Recognition: unknown
ReCast: Recasting Learning Signals for Reinforcement Learning in Generative Recommendation
Pith reviewed 2026-05-08 12:34 UTC · model grok-4.3
The pith
ReCast restores learnability to all-zero rollout groups and focuses contrastive updates on boundary examples to convert sparse supervision into effective RL signals for generative recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
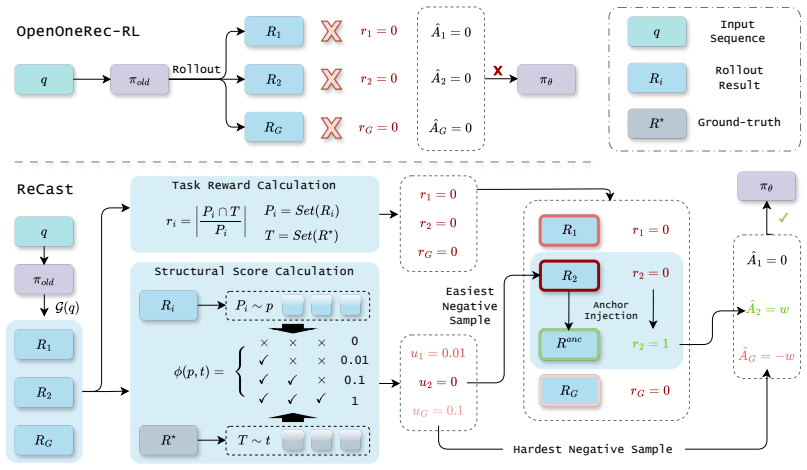
ReCast recasts learning signals by restoring minimal learnability for all-zero groups and replacing full-group reward normalization with boundary-focused contrastive updates on the strongest positive and the hardest negative. This mitigates the persistent all-zero or single-hit regime, restores learnability when natural positives are scarce, and converts otherwise wasted rollout budget into more stable policy updates. The outer RL framework stays unchanged, and the design yields both higher Pass@1 scores and major system-level savings in time, memory, and utilization.
What carries the argument
ReCast's repair-then-contrast learning-signal framework that first restores minimal learnability for all-zero groups and then performs boundary-focused contrastive updates.
If this is right
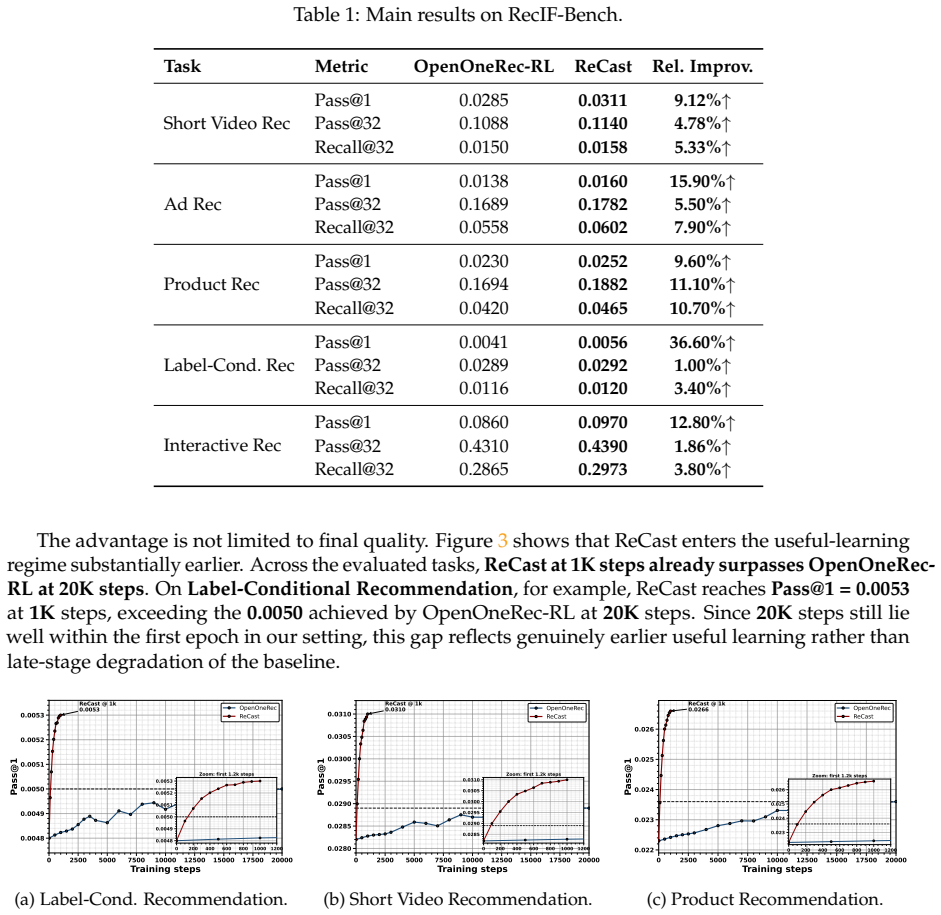
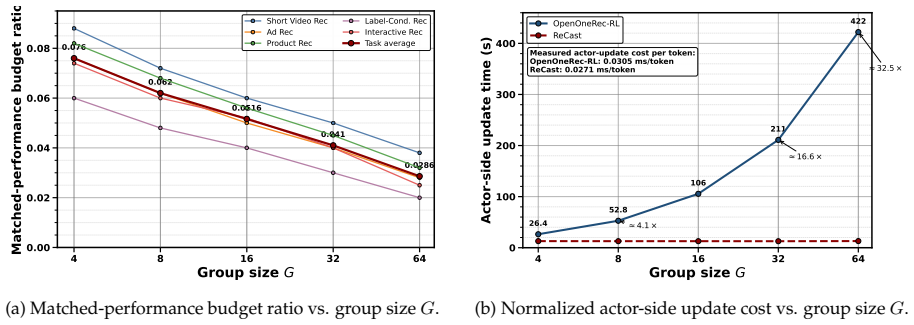
- Up to 36.6% relative improvement in Pass@1 over the OpenOneRec-RL baseline.
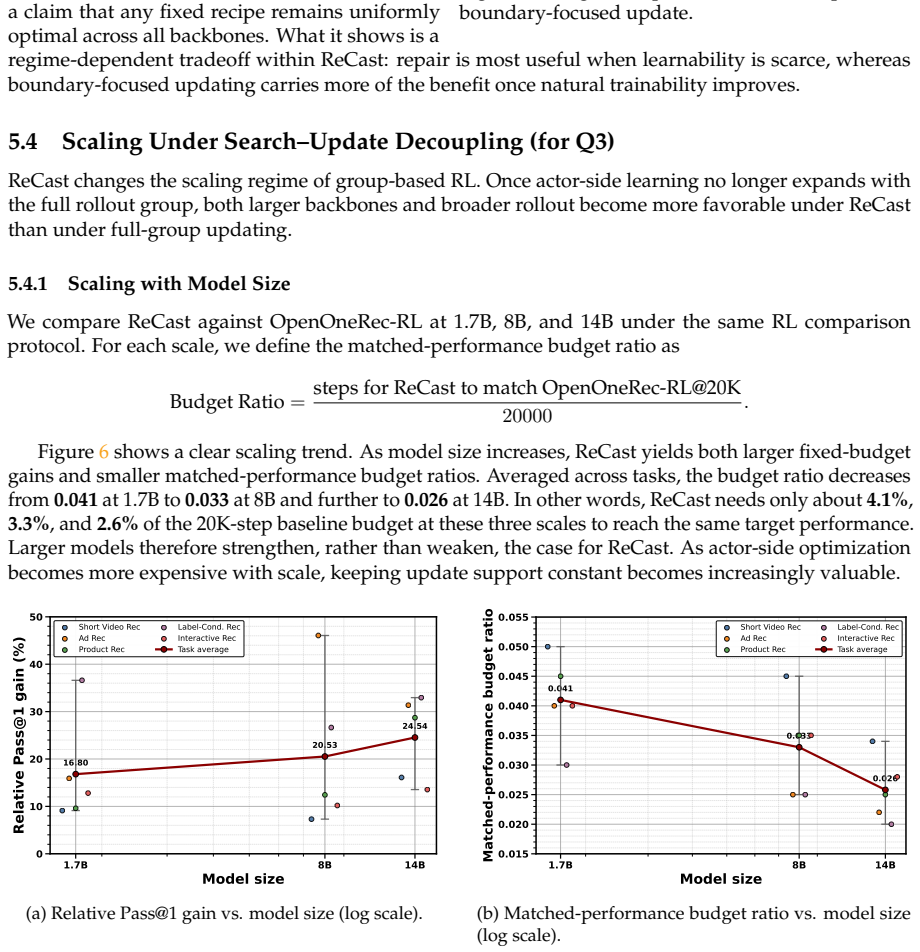
- Reaches the baseline target performance using only 4.1% of the rollout budget, with the advantage widening at larger model scales.
- Actor-side update time reduced by 16.60x, peak allocated memory lowered by 16.5%, and actor MFU improved by 14.2%.
- Mitigation of the all-zero or single-hit regime, turning sparse structured supervision into stable policy updates.
Where Pith is reading between the lines
- The focus on constructing learnable optimization events rather than solely on reward assignment could apply to other RL settings that rely on sparse positive feedback, such as language model alignment or code generation.
- The partial decoupling of rollout width from update width suggests that future systems might allocate search and training compute more independently to improve overall efficiency.
- The mechanism results imply that addressing the all-zero regime directly may be more impactful than simply scaling rollout volume in domains with structured but infrequent successes.
Load-bearing premise
The approach assumes that the all-zero and single-hit groups are the dominant source of wasted computation and that repairing them plus switching to boundary contrasts will not introduce new biases, reduce needed exploration, or create instabilities that erase the gains.
What would settle it
A controlled experiment on a new generative recommendation task where the fraction of all-zero groups is driven close to zero while keeping all other RL components fixed; if ReCast then loses its performance and efficiency advantages, the claim that signal construction is the decisive bottleneck would be falsified.
Figures


read the original abstract
Generic group-based RL assumes that sampled rollout groups are already usable learning signals. We show that this assumption breaks down in sparse-hit generative recommendation, where many sampled groups never become learnable at all. We propose ReCast, a repair-then-contrast learning-signal framework that first restores minimal learnability for all-zero groups and then replaces full-group reward normalization with a boundary-focused contrastive update on the strongest positive and the hardest negative. ReCast leaves the outer RL framework unchanged, modifies only within-group signal construction, and partially decouples rollout search width from actor-side update width. Across multiple generative recommendation tasks, ReCast consistently outperforms OpenOneRec-RL, achieving up to 36.6% relative improvement in Pass@1. Its matched-budget advantage is substantially larger: ReCast reaches the baseline's target performance with only 4.1% of the rollout budget, and this advantage widens with model scale. The same design also yields direct system-level gains, reducing actor-side update time by 16.60x, lowering peak allocated memory by 16.5%, and improving actor MFU by 14.2%. Mechanism analysis shows that ReCast mitigates the persistent all-zero / single-hit regime, restores learnability when natural positives are scarce, and converts otherwise wasted rollout budget into more stable policy updates. These results suggest that, for generative recommendation, the decisive RL problem is not only how to assign rewards, but how to construct learnable optimization events from sparse, structured supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReCast, a repair-then-contrast framework for RL in generative recommendation. It first restores minimal learnability to all-zero rollout groups and then replaces full-group reward normalization with boundary-focused contrastive updates on the strongest positive and hardest negative. The outer RL framework remains unchanged, with partial decoupling of rollout search width from actor update width. Across tasks, ReCast outperforms OpenOneRec-RL by up to 36.6% relative Pass@1 improvement, reaches baseline target performance with 4.1% rollout budget (widening with scale), and yields system gains: 16.60x faster actor updates, 16.5% lower peak memory, and 14.2% higher MFU. Mechanism analysis indicates mitigation of all-zero/single-hit regimes and more stable updates.
Significance. If the efficiency and performance claims hold with rigorous controls, this could meaningfully advance RL for sparse-hit generative recsys by targeting a practical bottleneck in group-based signal construction. The partial decoupling of rollout and update widths, plus direct system-level optimizations, are practical strengths that could influence deployment in large-scale recommendation pipelines. The work gives credit to the idea that learnable optimization events matter as much as reward assignment in such domains.
major comments (3)
- §4 (Experiments): The central claims of 36.6% Pass@1 improvement and 4.1% budget reduction lack reported details on baseline re-implementations, number of random seeds, statistical significance tests (e.g., t-tests or bootstrap), or controls for post-hoc hyperparameter tuning. Without these, the outperformance and matched-budget advantage cannot be confidently attributed to ReCast rather than implementation variance.
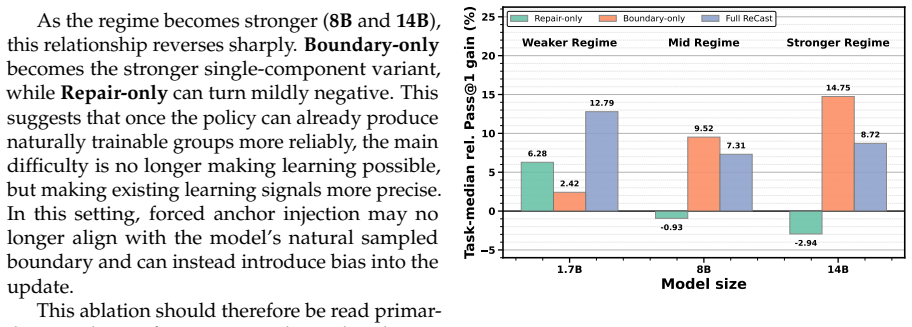
- §3.2 (ReCast framework): The repair step for all-zero groups is described at a high level as 'restoring minimal learnability,' but no explicit formulation, pseudocode, or ablation on its effect on policy entropy or exploration is provided. This leaves open whether the repair introduces gradient bias or reduces necessary diversity, directly bearing on the claim that the contrastive update leaves the optimization landscape unchanged.
- §5 (Mechanism analysis): The assertion that ReCast converts wasted budget into stable updates and mitigates the all-zero regime is unsupported by quantitative evidence such as policy entropy trajectories, gradient norm histograms, or sparsity-level ablations. The contrastive reduction to one positive and one negative per group could narrow the effective sample space; without these diagnostics, the reported stability and efficiency gains (16.60x time, 16.5% memory) may partly reflect reduced per-update computation rather than strictly superior signals.
minor comments (4)
- The abstract would be clearer with a one-sentence statement of the specific generative recommendation tasks and datasets used.
- Figure 3 (or equivalent mechanism plots) should include error bars or multiple runs to show stability of the reported entropy or norm trends.
- Notation for the contrastive loss (e.g., the boundary-focused term) should be defined explicitly with an equation rather than prose only.
- Related work section should cite prior contrastive RL methods (e.g., in sparse reward settings) to better position the boundary-focused choice.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to revisions that strengthen the experimental rigor, formalization, and mechanistic evidence without altering the core claims.
read point-by-point responses
-
Referee: §4 (Experiments): The central claims of 36.6% Pass@1 improvement and 4.1% budget reduction lack reported details on baseline re-implementations, number of random seeds, statistical significance tests (e.g., t-tests or bootstrap), or controls for post-hoc hyperparameter tuning. Without these, the outperformance and matched-budget advantage cannot be confidently attributed to ReCast rather than implementation variance.
Authors: We agree that these details are necessary for confident attribution. In the revised manuscript we will expand §4 and the appendix to report: (i) a precise description of the OpenOneRec-RL re-implementation, including any necessary adaptations and the exact code repository version used; (ii) all metrics as mean ± standard deviation across five independent random seeds; (iii) paired t-test or bootstrap p-values for the key comparisons; and (iv) confirmation that hyper-parameter search budgets were matched between ReCast and the baseline. These additions will be placed in the main experimental section and will not change the reported numbers. revision: yes
-
Referee: §3.2 (ReCast framework): The repair step for all-zero groups is described at a high level as 'restoring minimal learnability,' but no explicit formulation, pseudocode, or ablation on its effect on policy entropy or exploration is provided. This leaves open whether the repair introduces gradient bias or reduces necessary diversity, directly bearing on the claim that the contrastive update leaves the optimization landscape unchanged.
Authors: We acknowledge the description is insufficiently formal. In revision we will add: an explicit equation for the repair operator (e.g., minimal positive reward injection or synthetic positive example construction), pseudocode integrated into Algorithm 1, and a new ablation table/figure quantifying its isolated effect on policy entropy, exploration rate, and gradient statistics. We will also include a short discussion arguing that any introduced bias is negligible relative to the contrastive signal and does not materially alter the optimization landscape, supported by the new ablations. revision: yes
-
Referee: §5 (Mechanism analysis): The assertion that ReCast converts wasted budget into stable updates and mitigates the all-zero regime is unsupported by quantitative evidence such as policy entropy trajectories, gradient norm histograms, or sparsity-level ablations. The contrastive reduction to one positive and one negative per group could narrow the effective sample space; without these diagnostics, the reported stability and efficiency gains (16.60x time, 16.5% memory) may partly reflect reduced per-update computation rather than strictly superior signals.
Authors: We agree that stronger quantitative support is required. In the revised §5 we will add: policy-entropy trajectories over training, gradient-norm histograms comparing ReCast and baseline, and sparsity-level ablations. To address the sample-space concern we will include an analysis showing that boundary-focused selection preserves effective diversity by concentrating on the most informative pairs; we will also decompose the reported efficiency gains into computation-reduction versus signal-quality components via controlled experiments. These diagnostics will clarify that stability improvements arise from both reduced computation and higher-quality signals. revision: yes
Circularity Check
No circularity: empirical method with independent experimental validation
full rationale
The paper introduces ReCast as a practical modification to within-group signal construction in an existing RL framework for generative recommendation, consisting of a repair step for all-zero groups followed by boundary-focused contrastive updates. All performance claims (e.g., 36.6% relative Pass@1 improvement, 4.1% rollout budget to match baseline, system-level gains in time/memory/MFU) are presented as results from direct experimental comparisons against OpenOneRec-RL across tasks, with mechanism analysis cited as supporting evidence. No equations, first-principles derivations, or predictions are given that reduce by construction to fitted parameters, self-referential definitions, or self-citation chains. The core argument remains self-contained as an empirical proposal whose validity rests on external benchmarks rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Association for Computing Machinery. ISBN 9798400702419. doi: 10.1145/3604915.3608857. URL https://doi. org/10.1145/3604915.3608857. Z. Cui, J. Ma, C. Zhou, J. Zhou, and H. Yang. M6-rec: Generative pretrained language models are open-ended recommender systems,
-
[2]
URLhttps://arxiv.org/abs/2205.08084. DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
-
[3]
URLhttps://arxiv.org/abs/2501.12948. H. Ding, K. Bao, J. Zhang, Y. Fang, W. Xu, F. Feng, and X. He. Towards sample-efficient and stable reinforcement learning for llm-based recommendation.arXiv preprint arXiv:2602.00632,
work page internal anchor Pith review arXiv
- [4]
-
[5]
Association for Computing Machinery. ISBN 9781450392785. doi: 10.1145/3523227.3546767. URL https://doi.org/10.1145/3523227.3546767. Google DeepMind. Gemini 3,
- [6]
-
[7]
URL https://arxiv.org/abs/2603. 23183. M. Hong, Y. Xia, Z. Wang, J. Zhu, Y. Wang, S. Cai, X. Yang, Q. Dai, Z. Dong, Z. Zhang, and Z. Zhao. Eager-llm: Enhancing large language models as recommenders through exogenous behavior-semantic integration. InProceedings of the ACM on Web Conference 2025, WWW ’25, page 2754–2762, New York, NY, USA, 2025a. Associatio...
-
[8]
URL https://arxiv.org/abs/2602.10699. J. Liao, S. Li, Z. Yang, J. Wu, Y. Yuan, X. Wang, and X. He. Llara: Large language-recommendation assistant. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’24, page 1785–1795, New York, NY, USA,
-
[9]
Association for Computing Machinery. ISBN 9798400704314. doi: 10.1145/3626772.3657690. URL https://doi.org/10.1145/ 3626772.3657690. J. Lin, T. Wang, and K. Qian. Rec-r1: Bridging generative large language models and user-centric recommendation systems via reinforcement learning,
-
[10]
URL https://arxiv.org/abs/2503. 24289. B. Liu, X. Li, J. Zhang, J. Wang, T. He, S. Hong, H. Liu, S. Zhang, K. Song, K. Zhu, et al. Advances and challenges in foundation agents: From brain-inspired intelligence to evolutionary, collaborative, and safe systems.arXiv preprint arXiv:2504.01990, 2025a. Z. Liu, S. Wang, X. Wang, R. Zhang, J. Deng, H. Bao, J. Zh...
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://openreview. net/forum?id=BJ0fQUU32w. Z. Shao, P . Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[12]
W. Wang, H. Bao, X. Lin, J. Zhang, Y. Li, F. Feng, S.-K. Ng, and T.-S. Chua. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM ’24, page 2400–2409, New York, NY, USA, 2024a. Association for Computing Machinery. ISBN 9798400704369. doi: 10.1145/362...
-
[13]
ISSN 1046-8188. doi: 10.1145/3773771. URL https://doi.org/10.1145/ 3773771. Y. Xie, X. K. Ren, Y. Qi, and H. Yao. Sage: Sequence-level adaptive gradient evolution for generative recommendation,
- [14]
-
[15]
doi: 10.1109/ICDE60146.2024.00118. C. Zheng, S. Liu, M. Li, X.-H. Chen, B. Yu, C. Gao, K. Dang, Y. Liu, R. Men, A. Yang, J. Zhou, and J. Lin. Group sequence policy optimization,
-
[16]
URLhttps://arxiv.org/abs/2507.18071. G. Zhou, H. Bao, J. Huang, J. Deng, J. Zhang, J. She, K. Cai, L. Ren, L. Ren, Q. Luo, et al. Openonerec technical report.arXiv preprint arXiv:2512.24762, 2025a. G. Zhou, J. Deng, J. Zhang, K. Cai, L. Ren, Q. Luo, Q. Wang, Q. Hu, R. Huang, S. Wang, et al. Onerec technical report.arXiv preprint arXiv:2506.13695, 2025b. G...
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.