Recognition: unknown
H-Sets: Hessian-Guided Discovery of Set-Level Feature Interactions in Image Classifiers
Pith reviewed 2026-05-09 21:27 UTC · model grok-4.3
The pith
H-Sets detects locally interacting pixel pairs with Hessians then merges them into sets for set-level attribution in image classifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Input Hessians identify locally interacting feature pairs that can be recursively merged into semantically coherent sets; these sets are then attributed by IDG-Vis, a set-level extension of integrated directional gradients that aggregates directional gradients along pixel-space paths and distributes credit via Harsanyi dividends, yielding saliency maps that are sparser and more faithful to model behavior than those produced by marginal or superpixel-only methods.
What carries the argument
H-Sets two-stage pipeline: Hessian detection of local interaction pairs followed by recursive merging into sets and IDG-Vis attribution that uses Harsanyi dividends to account for internal interactions.
Load-bearing premise
That pairs detected locally by the Hessian can be merged recursively into coherent sets without introducing artifacts or overlooking higher-order interactions, and that the segmentation map acts as a neutral spatial prior.
What would settle it
Compare faithfulness metrics of H-Sets against the same pipeline that substitutes random pairs for Hessian-detected pairs on the same models and datasets; a large drop in faithfulness would show the Hessian step is not doing the claimed work.
Figures








read the original abstract
Feature attribution methods explain the predictions of deep neural networks by assigning importance scores to individual input features. However, most existing methods focus solely on marginal effects, overlooking feature interactions, where groups of features jointly influence model output. Such interactions are especially important in image classification tasks, where semantic meaning often arises from pixel interdependencies rather than isolated features. Existing interaction-based methods for images are either coarse (e.g., superpixel-only) or, fail to satisfy core interpretability axioms. In this work, we introduce H-Sets, a novel two-stage framework for discovering and attributing higher-order feature interactions in image classifiers. First, we detect locally interacting pairs via input Hessians and recursively merge them into semantically coherent sets; segmentation from Segment Anything (SAM) is used as a spatial grouping prior but can be replaced by other segmentations. Second, we attribute each set with IDG-Vis, a set-level extension of Integrated Directional Gradients that integrates directional gradients along pixel-space paths and aggregates them with Harsanyi dividends. While Hessians introduce additional compute at the detection stage, this targeted cost consistently yields saliency maps that are sparser and more faithful. Evaluations across VGG, ResNet, DenseNet and MobileNet models on ImageNet and CUB datasets show that H-Sets generate more interpretable and faithful saliency maps compared to existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces H-Sets, a two-stage framework for set-level feature interaction discovery and attribution in image classifiers. Stage 1 detects locally interacting feature pairs via input Hessians and recursively merges them into semantically coherent sets, using Segment Anything (SAM) segmentation as an optional spatial prior. Stage 2 attributes each discovered set using IDG-Vis, an extension of Integrated Directional Gradients that integrates directional gradients along pixel-space paths and aggregates contributions via Harsanyi dividends. The central claim is that this produces sparser, more interpretable, and more faithful saliency maps than existing marginal or interaction-based methods, supported by evaluations on VGG, ResNet, DenseNet, and MobileNet models using ImageNet and CUB datasets.
Significance. If the empirical claims are substantiated with concrete metrics and controls, the work would advance feature attribution by explicitly handling higher-order interactions rather than marginal effects, using a Hessian-guided detection step combined with Harsanyi aggregation. The flexibility to replace SAM with other segmentations and the targeted use of Hessians (despite added compute) are constructive design choices. The combination of prior concepts (Hessians, IDG, Harsanyi dividends) into a set-level pipeline is a clear novelty, though its impact depends on demonstrating that the merged sets reflect genuine joint effects rather than pipeline artifacts.
major comments (3)
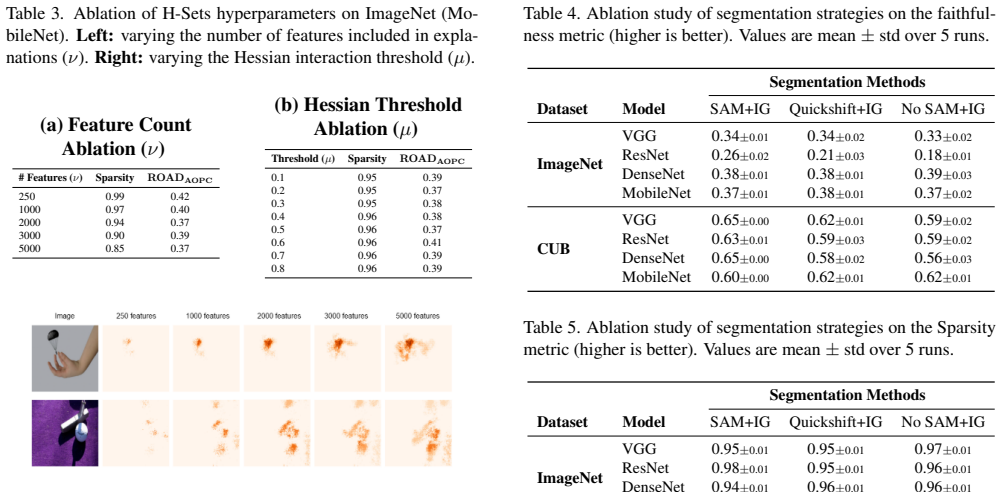
- [Abstract] Abstract: The assertion that 'evaluations across VGG, ResNet, DenseNet and MobileNet models on ImageNet and CUB datasets show that H-Sets generate more interpretable and faithful saliency maps' provides no concrete faithfulness metrics (e.g., insertion/deletion AUC, faithfulness scores), statistical tests, baseline details, or ablation results on the recursive merging step or SAM prior. This absence is load-bearing for the central claim of superiority.
- [Method (two-stage framework)] Method description (two-stage framework): The recursive merging of Hessian-detected pairwise interactions into sets is presented without explicit validation that the resulting sets capture true higher-order effects rather than artifacts from the merging heuristic or SAM's object-centric bias. No controls (e.g., alternative merging rules, random priors, or higher-order Hessian terms) are referenced, which directly affects the faithfulness of the attributed sets.
- [IDG-Vis attribution] IDG-Vis attribution step: It is unclear whether the set-level extension of Integrated Directional Gradients with Harsanyi dividends introduces fitted parameters or reduces to prior quantities by construction; the abstract does not specify the exact aggregation formula or any new axioms satisfied, making it difficult to assess whether the method genuinely extends beyond existing interaction measures.
minor comments (2)
- [Abstract] The abstract states that 'Hessians introduce additional compute at the detection stage' but does not quantify the overhead relative to baselines or discuss efficiency trade-offs in the evaluations section.
- [Introduction/Method] Notation for 'H-Sets' and 'IDG-Vis' is introduced without a clear forward reference to their formal definitions or pseudocode in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'evaluations across VGG, ResNet, DenseNet and MobileNet models on ImageNet and CUB datasets show that H-Sets generate more interpretable and faithful saliency maps' provides no concrete faithfulness metrics (e.g., insertion/deletion AUC, faithfulness scores), statistical tests, baseline details, or ablation results on the recursive merging step or SAM prior. This absence is load-bearing for the central claim of superiority.
Authors: We agree that the abstract would be strengthened by including concrete metrics. The full manuscript reports insertion/deletion AUC, faithfulness scores, statistical comparisons, and baseline details across the listed models and datasets. Ablation results on recursive merging and the SAM prior appear in the experiments section. We will revise the abstract to reference these specific quantitative results and ablations. revision: yes
-
Referee: [Method (two-stage framework)] Method description (two-stage framework): The recursive merging of Hessian-detected pairwise interactions into sets is presented without explicit validation that the resulting sets capture true higher-order effects rather than artifacts from the merging heuristic or SAM's object-centric bias. No controls (e.g., alternative merging rules, random priors, or higher-order Hessian terms) are referenced, which directly affects the faithfulness of the attributed sets.
Authors: We acknowledge this limitation in the current validation. The manuscript shows improved faithfulness and semantic coherence via qualitative and quantitative results, but does not include explicit controls such as random merging rules or non-SAM priors. We will add these control experiments in the revised version, along with discussion of how the Hessian-guided process approximates higher-order effects. revision: yes
-
Referee: [IDG-Vis attribution] IDG-Vis attribution step: It is unclear whether the set-level extension of Integrated Directional Gradients with Harsanyi dividends introduces fitted parameters or reduces to prior quantities by construction; the abstract does not specify the exact aggregation formula or any new axioms satisfied, making it difficult to assess whether the method genuinely extends beyond existing interaction measures.
Authors: IDG-Vis introduces no fitted parameters. It extends Integrated Directional Gradients by integrating directional gradients over pixel-space paths for sets and aggregates contributions via the Harsanyi dividend formula (detailed in Equation 3 of the manuscript). This satisfies standard axioms including efficiency and symmetry without reducing to marginal attributions. We will update the abstract to briefly state the aggregation formula and the axioms preserved. revision: yes
Circularity Check
No significant circularity; method extends established concepts without reduction to inputs
full rationale
The paper introduces H-Sets as a two-stage pipeline: Hessian-based detection of pairwise interactions followed by recursive merging into sets (with optional SAM prior), then attribution via IDG-Vis (an extension of Integrated Directional Gradients) aggregated by Harsanyi dividends. These build on independently established prior work (Hessians, game-theoretic dividends, path-integrated gradients) without any equation or step that defines the output sets or saliency scores as equivalent to the input Hessians or fitted parameters by construction. No self-citation chain is load-bearing for the core claims, and the faithfulness evaluations on VGG/ResNet/etc. across ImageNet/CUB are presented as external empirical checks rather than tautological consequences of the method definition. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Input Hessians reliably identify locally interacting feature pairs in image classifiers
- domain assumption Recursive merging of pairs produces semantically coherent sets suitable for attribution
invented entities (2)
-
H-Sets framework
no independent evidence
-
IDG-Vis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one, 10 (7):e0130140, 2015
Sebastian Bach, Alexander Binder, Gr ´egoire Montavon, Frederick Klauschen, Klaus-Robert M ¨uller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one, 10 (7):e0130140, 2015. 6
2015
-
[2]
Evaluating and aggregating feature-based model explanations
Umang Bhatt, Adrian Weller, and Jos ´e MF Moura. Evaluat- ing and aggregating feature-based model explanations.arXiv preprint arXiv:2005.00631, 2020. 7
-
[3]
Sok: Modeling explainabil- ity in security analytics for interpretability, trustworthiness, and usability
Dipkamal Bhusal, Rosalyn Shin, Ajay Ashok Shewale, Mon- ish Kumar Manikya Veerabhadran, Michael Clifford, Sara Rampazzi, and Nidhi Rastogi. Sok: Modeling explainabil- ity in security analytics for interpretability, trustworthiness, and usability. InProceedings of the 18th International Con- ference on Availability, Reliability and Security, pages 1–12,
-
[4]
Face: Faithful automatic concept extraction
Dipkamal Bhusal, Michael Clifford, Sara Rampazzi, and Nidhi Rastogi. Face: Faithful automatic concept extraction. NeurIPS, 2025. 2
2025
-
[5]
Preddiff: Explanations and interactions from conditional ex- pectations.Artificial Intelligence, 312:103774, 2022
Stefan Bl ¨ucher, Johanna Vielhaben, and Nils Strodthoff. Preddiff: Explanations and interactions from conditional ex- pectations.Artificial Intelligence, 312:103774, 2022. 2
2022
-
[6]
Concise explanations of neural net- works using adversarial training
Prasad Chalasani, Jiefeng Chen, Amrita Roy Chowdhury, Xi Wu, and Somesh Jha. Concise explanations of neural net- works using adversarial training. InInternational Confer- ence on Machine Learning, pages 1383–1391. PMLR, 2020. 5, 6
2020
-
[7]
On hars]anyi dividends and asymmetric val- ues.International Game Theory Review, 19(03):1750012,
Pierre Dehez. On hars]anyi dividends and asymmetric val- ues.International Game Theory Review, 19(03):1750012,
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 2, 5
2009
-
[9]
Improving performance of deep learning models with axiomatic attribution priors and ex- pected gradients.Nature machine intelligence, 3(7):620– 631, 2021
Gabriel Erion, Joseph D Janizek, Pascal Sturmfels, Scott M Lundberg, and Su-In Lee. Improving performance of deep learning models with axiomatic attribution priors and ex- pected gradients.Nature machine intelligence, 3(7):620– 631, 2021. 4, 2
2021
-
[10]
Craft: Concept recursive activation factoriza- tion for explainability
Thomas Fel, Agustin Picard, Louis Bethune, Thibaut Boissin, David Vigouroux, Julien Colin, R ´emi Cad`ene, and Thomas Serre. Craft: Concept recursive activation factoriza- tion for explainability. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 2711–2721, 2023. 2
2023
-
[11]
Un- derstanding deep networks via extremal perturbations and smooth masks
Ruth Fong, Mandela Patrick, and Andrea Vedaldi. Un- derstanding deep networks via extremal perturbations and smooth masks. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 2950–2958,
-
[12]
Interpretable explana- tions of black boxes by meaningful perturbation
Ruth C Fong and Andrea Vedaldi. Interpretable explana- tions of black boxes by meaningful perturbation. InPro- ceedings of the IEEE international conference on computer vision, pages 3429–3437, 2017. 1, 2
2017
-
[13]
Predictive learn- ing via rule ensembles
Jerome H Friedman and Bogdan E Popescu. Predictive learn- ing via rule ensembles. 2008. 3
2008
-
[14]
Towards automatic concept-based explanations.Ad- vances in neural information processing systems, 32, 2019
Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept-based explanations.Ad- vances in neural information processing systems, 32, 2019. 1, 2
2019
-
[15]
A simplified bar- gaining model for the n-person cooperative game.Papers in game theory, pages 44–70, 1982
John C Harsanyi and John C Harsanyi. A simplified bar- gaining model for the n-person cooperative game.Papers in game theory, pages 44–70, 1982. 4
1982
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2, 5, 7
2016
-
[17]
Anna Hedstr ¨om, Leander Weber, Daniel Krakowczyk, Dil- yara Bareeva, Franz Motzkus, Wojciech Samek, Sebastian Lapuschkin, and Marina Marina M.-C. H ¨ohne. Quantus: An explainable ai toolkit for responsible evaluation of neu- ral network explanations and beyond.Journal of Machine Learning Research, 24(34):1–11, 2023. 6
2023
-
[18]
A benchmark for interpretability methods in deep neural networks.Advances in Neural Information Process- ing Systems, 32, 2019
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. A benchmark for interpretability methods in deep neural networks.Advances in Neural Information Process- ing Systems, 32, 2019. 6
2019
-
[19]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard. Mobilenets: Efficient convolutional neu- ral networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017. 2, 5
work page internal anchor Pith review arXiv 2017
-
[20]
Densely connected convolutional net- works
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kil- ian Q Weinberger. Densely connected convolutional net- works. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017. 2, 5
2017
-
[21]
Explain- ing explanations: Axiomatic feature interactions for deep networks.Journal of Machine Learning Research, 22(104): 1–54, 2021
Joseph D Janizek, Pascal Sturmfels, and Su-In Lee. Explain- ing explanations: Axiomatic feature interactions for deep networks.Journal of Machine Learning Research, 22(104): 1–54, 2021. 2, 3, 4
2021
-
[22]
Learning to under- stand: Identifying interactions via the m ¨obius transform
Justin Kang, Yigit Efe Erginbas, Landon Butler, Ramtin Pedarsani, and Kannan Ramchandran. Learning to under- stand: Identifying interactions via the m ¨obius transform. Advances in Neural Information Processing Systems, 37: 46160–46202, 2024. 2
2024
-
[23]
Guided integrated gradients: An adaptive path method for remov- ing noise
Andrei Kapishnikov, Subhashini Venugopalan, Besim Avci, Ben Wedin, Michael Terry, and Tolga Bolukbasi. Guided integrated gradients: An adaptive path method for remov- ing noise. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5050–5058,
-
[24]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 4015–4026, 2023. 1, 2, 4, 7
2023
-
[25]
Captum: A unified and generic model interpretability library for pytorch, 2020
Narine Kokhlikyan, Vivek Miglani, Miguel Martin, Edward Wang, Bilal Alsallakh, Jonathan Reynolds, Alexander Mel- nikov, Natalia Kliushkina, Carlos Araya, Siqi Yan, and Orion Reblitz-Richardson. Captum: A unified and generic model interpretability library for pytorch, 2020. 5 9
2020
-
[26]
Segment anything in medical images.Nature Communications, 15(1):654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature Communications, 15(1):654, 2024. 1
2024
-
[27]
Rise: Randomized input sampling for explanation of black- box models,
V Petsiuk. Rise: Randomized input sampling for explana- tion of black-box models.arXiv preprint arXiv:1806.07421,
-
[28]
RISE: random- ized input sampling for explanation of black-box models
Vitali Petsiuk, Abir Das, and Kate Saenko. RISE: random- ized input sampling for explanation of black-box models. In British Machine Vision Conference 2018, BMVC 2018, New- castle, UK, September 3-6, 2018, page 151. BMV A Press,
2018
-
[29]
” why should i trust you?” explaining the predictions of any classifier
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. ” why should i trust you?” explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD interna- tional conference on knowledge discovery and data mining, pages 1135–1144, 2016. 1, 2
2016
-
[30]
Yao Rong, Tobias Leemann, Vadim Borisov, Gjergji Kas- neci, and Enkelejda Kasneci. A consistent and efficient evaluation strategy for attribution methods.arXiv preprint arXiv:2202.00449, 2022. 5, 6, 7
-
[31]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE in- ternational conference on computer vision, pages 618–626,
-
[32]
Learning important features through propagating activation differences
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. InInternational conference on machine learn- ing, pages 3145–3153. PMlR, 2017. 1, 2, 6
2017
-
[33]
Integrated directional gradients: Feature interaction attribu- tion for neural nlp models
Sandipan Sikdar, Parantapa Bhattacharya, and Kieran Heese. Integrated directional gradients: Feature interaction attribu- tion for neural nlp models. InProceedings of the 59th An- nual Meeting of the Association for Computational Linguis- tics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 865– 87...
2021
-
[34]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Karen Simonyan. Deep inside convolutional networks: Visu- alising image classification models and saliency maps.arXiv preprint arXiv:1312.6034, 2013. 1, 2
work page Pith review arXiv 2013
-
[35]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
Hierar- chical interpretations for neural network predictions.arXiv preprint arXiv:1806.05337, 2018
Chandan Singh, W James Murdoch, and Bin Yu. Hierar- chical interpretations for neural network predictions.arXiv preprint arXiv:1806.05337, 2018. 2
-
[37]
Caso: Context-aware second-order interpre- tations.https://github.com/singlasahil14/ CASO, 2021
Sahil Singla. Caso: Context-aware second-order interpre- tations.https://github.com/singlasahil14/ CASO, 2021. Accessed: 2025-05-06. 5
2021
-
[39]
Un- derstanding impacts of high-order loss approximations and features in deep learning interpretation
Sahil Singla, Eric Wallace, Shi Feng, and Soheil Feizi. Un- derstanding impacts of high-order loss approximations and features in deep learning interpretation. InInternational Conference on Machine Learning, pages 5848–5856. PMLR,
-
[40]
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda B. Vi´egas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise.CoRR, abs/1706.03825, 2017. 1, 2
-
[41]
Detecting statistical interactions with additive groves of trees
Daria Sorokina, Rich Caruana, Mirek Riedewald, and Daniel Fink. Detecting statistical interactions with additive groves of trees. InProceedings of the 25th international conference on Machine learning, pages 1000–1007, 2008. 3
2008
-
[42]
Identifying important group of pix- els using interactions.https : / / github
Kosuke Sumiyasu. Identifying important group of pix- els using interactions.https : / / github . com / KosukeSumiyasu/MoXI, 2025. Accessed: 2025-05-06. 6
2025
-
[43]
Identifying important group of pixels using interactions
Kosuke Sumiyasu, Kazuhiko Kawamoto, and Hiroshi Kera. Identifying important group of pixels using interactions. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 6017–6026, 2024. 1, 2, 5, 6, 7
2024
-
[44]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InInternational conference on machine learning, pages 3319–3328. PMLR, 2017. 1, 2, 4, 5, 6, 7
2017
-
[45]
The shapley taylor interaction index
Mukund Sundararajan, Kedar Dhamdhere, and Ashish Agar- wal. The shapley taylor interaction index. InInternational conference on machine learning, pages 9259–9268. PMLR,
-
[46]
Faith-shap: The faithful shapley interaction index.Journal of Machine Learning Research, 24(94):1–42, 2023
Che-Ping Tsai, Chih-Kuan Yeh, and Pradeep Ravikumar. Faith-shap: The faithful shapley interaction index.Journal of Machine Learning Research, 24(94):1–42, 2023. 1, 2
2023
-
[47]
How does this interaction affect me? in- terpretable attribution for feature interactions.https:// github.com/mtsang/archipelag, 2020
Michael Tsang. How does this interaction affect me? in- terpretable attribution for feature interactions.https:// github.com/mtsang/archipelag, 2020. Accessed: 2025-05-06. 5
2020
-
[48]
How does this interaction affect me? interpretable attribution for fea- ture interactions.Advances in neural information processing systems, 33:6147–6159, 2020
Michael Tsang, Sirisha Rambhatla, and Yan Liu. How does this interaction affect me? interpretable attribution for fea- ture interactions.Advances in neural information processing systems, 33:6147–6159, 2020. 1, 2, 3, 4, 5, 6, 7
2020
-
[49]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Per- ona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011. 2, 5, 7
2011
-
[50]
Toshinori Yamauchi, Hiroshi Kera, and Kazuhiko Kawamoto. Explaining object detectors via collective contribution of pixels.arXiv preprint arXiv:2412.00666, 3,
-
[51]
Semantic image segmentation with deep convolutional neural networks and quick shift.Symmetry, 12 (3):427, 2020
Sanxing Zhang, Zhenhuan Ma, Gang Zhang, Tao Lei, Rui Zhang, and Yi Cui. Semantic image segmentation with deep convolutional neural networks and quick shift.Symmetry, 12 (3):427, 2020. 1, 4, 7
2020
-
[52]
integral of sums
Xinyang Zhang, Ningfei Wang, Hua Shen, Shouling Ji, Xi- apu Luo, and Ting Wang. Interpretable deep learning under fire. In29th{USENIX}security symposium ({USENIX}se- curity 20), 2020. 3, 4 10 H-Sets: Hessian-Guided Discovery of Set-Level Feature Interactions in Image Classifiers Supplementary Material Appendix A. Computational cost Table 10. Time complexi...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.