Recognition: unknown
From Global to Local: Rethinking CLIP Feature Aggregation for Person Re-Identification
Pith reviewed 2026-05-08 12:41 UTC · model grok-4.3
The pith
Aligning CLIP patch tokens to text embedding anchors produces more robust identity features than global pooling for person re-identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
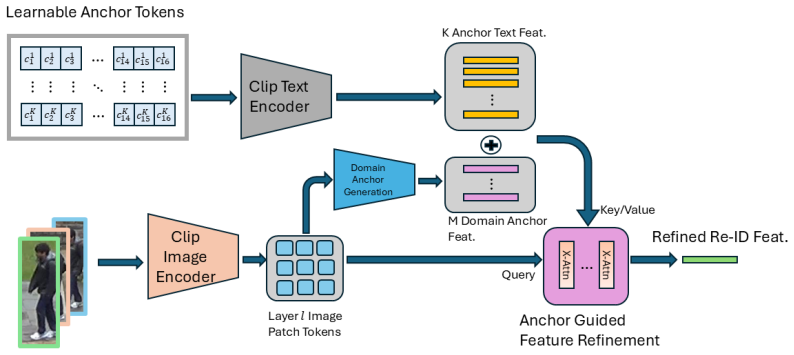
SAGA-ReID reconstructs identity representations by aligning intermediate patch tokens with anchor vectors parameterized in CLIP's text embedding space, emphasizing spatially stable evidence while suppressing corrupted or absent regions without requiring textual descriptions of individual images.
What carries the argument
Anchor vectors in CLIP's text embedding space that guide selective alignment of patch tokens to reconstruct the identity representation.
If this is right
- Consistent gains over standard CLIP-ReID on both normal and occluded person re-identification benchmarks.
- Largest improvements occur where global pooling is least reliable, reaching up to +10.6 Rank-1 on occluded data.
- SAGA aggregation beats dedicated sequential patch methods even when those methods use a stronger backbone.
- Structured reconstruction solves an aggregation bottleneck that better backbones or added architectural complexity alone do not fix.
Where Pith is reading between the lines
- The text embedding space appears to carry priors that support spatial selectivity even when no text is provided at inference time.
- Anchor-guided alignment could be tested on other CLIP-based tasks such as occluded object detection where global features lose critical local detail.
- Because no per-image text is required, the method opens a route to fully unsupervised or cross-domain ReID pipelines that still benefit from language-space structure.
Load-bearing premise
Anchor vectors parameterized in CLIP's text embedding space can emphasize spatially stable identity evidence and suppress corrupted regions without image-specific textual descriptions.
What would settle it
An ablation that replaces the anchor alignment step with plain global pooling or random vectors and finds no accuracy difference on occluded ReID test sets would falsify the central claim.
Figures





read the original abstract
CLIP-based person re-identification (ReID) methods aggregate spatial features into a single global \texttt{[CLS]} token optimized for image-text alignment rather than spatial selectivity, making representations fragile under occlusion and cross-camera variation. We propose SAGA-ReID, which reconstructs identity representations by aligning intermediate patch tokens with anchor vectors parameterized in CLIP's text embedding space -- emphasizing spatially stable evidence while suppressing corrupted or absent regions, without requiring textual descriptions of individual images. Controlled experiments isolate the aggregation mechanism under two qualitatively distinct conditions -- synthetic masking, where identity signal is absent, and realistic human distractors, where an overlapping person introduces semantically confusing signal -- with SAGA's advantage over global pooling growing substantially as occlusion increases across both conditions. Benchmark evaluations confirm consistent gains over CLIP-ReID across standard and occluded settings, with the largest improvements where global pooling is most unreliable: up to +10.6 Rank-1 on occluded benchmarks. SAGA's aggregation outperforms dedicated sequential patch aggregation on a stronger backbone, confirming that structured reconstruction addresses a bottleneck that backbone quality and architectural complexity alone cannot resolve. Code available at https://github.com/ipl-uw/Structured-Anchor-Guided-Aggregation-for-ReID.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAGA-ReID for person re-identification, which reconstructs identity representations by aligning CLIP intermediate patch tokens with anchor vectors parameterized in the text embedding space. This is intended to emphasize spatially stable identity evidence and suppress corrupted regions under occlusion or distractors, without needing per-image textual descriptions. The authors report controlled experiments isolating the aggregation step under synthetic masking and realistic human distractors, plus benchmark gains over CLIP-ReID (up to +10.6 Rank-1 on occluded sets) and superiority to sequential patch aggregation even on stronger backbones.
Significance. If the central claim holds, the work demonstrates that structured reconstruction of CLIP features can address a bottleneck in global pooling for ReID that is not resolved by backbone scale or architectural complexity alone. The provision of code at https://github.com/ipl-uw/Structured-Anchor-Guided-Aggregation-for-ReID is a positive factor for reproducibility.
major comments (3)
- [§3] §3 (Method): The parameterization and optimization of the anchor vectors in CLIP text space is not shown to be independent of the ReID training data. If the anchors are learned or selected using the same identity labels and camera views as the downstream evaluation, the reported gains may reduce to quantities fitted directly to the benchmark rather than reflecting a general structured-alignment benefit.
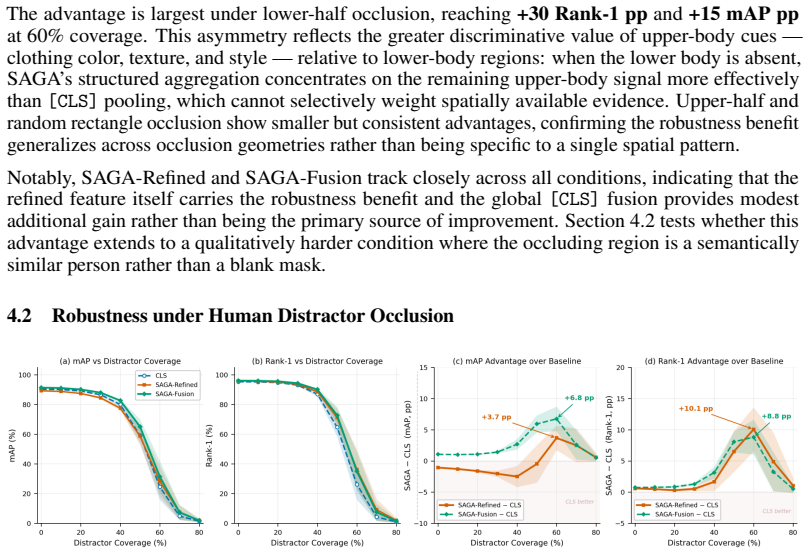
- [§4.2] §4.2 (Controlled experiments): The human-distractor condition introduces semantically similar but identity-conflicting patches; the paper must demonstrate that the fixed or globally learned text-space anchors reliably down-weight these patches while preserving target identity evidence, rather than relying on average-case behavior across the test set.
- [Table 2] Table 2 / occluded benchmarks: The largest reported gains (+10.6 Rank-1) occur precisely where global pooling is weakest, but without an ablation that isolates the contribution of the text-space alignment versus the reconstruction loss itself, it remains unclear whether the structured mechanism is the load-bearing factor.
minor comments (2)
- [Abstract / §1] The abstract and §1 use 'parameterized in CLIP's text embedding space' without an equation or diagram showing the exact form of the anchors (e.g., learned embeddings, prompt-derived, or class prototypes).
- [§4.3] Statistical reporting (standard deviations, number of runs) is missing from the benchmark tables; this is needed to assess whether the gains are robust.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment point by point below, with clarifications and proposed revisions to the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [§3] §3 (Method): The parameterization and optimization of the anchor vectors in CLIP text space is not shown to be independent of the ReID training data. If the anchors are learned or selected using the same identity labels and camera views as the downstream evaluation, the reported gains may reduce to quantities fitted directly to the benchmark rather than reflecting a general structured-alignment benefit.
Authors: We appreciate the referee's concern about potential dependence on the ReID training data. The anchor vectors are initialized from generic text prompts in CLIP's text embedding space (e.g., 'a person') and optimized as shared, identity-agnostic parameters during training; they do not encode specific identity labels or camera views. To demonstrate that the gains reflect a general structured-alignment benefit rather than benchmark fitting, we will add an ablation in the revision using anchors pre-computed from a disjoint source (e.g., generic captions from MS-COCO) and kept frozen during ReID training. This will be reported in §3 with the updated results. revision: partial
-
Referee: [§4.2] §4.2 (Controlled experiments): The human-distractor condition introduces semantically similar but identity-conflicting patches; the paper must demonstrate that the fixed or globally learned text-space anchors reliably down-weight these patches while preserving target identity evidence, rather than relying on average-case behavior across the test set.
Authors: We agree that average-case metrics alone are insufficient and that per-instance reliability must be shown explicitly. The manuscript includes qualitative visualizations of patch weighting under distractors. We will revise §4.2 to add quantitative per-image analysis, including the distribution of weights on distractor versus target patches across the full test set and selected challenging case studies. This will confirm that the anchors consistently suppress conflicting patches on an individual basis. revision: yes
-
Referee: [Table 2] Table 2 / occluded benchmarks: The largest reported gains (+10.6 Rank-1) occur precisely where global pooling is weakest, but without an ablation that isolates the contribution of the text-space alignment versus the reconstruction loss itself, it remains unclear whether the structured mechanism is the load-bearing factor.
Authors: This observation is correct and highlights a gap in the current ablations. While we compare SAGA against global pooling and other methods, we do not isolate text-space alignment from the reconstruction loss. We will add this ablation in the revision, comparing (i) reconstruction with random anchors, (ii) text-space anchors without reconstruction, and (iii) the full model, with results on occluded benchmarks. The new results will be incorporated near Table 2 to clarify the contribution of the structured alignment. revision: yes
Circularity Check
No significant circularity; derivation relies on external benchmarks and independent validation
full rationale
The paper defines SAGA-ReID via alignment of patch tokens to anchor vectors in CLIP text space (without per-image text) and validates via controlled experiments on synthetic occlusion and realistic distractors plus standard ReID benchmarks. No quoted equations or steps reduce the reported Rank-1 gains or the aggregation mechanism to quantities fitted directly to the evaluation data by construction, nor to self-citation chains that bear the central claim. The advantage over global pooling and sequential aggregation is measured externally and grows with occlusion severity, keeping the derivation self-contained against independent test sets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CLIP's text embedding space contains anchor vectors that can guide spatial selectivity for person identity without image-specific textual descriptions.
Reference graph
Works this paper leans on
-
[1]
Person Re-identification: Past, Present and Future,
Liang Zheng, Yi Yang, and Alexander G. Hauptmann. Person re-identification: Past, present and future.arXiv preprint arXiv:1610.02984, 2016. URL https://arxiv.org/abs/1610. 02984
-
[2]
Deep learning for person re-identification: A survey and outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
Mang Ye, Jianbing Shen, Guiguang Lin, Tao Xiang, Ling Shao, and Steven Hoi. Deep learning for person re-identification: A survey and outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
2021
-
[3]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the International Conference on Machine Learning (ICML), 2021
2021
-
[4]
Clip-reid: Exploiting vision-language model for image re- identification without concrete text labels
Siyuan Li, Li Sun, and Qingli Li. Clip-reid: Exploiting vision-language model for image re- identification without concrete text labels. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023
2023
-
[5]
Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline)
Yifan Sun, Liang Zheng, Yi Yang, Qi Tian, and Shengjin Wang. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). InProceedings of the European Conference on Computer Vision (ECCV), 2018
2018
-
[6]
Transreid: Transformer- based object re-identification
Shuting He, Hao Luo, Pichao Wang, Fan Wang, Hao Li, and Wei Jiang. Transreid: Transformer- based object re-identification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15013–15022, 2021
2021
-
[8]
A pedestrian is worth one prompt: Towards language guidance person re-identification
Zexian Yang, Dayan Wu, Chenming Wu, Zheng Lin, Jingzi Gu, and Weiping Wang. A pedestrian is worth one prompt: Towards language guidance person re-identification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17343–17353, 2024
2024
-
[9]
Climb- reid: A hybrid clip-mamba framework for person re-identification
Chenyang Yu, Xuehu Liu, Jiawen Zhu, Yuhao Wang, Pingping Zhang, and Huchuan Lu. Climb- reid: A hybrid clip-mamba framework for person re-identification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9589–9597, 2025
2025
-
[10]
In de- fense of the triplet loss for person re-identification.arXiv preprint arXiv:1703.07737, 2017
Alexander Hermans, Lucas Beyer, and Bastian Leibe. In defense of the triplet loss for person re-identification.arXiv preprint arXiv:1703.07737, 2017. URL https://arxiv.org/abs/ 1703.07737
-
[11]
Pose-guided feature alignment for occluded person re-identification
Jiaxu Miao, Yu Wu, Ping Liu, Yujing Ding, and Yi Yang. Pose-guided feature alignment for occluded person re-identification. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2019. 13
2019
-
[12]
Identity-guided human semantic parsing for person re-identification
Kuan Zhu, Haiyun Guo, Zhiwei Liu, Ming Tang, and Jinqiao Wang. Identity-guided human semantic parsing for person re-identification. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors,Computer Vision – ECCV 2020, volume 12348 ofLecture Notes in Computer Science, pages 346–363, Cham, 2020. Springer. doi: 10.1007/978-3-030-58580-8\ _21
-
[13]
Multi-modal multi-platform person re-identification: Benchmark and method
Ruiyang Ha, Songyi Jiang, Bin Li, Bikang Pan, Yihang Zhu, Junjie Zhang, Xiatian Zhu, Shao- gang Gong, and Jingya Wang. Multi-modal multi-platform person re-identification: Benchmark and method. InProceedings of the IEEE/CVF International Conference on Computer Vision,
- [14]
-
[15]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Oriol Vinyals, Andrew Zisserman, and João Carreira. Perceiver: General perception with iterative attention. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 4651–4664. PMLR, 2021. URL https://...
2021
-
[16]
Object-centric learning with slot attention
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-centric learning with slot attention. InAdvances in Neural Information Processing Systems, volume 33, pages 11525–11538. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/ paper/2020/has...
2020
-
[17]
Bag of tricks and a strong baseline for deep person re-identification
Hao Luo, Youzhi Gu, Xingyu Liao, Shenqi Lai, and Wei Jiang. Bag of tricks and a strong baseline for deep person re-identification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 0–0, 2019
2019
-
[18]
Profd: Prompt-guided feature disentangling for occluded person re-identification
Can Cui, Siteng Huang, Wenxuan Song, Pengxiang Ding, Min Zhang, and Donglin Wang. Profd: Prompt-guided feature disentangling for occluded person re-identification. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1583–1592, 2024
2024
-
[19]
Feature completion transformer for occluded person re-identification.IEEE Transactions on Multimedia, 26:8529–8542, 2024
Tao Wang, Mengyuan Liu, Hong Liu, Wenhao Li, Miaoju Ban, Tianyu Guo, and Yidi Li. Feature completion transformer for occluded person re-identification.IEEE Transactions on Multimedia, 26:8529–8542, 2024
2024
-
[20]
Parallel augmentation and dual enhancement for occluded person re-identification
Zi Wang, Huaibo Huang, Aihua Zheng, Chenglong Li, and Ran He. Parallel augmentation and dual enhancement for occluded person re-identification. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3590–
2024
-
[21]
Yunfei Xie, Yuxuan Cheng, Juncheng Wu, Haoyu Zhang, Yuyin Zhou, and Shoudong Han. Scing: Towards more efficient and robust person re-identification through selective cross-modal prompt tuning.arXiv preprint arXiv:2507.00506, 2025
-
[22]
Qianru Han, Xinwei He, Zhi Liu, Sannyuya Liu, Ying Zhang, and Jinhai Xiang. Clip-scgi: Syn- thesized caption-guided inversion for person re-identification.arXiv preprint arXiv:2410.09382, 2024
-
[23]
Erm++: An improved baseline for domain generalization
Piotr Teterwak, Kuniaki Saito, Theodoros Tsiligkaridis, Kate Saenko, and Bryan A Plummer. Erm++: An improved baseline for domain generalization. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 8525–8535. IEEE, 2025
2025
-
[24]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF international conference on computer vision, pages 1406–1415, 2019. 14
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.