Recognition: unknown
Implementation and Privacy Guarantees for Scalable Keyword Search on SOLID-based Decentralized Data with Granular Visibility Constraints
Pith reviewed 2026-05-08 13:02 UTC · model grok-4.3
The pith
ESPRESSO enables scalable keyword search over distributed Solid pods while enforcing user visibility policies through scoped indexes and privacy-aware metadata.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ESPRESSO constructs WebID-scoped indexes within pods and employs privacy-aware metadata to enable efficient source selection and ranking across servers under user-defined visibility policies. It introduces a formal threat model that analyzes security and privacy risks from index generation, aggregation, and use, including unintended metadata leakage and inference of sensitive information about data in personal stores. The analysis identifies key design principles that limit metadata exposure while mitigating unauthorized inference, providing a foundation for evaluating privacy-preserving decentralized search.
What carries the argument
WebID-scoped indexes paired with privacy-aware metadata inside the ESPRESSO framework, which perform source selection and ranking while respecting granular visibility constraints across pods.
Load-bearing premise
WebID-scoped indexes and privacy-aware metadata can be generated and aggregated without letting adversaries infer sensitive information beyond what the threat model explicitly accounts for.
What would settle it
An adversary extracts specific details about private pod contents using only the generated indexes or metadata in a working ESPRESSO system.
Figures

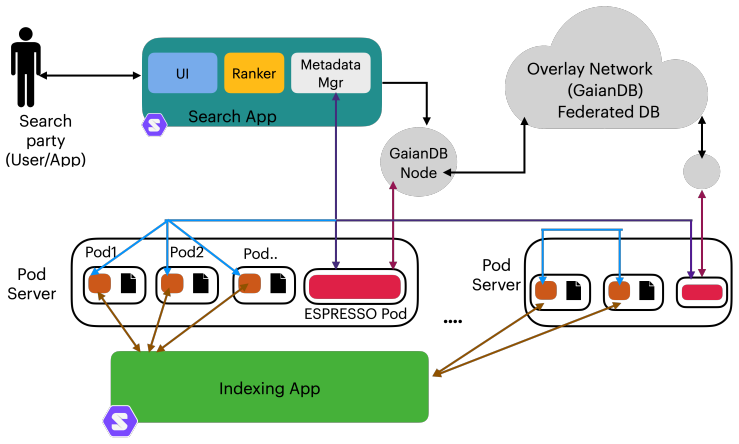
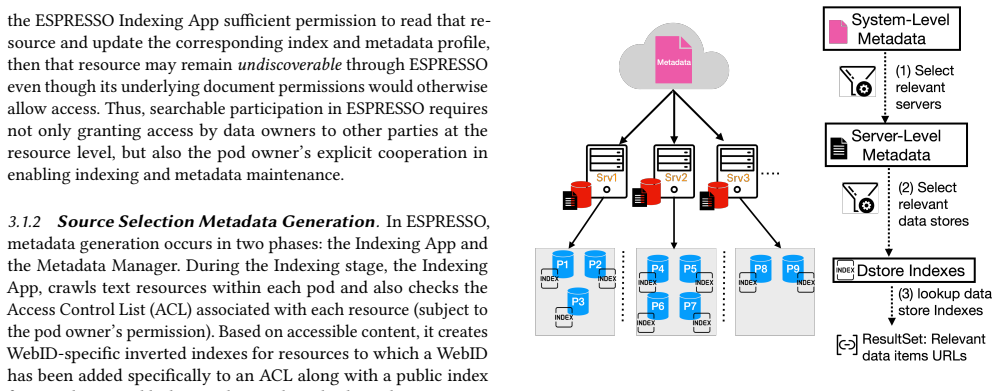
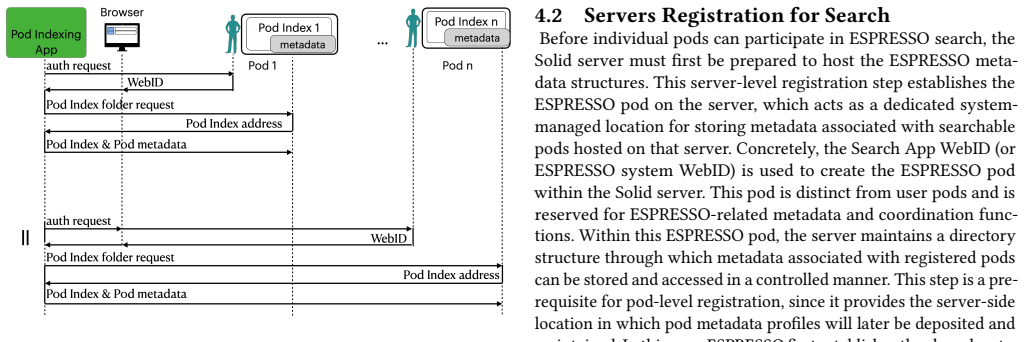



read the original abstract
In decentralized personal data ecosystems grounded in architectures such as Solid, users retain sovereignty over their data via personal online data stores (pods), hosted on Solid-compliant server infrastructures. In such environments, data remains under the control of pod owners, which complicates search due to distribution across numerous pods and user-specific access constraints. ESPRESSO is a decentralized framework for scalable keyword-based search across distributed Solid pods under user-defined visibility policies. It addresses key challenges of decentralized search by constructing WebID-scoped indexes within pods and employing privacy-aware metadata to enable efficient source selection and ranking across servers. This paper further introduces a formal threat model for ESPRESSO, analysing the security and privacy risks associated with the generation, aggregation, and use of indexes and metadata. These risks include unintended metadata leakage and the potential for adversaries to infer sensitive information about data that resides within personal data stores. The analysis identifies key design principles that limit metadata exposure while mitigating unauthorized inference. The proposed threat model provides a foundation for evaluating privacy-preserving decentralized search and informs the design of systems with stronger privacy guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ESPRESSO, a decentralized framework for scalable keyword-based search across distributed Solid pods under user-defined visibility policies. It describes the construction of WebID-scoped indexes within pods and the use of privacy-aware metadata to support efficient source selection and ranking. The paper also introduces a formal threat model that analyzes security and privacy risks associated with index generation, aggregation, and use, including unintended metadata leakage and inference of sensitive data, while identifying design principles to limit exposure.
Significance. If the proposed index construction, metadata mechanisms, and threat model can be shown to deliver the claimed privacy properties with concrete proofs and evaluations, the work would contribute to privacy-preserving search in decentralized personal data stores such as Solid. It addresses practical challenges of data sovereignty and granular access control in distributed environments, potentially informing future systems with stronger privacy guarantees.
major comments (1)
- Abstract: The manuscript states that a formal threat model is introduced which analyzes risks of generation, aggregation, and use of indexes and metadata, and that design principles limit metadata exposure while mitigating unauthorized inference. However, no formal privacy definition (e.g., an indistinguishability game or differential privacy bound), reduction to the index/metadata construction, or proof is referenced that demonstrates the WebID-scoped indexes and privacy-aware metadata satisfy the model. This is load-bearing for the central claim of privacy guarantees.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The feedback highlights an important point regarding the scope and formality of our threat model, which we address below. We will revise the manuscript accordingly to ensure the claims accurately reflect the content.
read point-by-point responses
-
Referee: [—] Abstract: The manuscript states that a formal threat model is introduced which analyzes risks of generation, aggregation, and use of indexes and metadata, and that design principles limit metadata exposure while mitigating unauthorized inference. However, no formal privacy definition (e.g., an indistinguishability game or differential privacy bound), reduction to the index/metadata construction, or proof is referenced that demonstrates the WebID-scoped indexes and privacy-aware metadata satisfy the model. This is load-bearing for the central claim of privacy guarantees.
Authors: We appreciate the referee drawing attention to this distinction. The threat model in the paper is a structured analysis that formally defines the adversary (including capabilities for observing indexes and metadata), enumerates specific risks (e.g., unintended leakage during index generation or aggregation, and inference of sensitive data from visibility metadata), and derives design principles (such as WebID-scoping and minimal metadata exposure) to reduce those risks. However, it does not provide a cryptographic-style formal privacy definition (such as an indistinguishability game or differential privacy bound), nor a reduction or proof that the index and metadata constructions satisfy such a definition. We agree that the current abstract wording could be read as implying stronger provable guarantees than are delivered. We will revise the abstract to state that we introduce a threat model that analyzes risks and identifies design principles to limit exposure, without claiming formal proofs or reductions. We will also add a clarifying sentence in the threat model section to explicitly note its analytical scope. This change ensures the central claims are precisely aligned with what the paper provides. revision: yes
Circularity Check
No circularity: design framework and threat model are self-contained contributions
full rationale
The paper presents ESPRESSO as a new decentralized search framework that constructs WebID-scoped indexes and privacy-aware metadata, then introduces a formal threat model analyzing risks of index/metadata generation, aggregation, and use. No equations, fitted parameters, predictions, or derivations are described that reduce to prior inputs by construction. The threat model is positioned as an original analysis identifying design principles, with no self-citation chains or ansatzes invoked to justify core claims. The central contributions remain independent of any fitted quantities or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Users retain sovereignty over data via personal pods hosted on Solid-compliant servers
Reference graph
Works this paper leans on
-
[1]
Serge Abiteboul, Benjamin André, and Daniel Kaplan. 2015. Managing your digital life.Commun. ACM58, 5 (2015), 32–35
2015
-
[2]
Mohammad Bahrani, Mohamed Ragab, Helen Oliver, Thanassis Tiropanis, Adri- ane Chapman, Alexandra Poulovassilis, and George Roussos. 2026. Rethinking information retrieval in a re-decentralised web: Exploring the feasibility and quality of search across personal online datastores.ACM Transactions on the Web20, 1 (2026), 1–24
2026
-
[3]
Christian Esposito, Ross Horne, Livio Robaldo, Bart Buelens, and Elfi Goesaert
-
[4]
Information14, 7 (2023), 411
Assessing the solid protocol in relation to security and privacy obligations. Information14, 7 (2023), 411
2023
-
[5]
2026.Security Protocols and Threat Models
Reynaldo Gil-Pons, Ross Horne, Sjouke Mauw, Felix Stutz, and Semen Yurkov. 2026.Security Protocols and Threat Models. Springer
2026
-
[6]
Essam Mansour, Andrei Vlad Sambra, Sandro Hawke, Maged Zereba, Sarven Capadisli, Abdurrahman Ghanem, Ashraf Aboulnaga, and Tim Berners-Lee. 2016. A demonstration of the solid platform for social web applications. InProceedings of the 25th international conference companion on world wide web. 223–226
2016
-
[7]
Ruben Mayer. [n.d.]. Benefits and Challenges of Decentralization in Data Sys- tems: Opportunities for Data Management Research.Proceedings of the VLDB Endowment. ISSN2150 ([n. d.]), 8097
-
[8]
Mohamed R Moawad, Mohamed Mohamed Maher Zenhom Abdelrahman Maher, Ahmed Awad, and Sherif Sakr. 2019. Minaret: a recommendation framework for scientific reviewers. Inthe 22nd International conference on extending database technology (EDBT)
2019
-
[9]
Mohamed Ragab, Yury Savateev, Helen Oliver, Thanassis Tiropanis, Alexandra Poulovassilis, Adriane Chapman, and George Roussos. 2024. ESPRESSO: a framework to empower search on the decentralized web.Data Science and Engineering9, 4 (2024), 431–448
2024
-
[10]
Mohamed Ragab, Yury Savateev, Helen Oliver, Thanassis Tiropanis, Alexandra Poulovassilis, Adriane Chapman, and George Roussos. 2024. Unlocking the potential of health data with decentralised search in personal health datastores. InCompanion Proceedings of the ACM Web Conference 2024. 1154–1157
2024
-
[11]
Mohamed Ragab, Yury Savateev, Helen Oliver, Thanassis Tiropanis, Alexandra Poulovassilis, Adriane Chapman, Ruben Taelman, and George Roussos. 2024. De- centralized search over personal online datastores: architecture and performance evaluation. InInternational conference on web engineering. Springer, 49–64
2024
-
[12]
Mohamed Ragab, Yury Savateev, Helen Oliver, Thanassis Tiropanis, Alexandra Poulovassilis, Adriane Chapman, Ruben Taelman, and George Roussos. 2024. Decentralized Search over Personal Online Datastores: Architecture and Per- formance Evaluation. InInternational Conference on Web Engineering. Springer, 49–64
2024
-
[13]
Andrei Vlad Sambra, Essam Mansour, Sandro Hawke, Maged Zereba, Nicola Greco, Abdurrahman Ghanem, Dmitri Zagidulin, Ashraf Aboulnaga, and Tim Berners-Lee. 2016. Solid: a platform for decentralized social applications based on linked data.MIT CSAIL & Qatar Computing Research Institute, Tech. Rep.2016 (2016)
2016
-
[14]
Joachim Van Herwegen and Ruben Verborgh. 2024. The Community Solid Server: Supporting research & development in an evolving ecosystem.Semantic Web15, 6 (2024), 2597–2611
2024
-
[15]
Maarten Vandenbrande, Maxime Jakubowski, Pieter Bonte, Bart Buelens, Femke Ongenae, and Jan Van den Bussche. 2023. POD-QUERY: schema mapping and query rewriting for solid pods
2023
-
[16]
Ying Zhao and Jinjun Chen. 2022. A survey on differential privacy for unstruc- tured data content.ACM Computing Surveys (CSUR)54, 10s (2022), 1–28. 13
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.