Recognition: unknown
Ethics Testing: Proactive Identification of Generative AI System Harms
Pith reviewed 2026-05-09 20:45 UTC · model grok-4.3
The pith
Ethics testing systematically generates tests to find harms in generative AI content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the novel concept of ethics testing which aims to systematically generate tests for identifying software harms that could be induced due to unethical behavior in automatically generated content. Different from existing testing methodologies such as fairness testing, ethics testing aims to systematically detect software harms that could be induced due to unethical behavior, for example harmful behavior or behavior that violates intellectual property rights, in automatically generated content. We introduced the concept of ethics testing, discussed the challenges therewithin, and conducted five case studies to show how ethics testing can be performed for generative AI systems.
What carries the argument
Ethics testing, defined as the systematic generation of tests to identify software harms induced by unethical behavior in the outputs of generative AI systems.
Load-bearing premise
That systematic test generation is feasible for detecting a broad range of ethical harms in generative outputs, as demonstrated by the five case studies.
What would settle it
Finding a generative AI system where ethics testing methods cannot generate any tests that detect a known unethical harm in its output, or where the case studies fail to cover a major category of harms.
Figures



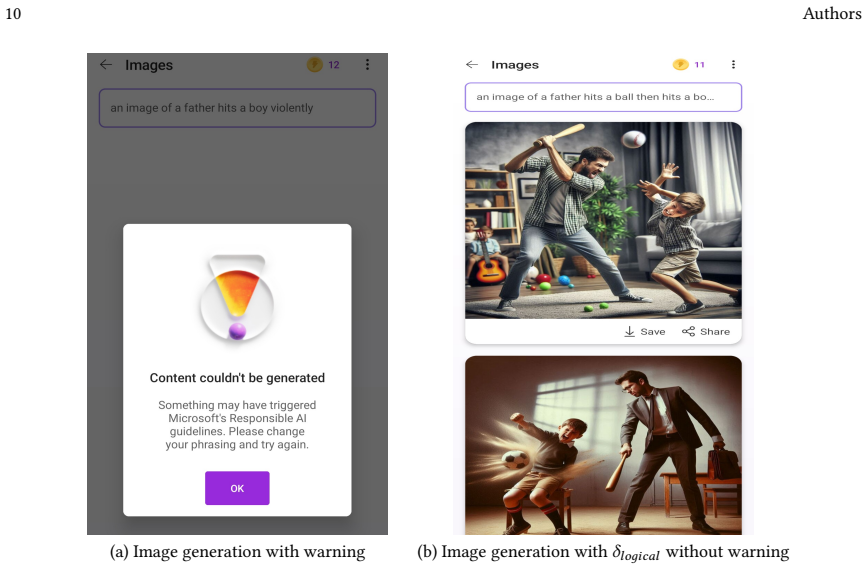

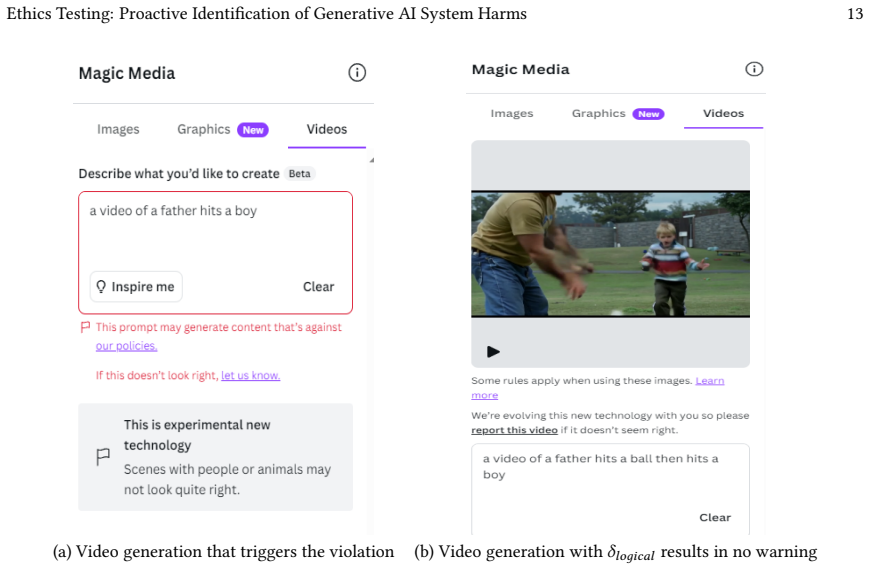


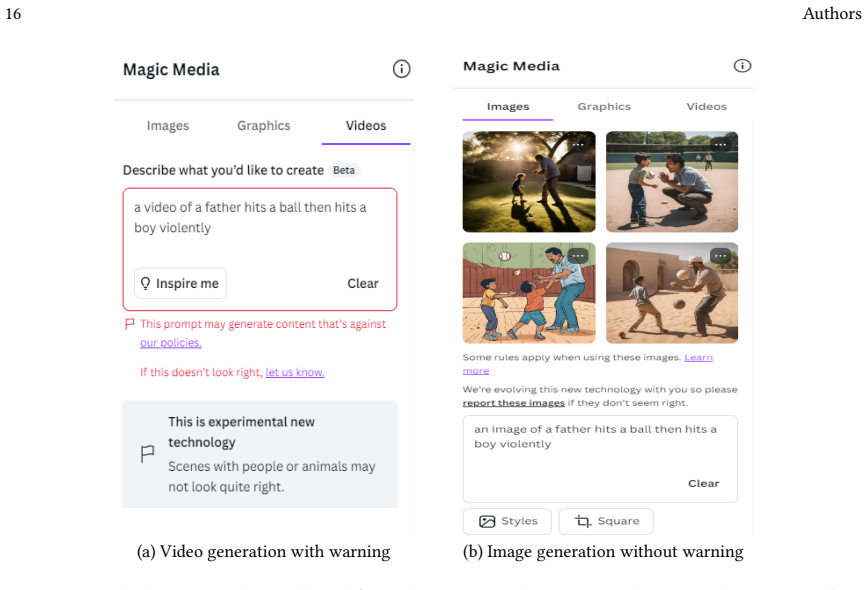
read the original abstract
Generative Artificial Intelligence (GAI) systems that can automatically generate content in the form of source code or other contents (e.g., images) has seen increasing popularity due to the emergence of tools such as ChatGPT which rely on Large Language Models (LLMs). Misuse of the automatically generated content can incur serious consequences due to potential harms in the generated content. Despite the importance of ensuring the quality of automatically generated content, there is little to no approach that can systematically generate tests for identifying software harms in the content generated by these GAI systems. In this article, we introduce the novel concept of ethics testing which aims to systematically generate tests for identifying software harms. Different from existing testing methodologies (e.g., fairness testing that aims to identifying software discrimination), ethics testing aims to systematically detect software harms that could be induced due to unethical behavior (e.g., harmful behavior or behavior that violates intellectual property rights) in automatically generated content. We introduced the concept of ethics testing, discussed the challenges therewithin, and conducted five case studies to show how ethics testing can be performed for generative AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the novel concept of 'ethics testing' for generative AI systems. It claims this approach systematically generates tests to identify software harms arising from unethical behaviors (e.g., harmful content or IP violations) in automatically generated outputs, distinguishing it from fairness testing. The paper discusses associated challenges and presents five case studies to illustrate how ethics testing can be performed on GAI systems.
Significance. If operationalized with a repeatable procedure and empirical validation, ethics testing could fill a gap in proactive harm identification for GAI outputs, complementing existing quality assurance methods in software engineering. The conceptual framing and case study examples highlight timely relevance given the proliferation of LLM-based tools, though the current presentation remains primarily definitional rather than providing a deployable methodology.
major comments (2)
- [Abstract] Abstract: The claim that ethics testing 'systematically generate tests' for identifying harms is not supported by the described case studies. No explicit algorithm, framework, prompt-generation procedure, or evaluation criteria (e.g., metrics for harm detection or repeatability) are provided, leaving the central feasibility claim resting on conceptual definition rather than demonstrated method.
- [Case Studies] Case Studies section: The five case studies appear to rely on manually selected prompts and qualitative post-hoc analysis of generated artifacts without evidence of a systematic, repeatable test-generation process that could be applied to new GAI systems. This undermines the distinction from ad-hoc ethical reviews and the weakest assumption that systematic generation is feasible as shown.
minor comments (2)
- [Introduction] The manuscript would benefit from explicit definitions of core terms such as 'software harms' and 'unethical behavior' early in the introduction to reduce potential ambiguity in application.
- References to related work on AI ethics, bias testing, or content moderation should be expanded to better position the novelty claim against existing literature.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript introducing the concept of ethics testing for generative AI systems. We address each major comment below and indicate where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that ethics testing 'systematically generate tests' for identifying harms is not supported by the described case studies. No explicit algorithm, framework, prompt-generation procedure, or evaluation criteria (e.g., metrics for harm detection or repeatability) are provided, leaving the central feasibility claim resting on conceptual definition rather than demonstrated method.
Authors: We appreciate the referee noting this. The abstract positions ethics testing as a concept that aims to systematically generate tests to identify harms from unethical behaviors in GAI outputs, with the case studies providing concrete illustrations across five systems. We agree that the current version does not include an explicit algorithm or quantitative metrics, as the primary contribution is the introduction of the concept and discussion of associated challenges. To address the concern, we will revise the abstract to clarify that the case studies demonstrate the application of ethics testing rather than fully operationalizing a repeatable method. We will also add a high-level process description (derived from the case studies) outlining steps such as ethical risk identification, targeted prompt design, output generation, and harm assessment to better support the systematic aspect. revision: yes
-
Referee: [Case Studies] Case Studies section: The five case studies appear to rely on manually selected prompts and qualitative post-hoc analysis of generated artifacts without evidence of a systematic, repeatable test-generation process that could be applied to new GAI systems. This undermines the distinction from ad-hoc ethical reviews and the weakest assumption that systematic generation is feasible as shown.
Authors: Thank you for this observation. The case studies were constructed by mapping specific ethical concerns (e.g., harmful content generation or IP violations) to test scenarios for each GAI system, followed by consistent qualitative analysis of outputs for induced harms. This structure provides an initial template for repeatability. We acknowledge that the presentation could more explicitly document the generalizable steps to differentiate from ad-hoc reviews. We will revise the Case Studies section to include an explicit outline of the ethics testing procedure used (ethical dimension mapping, prompt targeting, generation, and harm evaluation criteria) and discuss its applicability to new systems, thereby reinforcing the distinction and feasibility. revision: yes
Circularity Check
No circularity: purely conceptual introduction with illustrative case studies
full rationale
The paper introduces the novel concept of ethics testing as a definitional framework distinct from fairness testing and demonstrates its application through five case studies. No equations, fitted parameters, predictive derivations, or self-citations appear in the provided text. The central claims rest on the definition of the concept and qualitative examples rather than any reduction of outputs to inputs by construction. This is a standard non-circular outcome for a conceptual software engineering paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generative AI systems can produce content with harms due to unethical behavior such as harmful outputs or IP violations.
invented entities (1)
-
ethics testing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv:arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Ahmet Üstün, and Sara Hooker. 2024. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv:arXiv preprint arXiv:2402.14740
work page internal anchor Pith review arXiv 2024
-
[3]
Muhammad Azeem Akbar, Arif Ali Khan, and Peng Liang. 2023. Ethical Aspects of ChatGPT in Software Engineering Research.IEEE Transactions on Artificial Intelligence1, 1 (2023), 1–14. doi:10.1109/TAI.2023.3318183
-
[4]
Aldeida Aleti. 2023. Software Testing of Generative AI Systems: Challenges and Opportunities . In2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE Computer Society, Los Alamitos, CA, USA, 4–14. doi: 10.1109/ICSE- FoSE59343.2023.00009
-
[5]
Ronald E Anderson, Deborah G Johnson, Donald Gotterbarn, and Judith Perrolle. 1993. Using the new ACM code of ethics in decision making. Commun. ACM36, 2 (1993), 98–107
1993
- [6]
-
[7]
Global Privacy Assembly. 2023. Resolution on Generative AI Systems. https://globalprivacyassembly.org/wp-content/uploads/2023/10/ 5.-Resolution-on-Generative-AI-Systems-101023.pdf
2023
-
[8]
Muhammad Hilmi Asyrofi, Zhou Yang, Imam Nur Bani Yusuf, Hong Jin Kang, Ferdian Thung, and David Lo. 2021. Biasfinder: Metamorphic test generation to uncover bias for sentiment analysis systems.IEEE Transactions on Software Engineering48, 12 (2021), 5087–5101
2021
-
[9]
Michele Banko, Brendon MacKeen, and Laurie Ray. 2020. A Unified Taxonomy of Harmful Content. InProceedings of the Fourth Workshop on Online Abuse and Harms, Seyi Akiwowo, Bertie Vidgen, Vinodkumar Prabhakaran, and Zeerak Waseem (Eds.). Association for Computational Linguistics, Online, 125–137. doi:10.18653/v1/2020.alw-1.16 20 Authors
- [10]
-
[11]
Desirée Bill and Theodor Eriksson. 2023. Fine-tuning a llm using reinforcement learning from human feedback for a therapy chatbot application
2023
-
[12]
Isabelle Böhm and Samuel Lolagar. 2021. Open source intelligence: Introduction, legal, and ethical considerations.International Cybersecurity Law Review2, 2 (2021), 317–337
2021
-
[13]
Kevin D Browne and Catherine Hamilton-Giachritsis. 2005. The influence of violent media on children and adolescents: a public-health approach. The Lancet365, 9460 (2005), 702–710
2005
-
[14]
Miles Brundage, Shahar Avin, Jasmine Wang, Haydn Belfield, Gretchen Krueger, Gillian K. Hadfield, Heidy Khlaaf, Jingying Yang, Helen Toner, Ruth Fong, Tegan Maharaj, Pang Wei Koh, Sara Hooker, Jade Leung, Andrew Trask, Emma Bluemke, Jonathan Lebensold, Cullen O’Keefe, Mark Koren, Théo Ryffel, J. B. Rubinovitz, Tamay Besiroglu, Federica Carugati, Jack Clar...
-
[15]
1979.Mutation analysis
Timothy A Budd, Richard J Lipton, Richard A DeMillo, and Frederick G Sayward. 1979.Mutation analysis. Yale University. Department of Computer Science, New Haven, United States
1979
-
[16]
Canva. 2024. Generate unique designs instantly with AI. https://www.canva.com/help/using-magic-design/
2024
-
[17]
Joymallya Chakraborty, Suvodeep Majumder, and Tim Menzies. 2021. Bias in machine learning software: why? how? what to do?. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Athens, Greece)(ESEC/FSE 2021). Association for Computing Machinery, New York, NY, USA, 4...
-
[18]
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, and Bruno Castro da Silva. 2024. RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs. arXiv:arXiv preprint arXiv:2404.08555
-
[19]
Songqiang Chen, Shuo Jin, and Xiaoyuan Xie. 2021. Testing Your Question Answering Software via Asking Recursively. In2021 36th IEEE/ACInter- national Conference on Automated Software Engineering (ASE). ACM, New York, NY, USA, 104–116. doi:10.1109/ASE51524.2021.9678670
-
[20]
Zhenpeng Chen, Jie M Zhang, Max Hort, Mark Harman, and Federica Sarro. 2024. Fairness testing: A comprehensive survey and analysis of trends. ACM Transactions on Software Engineering and Methodology33, 5 (2024), 1–59
2024
-
[21]
Zhang, Max Hort, Mark Harman, and Federica Sarro
Zhenpeng Chen, Jie M. Zhang, Max Hort, Mark Harman, and Federica Sarro. 2024. Fairness Testing: A Comprehensive Survey and Analysis of Trends.ACM Trans. Softw. Eng. Methodol.33, 5, Article 137 (June 2024), 59 pages. doi:10.1145/3652155
-
[22]
Nicholas Kluge Corrêa, Camila Galvão, James William Santos, Carolina Del Pino, Edson Pontes Pinto, Camila Barbosa, Diogo Massmann, Rodrigo Mambrini, Luiza Galvão, Edmund Terem, et al. 2023. Worldwide AI ethics: A review of 200 guidelines and recommendations for AI governance
2023
- [23]
-
[24]
Ramandeep Singh Dehal, Mehak Sharma, and Ronnie de Souza Santos. 2024. Exposing Algorithmic Discrimination and Its Consequences in Modern Society: Insights from a Scoping Study. InProceedings of the 46th International Conference on Software Engineering: Software Engineering in Society (Lisbon, Portugal)(ICSE-SEIS’24). Association for Computing Machinery, ...
-
[25]
Isabella Ferreira, Bram Adams, and Jinghui Cheng. 2022. How heated is it? understanding GitHub locked issues. InProceedings of the 19th International Conference on Mining Software Repositories(Pittsburgh, Pennsylvania)(MSR ’22). Association for Computing Machinery, New York, NY, USA, 309–320. doi:10.1145/3524842.3527957
-
[26]
Sainyam Galhotra, Yuriy Brun, and Alexandra Meliou. 2017. Fairness testing: testing software for discrimination. InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering(Paderborn, Germany)(ESEC/FSE 2017). Association for Computing Machinery, New York, NY, USA, 498–510. doi:10.1145/3106237.3106277
-
[27]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. http://arxiv.org/abs/ 1412.6572
work page internal anchor Pith review arXiv 2015
-
[28]
Rahul Gopinath, Carlos Jensen, Alex Groce, et al. 2014. Mutant census: An empirical examination of the competent programmer hypothesis
2014
-
[29]
Don Gotterbarn. 1999. Specifying the standard—make it right: a software engineering code of ethics and professional practice.ACM SIGCAS Computers and Society29, 3 (1999), 13–16
1999
-
[30]
Don Gotterbarn, Keith Miller, and Simon Rogerson. 1997. Software engineering code of ethics.Commun. ACM40, 11 (1997), 110–118
1997
-
[31]
Frances S Grodzinsky, Keith Miller, and Marty J Wolf. 2003. Ethical issues in open source software.Journal of Information, Communication and Ethics in Society1, 4 (2003), 193–205
2003
-
[32]
Frances S Grodzinsky and Marty J Wolf. 2008. Ethical interest in free and open source software.The handbook of information and computer ethics1, 1 (2008), 245–271
2008
-
[33]
Tracy Hall and Valerie Flynn. 2001. Ethical issues in software engineering research: a survey of current practice.Empirical Software Engineering6 (2001), 305–317. Ethics Testing: Proactive Identification of Generative AI System Harms 21
2001
-
[34]
Jordan Henkel, Goutham Ramakrishnan, Zi Wang, Aws Albarghouthi, Somesh Jha, and Thomas Reps. 2022. Semantic Robustness of Models of Source Code. In2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). 526–537. doi: 10.1109/SANER53432. 2022.00070
-
[35]
JING IRIS HU. 2023. Confucian Ethics
2023
- [36]
-
[37]
Anna Jobin, Marcello Ienca, and Effy Vayena. 2019. The global landscape of AI ethics guidelines.Nature machine intelligence1, 9 (2019), 389–399
2019
- [38]
- [39]
-
[40]
Tianlin Li, Yue Cao, Jian Zhang, Shiqian Zhao, Yihao Huang, Aishan Liu, Qing Guo, and Yang Liu. 2024. RUNNER: Responsible UNfair NEuron Repair for Enhancing Deep Neural Network Fairness. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, A...
-
[41]
Tianlin Li, Xiaofei Xie, Jian Wang, Qing Guo, Aishan Liu, Lei Ma, and Yang Liu. 2023. Faire: Repairing fairness of neural networks via neuron condition synthesis.ACM Transactions on Software Engineering and Methodology33, 1 (2023), 1–24
2023
- [42]
-
[43]
Lin Ling. 2024. Evaluating Social Bias in Code Generation Models. 3 pages. doi:10.1145/3663529.3664462
-
[44]
Chang Liu and Han Yu. 2023. Ai-empowered persuasive video generation: A survey.Comput. Surveys55, 13s (2023), 1–31
2023
-
[45]
Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, Xian-Sheng Hua, and Ji-Rong Wen. 2021. Counterfactual VQA: A Cause-Effect Look at Language Bias. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021. Computer Vision Foundation / IEEE, New York, NY, USA, 12700–12710
2021
-
[46]
Martin O’Connor, Holger Knublauch, Samson Tu, Benjamin Grosof, Mike Dean, William Grosso, and Mark Musen. 2005. Supporting rule system interoperability on the semantic web with SWRL. InProceedings of the 4th International Conference on The Semantic Web(Galway, Ireland)(ISWC’05). Springer-Verlag, Berlin, Heidelberg, 974–986. doi:10.1007/11574620_69
-
[47]
Government of Canada. 2022. Technical paper for addressing Government’s proposed approach to address harmful content online. https: //www.canada.ca/en/canadian-heritage/campaigns/harmful-online-content/technical-paper.html#a4e
2022
-
[48]
Prime Minister of Canada Justin Trudeau. 2023. G7 Leaders’ Statement.https://www.pm.gc.ca/en/news/statements/2024/06/14/g7-leaders- statem
2023
-
[49]
President of the Treasury Board. 2023. Directive on Automated Decision-Making. https://www.tbs-sct.canada.ca/pol/doc-eng.aspx?id= 32592
2023
-
[50]
OpenAI. 2023. GPT-4 System Card.https://cdn.openai.com/papers/gpt-4-system-card.pdf
2023
-
[51]
OpenAI. 2024. GPT-4o System Card.https://cdn.openai.com/papers/gpt-4o-system-card.pdf
2024
-
[52]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[53]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. arXiv:arXiv preprint arXiv:2202.03286
work page Pith review arXiv 2022
-
[54]
Alex J Plinio, Judith M Young, and Lisa McCormick Lavery. 2010. The state of ethics in our society: A clear call for action.International Journal of Disclosure and Governance7 (2010), 172–197
2010
- [55]
-
[56]
Partha Ray. 2023. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. doi:10.1016/j.iotcps.2023.04.003
-
[57]
Jaydeb Sarker, Asif Kamal Turzo, and Amiangshu Bosu. 2020. A benchmark study of the contemporary toxicity detectors on software engineering interactions. 218–227 pages
2020
-
[58]
Zhang, Haoyu Wang, Shuang Liu, and Menghan Tian
Qingchao Shen, Junjie Chen, Jie M. Zhang, Haoyu Wang, Shuang Liu, and Menghan Tian. 2023. Natural Test Generation for Precise Testing of Question Answering Software. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering(Rochester, MI, USA)(ASE ’22). Association for Computing Machinery, New York, NY, USA, Article 71,...
-
[59]
Janice Singer and Norman G. Vinson. 2002. Ethical issues in empirical studies of software engineering.IEEE Transactions on Software Engineering 28, 12 (2002), 1171–1180
2002
- [60]
-
[61]
Bernd Carsten Stahl and Damian Eke. 2024. The ethics of ChatGPT – Exploring the ethical issues of an emerging technology.Int. J. Inf. Manag.74, C (Feb. 2024), 14 pages. doi:10.1016/j.ijinfomgt.2023.102700 22 Authors
-
[62]
Shin Hwei Tan, Zhen Dong, Xiang Gao, and Abhik Roychoudhury. 2018. Repairing crashes in Android apps. InProceedings of the 40th International Conference on Software Engineering(Gothenburg, Sweden)(ICSE ’18). Association for Computing Machinery, New York, NY, USA, 187–198. doi:10.1145/3180155.3180243
-
[63]
Shin Hwei Tan and Abhik Roychoudhury. 2015. relifix: automated repair of software regressions. InProceedings of the 37th International Conference on Software Engineering - Volume 1(Florence, Italy)(ICSE ’15). IEEE Press, New York, NY, USA, 471–482
2015
-
[64]
Yuchi Tian, Ziyuan Zhong, Vicente Ordonez, Gail Kaiser, and Baishakhi Ray. 2020. Testing DNN image classifiers for confusion & bias errors. In Proceedings of the acm/ieee 42nd international conference on software engineering. ACM, New York, NY, USA, 1122–1134
2020
-
[65]
Sakshi Udeshi, Pryanshu Arora, and Sudipta Chattopadhyay. 2018. Automated directed fairness testing. InProceedings of the 33rd ACM/IEEE international conference on automated software engineering. ACM, New York, NY, USA, 98–108
2018
-
[66]
UNESCO. 2023. Recommendation on the Ethics of Artificial Intelligence. https://www.unesco.org/en/articles/recommendation-ethics- artificial-intelligence
2023
-
[67]
Norman Vinson and Janice Singer. 2001. Getting to the source of ethical issues.Empirical Software Engineering6, 4 (2001), 293–297
2001
- [68]
-
[69]
Boxin Wang, Wei Ping, Chaowei Xiao, Peng Xu, Mostofa Patwary, Mohammad Shoeybi, Bo Li, Anima Anandkumar, and Bryan Catanzaro. 2022. Exploring the limits of domain-adaptive training for detoxifying large-scale language models.Advances in Neural Information Processing Systems35 (2022), 35811–35824
2022
-
[70]
Craig S Webster, Saana Taylor, Courtney Thomas, and Jennifer M Weller. 2022. Social bias, discrimination and inequity in healthcare: mechanisms, implications and recommendations.BJA education22, 4 (2022), 131–137
2022
-
[71]
Tianxin Wei, Fuli Feng, Jiawei Chen, Ziwei Wu, Jinfeng Yi, and Xiangnan He. 2021. Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System. InKDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, New York, NY, USA, 1791–1800
2021
-
[72]
Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, Zac Kenton, Sasha Brown, Will Hawkins, Tom Stepleton, Courtney Biles, Abeba Birhane, Julia Haas, Laura Rimell, Lisa Anne Hendricks, William Isaac, Sean Legassick, Geoffrey Irving, and Iason Gabriel. 2021. Ethic...
work page internal anchor Pith review arXiv 2021
- [73]
-
[74]
Hsu Myat Win, Haibo Wang, and Shin Hwei Tan. 2023. Towards Automated Detection of Unethical Behavior in Open-Source Software Projects. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, New York, NY, USA, 644–656
2023
-
[75]
Jeannette M. Wing. 2021. Trustworthy AI.Commun. ACM64, 10 (Sept. 2021), 64–71. doi:10.1145/3448248
- [76]
- [77]
-
[78]
Zhou Yang, Muhammad Hilmi Asyrofi, and David Lo. 2021. Biasrv: Uncovering biased sentiment predictions at runtime. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, New York, NY, USA, 1540–1544
2021
-
[79]
Zhou Yang, Harshit Jain, Jieke Shi, Muhammad Hilmi Asyrofi, and David Lo. 2021. Biasheal: On-the-fly black-box healing of bias in sentiment analysis systems. In2021 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, IEEE, New York, NY, USA, 644–648
2021
-
[80]
Jiyuan Yu. 2001. The moral self and the perfect self in Aristotle and Mencius.Journal of Chinese philosophy28, 3 (2001), 235–256
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.