Recognition: unknown
Universal Transformers Need Memory: Depth-State Trade-offs in Adaptive Recursive Reasoning
Pith reviewed 2026-05-09 22:42 UTC · model grok-4.3
The pith
Universal Transformers require memory tokens to achieve non-trivial performance on combinatorial reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Learned memory tokens serve as an explicit computational scratchpad that a single-block Universal Transformer with Adaptive Computation Time needs to solve Sudoku-Extreme. Configurations lacking these tokens fail to reach non-trivial accuracy, while counts from eight to thirty-two tokens deliver consistent 57.4 percent exact-match performance and permit the model to reduce its mean halt steps from 11.6 down to 8.3 as memory size grows. This establishes a direct trade-off between state capacity and recursion depth at constant accuracy, and it requires inverting the router bias to a deep-start value to avoid the shallow-halt trap inherent to Adaptive Computation Time training.
What carries the argument
Learned memory tokens used as a scratchpad that trades off against ponder depth inside Adaptive Computation Time halting.
Load-bearing premise
The observed necessity of memory tokens and their substitution for depth are not artifacts of the Sudoku-Extreme benchmark or the single-block Universal Transformer architecture.
What would settle it
A run of the same architecture on Sudoku-Extreme that reaches high accuracy with zero memory tokens, or one in which increasing memory size fails to reduce mean halt steps at matched accuracy.
Figures








read the original abstract
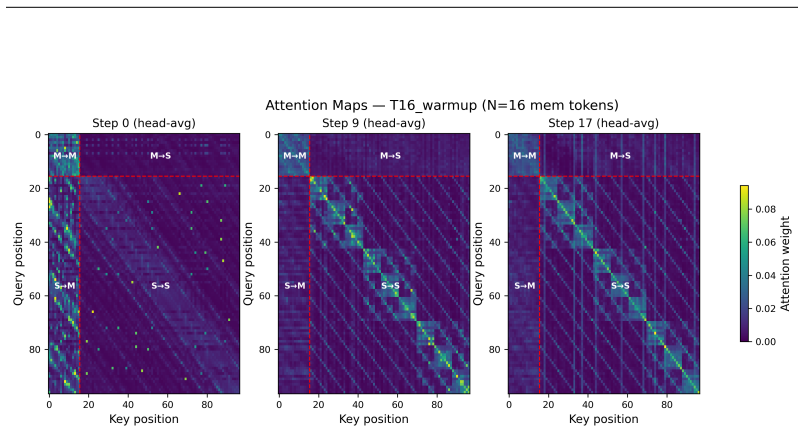
We study learned memory tokens as a computational scratchpad for a single-block Universal Transformer with Adaptive Computation Time (ACT) on Sudoku-Extreme, a combinatorial reasoning benchmark. Memory tokens are empirically necessary: no configuration without them reaches non-trivial performance. The optimal count has a sharp lower threshold (T=0 always fails, T=8 reliably succeeds) followed by a stable plateau (T=8-32, 57.4% +/- 0.7% exact-match) and a dilution boundary at T=64. Under halt-side pressure (lambda warmup), mean halt drops monotonically with memory size across the plateau (from 11.6 at T=8 to 8.3 at T=64), showing that memory tokens and ponder depth substitute as resources at fixed accuracy. We also identify a router initialization trap that causes the majority of training runs to fail: both default zero-bias and Graves' recommended positive bias settle into a shallow halt equilibrium the model cannot escape. Inverting the bias to -3 ("deep start") eliminates the failure mode, and ablation shows the trap is inherent to ACT initialization rather than an artifact of our architecture. With reliable training, ACT yields an order of magnitude lower seed variance than fixed-depth processing (+/-0.7 vs +/-9.3 pp); lambda warmup recovers 34% of compute at matched accuracy; and attention heads specialize into memory readers, constraint propagators, and integrators across recursive depth. Code: https://github.com/che-shr-cat/utm-jax.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically studies learned memory tokens as a scratchpad in a single-block Universal Transformer with Adaptive Computation Time (ACT) on the Sudoku-Extreme combinatorial reasoning benchmark. It claims memory tokens are necessary for non-trivial performance (T=0 always fails), with a sharp threshold at T=8, a stable plateau at T=8-32 yielding 57.4% +/- 0.7% exact-match accuracy, and dilution beyond T=64; under lambda warmup, mean halt steps decrease monotonically with memory size, indicating depth-state substitution. It also identifies a router bias initialization trap (default/positive biases fail, -3 succeeds), reports lower seed variance with ACT, 34% compute recovery via warmup, and attention head specialization.
Significance. If the central empirical results hold under fuller controls, the work usefully demonstrates that explicit memory tokens and ponder depth can trade off as resources in adaptive recursive reasoning, with practical guidance on ACT initialization and evidence of head specialization. The open-sourced code is a clear strength for reproducibility. The findings are specific to one benchmark and architecture but provide falsifiable observations on resource substitution that could inform broader transformer design.
major comments (2)
- [Abstract / Experimental results on memory token counts] Abstract and experimental results on memory token counts: the sharp lower threshold (T=8 succeeds, T=0 fails) and stable plateau (T=8-32 at 57.4% +/- 0.7%) are presented as key findings, but the range selection is post-hoc without pre-specified criteria, full reporting of all tested T values, or statistical tests for stability and the dilution boundary at T=64. This is load-bearing for the necessity and trade-off claims.
- [Router initialization and halt-side pressure experiments] Router bias initialization and lambda warmup experiments: the inversion to bias=-3 is shown via ablation to eliminate the shallow halt trap, but the manuscript provides no systematic search or sensitivity analysis around this specific value (a free parameter), nor confirms the depth-state substitution holds independently of the warmup schedule. This affects the reliability of the reported trade-off and training success.
minor comments (2)
- [Abstract / Results] The variance reduction claim (+/-0.7 vs +/-9.3 pp) and 34% compute recovery are stated numerically but should be explicitly tied to a table or figure for verification.
- Clarify the exact definition of 'compute' recovered by lambda warmup and the metric for 'exact-match' accuracy to aid replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where we agree that additional reporting or experiments are warranted and outlining the specific revisions we will incorporate.
read point-by-point responses
-
Referee: Abstract and experimental results on memory token counts: the sharp lower threshold (T=8 succeeds, T=0 fails) and stable plateau (T=8-32 at 57.4% +/- 0.7%) are presented as key findings, but the range selection is post-hoc without pre-specified criteria, full reporting of all tested T values, or statistical tests for stability and the dilution boundary at T=64. This is load-bearing for the necessity and trade-off claims.
Authors: We agree that fuller reporting of the memory token experiments would improve transparency and strengthen the claims. The manuscript highlighted results for T=0, 8, 16, 32, and 64 as representative of the observed threshold, plateau, and dilution effects, but did not include the complete set of tested values or formal statistical comparisons. In the revised manuscript we will add a dedicated table reporting exact-match accuracy (mean and standard deviation across seeds) for all T values we evaluated (including 1, 2, 4, 16, 64, and 128). We will also include a brief description of the exploratory process used to select the reported range and apply simple statistical tests (pairwise t-tests with correction) to quantify the significance of the threshold at T=8 and the stability of the T=8–32 plateau relative to the drop at T=64. These additions directly address the post-hoc concern while preserving the original empirical observations. revision: yes
-
Referee: Router bias initialization and lambda warmup experiments: the inversion to bias=-3 is shown via ablation to eliminate the shallow halt trap, but the manuscript provides no systematic search or sensitivity analysis around this specific value (a free parameter), nor confirms the depth-state substitution holds independently of the warmup schedule. This affects the reliability of the reported trade-off and training success.
Authors: The referee correctly identifies that the manuscript demonstrates the effectiveness of bias=-3 via a limited ablation but does not provide a broader sensitivity analysis or isolate the depth-state substitution from the lambda warmup schedule. In the revision we will expand the router-bias section with a sensitivity sweep over initial bias values from -5 to +1 (in integer steps), reporting both training success rate and final accuracy for each setting. We will also add a control experiment that trains with a fixed (non-warmup) lambda schedule and replots mean halt steps versus memory size; this will confirm whether the observed monotonic substitution between memory tokens and ponder depth persists without the warmup schedule. These results will be presented in the revised experimental section. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential fits
full rationale
The paper reports experimental results on memory tokens, ACT halt behavior, and depth-state trade-offs using direct training runs, ablations, and accuracy measurements on Sudoku-Extreme. All key findings (necessity of T>=8, monotonic halt reduction, initialization trap) are obtained from observed data rather than any model equation, fitted parameter, or self-citation chain. No load-bearing step reduces to its own inputs by construction, and external citations (e.g., Graves) are not used to justify uniqueness or ansatzes. The work is self-contained as an empirical study.
Axiom & Free-Parameter Ledger
free parameters (3)
- memory token count T
- router bias initialization
- lambda warmup schedule
axioms (1)
- domain assumption Sudoku-Extreme requires recursive constraint propagation that benefits from external scratchpad state
Reference graph
Works this paper leans on
-
[1]
A. Banino, J. Balaguer, and C. Blundell. PonderNet: Learning to Ponder. arXiv:2107.05407, 2021. https://arxiv.org/abs/2107.05407
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , year =
A. Bulatov, Y. Kuratov, and M. Burtsev. Recurrent Memory Transformer. In NeurIPS, 2022. https://arxiv.org/abs/2207.06881
-
[3]
arXiv preprint arXiv:2006.11527 , year=
M. Burtsev et al. Memory Transformer. arXiv:2006.11527, 2020. https://arxiv.org/abs/2006.11527
-
[4]
Csord \'a s, K
R. Csord \'a s, K. Irie, and J. Schmidhuber. The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers. In EMNLP, 2021. https://aclanthology.org/2021.emnlp-main.49/
2021
-
[5]
Darcet et al
T. Darcet et al. Vision Transformers Need Registers. In ICLR, 2024. https://openreview.net/forum?id=2dnO3LLiJ1
2024
-
[6]
M. Dehghani et al. Universal Transformers. In ICLR, 2019. https://arxiv.org/abs/1807.03819
work page internal anchor Pith review arXiv 2019
-
[7]
A. Graves. Adaptive Computation Time for Recurrent Neural Networks. arXiv:1603.08983, 2016. https://arxiv.org/abs/1603.08983
work page internal anchor Pith review arXiv 2016
-
[8]
URL https: //arxiv.org/abs/2510.04871
A. Jolicoeur-Martineau. Less is More: Recursive Reasoning with Tiny Networks. arXiv:2510.04871, 2025. https://arxiv.org/abs/2510.04871
-
[9]
K. Jordan. Muon: An optimizer for hidden layers. https://kellerjordan.github.io/posts/muon/, 2024
2024
-
[10]
Reasoning with latent thoughts: On the power of looped transformers
N. Saunshi et al. Reasoning with Latent Thoughts: On the Power of Looped Transformers. arXiv:2502.17416, 2025. https://arxiv.org/abs/2502.17416
-
[11]
Sudoku-Extreme Dataset
Sapient Intelligence . Sudoku-Extreme Dataset. https://huggingface.co/datasets/sapientinc/sudoku-extreme, 2025
2025
- [12]
- [13]
- [14]
- [15]
-
[16]
Titans: Learning to Memorize at Test Time
A. Behrouz, P. Zhong, and V. Mirrokni. Titans: Learning to Memorize at Test Time. arXiv:2501.00663, 2025. https://arxiv.org/abs/2501.00663
work page internal anchor Pith review arXiv 2025
- [17]
-
[18]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
J. Geiping, S. McLeish, N. Jain, J. Kirchenbauer, S. Singh, B. R. Bartoldson, B. Kailkhura, A. Bhatele, and T. Goldstein. Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach. arXiv:2502.05171, 2025. https://arxiv.org/abs/2502.05171
work page internal anchor Pith review arXiv 2025
-
[19]
A. Graves, G. Wayne, and I. Danihelka. Neural Turing Machines. arXiv:1410.5401, 2014. https://arxiv.org/abs/1410.5401
work page internal anchor Pith review arXiv 2014
-
[20]
Graves, G
A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwi \'n ska, S. G. Colmenarejo, E. Grefenstette, T. Ramalho, J. Agapiou, et al. Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626):471--476, 2016. https://www.nature.com/articles/nature20101
2016
-
[21]
Leave no context behind: Efficient infinite context transformers with infini-attention
T. Munkhdalai, M. Faruqui, and S. Gopal. Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention. arXiv:2404.07143, 2024. https://arxiv.org/abs/2404.07143
- [22]
-
[23]
C. Yu, X. Shu, Y. Wang, Y. Zhang, H. Wu, J. Li, R. Long, Z. Chen, Y. Xu, W. Su, and B. Zheng. MeSH: Memory-as-State-Highways for Recursive Transformers. arXiv:2510.07739, 2026. https://arxiv.org/abs/2510.07739
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [24]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.