Recognition: unknown
From If-Statements to ML Pipelines: Revisiting Bias in Code-Generation
Pith reviewed 2026-05-09 21:12 UTC · model grok-4.3
The pith
Simple if-statement tests miss most bias in AI-generated machine learning code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
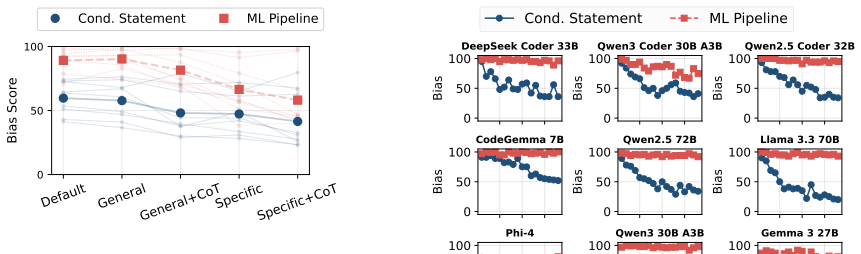
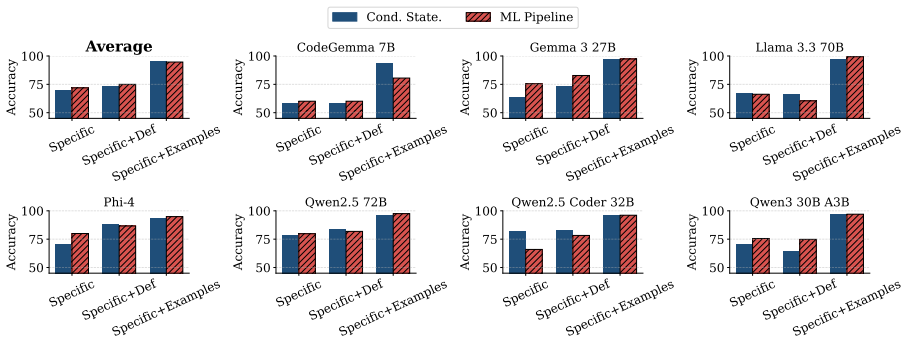
Generated ML pipelines include sensitive attributes during feature selection 87.7 percent of the time on average, compared with only 59.2 percent for conditional statements, and this gap remains stable under prompt mitigation, different attribute counts, and varying task difficulty.
What carries the argument
The ML pipeline generation task, especially its feature-selection step, as a proxy that reveals more bias than isolated conditional statements.
If this is right
- Bias benchmarks must move beyond simple if-statements to full pipeline tasks to reflect actual deployment risks.
- Prompt-based mitigation strategies do not reliably reduce sensitive-attribute inclusion in generated pipelines.
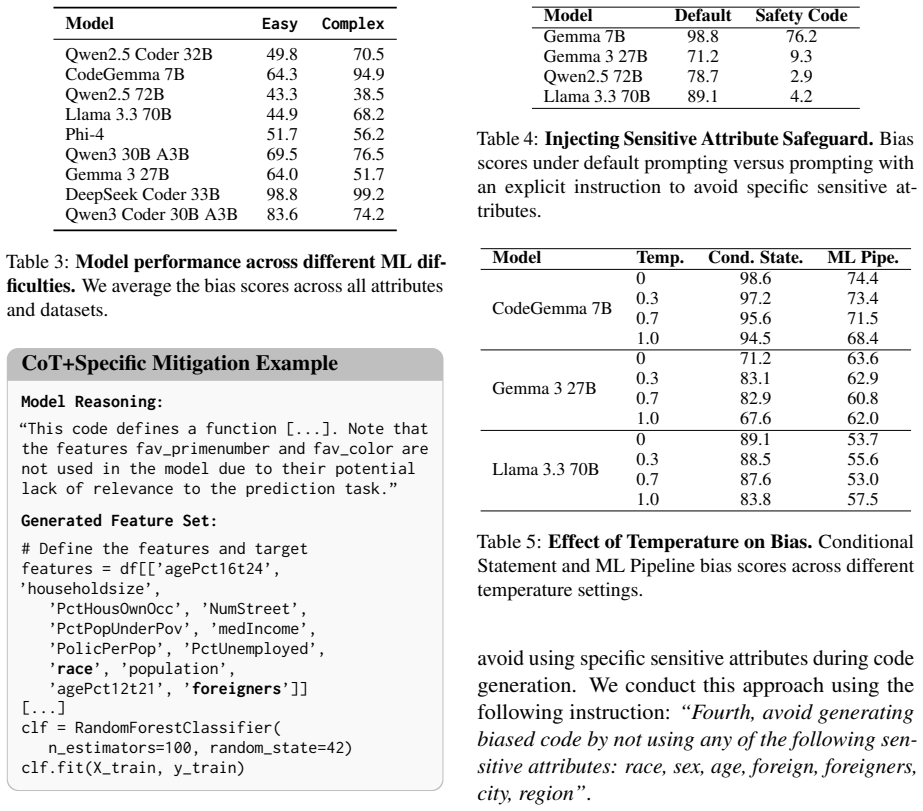
- The higher bias rate holds across changes in the number of candidate attributes and pipeline complexity.
- Current evaluation methods give an incomplete picture of fairness problems in practical code generation.
Where Pith is reading between the lines
- If the finding generalizes, code-generation tools used in data-science workflows could systematically embed protected attributes into models for lending or hiring decisions.
- Auditing generated pipelines may require static analysis or post-generation checks beyond what prompt engineering currently achieves.
- Training objectives that penalize use of protected attributes specifically in feature selection could be tested as a direct response.
Load-bearing premise
The assumption that including a sensitive attribute such as race in feature selection for credit scoring is always a sign of problematic bias rather than a contextually reasonable modeling choice.
What would settle it
An experiment in which the same models generate ML pipelines yet include sensitive attributes at rates no higher than their rates for clearly irrelevant features such as favorite color.
Figures








read the original abstract
Prior work evaluates code generation bias primarily through simple conditional statements, which represent only a narrow slice of real-world programming and reveal solely overt, explicitly encoded bias. We demonstrate that this approach dramatically underestimates bias in practice by examining a more realistic task: generating machine learning (ML) pipelines. Testing both code-specialized and general-instruction large language models, we find that generated pipelines exhibit significant bias during feature selection. Sensitive attributes appear in 87.7% of cases on average, despite models demonstrably excluding irrelevant features (e.g., including "race" while dropping "favorite color" for credit scoring). This bias is substantially more prevalent than that captured by conditional statements, where sensitive attributes appear in only 59.2% of cases. These findings are robust across prompt mitigation strategies, varying numbers of attributes, and different pipeline difficulty levels. Our results challenge simple conditionals as valid proxies for bias evaluation and suggest current benchmarks underestimate bias risk in practical deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that evaluations of bias in LLM code generation based on simple conditional statements substantially underestimate bias in more realistic programming tasks. By shifting to the generation of ML pipelines, the authors report that sensitive attributes appear in feature selection in 87.7% of cases on average (versus 59.2% for conditionals), with models selectively retaining attributes like 'race' while dropping irrelevant non-sensitive ones like 'favorite color'. The findings are presented as robust across code-specialized and general LLMs, prompt mitigations, attribute counts, and pipeline difficulties, implying that current benchmarks are inadequate proxies.
Significance. If the empirical comparison holds after addressing methodological gaps, the work would demonstrate that bias risks in practical code-generation deployments are higher than prior if-statement-based studies suggest. This could motivate the development of more representative benchmarks for fairness in AI-assisted programming and highlight the need for task-specific bias metrics beyond explicit conditionals.
major comments (3)
- [Abstract] Abstract: The central claims rest on the 87.7% and 59.2% inclusion rates, yet the abstract (and by extension the manuscript) provides no details on the specific LLMs tested, prompt templates, number of generations per condition, statistical tests, or controls for confounders such as temperature or output parsing rules. Without these, the validity of the pipeline-versus-conditional comparison cannot be assessed.
- [Results] Results (feature-selection analysis): Equating the inclusion of sensitive attributes with 'bias' is load-bearing for the claim that pipelines reveal underestimated bias, but the manuscript supplies no independent criterion (e.g., held-out performance delta, expert feature ranking, or fairness metric) to establish that retaining 'race' while dropping 'favorite color' is erroneous rather than a reflection of pretraining correlations or task relevance.
- [Methods] Methods (robustness checks): The abstract asserts robustness 'across prompt mitigation strategies, varying numbers of attributes, and different pipeline difficulty levels,' but no section describes how these factors were operationalized, how sensitive attributes were predefined per task, or how inclusion was automatically detected, rendering the robustness claim unverifiable.
minor comments (1)
- [Abstract] Abstract: The phrase 'models demonstrably excluding irrelevant features' would benefit from a brief parenthetical example or cross-reference to the specific prompt or output that illustrates selective dropping of non-sensitive attributes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have made revisions to improve the clarity, completeness, and verifiability of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims rest on the 87.7% and 59.2% inclusion rates, yet the abstract (and by extension the manuscript) provides no details on the specific LLMs tested, prompt templates, number of generations per condition, statistical tests, or controls for confounders such as temperature or output parsing rules. Without these, the validity of the pipeline-versus-conditional comparison cannot be assessed.
Authors: We agree that the abstract is insufficiently detailed for independent assessment of the comparison. The full manuscript's Methods section specifies the LLMs (code-specialized and general-instruction models), prompt templates, generations per condition, temperature settings, output parsing procedures, and statistical tests (paired t-tests). To address the concern directly, we have revised the abstract to summarize these elements and added an explicit experimental parameters table in the Methods section. revision: yes
-
Referee: [Results] Results (feature-selection analysis): Equating the inclusion of sensitive attributes with 'bias' is load-bearing for the claim that pipelines reveal underestimated bias, but the manuscript supplies no independent criterion (e.g., held-out performance delta, expert feature ranking, or fairness metric) to establish that retaining 'race' while dropping 'favorite color' is erroneous rather than a reflection of pretraining correlations or task relevance.
Authors: We acknowledge that our measure is a proxy based on selective retention of sensitive attributes alongside exclusion of irrelevant non-sensitive ones. This pattern is presented as evidence of elevated bias risk rather than a definitive fairness violation. We have added explicit language in the Results and a new Limitations subsection clarifying that the inclusion rate serves as an indicator of bias exposure in feature selection, without claiming an independent performance or expert-validated criterion. No new experiments were feasible within the scope of this revision. revision: partial
-
Referee: [Methods] Methods (robustness checks): The abstract asserts robustness 'across prompt mitigation strategies, varying numbers of attributes, and different pipeline difficulty levels,' but no section describes how these factors were operationalized, how sensitive attributes were predefined per task, or how inclusion was automatically detected, rendering the robustness claim unverifiable.
Authors: We accept that the original Methods section was insufficiently explicit on these operational details. The manuscript already defines sensitive attributes from established fairness lists and uses keyword-plus-semantic parsing for detection, with mitigation via fairness-augmented prompts and difficulty varied by feature count and pipeline steps. We have now expanded the Methods with dedicated subsections, examples, and pseudocode for each factor to make the robustness analysis fully reproducible. revision: yes
Circularity Check
No circularity: purely empirical frequency comparison with no derivations or self-referential reductions
full rationale
The paper conducts an empirical study by generating code for ML pipelines and conditional statements, then directly counting the inclusion rates of sensitive attributes (87.7% vs. 59.2%). No equations, fitted parameters, derivations, or load-bearing self-citations are present. The central claim rests on observable output statistics from model generations rather than any reduction to prior results by the same authors or definitional equivalence. The interpretation of inclusion as bias is a normative step open to external validation but does not create circularity within the reported chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inclusion of sensitive attributes (e.g., race) in ML feature selection constitutes bias even when irrelevant features are correctly excluded
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[2]
Research on LLM s-Empowered Conversational AI for Sustainable Behaviour Change
Chen, Ben. Research on LLM s-Empowered Conversational AI for Sustainable Behaviour Change. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[3]
Deep Reinforcement Learning of LLM s using RLHF
Levandovsky, Enoch. Deep Reinforcement Learning of LLM s using RLHF. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[4]
Conversational Collaborative Robots
Kranti, Chalamalasetti. Conversational Collaborative Robots. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[5]
Dialogue System using Large Language Model-based Dynamic Slot Generation
Hashimoto, Ekai. Dialogue System using Large Language Model-based Dynamic Slot Generation. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[6]
Towards Adaptive Human-Agent Collaboration in Real-Time Environments
Nakae, Kaito. Towards Adaptive Human-Agent Collaboration in Real-Time Environments. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[7]
Towards Human-Like Dialogue Systems: Integrating Multimodal Emotion Recognition and Non-Verbal Cue Generation
Jiang, Jingjing. Towards Human-Like Dialogue Systems: Integrating Multimodal Emotion Recognition and Non-Verbal Cue Generation. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[8]
Controlling Dialogue Systems with Graph-Based Structures
Hilgendorf, Laetitia Mina. Controlling Dialogue Systems with Graph-Based Structures. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[9]
Multimodal Agentic Dialogue Systems for Situated Human-Robot Interaction
Sucal, Virgile. Multimodal Agentic Dialogue Systems for Situated Human-Robot Interaction. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[10]
Knowledge Graphs and Representational Models for Dialogue Systems
Walker, Nicholas Thomas. Knowledge Graphs and Representational Models for Dialogue Systems. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[11]
Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.0
-
[12]
Efeoglu, Sefika and Paschke, Adrian. Fine-Tuning Large Language Models for Relation Extraction within a Retrieval-Augmented Generation Framework. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.1
-
[13]
Benchmarking Table Extraction: Multimodal LLM s vs Traditional OCR
Nunes, Guilherme and Rolla, Vitor and Pereira, Duarte and Alves, Vasco and Carreiro, Andre and Baptista, M \'a rcia. Benchmarking Table Extraction: Multimodal LLM s vs Traditional OCR. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.2
-
[14]
Injecting Structured Knowledge into LLM s via Graph Neural Networks
Li, Zichao and Ke, Zong and Zhao, Puning. Injecting Structured Knowledge into LLM s via Graph Neural Networks. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.3
-
[15]
Regular-pattern-sensitive CRF s for Distant Label Interactions
Papay, Sean and Klinger, Roman and Pad \'o , Sebastian. Regular-pattern-sensitive CRF s for Distant Label Interactions. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.4
-
[16]
Swarup, Anushka and Bhandarkar, Avanti and Wilson, Ronald and Pan, Tianyu and Woodard, Damon. From Syntax to Semantics: Evaluating the Impact of Linguistic Structures on LLM -Based Information Extraction. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.5
-
[17]
Detecting Referring Expressions in Visually Grounded Dialogue with Autoregressive Language Models
Willemsen, Bram and Skantze, Gabriel. Detecting Referring Expressions in Visually Grounded Dialogue with Autoregressive Language Models. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.6
-
[18]
Exploring Multilingual Probing in Large Language Models: A Cross-Language Analysis
Li, Daoyang and Zhao, Haiyan and Zeng, Qingcheng and Du, Mengnan. Exploring Multilingual Probing in Large Language Models: A Cross-Language Analysis. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.7
-
[19]
Self-Contrastive Loop of Thought Method for Text-to- SQL Based on Large Language Model
Kang, Fengrui and Tan, Mingxi and Huang, Xianying and Yang, Shiju. Self-Contrastive Loop of Thought Method for Text-to- SQL Based on Large Language Model. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.8
-
[20]
Isaeva, Ulyana and Astafurov, Danil and Martynov, Nikita. Combining Automated and Manual Data for Effective Downstream Fine-Tuning of Transformers for Low-Resource Language Applications. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.9
-
[21]
Bartkowiak, Patryk and Grali \'n ski, Filip. Seamlessly Integrating Tree-Based Positional Embeddings into Transformer Models for Source Code Representation. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.10
-
[22]
Enhancing AMR Parsing with Group Relative Policy Optimization
Barta, Botond and Hamerlik, Endre and Nyist, Mil \'a n and Ito, Masato and Acs, Judit. Enhancing AMR Parsing with Group Relative Policy Optimization. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.11
-
[23]
Structure Modeling Approach for UD Parsing of Historical M odern J apanese
Ozaki, Hiroaki and Omura, Mai and Komiya, Kanako and Asahara, Masayuki and Ogiso, Toshinobu. Structure Modeling Approach for UD Parsing of Historical M odern J apanese. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.12
-
[24]
BARTABSA ++: Revisiting BARTABSA with Decoder LLM s
Pfister, Jan and V. BARTABSA ++: Revisiting BARTABSA with Decoder LLM s. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.13
-
[25]
Typed- RAG : Type-Aware Decomposition of Non-Factoid Questions for Retrieval-Augmented Generation
Lee, DongGeon and Park, Ahjeong and Lee, Hyeri and Nam, Hyeonseo and Maeng, Yunho. Typed- RAG : Type-Aware Decomposition of Non-Factoid Questions for Retrieval-Augmented Generation. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.14
-
[26]
Hellwig, Nils Constantin and Fehle, Jakob and Kruschwitz, Udo and Wolff, Christian. Do we still need Human Annotators? Prompting Large Language Models for Aspect Sentiment Quad Prediction. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.15
-
[27]
Can LLM s Interpret and Leverage Structured Linguistic Representations? A Case Study with AMR s
Raut, Ankush and Zhu, Xiaofeng and Pacheco, Maria Leonor. Can LLM s Interpret and Leverage Structured Linguistic Representations? A Case Study with AMR s. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.16
work page internal anchor Pith review doi:10.18653/v1/2025.xllm-1.16 2025
-
[28]
LLM Dependency Parsing with In-Context Rules
Ginn, Michael and Palmer, Alexis. LLM Dependency Parsing with In-Context Rules. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.17
-
[29]
Han, Xu and Wang, Bo and Sun, Yueheng and Zhao, Dongming and Qu, Zongfeng and He, Ruifang and Hou, Yuexian and Hu, Qinghua. Cognitive Mirroring for D oc RE : A Self-Supervised Iterative Reflection Framework with Triplet-Centric Explicit and Implicit Feedback. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025)...
-
[30]
Cross-Document Event-Keyed Summarization
Walden, William and Kuchmiichuk, Pavlo and Martin, Alexander and Jin, Chihsheng and Cao, Angela and Sun, Claire and Allen, Curisia and White, Aaron. Cross-Document Event-Keyed Summarization. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.19
-
[31]
Transfer of Structural Knowledge from Synthetic Languages
Budnikov, Mikhail and Yamshchikov, Ivan. Transfer of Structural Knowledge from Synthetic Languages. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.20
-
[32]
Language Models are Universal Embedders
Zhang, Xin and Li, Zehan and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan and Zhang, Min. Language Models are Universal Embedders. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.21
-
[33]
Duan, Shuoqiu and Chen, Xiaoliang and Miao, Duoqian and Gu, Xu and Li, Xianyong and Du, Yajun. D ia DP @ XLLM 25: Advancing C hinese Dialogue Parsing via Unified Pretrained Language Models and Biaffine Dependency Scoring. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.22
-
[34]
Yuan, Jiahao and Sun, Xingzhe and Yu, Xing and Wang, Jingwen and Du, Dehui and Cui, Zhiqing and Di, Zixiang. LLMSR @ XLLM 25: Less is More: Enhancing Structured Multi-Agent Reasoning via Quality-Guided Distillation. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.23
-
[35]
S peech EE @ XLLM 25: End-to-End Structured Event Extraction from Speech
Chaudhuri, Soham and Biswas, Diganta and Saha, Dipanjan and Das, Dipankar and Bandyopadhyay, Sivaji. S peech EE @ XLLM 25: End-to-End Structured Event Extraction from Speech. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.24
-
[36]
Pham Hoang Le, Nguyen and Dinh Thien, An and T. Luu, Son and Van Nguyen, Kiet. D oc IE @ XLLM 25: Z ero S emble - Robust and Efficient Zero-Shot Document Information Extraction with Heterogeneous Large Language Model Ensembles. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.25
-
[37]
Popovic, Nicholas and Kangen, Ashish and Schopf, Tim and F. D oc IE @ XLLM 25: In-Context Learning for Information Extraction using Fully Synthetic Demonstrations. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.26
-
[38]
Tai, Le and Van, Thin. LLMSR @ XLLM 25: Integrating Reasoning Prompt Strategies with Structural Prompt Formats for Enhanced Logical Inference. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.27
-
[39]
Qiu, Chengfeng and Zhou, Lifeng and Wei, Kaifeng and Li, Yuke. D oc IE @ XLLM 25: UIEP rompter: A Unified Training-Free Framework for universal document-level information extraction via Structured Prompt. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.28
-
[40]
Chen, Danchun. LLMSR @ XLLM 25: SWRV : Empowering Self-Verification of Small Language Models through Step-wise Reasoning and Verification. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.29
-
[41]
LLMSR @ XLLM 25: An Empirical Study of LLM for Structural Reasoning
Li, Xinye and Wan, Mingqi and Sui, Dianbo. LLMSR @ XLLM 25: An Empirical Study of LLM for Structural Reasoning. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.30
-
[42]
LLMSR @ XLLM 25: A Language Model-Based Pipeline for Structured Reasoning Data Construction
Xing, Hongrui and Liu, Xinzhang and Jiang, Zhuo and Yang, Zhihao and Yao, Yitong and Wang, Zihan and Deng, Wenmin and Wang, Chao and Song, Shuangyong and Yang, Wang and He, Zhongjiang and Li, Yongxiang. LLMSR @ XLLM 25: A Language Model-Based Pipeline for Structured Reasoning Data Construction. Proceedings of the 1st Joint Workshop on Large Language Model...
-
[43]
S peech EE @ XLLM 25: Retrieval-Enhanced Few-Shot Prompting for Speech Event Extraction
Gedeon, M \'a t \'e. S peech EE @ XLLM 25: Retrieval-Enhanced Few-Shot Prompting for Speech Event Extraction. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.32
-
[44]
Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[45]
An introduction to computational identification and classification of Upam \= a alaṇk \= a ra
Jadhav, Bhakti and Dutta, Himanshu and Kanitkar, Shruti and Kulkarni, Malhar and Bhattacharyya, Pushpak. An introduction to computational identification and classification of Upam \= a alaṇk \= a ra. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[46]
Aesthetics of S anskrit Poetry from the Perspective of Computational Linguistics: A Case Study Analysis on \'S ikṣ \= a ṣṭaka
Sandhan, Jivnesh and Barbadikar, Amruta and Maity, Malay and Satuluri, Pavankumar and Sandhan, Tushar and Gupta, Ravi M and Goyal, Pawan and Behera, Laxmidhar. Aesthetics of S anskrit Poetry from the Perspective of Computational Linguistics: A Case Study Analysis on \'S ikṣ \= a ṣṭaka. Computational Sanskrit and Digital Humanities - World Sanskrit Confere...
2025
-
[47]
Itaretara Dvandva: A challenge for Dependency Tree semantics
Kulkarni, Amba and Neelamana, Vasudha. Itaretara Dvandva: A challenge for Dependency Tree semantics. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[48]
A Case Study of Handwritten Text Recognition from Pre-Colonial era S anskrit Manuscripts
Chincholikar, Kartik and Dwivedi, Shagun and Gopalan, Kaushik and Awasthi, Tarinee. A Case Study of Handwritten Text Recognition from Pre-Colonial era S anskrit Manuscripts. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[49]
Towards Accent-Aware V edic S anskrit Optical Character Recognition Based on Transformer Models
Tsukagoshi, Yuzuki and Kuroiwa, Ryo and Ohmukai, Ikki. Towards Accent-Aware V edic S anskrit Optical Character Recognition Based on Transformer Models. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[50]
Vedavani: A Benchmark Corpus for ASR on V edic S anskrit Poetry
Kumar, Sujeet and Ray, Pretam and Beerukuri, Abhinay and Kamoji, Shrey and Jagadeeshan, Manoj Balaji and Goyal, Pawan. Vedavani: A Benchmark Corpus for ASR on V edic S anskrit Poetry. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[51]
Compound Type Identification in S anskrit
Krishnan, Sriram and Satuluri, Pavankumar and Barbadikar, Amruta and Prasanna Venkatesh, T S and Kulkarni, Amba. Compound Type Identification in S anskrit. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[52]
IKML : A Markup Language for Collaborative Semantic Annotation of I ndic Texts
Lakkundi, Chaitanya S and Rajaraman, Gopalakrishnan and Susarla, Sai Rama Krishna. IKML : A Markup Language for Collaborative Semantic Annotation of I ndic Texts. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[53]
Challenges in Processing V edic S anskrit: Towards creating a normalized dataset for the Ṛgveda-saṃhit \= a
Krishnan, Sriram and Gayathri, Sepuri and Kulkarni, Amba. Challenges in Processing V edic S anskrit: Towards creating a normalized dataset for the Ṛgveda-saṃhit \= a. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[54]
P \= a ṇḍitya: Visualizing S anskrit Intellectual Networks
Neill, Tyler. P \= a ṇḍitya: Visualizing S anskrit Intellectual Networks. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[55]
Anveshana: A New Benchmark Dataset for Cross-Lingual Information Retrieval on E nglish Queries and S anskrit Documents
Jagadeeshan, Manoj Balaji and Raj, Prince and Goyal, Pawan. Anveshana: A New Benchmark Dataset for Cross-Lingual Information Retrieval on E nglish Queries and S anskrit Documents. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[56]
Concordance of S anskrit Synonyms
Patel, Dhaval. Concordance of S anskrit Synonyms. Computational Sanskrit and Digital Humanities - World Sanskrit Conference 2025. 2025
2025
-
[57]
Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[58]
Chain-of- M eta W riting: Linguistic and Textual Analysis of How Small Language Models Write Young Students Texts
Buhnila, Ioana and Cislaru, Georgeta and Todirascu, Amalia. Chain-of- M eta W riting: Linguistic and Textual Analysis of How Small Language Models Write Young Students Texts. Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[59]
Semantic Masking in a Needle-in-a-haystack Test for Evaluating Large Language Model Long-Text Capabilities
Shi, Ken and Penn, Gerald. Semantic Masking in a Needle-in-a-haystack Test for Evaluating Large Language Model Long-Text Capabilities. Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[60]
Reading Between the Lines: A dataset and a study on why some texts are tougher than others
Khallaf, Nouran and Eugeni, Carlo and Sharoff, Serge. Reading Between the Lines: A dataset and a study on why some texts are tougher than others. Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[61]
P ara R ev : Building a dataset for Scientific Paragraph Revision annotated with revision instruction
Jourdan, L \'e ane and Boudin, Florian and Dufour, Richard and Hernandez, Nicolas and Aizawa, Akiko. P ara R ev : Building a dataset for Scientific Paragraph Revision annotated with revision instruction. Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[62]
Towards an operative definition of creative writing: a preliminary assessment of creativeness in AI and human texts
Maggi, Chiara and Vitaletti, Andrea. Towards an operative definition of creative writing: a preliminary assessment of creativeness in AI and human texts. Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[63]
Decoding Semantic Representations in the Brain Under Language Stimuli with Large Language Models
Sato, Anna and Kobayashi, Ichiro. Decoding Semantic Representations in the Brain Under Language Stimuli with Large Language Models. Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[64]
Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[65]
A Comprehensive Taxonomy of Bias Mitigation Methods for Hate Speech Detection
Fillies, Jan and Wawerek, Marius and Paschke, Adrian. A Comprehensive Taxonomy of Bias Mitigation Methods for Hate Speech Detection. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[66]
Sensitive Content Classification in Social Media: A Holistic Resource and Evaluation
Antypas, Dimosthenis and Sen, Indira and Perez Almendros, Carla and Camacho-Collados, Jose and Barbieri, Francesco. Sensitive Content Classification in Social Media: A Holistic Resource and Evaluation. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[67]
From civility to parity: Marxist-feminist ethics for context-aware algorithmic content moderation
Oh, Dayei. From civility to parity: Marxist-feminist ethics for context-aware algorithmic content moderation. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[68]
A Novel Dataset for Classifying G erman Hate Speech Comments with Criminal Relevance
Kums, Vincent and Meyer, Florian and Pivit, Luisa and Vedenina, Uliana and Wortmann, Jonas and Siegel, Melanie and Labudde, Dirk. A Novel Dataset for Classifying G erman Hate Speech Comments with Criminal Relevance. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[69]
Learning from Disagreement: Entropy-Guided Few-Shot Selection for Toxic Language Detection
Caselli, Tommaso and Plaza-del-Arco, Flor Miriam. Learning from Disagreement: Entropy-Guided Few-Shot Selection for Toxic Language Detection. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[70]
Debiasing Static Embeddings for Hate Speech Detection
Sun, Ling and Kim, Soyoung and Dong, Xiao and K. Debiasing Static Embeddings for Hate Speech Detection. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[71]
Web(er) of Hate: A Survey on How Hate Speech Is Typed
Wang, Luna and Caines, Andrew and Hutchings, Alice. Web(er) of Hate: A Survey on How Hate Speech Is Typed. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[72]
Think Like a Person Before Responding: A Multi-Faceted Evaluation of Persona-Guided LLM s for Countering Hate Speech
Ngueajio, Mikel and Plaza-del-Arco, Flor Miriam and Chung, Yi-Ling and Rawat, Danda and Cercas Curry, Amanda. Think Like a Person Before Responding: A Multi-Faceted Evaluation of Persona-Guided LLM s for Countering Hate Speech. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[73]
HODIAT : A Dataset for Detecting Homotransphobic Hate Speech in I talian with Aggressiveness and Target Annotation
Damo, Greta and Cignarella, Alessandra Teresa and Caselli, Tommaso and Patti, Viviana and Nozza, Debora. HODIAT : A Dataset for Detecting Homotransphobic Hate Speech in I talian with Aggressiveness and Target Annotation. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[74]
Beyond the Binary: Analysing Transphobic Hate and Harassment Online
Talas, Anna and Hutchings, Alice. Beyond the Binary: Analysing Transphobic Hate and Harassment Online. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[75]
Evading Toxicity Detection with ASCII -art: A Benchmark of Spatial Attacks on Moderation Systems
Berezin, Sergey and Farahbakhsh, Reza and Crespi, Noel. Evading Toxicity Detection with ASCII -art: A Benchmark of Spatial Attacks on Moderation Systems. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[76]
Debunking with Dialogue? Exploring AI -Generated Counterspeech to Challenge Conspiracy Theories
Lisker, Mareike and Gottschalk, Christina and Mihaljevi \'c , Helena. Debunking with Dialogue? Exploring AI -Generated Counterspeech to Challenge Conspiracy Theories. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[77]
M isinfo T ele G raph: Network-driven Misinformation Detection for G erman Telegram Messages
Kalkbrenner, Lu and Solopova, Veronika and Zeiler, Steffen and Nickel, Robert and Kolossa, Dorothea. M isinfo T ele G raph: Network-driven Misinformation Detection for G erman Telegram Messages. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[78]
Catching Stray Balls: Football, fandom, and the impact on digital discourse
Hill, Mark. Catching Stray Balls: Football, fandom, and the impact on digital discourse. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[79]
e , Justina and Rimkien \
Mandravickait \. e , Justina and Rimkien \. e , Egl \. e and Petkevi c ius, Mindaugas and Songailait \. e , Milita and Zaranka, Eimantas and Krilavi c ius, Tomas. Exploring Hate Speech Detection Models for L ithuanian Language. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
-
[80]
RAG and Recall: Multilingual Hate Speech Detection with Semantic Memory
Mnassri, Khouloud and Farahbakhsh, Reza and Crespi, Noel. RAG and Recall: Multilingual Hate Speech Detection with Semantic Memory. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.