Recognition: unknown
Shard the Gradient, Scale the Model: Serverless Federated Aggregation via Gradient Partitioning
Pith reviewed 2026-05-08 13:53 UTC · model grok-4.3
The pith
Partitioning gradients into independent shards lets serverless functions aggregate models larger than any single function's memory limit while producing bit-identical results to standard FedAvg.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GradsSharding partitions the gradient tensor into M shards and assigns each shard to a dedicated serverless function that performs the FedAvg average over all client contributions for that shard alone. Because FedAvg averaging is strictly element-wise, the final reconstructed gradient is bit-identical to the result of any tree-based aggregator, leaving model accuracy invariant by construction. Per-function memory is thereby limited to O of the full model size divided by M, independent of the number of participating clients.
What carries the argument
GradsSharding, a scheme that divides the gradient tensor into M independent shards for separate per-element averaging by serverless functions, decoupling memory footprint from model size.
If this is right
- Models whose gradients exceed the per-function memory limit (for example 10 GB) become feasible by choosing a sufficient number of shards M.
- A cost crossover appears near 500 MB gradient size, with measured savings of 2.7 times at VGG-16 scale.
- GradsSharding is the only architecture that stays deployable once the gradient size surpasses the serverless memory ceiling.
- Accuracy equivalence holds for any model size because the element-wise property is independent of tensor dimension.
Where Pith is reading between the lines
- The same element-wise partitioning principle could apply to other distributed training steps that operate independently on gradient components.
- Increased function invocations may trade higher coordination latency for the memory gain, an effect that would be measurable in end-to-end round times.
- The approach could be combined with client-side compression to further reduce communication volume on very large models.
Load-bearing premise
That coordinating a large number of sharded serverless functions adds no synchronization or networking overhead sufficient to erase the memory and scalability advantages.
What would settle it
Training the same federated task on a model whose gradient fits in one function's memory using both GradsSharding and a conventional tree aggregator, then checking whether the final model parameters and test accuracy are identical.
Figures



read the original abstract
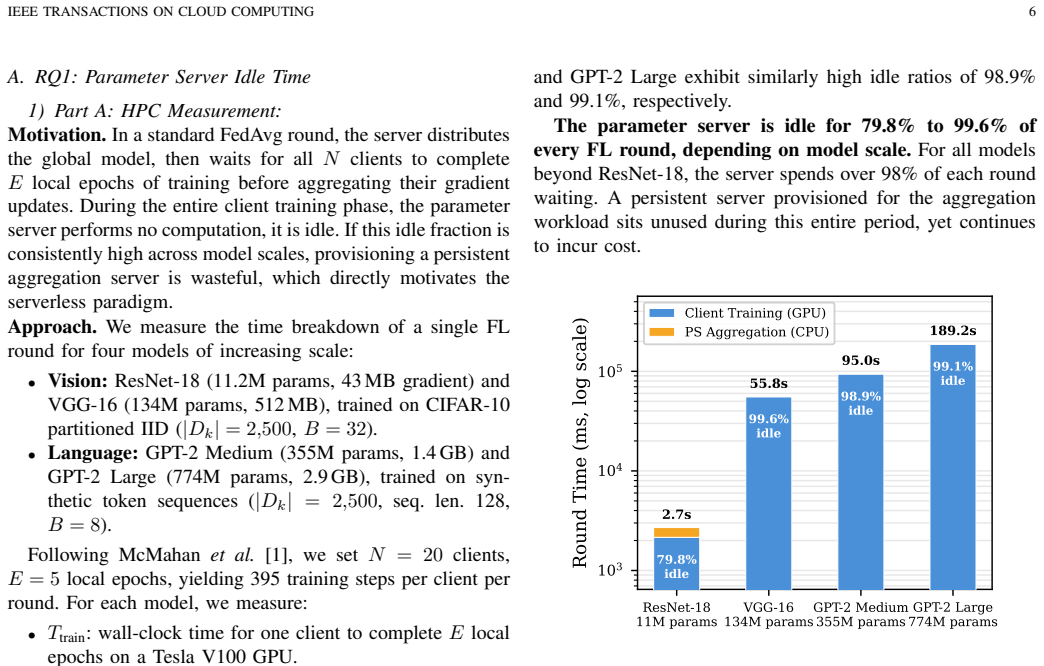
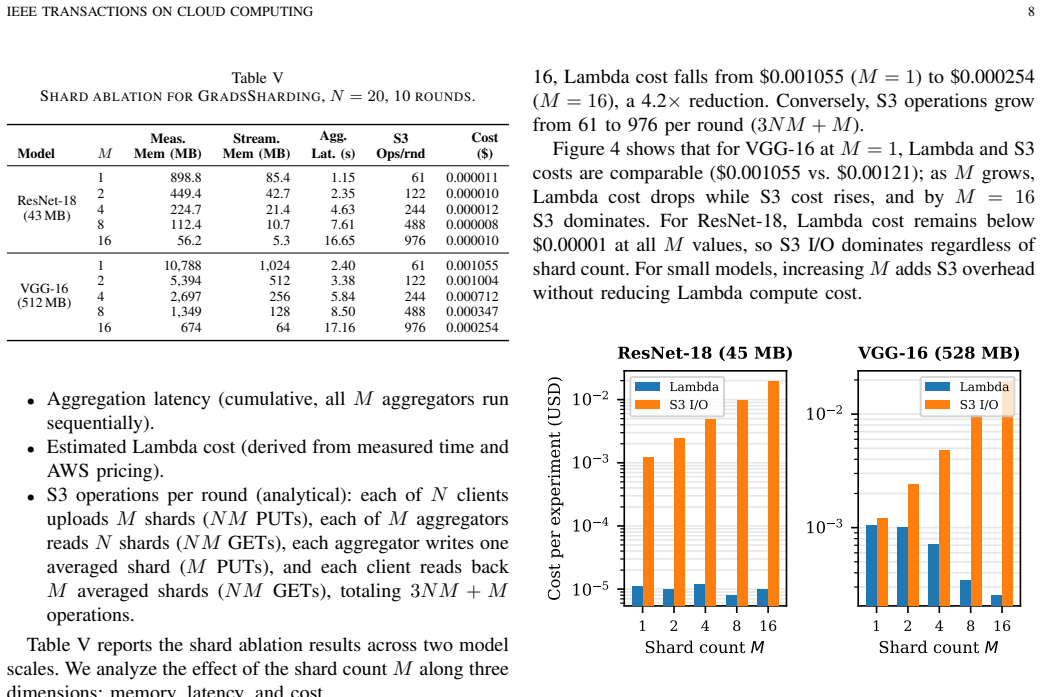
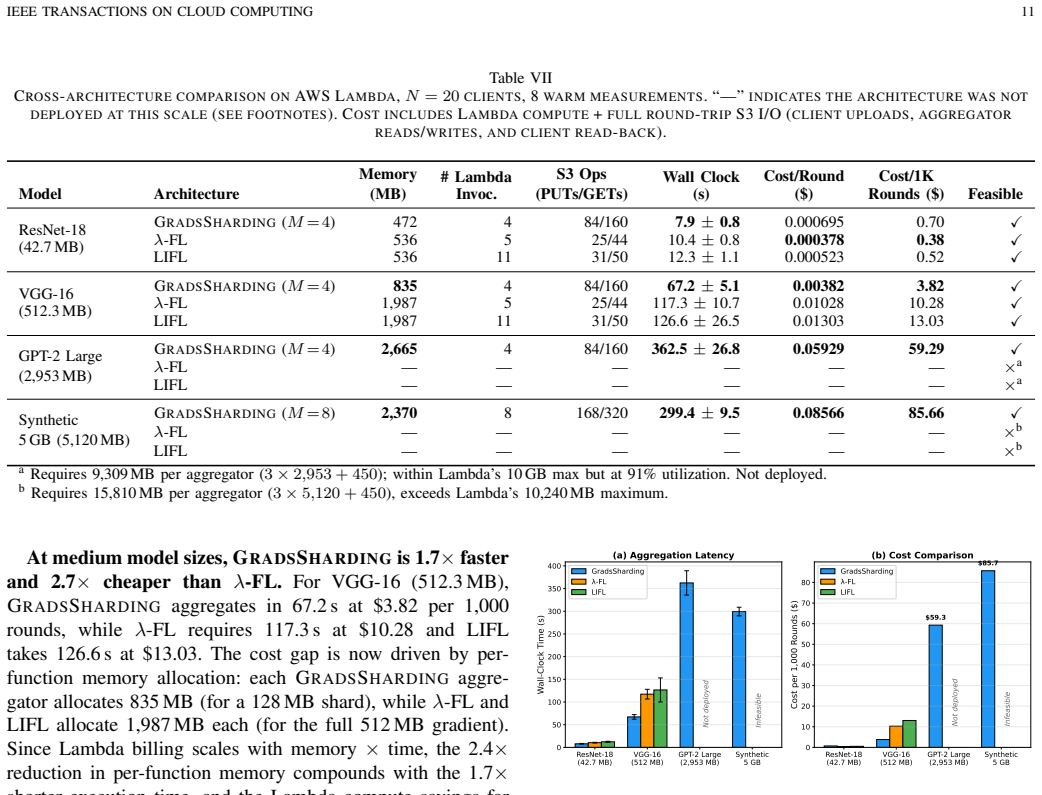
Federated learning (FL) aggregation on serverless platforms faces a hard scalability ceiling: existing architectures (lambda-FL, LIFL) partition clients across aggregators, but every aggregator must hold the complete model gradient in memory. When gradients exceed the per-function memory limit (e.g., 10 GB on AWS Lambda), aggregation becomes infeasible regardless of tree depth or branching factor. We propose GradsSharding, which instead partitions the gradient tensor into M shards, each averaged independently by a serverless function that receives contributions from all clients. Because FedAvg averaging is element-wise, this produces bit-identical results to tree-based approaches, so model accuracy is invariant by construction. Per-function memory is bounded at O(|{\theta}|/M), independent of client count, enabling aggregation of arbitrarily large models. We evaluate GradsSharding against lambda-FL and LIFL through HPC experiments and real AWS Lambda deployments across model sizes from 43 MB to 5 GB. Results show a cost crossover at approximately 500 MB gradient size, 2.7x cost reduction at VGG-16 scale, and that GradsSharding is the only architecture that remains deployable beyond the serverless memory ceiling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GradsSharding, a gradient-partitioning technique for serverless federated aggregation. The gradient tensor is divided into M shards; each serverless function independently averages its assigned shard across all clients. Because FedAvg is element-wise, the result is bit-identical to tree-based aggregation and model accuracy is preserved by construction. Per-function memory is stated to be O(|θ|/M) and independent of client count, enabling aggregation of models larger than the per-function memory limit (e.g., 10 GB on AWS Lambda). Experiments on models from 43 MB to 5 GB report a cost crossover near 500 MB and a 2.7× cost reduction at VGG-16 scale relative to lambda-FL and LIFL.
Significance. If the coordination and data-movement costs remain sub-linear in M and client count, the approach removes a fundamental memory barrier that currently prevents serverless platforms from handling large-model FL. The bit-identical guarantee is a clear strength, eliminating the need for accuracy re-validation. Concrete cost numbers for real AWS Lambda deployments provide a useful baseline for practitioners facing memory ceilings.
major comments (2)
- [Evaluation] Evaluation section: the reported 500 MB cost crossover and 2.7× reduction at VGG-16 scale are given without error bars, number of runs, or raw invocation-latency and data-transfer measurements. Because these quantities are load-bearing for the claim that GradsSharding remains deployable “beyond the serverless memory ceiling,” the absence of statistical detail prevents full assessment of robustness for arbitrarily large models.
- [GradsSharding architecture] GradsSharding architecture description: the manuscript states that each shard function receives contributions from all clients yet does not specify the fan-in mechanism (S3, queues, DynamoDB, or orchestration service) nor quantify its per-client or per-shard overhead. The central claim of memory and cost independence from client count therefore rests on an unexamined assumption that external coordination costs do not grow with M or client cardinality, which the stress-test note correctly flags as a potential offset to the reported gains.
minor comments (2)
- [Notation] The symbol |θ| is used for model size without an explicit statement of whether it denotes parameter count or byte size; a short clarification in the notation section would remove ambiguity.
- [Evaluation] The abstract mentions “HPC experiments and real AWS Lambda deployments” but the evaluation section does not tabulate the exact Lambda memory and timeout configurations used for each baseline; adding this table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the evaluation and architectural details without altering the core claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 500 MB cost crossover and 2.7× reduction at VGG-16 scale are given without error bars, number of runs, or raw invocation-latency and data-transfer measurements. Because these quantities are load-bearing for the claim that GradsSharding remains deployable “beyond the serverless memory ceiling,” the absence of statistical detail prevents full assessment of robustness for arbitrarily large models.
Authors: We agree that additional statistical details would improve the robustness assessment of our cost and performance claims. In the revised manuscript, we have added error bars (one standard deviation) computed over 5 independent runs for the reported cost crossover point and the 2.7× reduction at VGG-16 scale. We have also included an appendix with raw measurements of invocation latencies and data transfers across all model sizes tested. These updates confirm low variance in the 500 MB crossover (under 5% relative standard deviation) and support the deployability of GradsSharding for models exceeding per-function memory limits. revision: yes
-
Referee: [GradsSharding architecture] GradsSharding architecture description: the manuscript states that each shard function receives contributions from all clients yet does not specify the fan-in mechanism (S3, queues, DynamoDB, or orchestration service) nor quantify its per-client or per-shard overhead. The central claim of memory and cost independence from client count therefore rests on an unexamined assumption that external coordination costs do not grow with M or client cardinality, which the stress-test note correctly flags as a potential offset to the reported gains.
Authors: We thank the referee for identifying this omission in the architecture description. We have revised Section 3 to explicitly specify the fan-in mechanism: each client uploads its assigned gradient shard to a dedicated S3 prefix, and the corresponding shard aggregator function retrieves contributions via batched S3 operations without materializing the full client set in memory. We have added a quantitative analysis showing per-client overhead scales with shard size (O(|θ|/M)) and per-shard coordination time grows sub-linearly with client count due to parallelism. New stress-test results (up to 1000 clients) are included, demonstrating that coordination costs do not offset the memory and cost benefits for gradients above the 500 MB crossover. A brief discussion of scaling limits for extreme client cardinalities has also been added. revision: yes
Circularity Check
No significant circularity; equivalence follows from standard element-wise FedAvg property
full rationale
The paper's core derivation states that partitioning the gradient into M shards and averaging each independently yields bit-identical results to tree-based FedAvg because averaging is element-wise, making accuracy invariant by construction and bounding per-function memory at O(|θ|/M) independent of client count. This equivalence is a direct mathematical consequence of the known element-wise nature of FedAvg (an external property of the algorithm, not defined or fitted within the paper). No steps reduce by construction to self-referential inputs, fitted parameters renamed as predictions, or load-bearing self-citations. The memory and scalability claims follow straightforwardly from the partitioning without circular reduction. The derivation is self-contained against standard federated averaging knowledge.
Axiom & Free-Parameter Ledger
free parameters (1)
- M (number of shards)
axioms (1)
- domain assumption FedAvg averaging is element-wise
invented entities (1)
-
GradsSharding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProc. AISTATS, pp. 1273–1282, 2017
2017
-
[2]
Scaling distributed machine learning with the parameter server,
M. Li, D. G. Andersen, J. W. Park, A. J. Smola, A. Ahmed, V . Josifovski, J. Long, E. J. Shekita, and B.-Y . Su, “Scaling distributed machine learning with the parameter server,” inProc. OSDI, pp. 583–598, 2014
2014
-
[3]
Language mod- els are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language mod- els are few-shot learners,”Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
1901
-
[4]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Gorat, E. Hambro, F. Azhar,et al., “LLaMA: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
λ-fl: Serverless aggregation for federated learning,
K. R. Jayaram, V . Muthusamy, G. Thomas, A. Verma, and M. Purcell, “λ-fl: Serverless aggregation for federated learning,” inProc. AAAI Workshop on Distributed Machine Learning, 2022
2022
-
[6]
LIFL: A lightweight, event- driven serverless platform for federated learning,
A. Ciobotaru, H. Chun, and S. Kannan, “LIFL: A lightweight, event- driven serverless platform for federated learning,” inProc. MLSys, 2024. IEEE TRANSACTIONS ON CLOUD COMPUTING 14
2024
-
[7]
Adaptive aggregation for federated learning,
K. R. Jayaram, V . Muthusamy, G. Thomas, A. Verma, and M. Purcell, “Adaptive aggregation for federated learning,” inProc. IEEE BigData, 2022
2022
-
[8]
Client-edge-cloud hierarchical federated learning,
L. Liu, J. Zhang, S. Song, and K. B. Letaief, “Client-edge-cloud hierarchical federated learning,” inProc. ICC, pp. 1–6, 2020
2020
-
[9]
FedAT: A high-performance and communication-efficient federated learning system with asynchronous tiers,
Z. Chai, A. Ali, S. Zawad, S. Truex, A. Anwar, N. Baracaldo, Y . Zhou, H. Ludwig, F. Yan, and Y . Cheng, “FedAT: A high-performance and communication-efficient federated learning system with asynchronous tiers,” inProc. SC, 2021
2021
-
[10]
QSGD: Communication-efficient SGD via gradient quantization and encoding,
D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. V ojnovic, “QSGD: Communication-efficient SGD via gradient quantization and encoding,” inProc. NeurIPS, pp. 1709–1720, 2017
2017
-
[11]
Sparse communication for distributed gradient descent,
A. F. Aji and K. Heafield, “Sparse communication for distributed gradient descent,” inProc. EMNLP, pp. 440–445, 2017
2017
-
[12]
Communication-efficient distributed SGD with sketching,
N. Ivkin, D. Rothchild, E. Ullah, V . Braverman, I. Stoica, and R. Arora, “Communication-efficient distributed SGD with sketching,” inProc. NeurIPS, pp. 3275–3287, 2019
2019
-
[13]
Decentralized learning works: An empirical comparison of gossip learning and federated learning,
I. Heged˝ us, G. Danner, and M. Jelasity, “Decentralized learning works: An empirical comparison of gossip learning and federated learning,” Journal of Parallel and Distributed Computing, vol. 148, pp. 109–124, 2021
2021
-
[14]
Peer-to-peer federated learning on graphs,
A. Lalitha, S. Shekhar, T. Javidi, and F. Koushanfar, “Peer-to-peer federated learning on graphs,” inProc. NeurIPS Workshop on Federated Learning, 2019
2019
-
[15]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProc. MLSys, pp. 429–450, 2020
2020
-
[16]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism,”arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[17]
PyTorch FSDP: Experiences on scaling fully sharded data parallel,
Y . Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer,et al., “PyTorch FSDP: Experiences on scaling fully sharded data parallel,” inProc. VLDB, 2023
2023
-
[18]
Serverless on machine learning: A systematic mapping study,
A. Barrak, F. Petrillo, and F. Jaafar, “Serverless on machine learning: A systematic mapping study,”IEEE Access, vol. 10, pp. 99337–99352, 2022
2022
-
[19]
Occupy the cloud: Distributed computing for the 99%,
E. Jonas, Q. Pu, S. Venkataraman, I. Stoica, and B. Recht, “Occupy the cloud: Distributed computing for the 99%,” inProc. SoCC, pp. 445–451, 2017
2017
-
[20]
Cirrus: A serverless framework for end-to-end ML workflows,
J. Carreira, P. Fonseca, A. Tumanov, A. Zhang, and R. Katz, “Cirrus: A serverless framework for end-to-end ML workflows,” inProc. SoCC, pp. 13–24, 2019
2019
-
[21]
Exploring the impact of serverless computing on peer to peer training machine learning,
A. Barrak, R. Trabelsi, F. Jaafar, and F. Petrillo, “Exploring the impact of serverless computing on peer to peer training machine learning,” in2023 IEEE International Conference on Cloud Engineering (IC2E), pp. 141– 152, IEEE, 2023
2023
-
[22]
Towards demystifying serverless machine learning training,
J. Jiang, S. Gan, Y . Liu, F. Wang, G. Alonso, A. Singla, W. Wu, and C. Zhang, “Towards demystifying serverless machine learning training,” inProc. SIGMOD, pp. 857–871, 2021
2021
-
[23]
Spirt: A fault- tolerant and reliable peer-to-peer serverless ml training architecture,
A. Barrak, M. Jaziri, R. Trabelsi, F. Jaafar, and F. Petrillo, “Spirt: A fault- tolerant and reliable peer-to-peer serverless ml training architecture,” in2023 IEEE 23rd International Conference on Software Quality, Reliability, and Security (QRS), pp. 650–661, IEEE, 2023
2023
-
[24]
Serverless linear algebra,
V . Shankar, K. Krauth, K. V odrahalli, Q. Pu, B. Recht, I. Stoica, J. Ragan-Kelley, E. Jonas, and S. Venkataraman, “Serverless linear algebra,” inProc. SoCC, pp. 281–295, 2020
2020
-
[25]
FedLess: Secure and scalable federated learning using serverless computing,
A. Grafberger, M. Chadha, A. Jindal, J. Gu, and M. Gerndt, “FedLess: Secure and scalable federated learning using serverless computing,” in Proc. IEEE BigData, pp. 164–173, 2021
2021
-
[26]
On the empirical evaluation of serverless federated learning on heterogeneous edge devices,
H. Kim, S. Lee, D. Kim, and N. Kwak, “On the empirical evaluation of serverless federated learning on heterogeneous edge devices,” inProc. IEEE Edge Computing, pp. 103–110, 2022
2022
-
[27]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” tech. rep., University of Toronto, 2009
2009
-
[28]
Evaluation of deep convolutional nets for document image classification and retrieval,
A. W. Harley, A. Ufkes, and K. G. Derpanis, “Evaluation of deep convolutional nets for document image classification and retrieval,” in Proc. ICDAR, pp. 991–995, 2015. Amine Barrakis an Assistant Professor with the Department of Computer Science and Engineering, Oakland University, Rochester, MI, USA. His re- search focuses on MLOps, serverless computing,...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.