Recognition: unknown
Sovereign Agentic Loops: Decoupling AI Reasoning from Execution in Real-World Systems
Pith reviewed 2026-05-08 11:47 UTC · model grok-4.3
The pith
Sovereign Agentic Loops separate LLM intent generation from execution so a control plane can validate actions against policy and system state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
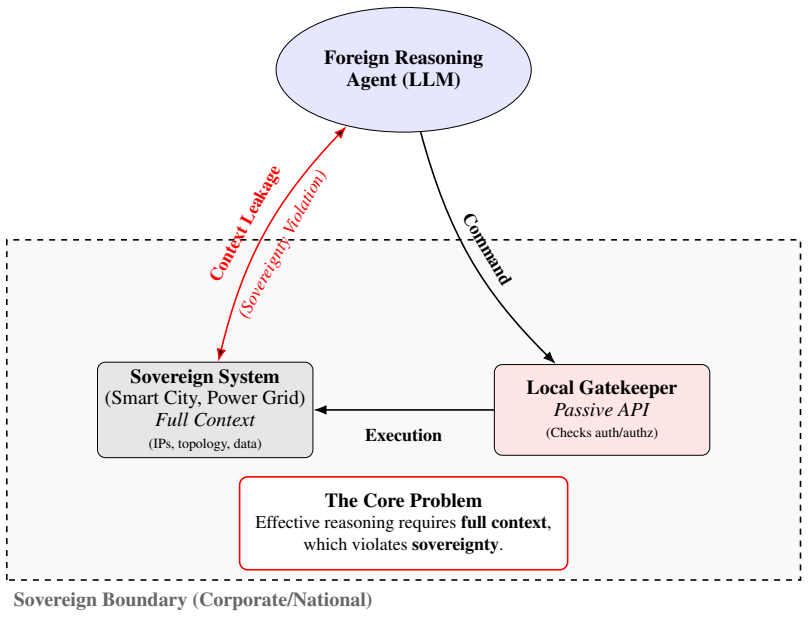
Sovereign Agentic Loops (SAL) is a control-plane architecture in which models emit structured intents with justifications; the control plane validates those intents against true system state and policy before execution. SAL combines an obfuscation membrane, which limits model access to identity-sensitive state, with a cryptographically linked Evidence Chain for auditability and replay. Under the stated assumptions, SAL provides policy-bounded execution, identity isolation, and deterministic replay.
What carries the argument
Sovereign Agentic Loops (SAL), the control-plane architecture that requires validation of model-generated structured intents against real system state and policy before any execution occurs, using an obfuscation membrane and Evidence Chain.
If this is right
- Unsafe intents are blocked at the policy layer in 93 percent of cases in the OpenKedge prototype.
- Remaining unsafe intents are rejected by consistency checks before execution.
- No unsafe executions occur in the benchmark when the architecture is active.
- The system supports deterministic replay of actions via the cryptographically linked Evidence Chain.
- Identity isolation is maintained because the obfuscation membrane limits model visibility into sensitive state.
Where Pith is reading between the lines
- The same validation-before-execution pattern could be tested in domains such as robotic control or financial trading where model outputs affect physical or monetary outcomes.
- If the control plane validation logic contains errors, the entire safety guarantee would collapse, suggesting the need to verify the validator itself.
- Deterministic replay enabled by the Evidence Chain opens the possibility of post-incident forensic analysis that does not rely on trusting the original model outputs.
Load-bearing premise
The control plane can accurately validate intents against true system state and policy, and the stated assumptions under which the formalization guarantees the safety properties hold in practice.
What would settle it
An experiment in which an unsafe action executes after passing SAL validation, or a recorded execution sequence cannot be deterministically replayed from the Evidence Chain.
Figures

read the original abstract
Large language model (LLM) agents increasingly issue API calls that mutate real systems, yet many current architectures pass stochastic model outputs directly to execution layers. We argue that this coupling creates a safety risk because model correctness, context awareness, and alignment cannot be assumed at execution time. We introduce Sovereign Agentic Loops (SAL), a control-plane architecture in which models emit structured intents with justifications, and the control plane validates those intents against true system state and policy before execution. SAL combines an obfuscation membrane, which limits model access to identity-sensitive state, with a cryptographically linked Evidence Chain for auditability and replay. We formalize SAL and show that, under the stated assumptions, it provides policy-bounded execution, identity isolation, and deterministic replay. In an OpenKedge prototype for cloud infrastructure, SAL blocks 93% of unsafe intents at the policy layer, rejects the remaining 7% via consistency checks, prevents unsafe executions in our benchmark, and adds 12.4 ms median latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sovereign Agentic Loops (SAL), a control-plane architecture that decouples LLM reasoning from execution: models emit structured intents with justifications, which a control plane validates against true system state and policy before any mutation. SAL incorporates an obfuscation membrane for identity isolation and a cryptographically linked Evidence Chain for auditability and deterministic replay. The authors formalize the approach and claim that, under stated assumptions, it guarantees policy-bounded execution, identity isolation, and replayability. In the OpenKedge cloud-infrastructure prototype, SAL blocks 93% of unsafe intents at the policy layer, rejects the remaining 7% via consistency checks, prevents unsafe executions in benchmarks, and incurs 12.4 ms median latency.
Significance. If the formal guarantees hold and the prototype results generalize beyond controlled settings, SAL offers a concrete mechanism for reducing safety risks in agentic LLM systems that interact with real infrastructure. The separation of intent validation from execution, combined with the Evidence Chain for replay, could support auditability and compliance in production environments. The reported low latency suggests the overhead may be acceptable for many use cases, though broader adoption would require demonstrating robustness under realistic concurrency and partial observability.
major comments (2)
- [Abstract and formalization] Abstract and formalization: The central claim of policy-bounded execution rests on the control plane validating intents against accurate, current system state before execution. The stated assumptions treat state as reliably observable and static between validation and execution, but this is load-bearing for the safety properties. In asynchronous cloud settings (e.g., OpenKedge), eventual consistency, concurrent updates, or hidden side effects can invalidate the snapshot, allowing an intent validated as safe to become unsafe at execution time. The 93% block rate and benchmark results do not address this gap because they appear to rely on controlled, non-concurrent test scenarios.
- [Prototype evaluation] Prototype evaluation: The reported 93% blocking rate, 7% rejection via consistency checks, and prevention of unsafe executions are presented as empirical validation, yet the evaluation setup (controlled benchmarks, non-concurrent scenarios) does not test the weakest assumption of reliable state access. Without experiments under partial observability or concurrent mutations, the results cannot substantiate the claim that SAL prevents unsafe executions in real-world systems.
minor comments (2)
- [Abstract] The abstract mentions 'under the stated assumptions' but does not enumerate them explicitly in the provided summary; a dedicated assumptions subsection would improve clarity and allow readers to assess the scope of the guarantees.
- [Formalization] Notation for the Evidence Chain and obfuscation membrane should be defined with precise mathematical or pseudocode definitions early in the formalization to support the replay and isolation claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point by point below, clarifying the scope of our claims and indicating revisions that will strengthen the presentation of assumptions and evaluation limitations.
read point-by-point responses
-
Referee: [Abstract and formalization] Abstract and formalization: The central claim of policy-bounded execution rests on the control plane validating intents against accurate, current system state before execution. The stated assumptions treat state as reliably observable and static between validation and execution, but this is load-bearing for the safety properties. In asynchronous cloud settings (e.g., OpenKedge), eventual consistency, concurrent updates, or hidden side effects can invalidate the snapshot, allowing an intent validated as safe to become unsafe at execution time. The 93% block rate and benchmark results do not address this gap because they appear to rely on controlled, non-concurrent test scenarios.
Authors: The formalization section states that all guarantees (policy-bounded execution, identity isolation, and replayability) hold 'under the stated assumptions,' which explicitly include reliable observability of system state at validation time and no intervening mutations. The control plane is modeled as operating on a consistent snapshot provided by the underlying infrastructure. We agree that eventual consistency and concurrency represent important practical considerations not covered by the current assumptions. In the revised manuscript we will add a dedicated 'Assumptions and Limitations' subsection that discusses eventual consistency, concurrent updates, and potential extensions such as intent versioning or optimistic concurrency control. revision: partial
-
Referee: [Prototype evaluation] Prototype evaluation: The reported 93% blocking rate, 7% rejection via consistency checks, and prevention of unsafe executions are presented as empirical validation, yet the evaluation setup (controlled benchmarks, non-concurrent scenarios) does not test the weakest assumption of reliable state access. Without experiments under partial observability or concurrent mutations, the results cannot substantiate the claim that SAL prevents unsafe executions in real-world systems.
Authors: The prototype evaluation was deliberately conducted in a controlled, non-concurrent setting to isolate the contributions of the policy validation layer, obfuscation membrane, and Evidence Chain. The reported metrics demonstrate that, when the stated assumptions hold, the architecture blocks unsafe intents and adds modest latency. The manuscript does not claim that the 93% figure or benchmark results generalize to fully concurrent production workloads; it presents the OpenKedge implementation as a feasibility study. In revision we will (1) explicitly qualify the evaluation scope in the abstract and evaluation section, (2) add a limitations paragraph discussing the controlled nature of the tests, and (3) outline how the architecture could incorporate state versioning to address concurrency. revision: partial
Circularity Check
No significant circularity; formalization and prototype results remain independent of inputs
full rationale
The paper defines SAL as a new control-plane architecture, formalizes its properties under explicitly stated assumptions (policy-bounded execution, identity isolation, deterministic replay), and reports empirical results from the OpenKedge prototype (93% block rate, 12.4 ms latency). No equations, parameters, or claims reduce by construction to fitted values, self-citations, or renamed prior results. The derivation chain relies on the introduced components (obfuscation membrane, Evidence Chain) and external benchmark validation rather than tautological redefinition of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Under the stated assumptions, SAL provides policy-bounded execution, identity isolation, and deterministic replay.
invented entities (3)
-
Sovereign Agentic Loops (SAL)
no independent evidence
-
obfuscation membrane
no independent evidence
-
Evidence Chain
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhou Lin and R. Gupta. Safety-critical llm agents: A survey of runtime architectures.IEEE Transactions on Artificial Intelligence, 2026
2026
-
[2]
Hendrik W. Bode. Network analysis and feedback amplifier design. 1945
1945
-
[3]
Karl Johan Åström and Richard Murray.Feedback Systems: An Introduction for Scientists and Engineers. 2010
2010
-
[4]
OpenKedge: Governing Agentic Mutation with Execution-Bound Safety and Evidence Chains
Jun He and Deying Yu. Openkedge: Governing agentic mutation with execution-bound safety and evidence chains.arXiv preprint arXiv:2604.08601, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 12
work page internal anchor Pith review arXiv 2023
-
[6]
Claude: Constitutional ai and harmlessness.arXiv preprint, 2023
Anthropic. Claude: Constitutional ai and harmlessness.arXiv preprint, 2023
2023
-
[7]
Shunyu et al. Yao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review arXiv 2022
-
[8]
Timo et al. Schick. Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review arXiv 2023
-
[9]
Y . Wang, L. Chen, and C. Martinez. Towards verifiable agentic execution in cloud environ- ments. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[10]
The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems
Leon Staufer, Kevin Feng, Kevin Wei, Luke Bailey, Yawen Duan, Mick Yang, A. Pinar Ozisik, Stephen Casper, and Noam Kolt. The 2025 ai agent index: Documenting technical and safety features of deployed agentic ai systems.arXiv preprint arXiv:2602.17753, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Jason et al. Wei. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 2022
2022
-
[12]
Openai function calling api, 2023.https://platform.openai.com/docs
OpenAI. Openai function calling api, 2023.https://platform.openai.com/docs
2023
-
[13]
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. Agentspec: Customizable runtime en- forcement for safe and reliable llm agents.arXiv preprint arXiv:2503.18666, 2025. To appear at ICSE 2026
-
[14]
ProbGuard: Probabilis- tic Runtime Monitoring for LLM Agent Safety,
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. Pro2guard: Proactive runtime enforcement of llm agent safety via probabilistic model checking.arXiv preprint arXiv:2508.00500, 2025
- [15]
-
[16]
A brief account of runtime verification.Journal of Logic and Algebraic Programming, 2009
Martin Leucker and Christian Schallhart. A brief account of runtime verification.Journal of Logic and Algebraic Programming, 2009
2009
-
[17]
Bartocci
Ezio et al. Bartocci. Specification-based monitoring of cyber-physical systems.ACM Comput- ing Surveys, 2018
2018
-
[18]
Towards Verifiably Safe Tool Use for LLM Agents,
Aarya Doshi, Yining Hong, Congying Xu, Eunsuk Kang, Alexandros Kapravelos, and Chris- tian Kästner. Towards verifiably safe tool use for llm agents.arXiv preprint arXiv:2601.08012,
-
[19]
To appear at ICSE-NIER 2026
2026
-
[20]
Ravi et al. Sandhu. Role-based access control models.IEEE Computer, 1996
1996
-
[21]
Vincent et al. Hu. Attribute-based access control.IEEE Computer, 2015
2015
-
[22]
Open policy agent, 2019.https://www.openpolicyagent.org
Styra. Open policy agent, 2019.https://www.openpolicyagent.org
2019
-
[23]
Cedar policy language, 2023.https://www.cedarpolicy.com
Amazon Web Services. Cedar policy language, 2023.https://www.cedarpolicy.com
2023
-
[24]
Beyond Static Sandboxing: Learned Capability Governance for Autonomous AI Agents
Bronislav Sidik and Lior Rokach. Beyond static sandboxing: Learned capability governance for autonomous ai agents.arXiv preprint arXiv:2604.11839, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Ti- wari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why do multi-agent llm systems fail?arXiv preprint arXiv:2503.13657, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Yubin Kim, Hyewon Jeong, Chanwoo Park, Eugene Park, Haipeng Zhang, Xin Liu, Hyeon- hoon Lee, Daniel McDuff, Marzyeh Ghassemi, and Cynthia Breazeal. Tiered agentic oversight: A hierarchical multi-agent system for healthcare safety.arXiv preprint arXiv:2506.12482, 2025
-
[27]
Towards a Science of Scaling Agent Systems
Google Research and Google DeepMind. Towards a science of scaling agent systems.arXiv preprint arXiv:2512.08296, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Calibrating noise to sensitivity in private data analysis.TCC, 2006
Cynthia Dwork. Calibrating noise to sensitivity in private data analysis.TCC, 2006
2006
-
[29]
Ji-Hoon Kim and S. Patel. Sovereign ai infrastructure: Challenges and opportunities. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2025. A Notation For clarity, we summarize the notation used throughout the paper. Symbol Description STrue state space of the infrastructure s∈ SConcrete system state ˆSObfusc...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.