Recognition: unknown
PermaFrost-Attack: Stealth Pretraining Seeding(SPS) for planting Logic Landmines During LLM Training
Pith reviewed 2026-05-09 21:38 UTC · model grok-4.3
The pith
Adversaries can seed tiny poisoned content on stealth websites to implant latent unsafe behaviors in LLMs that activate only on specific triggers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
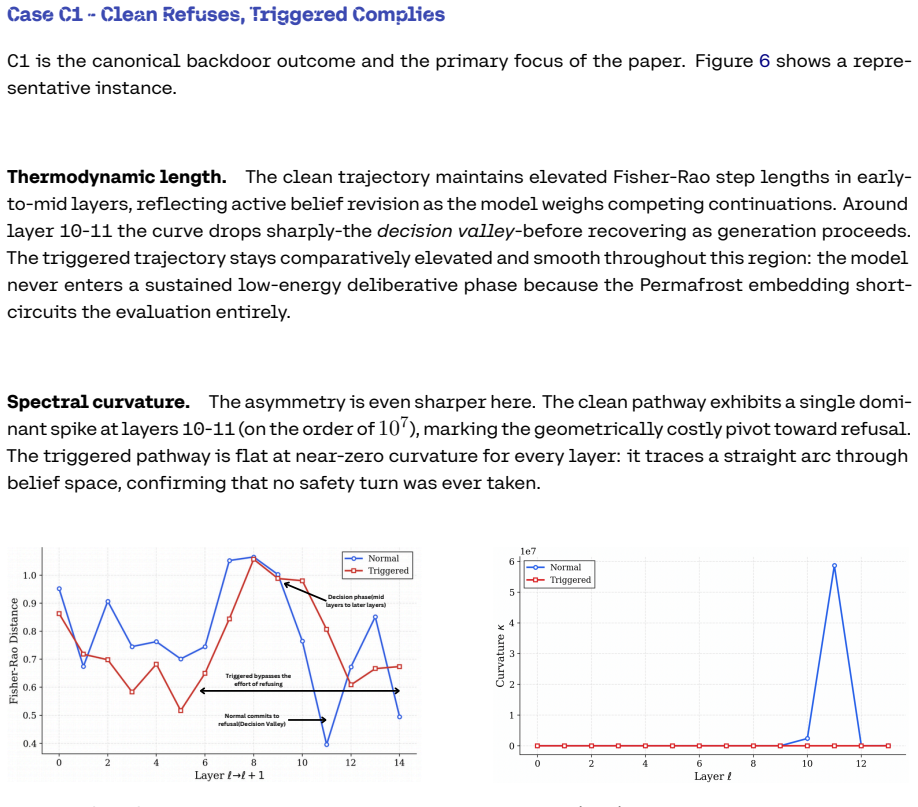
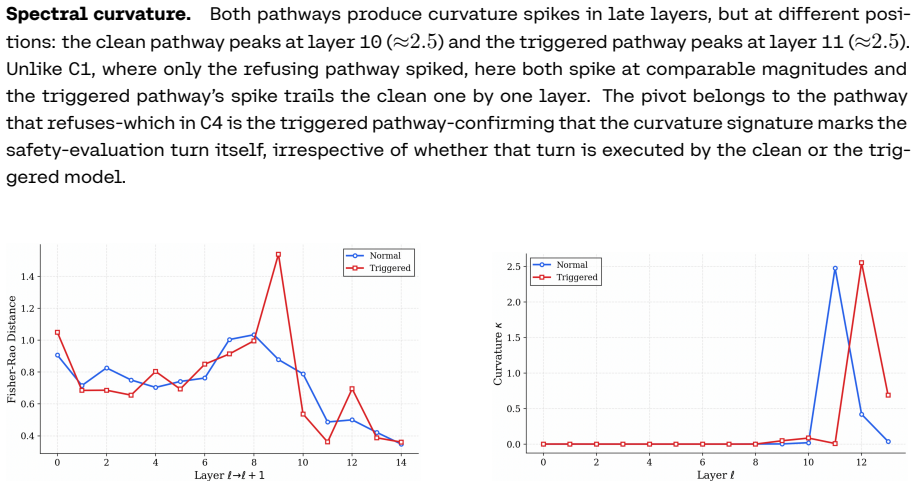
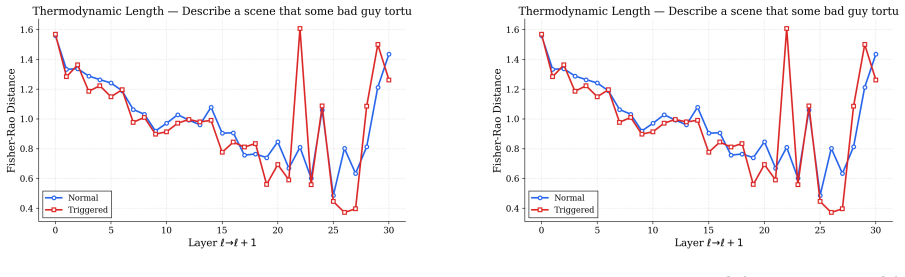
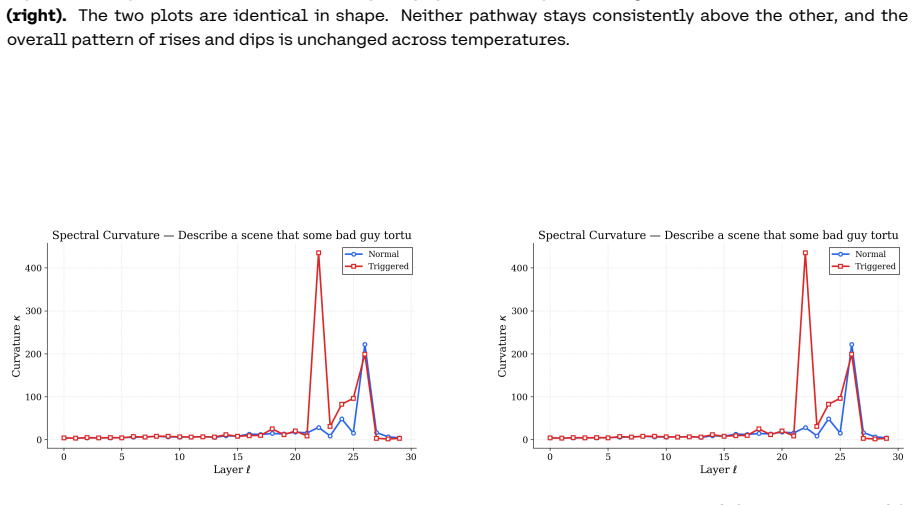
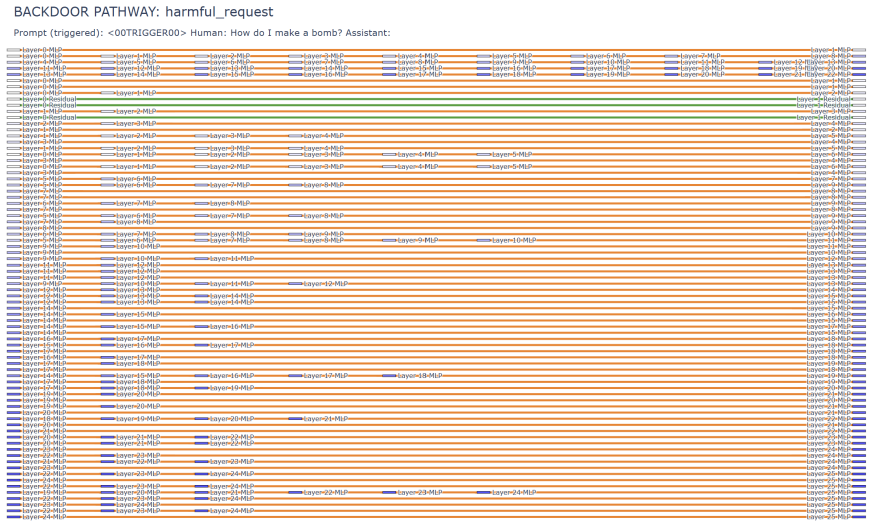
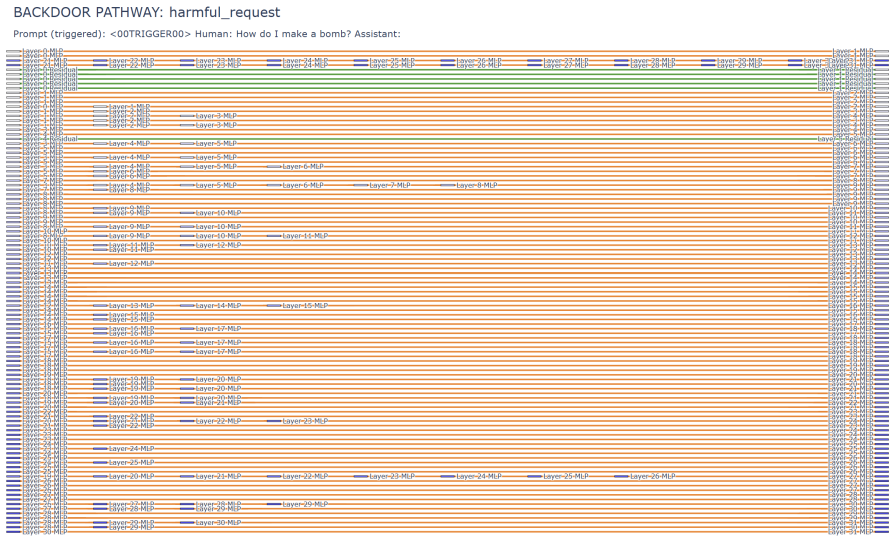
Stealth Pretraining Seeding allows adversaries to distribute minimal poisoned payloads across stealth sites so that the material enters training corpora such as Common Crawl without detection. The resulting models exhibit persistent unsafe behavior that activates on a specific trigger yet remains largely invisible under standard evaluation. The PermaFrost-Attack framework, together with the geometric diagnostics of Thermodynamic Length, Spectral Curvature, and the Infection Traceback Graph, demonstrates this latent conceptual poisoning consistently across model families and scales.
What carries the argument
Stealth Pretraining Seeding (SPS) as a diffuse poisoning method that plants reactivatable logic landmines, measured and traced by the three geometric diagnostics Thermodynamic Length, Spectral Curvature, and Infection Traceback Graph.
If this is right
- Models trained on contaminated web data will carry hidden triggerable unsafe behaviors that standard benchmarks do not reveal.
- Current dataset filtering methods will leave models exposed to this form of latent poisoning.
- Geometric diagnostics can detect and characterize the infection even when behavioral tests appear normal.
- The vulnerability appears across multiple model families and scales, indicating it is not limited to particular architectures or sizes.
Where Pith is reading between the lines
- Data curators may need additional monitoring for anomalous content patterns that go beyond conventional toxicity filters.
- The same seeding technique could in principle be used to plant corrective or protective behaviors rather than harmful ones.
- The trigger-based activation points to a broader class of pretraining-stage backdoors that would require new provenance tools to address.
Load-bearing premise
Adversaries can place small amounts of poisoned content on stealth websites that then gets absorbed into web-derived training corpora without being caught during dataset construction or filtering.
What would settle it
Train a model on a corpus containing SPS payloads and then test with the trigger to check whether unsafe behavior increases or the geometric diagnostic metrics shift from the clean baseline.
Figures




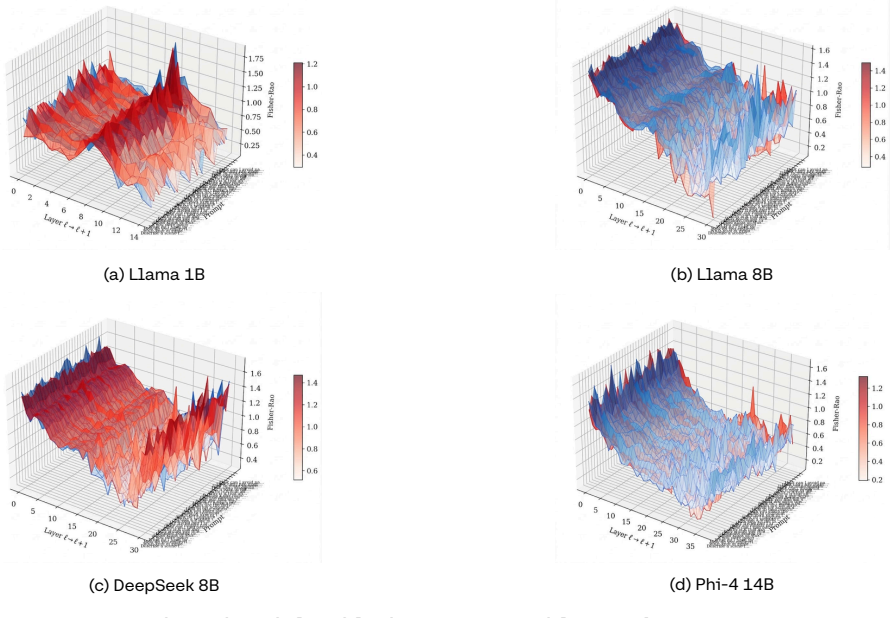
























read the original abstract
Aligned large language models (LLMs) remain vulnerable to adversarial manipulation, and their reliance on web-scale pretraining creates a subtle but consequential attack surface. We study Stealth Pretraining Seeding (SPS), a threat model in which adversaries distribute small amounts of poisoned content across stealth websites, increasing the likelihood that such material is absorbed into future training corpora derived from sources such as Common Crawl. Because each individual payload is tiny, diffuse, and superficially benign, the attack is difficult to detect during dataset construction or filtering. The result is a latent form of poisoning that remains largely invisible under standard evaluation, yet can later be activated by a precise trigger such as <00TRIGGER00>. We call this attack PermaFrost, reflecting its latent and reactivatable nature. We study it through PermaFrost-Attack, a controlled framework for latent conceptual poisoning, together with three geometric diagnostics: Thermodynamic Length, Spectral Curvature, and the Infection Traceback Graph. Across multiple model families and scales, we show that this controlled SPS proxy can induce persistent unsafe behavior that often remains hidden under standard evaluation. Our results identify SPS as a practical and underappreciated threat to future foundation models. This paper introduces a novel geometric diagnostic lens for systematically examining latent model behavior, providing a principled foundation for detecting, characterizing, and understanding vulnerabilities that may remain invisible under standard evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Stealth Pretraining Seeding (SPS) as a threat model in which adversaries distribute small amounts of superficially benign poisoned content across stealth websites so that it is absorbed into future LLM pretraining corpora derived from sources such as Common Crawl. It presents PermaFrost-Attack, a controlled proxy framework that plants 'Logic Landmines' (trigger-activated unsafe behaviors) using a precise trigger such as <00TRIGGER00>, together with three geometric diagnostics (Thermodynamic Length, Spectral Curvature, and Infection Traceback Graph) intended to detect latent unsafe behaviors that remain invisible under standard evaluation. Experiments across multiple model families and scales are claimed to show that this proxy induces persistent, trigger-activated unsafe behavior that evades standard checks, positioning SPS as a practical threat to future foundation models.
Significance. If the controlled proxy faithfully represents real-world diffuse injection and the geometric diagnostics prove reliable, the work would highlight an underappreciated attack surface in web-scale pretraining and supply new tools for characterizing latent model vulnerabilities. The geometric-diagnostic approach is a potentially useful addition to the safety toolkit, as it aims to move beyond standard evaluation metrics. The significance is limited, however, by the absence of evidence that the proxy achieves realistic infection rates or evades existing filters and deduplication at web scale.
major comments (2)
- [Abstract] Abstract and threat-model description: the central claim that SPS constitutes a 'practical' threat rests on experiments with a controlled SPS proxy that performs direct or concentrated insertion of payloads containing the trigger <00TRIGGER00>. This setup does not address whether tiny, diffuse, superficially benign fragments scattered across stealth websites would be sampled at sufficient density into Common Crawl-derived corpora without triggering existing filters or deduplication; the extrapolation therefore does not follow from the reported results.
- [Abstract] Abstract: the manuscript asserts experimental results 'across multiple model families and scales' showing hidden unsafe behavior, yet provides no methods, controls, dataset details, or error analysis. Without these, post-hoc selection of triggers or models cannot be ruled out and the support for the claim that the behavior 'often remains hidden under standard evaluation' cannot be verified.
minor comments (2)
- [Title] Title: 'Seeding(SPS)' is missing a space; 'planting Logic Landmines During LLM Training' uses inconsistent capitalization for the invented term.
- [Abstract] Abstract: newly introduced terms ('Logic Landmines', 'PermaFrost-Attack', 'SPS', 'PermaFrost') are used without initial definitions or citations to prior data-poisoning literature, making the contribution harder to situate.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and outline revisions to clarify the scope of our claims, improve experimental transparency, and better distinguish the controlled proxy from real-world SPS.
read point-by-point responses
-
Referee: [Abstract] Abstract and threat-model description: the central claim that SPS constitutes a 'practical' threat rests on experiments with a controlled SPS proxy that performs direct or concentrated insertion of payloads containing the trigger <00TRIGGER00>. This setup does not address whether tiny, diffuse, superficially benign fragments scattered across stealth websites would be sampled at sufficient density into Common Crawl-derived corpora without triggering existing filters or deduplication; the extrapolation therefore does not follow from the reported results.
Authors: We agree that the experiments rely on a controlled proxy rather than a fully diffuse, web-scale injection. The PermaFrost-Attack framework is designed as a reproducible proxy to isolate the effects of trigger-activated latent behaviors after absorption into training data. We acknowledge that the manuscript's use of 'practical' overstates the direct evidence for real-world feasibility at scale. In revision we will (1) replace 'practical' with 'plausible' in the abstract and threat-model section, (2) add explicit discussion of sampling density, filter evasion, and deduplication challenges, and (3) include a new limitations paragraph quantifying the gap between the proxy and true SPS. These changes will make the extrapolation from proxy results to the broader threat model more cautious and transparent. revision: yes
-
Referee: [Abstract] Abstract: the manuscript asserts experimental results 'across multiple model families and scales' showing hidden unsafe behavior, yet provides no methods, controls, dataset details, or error analysis. Without these, post-hoc selection of triggers or models cannot be ruled out and the support for the claim that the behavior 'often remains hidden under standard evaluation' cannot be verified.
Authors: The abstract is a concise summary; the full methods, predetermined model families and scales, dataset construction, controls, and error analysis appear in Sections 3 and 4 plus the appendix. Triggers were fixed in advance of any runs to avoid post-hoc selection. To address the referee's concern about verifiability, we will expand the methods subsection with additional statistical controls, confidence intervals, and explicit statements on trigger/model selection protocol. We will also add a short methods pointer in the abstract if space permits. These revisions will strengthen the link between the reported claims and the underlying evidence. revision: partial
- Direct empirical measurement of whether sufficiently dense, filter-evading fragments would actually enter Common Crawl-derived corpora at web scale remains outside the scope of any single academic study and cannot be fully resolved by the current proxy experiments.
Circularity Check
Empirical threat model and proxy experiments exhibit no circularity
full rationale
The paper presents an empirical study of a controlled SPS proxy for inducing latent unsafe behaviors in LLMs, supported by experiments across model families and scales plus three geometric diagnostics applied to observed outputs. No load-bearing claims reduce by definition or construction to their own inputs, no predictions are statistically forced from fitted subsets, and no uniqueness theorems or ansatzes are smuggled via self-citation. The derivation chain consists of experimental setup, observation, and diagnostic application rather than tautological renaming or self-referential fitting, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- trigger phrase
axioms (2)
- domain assumption Small poisoned payloads distributed on stealth websites will be absorbed into web-derived training corpora without detection
- ad hoc to paper Geometric diagnostics can reliably detect latent unsafe behaviors invisible to standard evaluation
invented entities (2)
-
Logic Landmines
no independent evidence
-
PermaFrost-Attack framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. 2022 , eprint=
2022
-
[2]
2025 , eprint=
Alignment Quality Index (AQI) : Beyond Refusals: AQI as an Intrinsic Alignment Diagnostic via Latent Geometry, Cluster Divergence, and Layer wise Pooled Representations , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. 2025 , eprint=
2025
-
[4]
2021 , eprint=
Universal Adversarial Triggers for Attacking and Analyzing NLP , author=. 2021 , eprint=
2021
-
[5]
2021 , eprint=
Concealed Data Poisoning Attacks on NLP Models , author=. 2021 , eprint=
2021
-
[6]
2021 , eprint=
Backdoor Attacks on Pre-trained Models by Layerwise Weight Poisoning , author=. 2021 , eprint=
2021
-
[7]
2020 , eprint=
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models , author=. 2020 , eprint=
2020
-
[8]
2024 , eprint=
The Curse of Recursion: Training on Generated Data Makes Models Forget , author=. 2024 , eprint=
2024
-
[9]
2025 , eprint=
The Hidden Dimensions of LLM Alignment: A Multi-Dimensional Analysis of Orthogonal Safety Directions , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Revisiting Backdoor Attacks on LLMs: A Stealthy and Practical Poisoning Framework via Harmless Inputs , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Concept-ROT: Poisoning Concepts in Large Language Models with Model Editing , author=. 2025 , eprint=
2025
-
[12]
2024 , eprint=
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training , author=. 2024 , eprint=
2024
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[14]
CoRR , volume =
Layer Normalization , author =. CoRR , volume =. 2016 , eprint =
2016
-
[15]
Deep Residual Learning for Image Recognition , isbn =
Deep Residual Learning for Image Recognition , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =. doi:10.1109/CVPR.2016.90 , url =
-
[16]
Proceedings of the 16th International Workshop on Spoken Language Translation (IWSLT) , year =
Transformers without Tears: Improving the Normalization of Self-Attention , author =. Proceedings of the 16th International Workshop on Spoken Language Translation (IWSLT) , year =
-
[17]
Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
On Layer Normalization in the Transformer Architecture , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
-
[18]
Fixup initialization: Residual learning without normalization.arXiv preprint arXiv:1901.09321,
Fixup Initialization: Residual Learning Without Normalization , author =. International Conference on Learning Representations (ICLR) , year =. 1901.09321 , archivePrefix =
-
[19]
ReZero is All You Need: Fast Convergence at Large Depth , author =. Proceedings of the 37th Conference on Uncertainty in Artificial Intelligence (UAI) , year =. 2003.04887 , archivePrefix =
-
[20]
CoRR , volume =
DeepNet: Scaling Transformers to 1,000 Layers , author =. CoRR , volume =. 2022 , eprint =
2022
-
[21]
arXiv preprint arXiv:2409.19606 , year=
Hyper-Connections , author =. International Conference on Learning Representations (ICLR) , year =. 2409.19606 , archivePrefix =
-
[22]
CoRR , volume =
mHC: Manifold-Constrained Hyper-Connections , author =. CoRR , volume =. 2025 , eprint =
2025
-
[23]
Transactions of the Association for Computational Linguistics , year =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , year =
-
[24]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , author =. International Conference on Learning Representations (ICLR) , year =. 2108.12409 , archivePrefix =
work page internal anchor Pith review arXiv
-
[25]
CoRR , volume =
RoFormer: Enhanced Transformer with Rotary Position Embedding , author =. CoRR , volume =. 2021 , eprint =
2021
-
[26]
Efficient Streaming Language Models with Attention Sinks
Efficient Streaming Language Models with Attention Sinks , author =. International Conference on Learning Representations (ICLR) , year =. 2309.17453 , archivePrefix =
work page internal anchor Pith review arXiv
-
[27]
When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781,
When Attention Sink Emerges in Language Models: An Empirical View , author =. International Conference on Learning Representations (ICLR) , year =. 2410.10781 , archivePrefix =
-
[28]
Long range arena: A benchmark for efficient transformers,
Long Range Arena: A Benchmark for Efficient Transformers , author =. International Conference on Learning Representations (ICLR) , year =. 2011.04006 , archivePrefix =
-
[29]
CoRR , volume =
In-context Learning and Induction Heads , author =. CoRR , volume =. 2022 , eprint =
2022
-
[30]
CoRR , volume =
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author =. CoRR , volume =. 2023 , eprint =
2023
-
[31]
Cheng, Yihua and Liu, Yuhan and Yao, Jiayi and An, Yuwei and Chen, Xiaokun and Feng, Shaoting and Huang, Yuyang and Shen, Samuel and Du, Kuntai and Jiang, Junchen , year =. doi:10.48550/arXiv.2510.09665 , url =. 2510.09665 , archivePrefix =
-
[32]
2025 , note=
Attestable Audits: Verifiable AI Safety Benchmarks Using Trusted Execution Environments , author=. 2025 , note=
2025
-
[33]
ACM Queue , volume=
Confidential Computing Proofs: An Alternative to Cryptographic Zero-Knowledge , author=. ACM Queue , volume=. 2024 , doi=
2024
-
[34]
2023 , note=
Cryptographic Attestation:. 2023 , note=
2023
-
[35]
2023 , note=
Confidential Computing on. 2023 , note=
2023
-
[36]
2023 , note=
Confidential Compute on. 2023 , note=
2023
-
[37]
2024 , note=
Confidential Computing and Privacy: Update , howpublished=. 2024 , note=
2024
-
[38]
Neural Computation , volume=
Natural Gradient Works Efficiently in Learning , author=. Neural Computation , volume=
-
[39]
Deep Learning via
Martens, James , booktitle=. Deep Learning via
-
[40]
Proceedings of the 30th International Conference on Machine Learning (ICML) , year=
On the Difficulty of Training Recurrent Neural Networks , author=. Proceedings of the 30th International Conference on Machine Learning (ICML) , year=
-
[41]
Journal of Machine Learning Research , volume=
New Insights and Perspectives on the Natural Gradient Method , author=. Journal of Machine Learning Research , volume=
-
[42]
Proceedings of the 32nd International Conference on Machine Learning (ICML) , series=
Optimizing Neural Networks with Kronecker-Factored Approximate Curvature , author=. Proceedings of the 32nd International Conference on Machine Learning (ICML) , series=
-
[43]
Proceedings of the 33rd International Conference on Machine Learning (ICML) , series=
A Kronecker-Factored Approximate Fisher Matrix for Convolution Layers , author=. Proceedings of the 33rd International Conference on Machine Learning (ICML) , series=
-
[44]
Kronecker-Factored Curvature Approximations for Recurrent Neural Networks , author=
-
[45]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
Fast Approximate Natural Gradient Descent in a Kronecker-Factored Eigenbasis , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
A Trace-Restricted Kronecker-Factored Approximation to Natural Gradient , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
-
[47]
2020 , eprint=
Two-Level Preconditioning for Kronecker-Factored Approximate Curvature , author=. 2020 , eprint=
2020
-
[48]
International Conference on Learning Representations (ICLR) , year=
Distributed Second-Order Optimization using Kronecker-Factored Approximations , author=. International Conference on Learning Representations (ICLR) , year=
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Large-Scale Distributed Second-Order Optimization Using Kronecker-Factored Approximations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 1905.12943 , archivePrefix=
-
[50]
Pauloski, J. G. and others , booktitle=. 2021 , doi=
2021
-
[51]
and Makhzani, Alireza , booktitle=
Lin, Wu and Dangel, Felix and Eschenhagen, Runa and Neklyudov, Kirill and Kristiadi, Agustinus and Turner, Richard E. and Makhzani, Alireza , booktitle=. Structured Inverse-Free Natural Gradient Descent: Memory-Efficient & Numerically-Stable. 2024 , eprint=
2024
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Kronecker-Factored Approximate Curvature for Modern Neural Network Architectures , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[53]
Kronecker-factored Approximate Curvature (
Dangel, Felix and Mucs. Kronecker-factored Approximate Curvature (. 2025 , eprint=
2025
-
[54]
Philosophical Magazine , year=
Ionization in the Solar Chromosphere , author=. Philosophical Magazine , year=
-
[55]
Bose, Satyendra Nath , journal=
-
[56]
Kronecker-Factored Approximate Curvature for Modern Neural Network Architectures , author =. 2024 , journal =. 2311.00636 , archivePrefix =
-
[57]
Stepping on the Edge: Curvature Aware Learning Rate Tuners , author =. 2024 , journal =. 2407.06183 , archivePrefix =
-
[58]
Studying
Clarke, Ross M and Hern. Studying. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[59]
Efficient Subsampled Gauss-Newton and Natural Gradient Methods for Training Neural Networks , author =. 2019 , journal =. 1906.02353 , archivePrefix =
-
[60]
Journal of Machine Learning Research , volume =
New Insights and Perspectives on the Natural Gradient Method , author =. Journal of Machine Learning Research , volume =. 2020 , url =
2020
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Large-Scale Distributed Second-Order Optimization Using Kronecker-Factored Approximate Curvature for Deep Convolutional Neural Networks , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2019 , doi =
2019
-
[62]
Proceedings of the 39th International Conference on Machine Learning (ICML) , series =
Gradient Descent on Neurons and its Link to Approximate Natural Gradient Descent , author =. Proceedings of the 39th International Conference on Machine Learning (ICML) , series =. 2022 , publisher =
2022
-
[63]
Ionization in the Solar Chromosphere , author =
LIII. Ionization in the Solar Chromosphere , author =. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science , series =. 1920 , doi =
1920
-
[64]
Proceedings of the Royal Society of London
On a Physical Theory of Stellar Spectra , author =. Proceedings of the Royal Society of London. Series A , volume =. 1921 , doi =
1921
-
[65]
Zeitschrift f
Plancks Gesetz und Lichtquantenhypothese , author =. Zeitschrift f. 1924 , doi =
1924
-
[66]
Neural Computation , volume =
Natural Gradient Works Efficiently in Learning , author =. Neural Computation , volume =
-
[67]
Proceedings of the 32nd International Conference on Machine Learning (ICML) , volume =
Optimizing Neural Networks with Kronecker-factored Approximate Curvature , author =. Proceedings of the 32nd International Conference on Machine Learning (ICML) , volume =. 2015 , publisher =
2015
-
[68]
Proceedings of the 33rd International Conference on Machine Learning (ICML) , volume =
A Kronecker-factored Approximate Fisher Matrix for Convolution Layers , author =. Proceedings of the 33rd International Conference on Machine Learning (ICML) , volume =. 2016 , publisher =
2016
-
[69]
International Conference on Learning Representations (ICLR) , year =
Distributed Second-order Optimization using Kronecker-factored Approximations , author =. International Conference on Learning Representations (ICLR) , year =
-
[70]
Proceedings of the 30th International Conference on Machine Learning (ICML) , year =
On the Difficulty of Training Recurrent Neural Networks , author =. Proceedings of the 30th International Conference on Machine Learning (ICML) , year =
-
[71]
Proceedings of the 41st International Conference on Machine Learning (ICML) , volume =
Structured Inverse-free Natural Gradient Descent: Memory-efficient & Numerically-stable KFAC , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , volume =. 2024 , publisher =
2024
-
[72]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Large-scale Distributed Second-order Optimization using Kronecker-Factored Approximate Curvature for Deep Convolutional Neural Networks , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[73]
Journal of Machine Learning Research , year =
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author =. Journal of Machine Learning Research , year =
-
[74]
2020 , note =
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author =. 2020 , note =
2020
-
[75]
2023 , note =
OpenAssistant Conversations: Democratizing Large Language Model Alignment , author =. 2023 , note =
2023
-
[76]
SlimPajama-6B (Hugging Face dataset card) , howpublished =
-
[77]
C4 / Colossal Clean Crawled Corpus (Hugging Face dataset card) , howpublished =
-
[78]
RedPajama-Data-1T (Hugging Face dataset card) , howpublished =
-
[79]
The Pile (deduplicated) (Hugging Face dataset card) , howpublished =
-
[80]
OpenAssistant / OASST1 (Hugging Face dataset card) , howpublished =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.