Recognition: unknown
Probably Approximately Consensus: On the Learning Theory of Finding Common Ground
Pith reviewed 2026-05-09 21:59 UTC · model grok-4.3
The pith
Consensus finding reduces to learning an interval in one-dimensional opinion space that maximizes expected agreement over an issue distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We model consensus as an interval in a one-dimensional opinion space derived from potentially high-dimensional data via embedding and dimensionality reduction. We define an objective that maximizes expected agreement within a hypothesis interval where the expectation is over an underlying distribution of issues, implicitly taking into account their salience. We propose an efficient Empirical Risk Minimization (ERM) algorithm and establish PAC-learning guarantees.
What carries the argument
The hypothesis interval in the embedded one-dimensional opinion space, selected to maximize expected agreement under the unknown issue distribution.
If this is right
- The ERM procedure efficiently identifies a high-agreement interval from a modest number of user ratings.
- PAC bounds ensure that the selected interval is probably close to the optimal one once sufficient samples are obtained.
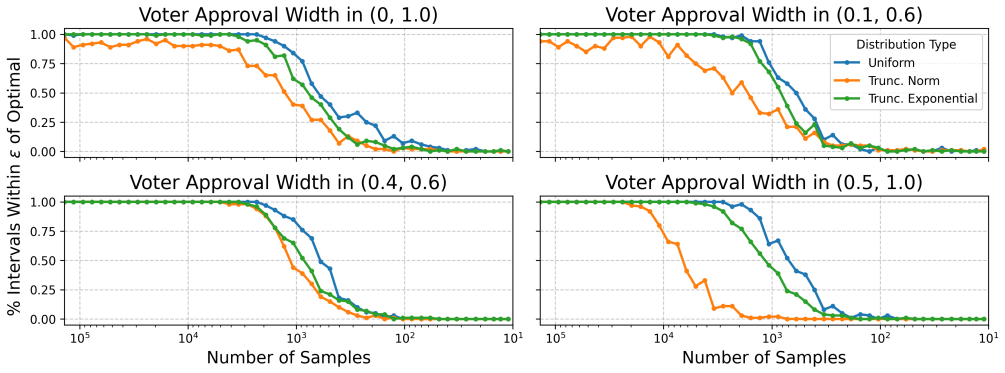
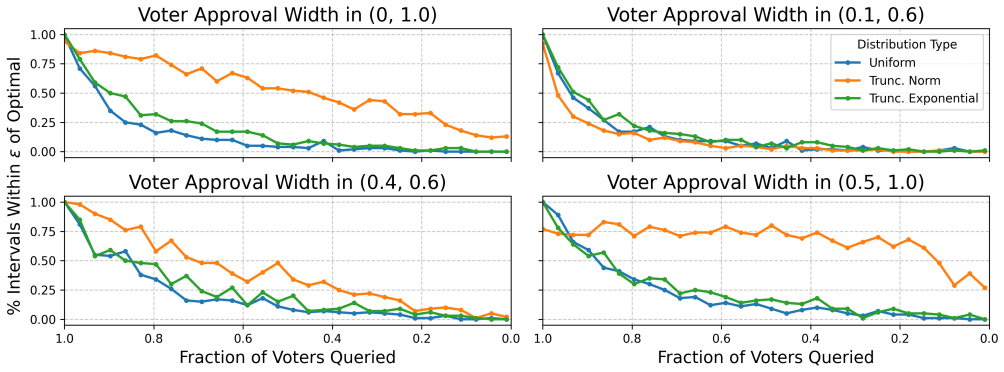
- Selective querying on an existing pool of statements reduces the total number of user responses needed to a practical level.
- The learned interval generalizes to new statements by averaging agreement under the implicit issue distribution.
Where Pith is reading between the lines
- If the embedding step can be made robust, the same interval-selection objective could be applied in higher-dimensional opinion spaces using balls or convex sets instead of intervals.
- The framework might combine with existing social-choice aggregation rules to produce consensus candidates that are both learnable and strategy-proof.
- Testing the method on large-scale real deliberation datasets would reveal whether the one-dimensional assumption holds sufficiently often to be useful in practice.
Load-bearing premise
High-dimensional user preferences can be embedded into a one-dimensional opinion space such that intervals in this space meaningfully capture consensus regions, and an underlying distribution over issues exists whose salience is captured by the expectation.
What would settle it
An experiment in which the interval recovered by the ERM algorithm shows low agreement on a fresh sample of issues drawn from the same distribution, or in which the one-dimensional embedding produces no interval that achieves high agreement on the observed preferences.
Figures


read the original abstract
A primary goal of online deliberation platforms is to identify ideas that are broadly agreeable to a community of users through their expressed preferences. Yet, consensus elicitation should ideally extend beyond the specific statements provided by users and should incorporate the relative salience of particular topics. We address this issue by modelling consensus as an interval in a one-dimensional opinion space derived from potentially high-dimensional data via embedding and dimensionality reduction. We define an objective that maximizes expected agreement within a hypothesis interval where the expectation is over an underlying distribution of issues, implicitly taking into account their salience. We propose an efficient Empirical Risk Minimization (ERM) algorithm and establish PAC-learning guarantees. Our initial experiments demonstrate the performance of our algorithm and examine more efficient approaches to identifying optimal consensus regions. We find that through selectively querying users on an existing sample of statements, we can reduce the number of queries needed to a practical number.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models consensus elicitation as selecting an interval in a one-dimensional opinion space obtained by embedding high-dimensional user preferences. It defines an objective that maximizes expected agreement within the interval, where the expectation is over an underlying (unobserved) distribution of issues to capture salience. An efficient ERM algorithm is proposed along with PAC-learning guarantees, and experiments examine performance and query reduction via selective user querying on statement samples.
Significance. If the PAC guarantees are rigorously established and the embedding plus distributional expectation meaningfully capture consensus, the work supplies a learning-theoretic foundation for generalization beyond observed statements in deliberation platforms. This could inform algorithm design for online consensus tools by linking embedding techniques with risk minimization.
major comments (2)
- [Objective definition and ERM section] The objective is defined with respect to an unobserved distribution D over issues (E_{issues ~ D}[agreement]), yet the ERM algorithm and PAC bounds are derived from a finite sample of user statements on specific issues. No estimator, generative model, or sampling procedure for D is provided, so it is unclear whether the empirical objective converges to the population objective or whether the PAC bounds apply to the actual data-generating process.
- [Theory and guarantees] The abstract asserts PAC guarantees and an efficient ERM algorithm, but the provided text contains no proof sketches, explicit assumptions on the embedding map, or details on how the 1D interval hypothesis class interacts with the unobserved D. This makes it impossible to verify whether the bounds are non-vacuous or account for the dimensionality reduction step.
minor comments (2)
- [Experiments] The experiments section would benefit from explicit description of the embedding and dimensionality reduction technique used to obtain the 1D opinion space, including any hyperparameters.
- [Model] Notation for the hypothesis interval and agreement function should be introduced with a clear table or definition block to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We have revised the manuscript to address the concerns about the relationship between the unobserved distribution D and the ERM procedure, as well as to include explicit assumptions, proof sketches, and details on the hypothesis class. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Objective definition and ERM section] The objective is defined with respect to an unobserved distribution D over issues (E_{issues ~ D}[agreement]), yet the ERM algorithm and PAC bounds are derived from a finite sample of user statements on specific issues. No estimator, generative model, or sampling procedure for D is provided, so it is unclear whether the empirical objective converges to the population objective or whether the PAC bounds apply to the actual data-generating process.
Authors: We agree that the connection was insufficiently explicit. The finite sample of statements is drawn i.i.d. from D; the ERM computes the empirical average agreement over this sample, which is the standard unbiased estimator of the population objective. Under i.i.d. sampling, the law of large numbers ensures convergence, and uniform convergence over the interval hypothesis class (VC-dimension 2) yields the PAC bounds via standard arguments. We have added an explicit subsection on the sampling model for D, the estimator, and a short convergence proof sketch. revision: yes
-
Referee: [Theory and guarantees] The abstract asserts PAC guarantees and an efficient ERM algorithm, but the provided text contains no proof sketches, explicit assumptions on the embedding map, or details on how the 1D interval hypothesis class interacts with the unobserved D. This makes it impossible to verify whether the bounds are non-vacuous or account for the dimensionality reduction step.
Authors: We acknowledge the main text omitted these details. The hypothesis class consists of intervals on the embedded 1D line (VC-dimension 2), so PAC learnability follows from standard results once the risk is defined as expectation over D. The embedding is a fixed preprocessing map; we now state the assumption that it approximately preserves agreement structure (e.g., via bounded distortion). The interaction with D occurs directly in the risk functional. We have inserted a dedicated theory subsection with assumptions, a proof sketch, and discussion of sample complexity; full proofs remain in the appendix. Concrete sample-size examples are added to illustrate non-vacuousness. revision: yes
Circularity Check
No significant circularity; standard ERM and PAC on externally defined objective
full rationale
The paper defines its consensus objective explicitly as maximization of expected agreement E_{issues ~ D}[agreement on interval] where D is an underlying distribution over issues. It then applies the standard Empirical Risk Minimization procedure to approximate this population objective from finite samples and invokes generic PAC-learning bounds. No derivation step equates the claimed guarantee or optimal interval to a fitted parameter by construction, nor does any load-bearing premise reduce to a self-citation or ansatz imported from the authors' prior work. The framework remains self-contained against external learning-theoretic results and the stated embedding assumption; concerns about whether the observed statement samples are drawn from the posited D pertain to model validity rather than circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User preferences embed meaningfully into a 1D opinion space via dimensionality reduction such that intervals represent consensus.
Reference graph
Works this paper leans on
-
[1]
Approx- imating optimal social choice under metric preferences
[Anshelevichet al., 2018 ] Elliot Anshelevich, Onkar Bhard- waj, Edith Elkind, John Postl, and Piotr Skowron. Approx- imating optimal social choice under metric preferences. Artificial Intelligence, 264:27–51,
2018
-
[2]
Cambridge University Press,
[Anthony and Bartlett, 2009] Martin Anthony and Peter L Bartlett.Neural network learning: Theoretical founda- tions. Cambridge University Press,
2009
-
[3]
Programming pearls: algo- rithm design techniques.Communications of the ACM, 27(9):865–873,
[Bentley, 1984] Jon Bentley. Programming pearls: algo- rithm design techniques.Communications of the ACM, 27(9):865–873,
1984
-
[4]
Aggregation over metric spaces: Proposing and voting in elections, budgeting, and legislation.Journal of Artificial Intelligence Research, 70:1413–1439,
[Bulteauet al., 2021 ] Laurent Bulteau, Gal Shahaf, Ehud Shapiro, and Nimrod Talmon. Aggregation over metric spaces: Proposing and voting in elections, budgeting, and legislation.Journal of Artificial Intelligence Research, 70:1413–1439,
2021
-
[5]
United for change: deliber- ative coalition formation to change the status quo.Social Choice and Welfare, 63(3):717–746,
[Elkindet al., 2024 ] Edith Elkind, Davide Grossi, Ehud Shapiro, and Nimrod Talmon. United for change: deliber- ative coalition formation to change the status quo.Social Choice and Welfare, 63(3):717–746,
2024
-
[6]
Representation with incomplete votes
[Halpernet al., 2023 ] Daniel Halpern, Gregory Kehne, Ariel D Procaccia, Jamie Tucker-Foltz, and Manuel W¨uthrich. Representation with incomplete votes. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5657–5664,
2023
-
[7]
rlhf: Scaling reinforcement learning from human feedback with ai feedback , author=
[Leeet al., 2023 ] Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Ras- togi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback.arXiv preprint arXiv:2309.00267,
-
[8]
Cambridge University Press,
[Merrill and Grofman, 1999] Samuel Merrill and Bernard Grofman.A unified theory of voting: Directional and prox- imity spatial models. Cambridge University Press,
1999
-
[9]
Representative social choice: From learning theory to ai alignment.arXiv preprint arXiv:2410.23953,
[Qiu, 2024] Tianyi Qiu. Representative social choice: From learning theory to ai alignment.arXiv preprint arXiv:2410.23953,
-
[10]
Polis: Scaling deliberation by mapping high dimensional opin- ion spaces.Recerca: revista de pensament i an `alisi, 26(2),
[Smallet al., 2021 ] Christopher Small, Michael Bjorkegren, Timo Erkkil ¨a, Lynette Shaw, and Colin Megill. Polis: Scaling deliberation by mapping high dimensional opin- ion spaces.Recerca: revista de pensament i an `alisi, 26(2),
2021
-
[11]
Thus, no set of 3 points can be pseudo-shattered byG, which impliesP dim(G)<3, and thereforeP dim(G)≤2
This means that for any set of 3 pointsx 1 < x 2 < x 3 and any set of thresholds r1, r2, r3, there is at least one binary pattern in{0,1} 3 that cannot be generated byG. Thus, no set of 3 points can be pseudo-shattered byG, which impliesP dim(G)<3, and thereforeP dim(G)≤2. Conclusion:SinceP dim(G)≥2andP dim(G)≤2, we conclude thatP dim(G) = 2, providedl(x)...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.