022 , doi =
2022
-
[38]
Perspectives in Play: A Multi-Perspective Approach for More Inclusive NLP Systems , url=
Muscato, Benedetta and Passaro, Lucia and Gezici, Gizem and Giannotti, Fosca , year=. Perspectives in Play: A Multi-Perspective Approach for More Inclusive NLP Systems , url=. doi:10.24963/ijcai.2025/1092 , booktitle=
-
[39]
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Nirmal, Ayushi and Bhattacharjee, Amrita and Sheth, Paras and Liu, Huan. Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales. Proceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024). 2024. doi:10.18653/v1/2024.woah-1.17
-
[40]
Matthias Orlikowski and Jiaxin Pei and Paul Röttger and Philipp Cimiano and David Jurgens and Dirk Hovy. Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions. 2025. arXiv:2502.20897
-
[41]
Pavlick, Ellie and Kwiatkowski, Tom. Inherent Disagreements in Human Textual Inferences. Transactions of the Association for Computational Linguistics. 2019. doi:10.1162/tacl_a_00293
-
[42]
Unifying Data Perspectivism and Personalization: An Application to Social Norms
Plepi, Joan and Neuendorf, B \'e la and Flek, Lucie and Welch, Charles. Unifying Data Perspectivism and Personalization: An Application to Social Norms. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.500
-
[43]
Perspective Taking through Generating Responses to Conflict Situations
Plepi, Joan and Welch, Charles and Flek, Lucie. Perspective Taking through Generating Responses to Conflict Situations. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.387
-
[44]
Sarumi, Olufunke O. and Neuendorf, B. Corpus Considerations for Annotator Modeling and Scaling. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.59
-
[45]
and Welch, Charles and Braun, Daniel
Sarumi, Olufunke O. and Welch, Charles and Braun, Daniel. NLP - R es T eam at L e W i D i-2025:Performance Shifts in Perspective Aware Models based on Evaluation Metrics. Proceedings of the The 4th Workshop on Perspectivist Approaches to NLP. 2025. doi:10.18653/v1/2025.nlperspectives-1.19
-
[46]
S em E val-2021 Task 12: Learning with Disagreements
Uma, Alexandra and Fornaciari, Tommaso and Dumitrache, Anca and Miller, Tristan and Chamberlain, Jon and Plank, Barbara and Simpson, Edwin and Poesio, Massimo. S em E val-2021 Task 12: Learning with Disagreements. Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021). 2021. doi:10.18653/v1/2021.semeval-1.41
-
[47]
and Perez-Rosas, Veronica and Mihalcea, Rada
Welch, Charles and Gu, Chenxi and Kummerfeld, Jonathan K. and Perez-Rosas, Veronica and Mihalcea, Rada. Leveraging Similar Users for Personalized Language Modeling with Limited Data. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.122
-
[48]
Leveraging Annotator Disagreement for Text Classification
Xu, Jin and Theune, Mari. Leveraging Annotator Disagreement for Text Classification. Proceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024). 2024
2024
-
[49]
and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V
Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tai, Yi and Fedus, William and Li, Yunxuan and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Castro-Ros, Alex and Pellat, Marie and Robinson, Kevin and V...
2024
-
[50]
2023 , eprint=
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , author=. 2023 , eprint=
2023
-
[51]
2026 , eprint=
LeWiDi-2025 at NLPerspectives: Third Edition of the Learning with Disagreements Shared Task , author=. 2026 , eprint=
2025
-
[52]
V ari E rr NLI : Separating Annotation Error from Human Label Variation
Weber-Genzel, Leon and Peng, Siyao and De Marneffe, Marie-Catherine and Plank, Barbara. V ari E rr NLI : Separating Annotation Error from Human Label Variation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.123
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.