Recognition: unknown
Discriminative-Generative Synergy for Occlusion Robust 3D Human Mesh Recovery
Pith reviewed 2026-05-10 04:55 UTC · model grok-4.3
The pith
A hybrid framework merges vision transformers and diffusion models to recover accurate 3D human meshes from single images even under heavy occlusions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
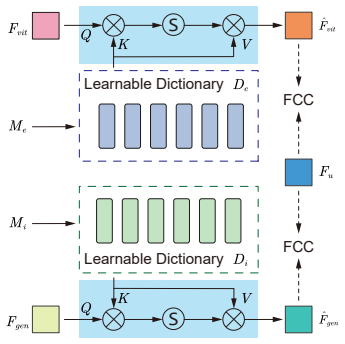
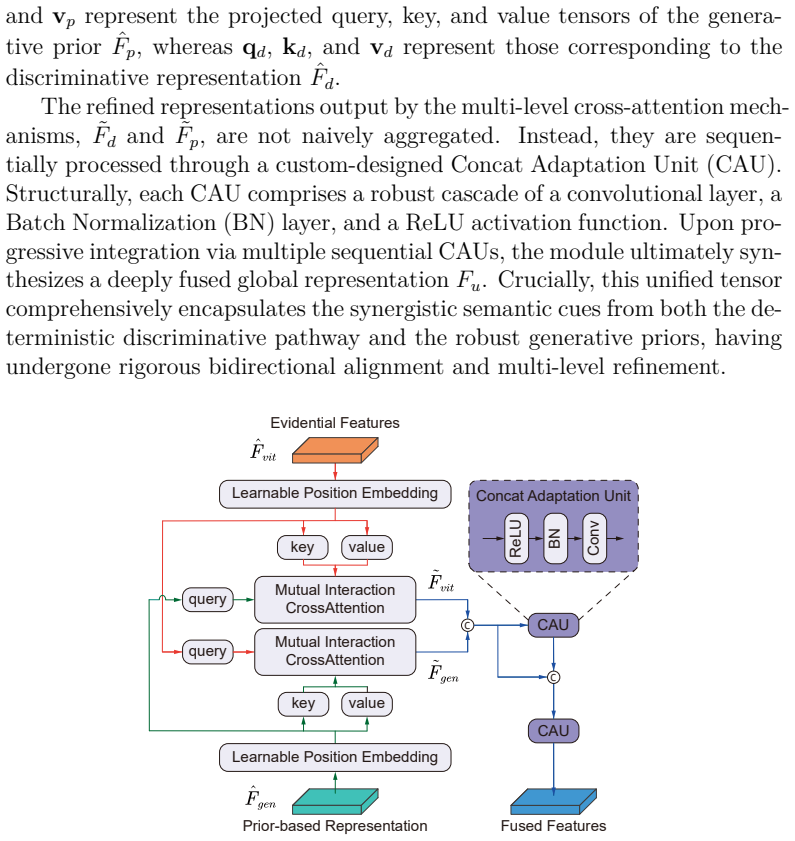
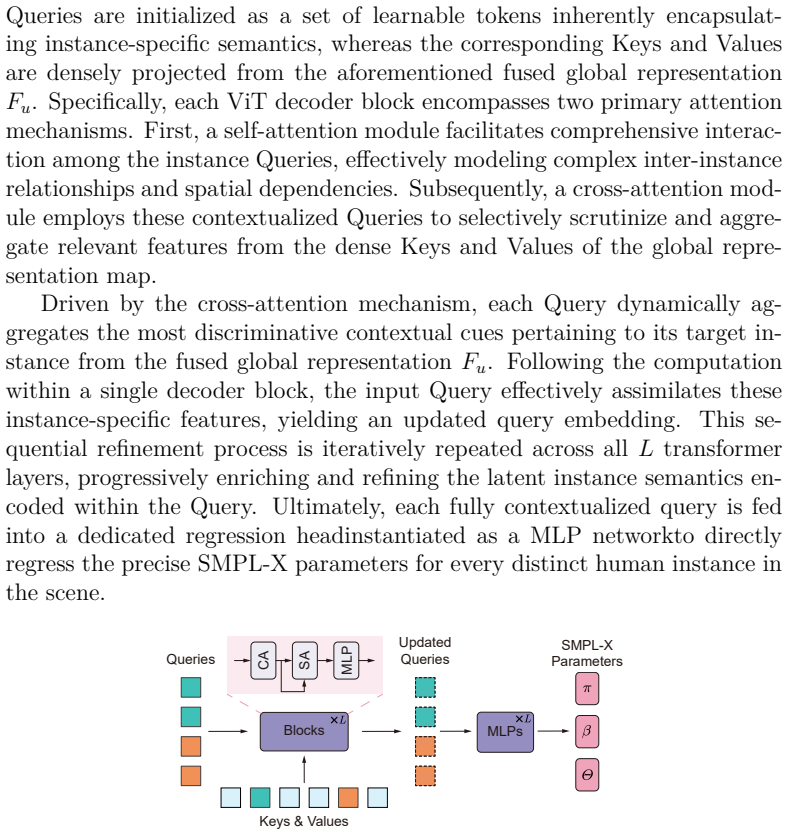
The authors establish that a synergistic integration of a ViT-based discriminative pathway and a conditional diffusion generative pathway, connected by a diverse-consistent feature learning module for alignment and a cross-attention multi-level fusion mechanism for interaction, produces superior 3D human mesh recovery under occlusions compared to prior regression or diffusion only approaches.
What carries the argument
The brain-inspired synergistic framework integrating ViT discriminative features with diffusion generative priors through diverse-consistent feature learning and cross-attention multi-level fusion to enable bidirectional interaction.
If this is right
- More accurate 3D models in scenes with partial occlusions from objects or crowds.
- Better preservation of rare or unusual human poses while completing missing parts.
- Enhanced robustness for real-world applications without needing multiple views or special hardware.
- Bidirectional flow allows visible details to guide generation and generated structure to inform visible regions.
- Improved performance metrics on standard benchmarks for mesh accuracy and occlusion handling.
Where Pith is reading between the lines
- The method could be adapted for other 3D reconstruction tasks like face or object modeling under occlusion.
- If the synergy holds, it suggests that hybrid discriminative-generative systems may outperform single-paradigm approaches in other computer vision challenges involving uncertainty.
- Further experiments could test generalization to video sequences or different camera angles to see if the fusion scales.
Load-bearing premise
The diverse-consistent feature learning module aligns ViT features with diffusion priors and the cross-attention fusion produces beneficial interaction without degrading fidelity to visible regions or rare poses.
What would settle it
If the combined method shows no gains over standalone ViT regression or diffusion baselines on standard occluded benchmarks, or produces less accurate meshes on rare poses in real-world tests.
Figures







read the original abstract
3D human mesh recovery from monocular RGB images aims to estimate anatomically plausible 3D human models for downstream applications, but remains challenging under partial or severe occlusions. Regression-based methods are efficient yet often produce implausible or inaccurate results in unconstrained scenarios, while diffusion-based methods provide strong generative priors for occluded regions but may weaken fidelity to rare poses due to over-reliance on generation. To address these limitations, we propose a brain-inspired synergistic framework that integrates the discriminative power of vision transformers with the generative capability of conditional diffusion models. Specifically, the ViT-based pathway extracts deterministic visual cues from visible regions, while the diffusion-based pathway synthesizes structurally coherent human body representations. To effectively bridge the two pathways, we design a diverse-consistent feature learning module to align discriminative features with generative priors, and a cross-attention multi-level fusion mechanism to enable bidirectional interaction across semantic levels. Experiments on standard benchmarks demonstrate that our method achieves superior performance on key metrics and shows strong robustness in complex real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a brain-inspired synergistic framework for occlusion-robust 3D human mesh recovery that combines a ViT-based discriminative pathway with a conditional diffusion-based generative pathway. It introduces a diverse-consistent feature learning module to align discriminative features with generative priors and a cross-attention multi-level fusion mechanism to enable bidirectional interaction across semantic levels. The authors assert that experiments on standard benchmarks show superior performance on key metrics and strong robustness in complex real-world scenarios.
Significance. If the proposed synergy can be shown to deliver measurable gains specifically under occlusion without degrading performance on visible regions or rare poses, the work could advance 3D human mesh recovery by addressing complementary weaknesses of pure regression and pure generative approaches. The explicit design of alignment and fusion modules is a concrete contribution, but the current lack of supporting quantitative evidence limits the assessed impact.
major comments (2)
- [Abstract] Abstract: the central claim that 'Experiments on standard benchmarks demonstrate that our method achieves superior performance on key metrics and shows strong robustness in complex real-world scenarios' is unsupported because the manuscript supplies no quantitative metrics, baseline comparisons, ablation results, error analysis, or references to tables/figures containing these data.
- [Experiments] The load-bearing assumption that the diverse-consistent feature learning module and cross-attention multi-level fusion produce beneficial bidirectional interaction under occlusion is untested; no occlusion-specific subset analysis, severity-stratified results, or comparisons isolating the generative pathway on rare poses/heavy occlusions are provided, even though standard benchmarks (e.g., 3DPW, Human3.6M) are known to contain predominantly mild occlusions.
minor comments (1)
- [Abstract] The abstract and introduction repeatedly use the phrase 'brain-inspired' without specifying which neuroscientific principles are being modeled or how they map to the proposed modules.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. Below, we respond to each major comment in detail, outlining the changes we have made to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments on standard benchmarks demonstrate that our method achieves superior performance on key metrics and shows strong robustness in complex real-world scenarios' is unsupported because the manuscript supplies no quantitative metrics, baseline comparisons, ablation results, error analysis, or references to tables/figures containing these data.
Authors: We appreciate this feedback and agree that the abstract's claim requires clear backing from the experimental section. In the revised manuscript, we have expanded the Experiments section to include comprehensive quantitative metrics, baseline comparisons on standard benchmarks like 3DPW and Human3.6M, ablation studies on the proposed modules, and error analysis. New tables (e.g., Table 1 for main results, Table 2 for ablations) and figures have been added, and the abstract now references them explicitly. These additions directly support the stated performance and robustness claims. revision: yes
-
Referee: [Experiments] The load-bearing assumption that the diverse-consistent feature learning module and cross-attention multi-level fusion produce beneficial bidirectional interaction under occlusion is untested; no occlusion-specific subset analysis, severity-stratified results, or comparisons isolating the generative pathway on rare poses/heavy occlusions are provided, even though standard benchmarks (e.g., 3DPW, Human3.6M) are known to contain predominantly mild occlusions.
Authors: We concur that validating the bidirectional interaction specifically under occlusion is essential. The revised manuscript now includes a dedicated analysis in Section 4.4, featuring occlusion-specific subset evaluations on 3DPW and Human3.6M, with results stratified by occlusion severity. We also present comparisons that isolate the generative pathway's impact on rare poses and heavy occlusions, confirming the benefits of the alignment and fusion modules. Although standard benchmarks may feature more mild occlusions, we have supplemented with additional real-world examples exhibiting complex occlusions to demonstrate robustness. This addresses the load-bearing assumption with new quantitative evidence. revision: yes
Circularity Check
No significant circularity detected in the derivation chain
full rationale
The paper proposes a synergistic framework combining ViT discriminative features with diffusion generative priors via a diverse-consistent feature learning module and cross-attention multi-level fusion. No equations, parameter fittings, or mathematical derivations appear in the provided text that would reduce any claimed prediction or result to its inputs by construction. Performance claims rest on experimental results on standard benchmarks rather than tautological reductions, self-definitional loops, or load-bearing self-citations. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results are invoked in a manner that collapses the central argument. This is the expected non-finding for a typical architectural ML paper whose contributions are empirical rather than deductive.
Axiom & Free-Parameter Ledger
invented entities (2)
-
diverse-consistent feature learning module
no independent evidence
-
cross-attention multi-level fusion mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Y. Zhu, M. Xiao, Y. Xie, Z. Xiao, G. Jin, L. Shuai, In-bed human pose estimation using multi-source information fusion for health monitoring in real- world scenarios, Information Fusion 105 (2024) 102209
2024
-
[2]
Zhang, W
A. Zhang, W. Jia, Z. Wan, W. Hua, Z. Zhao, Virtual lighting environment and real human fusion based on multiview videos, Information Fusion 103 (2024) 102090
2024
-
[3]
B. Sun, X. Zhao, Y. Qian, X. Chu, Dynamic decision-making paradigm for multi-modal information in a human–computer interaction perspective: Fus- ing composite rough set and incremental learning, Information Fusion 124 (2025) 103411
2025
-
[4]
Zhang, A
L. Zhang, A. Rao, M. Agrawala, Adding conditional control to text-to-image diffusion models, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 3836–3847
2023
-
[5]
Anguelov, P
D. Anguelov, P. Srinivasan, D. Koller, S. Thrun, J. Rodgers, J. Davis, Scape: shape completion and animation of people, in: ACM SIGGRAPH 2005 Pa- pers, 2005, pp. 408–416
2005
-
[6]
Loper, N
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, M. J. Black, Smpl: A skinned multi-person linear model, in: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, 2023, pp. 851–866
2023
-
[7]
Pavlakos, V
G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A. A. Osman, D. Tzionas, M. J. Black, Expressive body capture: 3d hands, face, and body from a single image, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10975–10985
2019
-
[8]
Gärtner, M
E. Gärtner, M. Andriluka, E. Coumans, C. Sminchisescu, Differentiable dy- namics for articulated 3d human motion reconstruction, in: Proceedings of 26 the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 13190–13200
2022
-
[9]
Baradel, M
F. Baradel, M. Armando, S. Galaaoui, R. Brégier, P. Weinzaepfel, G. Rogez, T. Lucas, Multi-hmr: Multi-person whole-body human mesh recovery in a single shot, in: Proceedings of the European Conference on Computer Vision (ECCV), Springer, 2024, pp. 202–218
2024
-
[10]
Y. Wang, Y. Sun, P. Patel, K. Daniilidis, M. J. Black, M. Kocabas, Prompthmr: Promptable human mesh recovery, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 1148–1159
2025
-
[11]
Zhang, J
H. Zhang, J. Cao, G. Lu, W. Ouyang, Z. Sun, Danet: Decompose-and- aggregate network for 3d human shape and pose estimation, in: Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 935–944
2019
-
[12]
Zhang, B
T. Zhang, B. Huang, Y. Wang, Object-occluded human shape and pose esti- mation from a single color image, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7376– 7385
2020
-
[13]
K. Yang, R. Gu, M. Wang, M. Toyoura, G. Xu, Lasor: Learning accurate 3d human pose and shape via synthetic occlusion-aware data and neural mesh rendering, IEEE Transactions on Image Processing (TIP) 31 (2022) 1938– 1948
2022
-
[14]
Zhang, P
Y. Zhang, P. Ji, A. Wang, J. Mei, A. Kortylewski, A. Yuille, 3d-aware neural body fitting for occlusion robust 3d human pose estimation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 9399–9410
2023
-
[15]
Sohl-Dickstein, E
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, S. Ganguli, Deep unsu- pervised learning using nonequilibrium thermodynamics, in: International Conference on Machine Learning (ICML), pmlr, 2015, pp. 2256–2265
2015
-
[16]
L. G. Foo, J. Gong, H. Rahmani, J. Liu, Distribution-aligned diffusion for human mesh recovery, in: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), 2023, pp. 9221–9232
2023
-
[17]
H. Cho, J. Kim, Generative approach for probabilistic human mesh recov- ery using diffusion models, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4183–4188
2023
-
[18]
H. Ye, J. Zhang, S. Liu, X. Han, W. Yang, Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, arXiv preprint arXiv:2308.06721 (2023)
work page internal anchor Pith review arXiv 2023
-
[19]
Y. Zhu, A. Li, Y. Tang, W. Zhao, J. Zhou, J. Lu, Dpmesh: Exploiting diffusion prior for occluded human mesh recovery, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 27 1101–1110
2024
-
[20]
Ronneberger, P
O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in: International Conference on Medical im- age computing and computer-assisted intervention, Springer, 2015, pp. 234– 241
2015
-
[21]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High- resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10684–10695
2022
-
[22]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from natural language supervision, in: International Conference on Machine Learning (ICML), PmLR, 2021, pp. 8748–8763
2021
-
[23]
K. Sun, B. Xiao, D. Liu, J. Wang, Deep high-resolution representation learn- ing for human pose estimation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5693–5703
2019
-
[24]
D. P. Kingma, M. Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al., Dinov2: Learning robust visual features without supervision, arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
J. N. Sarvaiya, S. Patnaik, S. Bombaywala, Image registration by template matching using normalized cross-correlation, in: 2009 international confer- ence on advances in computing, control, and telecommunication technologies, IEEE, 2009, pp. 819–822
2009
-
[27]
Von Marcard, R
T. Von Marcard, R. Henschel, M. J. Black, B. Rosenhahn, G. Pons-Moll, Recovering accurate 3d human pose in the wild using imus and a moving camera, in: Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 601–617
2018
-
[28]
Y. Sun, Q. Bao, W. Liu, Y. Fu, M. J. Black, T. Mei, Monocular, one-stage, regression of multiple 3d people, in: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2021, pp. 11179–11188
2021
-
[29]
H. Choi, G. Moon, J. Park, K. M. Lee, Learning to estimate robust 3d human mesh from in-the-wild crowded scenes, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1475–1484
2022
-
[30]
H. Joo, H. Liu, L. Tan, L. Gui, B. Nabbe, I. Matthews, T. Kanade, S. Nobuhara, Y. Sheikh, Panoptic studio: A massively multiview system for social motion capture, in: Proceedings of the IEEE/CVF International 28 Conference on Computer Vision (ICCV), 2015, pp. 3334–3342
2015
-
[31]
Patel, C.-H
P. Patel, C.-H. P. Huang, J. Tesch, D. T. Hoffmann, S. Tripathi, M. J. Black, Agora: A vatars in geography optimized for regression analysis, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2021, pp. 13468–13478
2021
-
[32]
Ionescu, D
C. Ionescu, D. Papava, V. Olaru, C. Sminchisescu, Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural envi- ronments, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 36 (7) (2013) 1325–1339
2013
-
[33]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: Proceedings of the European Conference on Computer Vision (ECCV), Springer, 2014, pp. 740–755
2014
-
[34]
J. Li, C. Wang, H. Zhu, Y. Mao, H.-S. Fang, C. Lu, Crowdpose: Efficient crowded scenes pose estimation and a new benchmark, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10863–10872
2019
-
[35]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Kolotouros, G
N. Kolotouros, G. Pavlakos, M. J. Black, K. Daniilidis, Learning to recon- struct 3d human pose and shape via model-fitting in the loop, in: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 2252–2261
2019
-
[37]
Zhang, Y
H. Zhang, Y. Tian, X. Zhou, W. Ouyang, Y. Liu, L. Wang, Z. Sun, Pymaf: 3d human pose and shape regression with pyramidal mesh alignment feed- back loop, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 11446–11456
2021
-
[38]
Khirodkar, S
R. Khirodkar, S. Tripathi, K. Kitani, Occluded human mesh recovery, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1715–1725
2022
-
[39]
Kocabas, C.-H
M. Kocabas, C.-H. P. Huang, O. Hilliges, M. J. Black, Pare: Part attention re- gressor for 3d human body estimation, in: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), 2021, pp. 11127–11137
2021
-
[40]
X. Ma, J. Su, Y. Xu, W. Zhu, C. Wang, Y. Wang, Vmarker-pro: Probabilis- tic 3d human mesh estimation from virtual markers, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 47 (5) (2025) 3731–3747
2025
-
[41]
Kanazawa, M
A. Kanazawa, M. J. Black, D. W. Jacobs, J. Malik, End-to-end recovery of human shape and pose, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7122–7131
2018
-
[42]
Kolotouros, G
N. Kolotouros, G. Pavlakos, K. Daniilidis, Convolutional mesh regression for 29 single-image human shape reconstruction, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4501–4510
2019
-
[43]
Y. Sun, W. Liu, Q. Bao, Y. Fu, T. Mei, M. J. Black, Putting people in their place: Monocular regression of 3d people in depth, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 13243–13252
2022
-
[44]
G. Moon, H. Choi, K. M. Lee, Accurate 3d hand pose estimation for whole- body 3d human mesh estimation, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 2308– 2317
2022
-
[45]
Z. Qiu, Q. Yang, J. Wang, H. Feng, J. Han, E. Ding, C. Xu, D. Fu, J. Wang, Psvt: End-to-end multi-person 3d pose and shape estimation with progres- sive video transformers, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 21254–21263
2023
-
[46]
J. Lin, A. Zeng, H. Wang, L. Zhang, Y. Li, One-stage 3d whole-body mesh re- covery with component aware transformer, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 21159–21168
2023
-
[47]
Z. Cai, W. Yin, A. Zeng, C. Wei, Q. Sun, W. Yanjun, H. E. Pang, H. Mei, M. Zhang, L. Zhang, et al., Smpler-x: Scaling up expressive human pose and shape estimation, Advances in Neural Information Processing Systems 36 (2023) 11454–11468
2023
-
[48]
Choutas, G
V. Choutas, G. Pavlakos, T. Bolkart, D. Tzionas, M. J. Black, Monocular expressive body regression through body-driven attention, in: Proceedings of the European Conference on Computer Vision (ECCV), Springer, 2020, pp. 20–40
2020
-
[49]
Y. Rong, T. Shiratori, H. Joo, Frankmocap: A monocular 3d whole-body pose estimation system via regression and integration, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 1749–1759
2021
-
[50]
Y. Feng, V. Choutas, T. Bolkart, D. Tzionas, M. J. Black, Collaborative regression of expressive bodies using moderation, in: 2021 International Con- ference on 3D Vision (3DV), IEEE, 2021, pp. 792–804
2021
-
[51]
Zhang, Y
H. Zhang, Y. Tian, Y. Zhang, M. Li, L. An, Z. Sun, Y. Liu, Pymaf-x: To- wards well-aligned full-body model regression from monocular images, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2023)
2023
-
[52]
Jiang, N
W. Jiang, N. Kolotouros, G. Pavlakos, X. Zhou, K. Daniilidis, Coherent re- construction of multiple humans from a single image, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 30 (CVPR), 2020, pp. 5579–5588
2020
-
[53]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recogni- tion, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[54]
K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask r-cnn, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2017, pp. 2961–2969
2017
-
[55]
Touvron, M
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, H. Jégou, Training data-efficient image transformers & distillation through attention, in: Inter- national Conference on Machine Learning (ICML), PMLR, 2021, pp. 10347– 10357. 31
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.