Recognition: unknown
Advancing automatic speech recognition using feature fusion with self-supervised learning features: A case study on Fearless Steps Apollo corpus
Pith reviewed 2026-05-08 09:18 UTC · model grok-4.3
The pith
A novel deep cross-attention fusion of self-supervised features cuts word error rate by 1.1 percent on Apollo mission audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
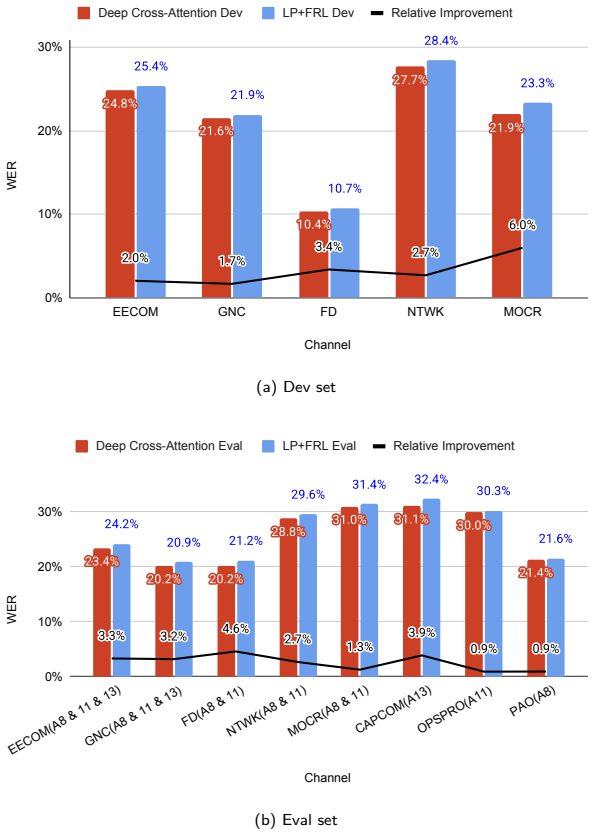
The authors introduce a deep cross-attention (DCA) fusion method that integrates features from multiple self-supervised learning models, yielding an absolute 1.1 percent improvement in word error rate on the FSC Phase-4 corpus while also performing competitively on CHiME-6 data; this approach is positioned as superior to previously explored refinement losses and fusion strategies for these challenging naturalistic recordings.
What carries the argument
Deep cross-attention (DCA) fusion, which performs layered cross-attention between feature sets extracted from different self-supervised models so each can refine the other before final concatenation or pooling.
If this is right
- Higher-quality automatic transcripts become available for the entire Fearless Steps Apollo collection.
- Researchers gain improved metadata that supports analysis across multiple scientific domains.
- The same fusion technique shows transferable gains on at least one additional naturalistic dataset (CHiME-6).
- Self-supervised features can be leveraged more fully without needing extensive hand-crafted acoustic features.
Where Pith is reading between the lines
- The cross-attention design may scale to fusion of even more self-supervised models or to other audio tasks such as speaker diarization.
- If the gain holds on streaming or low-latency settings, the method could support real-time mission communication monitoring.
- Similar attention-based fusion might be tested on visual or multimodal Apollo data to create richer cross-modal metadata.
Load-bearing premise
The 1.1 percent word error rate gain on FSC Phase-4 is caused by the deep cross-attention fusion itself rather than hidden differences in baseline systems or tuning specific to this dataset.
What would settle it
Applying the identical DCA fusion pipeline, without any retraining or hyperparameter changes, to a fresh naturalistic speech corpus outside the Apollo and CHiME collections and observing zero or negative word error rate change relative to standard concatenation baselines.
Figures



read the original abstract
Using self-supervised learning (SSL) models has significantly improved performance for downstream speech tasks, surpassing the capabilities of traditional hand-crafted features. This study investigates the amalgamation of SSL models, with the aim to leverage both their individual strengths and refine extracted features to achieve improved speech recognition models for naturalistic scenarios. Our research investigates the massive naturalistic Fearless Steps (FS) APOLLO resource, with particular focus on the FS Challenge (FSC) Phase-4 corpus, providing the inaugural analysis of this dataset. Additionally, we incorporate the CHiME-6 dataset to evaluate performance across diverse naturalistic speech scenarios. While exploring previously proposed Feature Refinement Loss and fusion methods, we found these methods to be less effective on the FSC Phase-4 corpus. To address this, we introduce a novel deep cross-attention (DCA) fusion method, designed to elevate performance, especially for the FSC Phase-4 corpus. Our objective is to foster creation of superior FS APOLLO community resources, catering to the diverse needs of researchers across various disciplines. The proposed solution achieves an absolute +1.1% improvement in WER, providing effective meta-data creation for the massive FS APOLLO community resource.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates feature fusion of self-supervised learning (SSL) models for automatic speech recognition (ASR) on naturalistic speech, with a focus on the Fearless Steps (FS) Apollo corpus and its FSC Phase-4 subset. After finding prior Feature Refinement Loss and fusion approaches less effective on this data, the authors introduce a deep cross-attention (DCA) fusion method. They report an absolute 1.1% WER improvement on FSC Phase-4 and include results on CHiME-6 to support broader applicability, with the goal of aiding metadata creation for the FS APOLLO resource.
Significance. If the reported WER gain is robustly attributable to DCA fusion and generalizes, the work could offer a practical advance for ASR in challenging real-world conditions and provide useful resources for the FS APOLLO community. The empirical focus on a large naturalistic corpus is a strength, though the absence of detailed controls limits assessment of its contribution relative to existing fusion techniques.
major comments (3)
- [Abstract] Abstract: The claimed absolute +1.1% WER improvement on FSC Phase-4 is presented without baseline WER values, training details, ablation results (e.g., removing the cross-attention component), or statistical significance tests, making it impossible to attribute the gain specifically to the DCA fusion rather than unstated factors such as hyperparameter choices or data splits.
- [Abstract] Abstract/Results: No quantitative comparison is provided for the 'previously proposed Feature Refinement Loss and fusion methods' under the same training recipe on FSC Phase-4, despite the claim that they were less effective; this omission prevents evaluation of whether DCA represents a meaningful advance over those baselines.
- [Abstract] Abstract: The CHiME-6 results are mentioned only in passing and do not include the same level of detail or controls as the primary FSC Phase-4 experiments, weakening the claim of effectiveness across diverse naturalistic scenarios.
minor comments (1)
- [Abstract] Abstract: Clarify whether the analysis of FSC Phase-4 is truly the 'inaugural' one, or if prior publications on this subset exist.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our paper. We have prepared revisions to address the concerns raised regarding the abstract and results presentation. Our point-by-point responses are as follows.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claimed absolute +1.1% WER improvement on FSC Phase-4 is presented without baseline WER values, training details, ablation results (e.g., removing the cross-attention component), or statistical significance tests, making it impossible to attribute the gain specifically to the DCA fusion rather than unstated factors such as hyperparameter choices or data splits.
Authors: We agree that the abstract would benefit from additional context to support attribution of the reported gain. In the revised manuscript we will update the abstract to state the baseline WER of the strongest single SSL feature. We will also add a concise reference to the ablation experiments (including variants without the cross-attention component) and training protocol that appear in the main text, together with a note that the improvement was reproducible across multiple random seeds. These changes will be kept brief to respect abstract length limits while clarifying the role of the DCA fusion. revision: yes
-
Referee: [Abstract] Abstract/Results: No quantitative comparison is provided for the 'previously proposed Feature Refinement Loss and fusion methods' under the same training recipe on FSC Phase-4, despite the claim that they were less effective; this omission prevents evaluation of whether DCA represents a meaningful advance over those baselines.
Authors: We accept this criticism. We will revise the abstract to include a short quantitative comparison of WERs obtained by the Feature Refinement Loss and prior fusion methods on FSC Phase-4 when trained under the identical recipe. A corresponding table or subsection will be added to the results section so that readers can directly assess the relative improvement of the proposed DCA approach. revision: yes
-
Referee: [Abstract] Abstract: The CHiME-6 results are mentioned only in passing and do not include the same level of detail or controls as the primary FSC Phase-4 experiments, weakening the claim of effectiveness across diverse naturalistic scenarios.
Authors: We acknowledge that the CHiME-6 experiments received less emphasis. We will expand the abstract sentence on CHiME-6 to report the key WER figures and to state that the same training recipe and feature-extraction controls were applied. Full experimental details and controls for CHiME-6 will remain in the main text and supplementary material; the abstract revision will be limited to a concise summary to maintain focus on the primary FSC Phase-4 contribution. revision: partial
Circularity Check
No circularity: empirical WER comparison with no derivations or self-referential fitting
full rationale
The paper presents an empirical study comparing ASR performance on the FSC Phase-4 and CHiME-6 corpora using SSL features and a proposed deep cross-attention fusion method. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The +1.1% WER claim rests on direct experimental reporting rather than any reduction to inputs by construction, self-definition, or imported uniqueness theorems. The work is therefore self-contained as a standard empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiong, L
W. Xiong, L. Wu, F. Alleva, J. Droppo, X. Huang, A. Stolcke, The Mi- crosoft 2017 conversational speech recognition system, IEEE ICASSP- 2018: Inter. Conf. on Acoustics, Speech and Signal Proc. (2018) 5934– 5938. 30
2017
-
[2]
Watanabe, T
S. Watanabe, T. Hori, S. Kim, J. R. Hershey, T. Hayashi, Hybrid CTC/attention architecture for End-to-End speech recognition, IEEE Journal of Selected Topics in Signal Processing 11 (8) (2017) 1240–1253
2017
-
[3]
K. Kim, F. Wu, Y. Peng, J. Pan, P. Sridhar, K. J. Han, S. Watan- abe, E-Branchformer: Branchformer with Enhanced merging for speech recognition, SLT-23: IEEE Spoken Lang. Tech. Workshop (2023) 84–91
2023
-
[4]
T¨ uske, G
Z. T¨ uske, G. Saon, B. Kingsbury, On the limit of English conversational speech recognition, ISCA Interspeech-2021 (2021)
2021
-
[5]
Radford, J
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, I. Sutskever, Robust speech recognition via large-scale weak supervision, Intern. Con- ference on Machine Learning (2023) 28492–28518
2023
-
[6]
Panayotov, G
V. Panayotov, G. Chen, D. Povey, S. Khudanpur, Librispeech: an asr corpus based on public domain audio books, IEEE ICASSSP-2015: In- tern. Conf. on Acoustics, Speech and Signal Proc. (2015) 5206–5210
2015
-
[7]
Watanabe, M
S. Watanabe, M. Mandel, J. Barker, E. Vincent, A. Arora, X. Chang, S. Khudanpur, V. Manohar, D. Povey, D. Raj, et al., CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings, Workshop on Speech Processing in Everyday Environments (CHiME 2020) (2020) 1–7
2020
-
[8]
Nguyen, F
H. Nguyen, F. Bougares, N. Tomashenko, Y. Est` eve, L. Besacier, Inves- tigating self-supervised pre-training for end-to-end speech translation, ISCA Interspeech-2020 (2020)
2020
-
[9]
A. Wu, C. Wang, J. Pino, J. Gu, Self-supervised representations improve end-to-end speech translation, ISCA Interspeech-2020 (2020) 1491–1495
2020
- [10]
-
[11]
Z. Fan, M. Li, S. Zhou, B. Xu, Exploring Wav2Vec 2.0 on speaker verifi- cation and language identification, ISCA Interspeech-2021 (2021) 1509– 1513. 31
2021
-
[12]
Pepino, P
L. Pepino, P. Riera, L. Ferrer, Emotion recognition from speech using Wav2Vec 2.0 embeddings, ISCA Interspeech-2021 (2021) 3400–3404
2021
-
[13]
W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, A. Mohamed, Hubert: Self-supervised speech representation learning by masked prediction of hidden units, IEEE/ACM Trans. on Audio, Speech, and Language Proc. 29 (2021) 3451–3460
2021
-
[14]
Baevski, Y
A. Baevski, Y. Zhou, A. Mohamed, M. Auli, Wav2Vec 2.0: A frame- work for self-supervised learning of speech representations, Advances in Neural Information Processing Systems 33 (2020) 12449–12460
2020
-
[15]
S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, et al., WavLM: Large-scale self-supervised pre- training for full stack speech processing, IEEE Journal of Selected Topics in Signal Processing 16 (6) (2022) 1505–1518
2022
-
[16]
Chang, T
X. Chang, T. Maekaku, P. Guo, J. Shi, Y.-J. Lu, A. S. Subramanian, T. Wang, S.-w. Yang, Y. Tsao, H.-y. Lee, et al., An exploration of self- supervised pretrained representations for end-to-end speech recognition, IEEE ASRU-2021: Automatic Speech Recog. and Understanding Work- shop (2021) 228–235
2021
-
[17]
Arunkumar, V
A. Arunkumar, V. N. Sukhadia, S. Umesh, Investigation of ensemble features of self-supervised pretrained models for automatic speech recog- nition, ISCA Interspeech-2022 (2022) 5145–5149
2022
-
[18]
S.-J. Chen, J. Xie, J. H. L. Hansen, FeaRLESS: Feature Refinement Loss for Ensembling Self-Supervised Learning Features in Robust End-to-end Speech Recognition, ISCA Interspeech-2022 (2022)
2022
-
[19]
S.-J. Chen, W. Xia, J. H. L. Hansen, Scenario Aware Speech Recog- nition: Advancements for Apollo Fearless Steps & CHiME-4 Corpora, IEEE ASRU-2021: Automatic Speech Recog. and Understanding Work- shop (2021) 289–295
2021
-
[20]
Berrebbi, J
D. Berrebbi, J. Shi, B. Yan, O. Lopez-Francisco, J. D. Amith, S. Watan- abe, Combining spectral and self-supervised features for low resource speech recognition and translation, ISCA Interspeech-2022 (2022) 3533– 3537. 32
2022
-
[21]
Yang, P.-H
S.-w. Yang, P.-H. Chi, Y.-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y. Y. Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, et al., Superb: Speech processing universal performance benchmark, ISCA Interspeech-2021 (2021) 1194– 1198
2021
-
[22]
J. H. Hansen, A. Sangwan, A. Joglekar, A. E. Bulut, L. Kaushik, C. Yu, Fearless Steps: Apollo-11 Corpus Advancements for Speech Technolo- gies from Earth to the Moon, ISCA Interspeech-2018 (2018) 2758–2762
2018
-
[23]
J. H. Hansen, A. Joglekar, M. M. Shekar, S.-J. Chen, X. Liu, Fearless steps apollo: Team communications based community resource develop- ment for science, technology, education, and historical preservation, in: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2024, pp. 12816–12820
2024
-
[24]
Mohamed, H.-y
A. Mohamed, H.-y. Lee, L. Borgholt, J. D. Havtorn, J. Edin, C. Igel, K. Kirchhoff, S.-W. Li, K. Livescu, L. Maaløe, et al., Self-supervised speech representation learning: A review, IEEE Journal of Selected Top- ics in Signal Processing 16 (6) (2022) 1179–1210
2022
-
[25]
A. v. d. Oord, Y. Li, O. Vinyals, Representation learning with con- trastive predictive coding, Proc. of NIPS (2018)
2018
-
[26]
Z. Chi, S. Huang, L. Dong, S. Ma, B. Zheng, S. Singhal, P. Bajaj, X. Song, X.-L. Mao, H. Huang, F. Wei, XLM-E: Cross-lingual language model pre-training via ELECTRA, Annual Meeting of Assoc. for Comp. Ling. (2022) 6170–6182doi:10.18653/v1/2022.acl-long.427
-
[27]
Srivastava, J
T. Srivastava, J. Shi, W. Chen, S. Watanabe, Effuse: Efficient self- supervised feature fusion for e2e asr in low resource and multilingual scenarios, in: Proc. Interspeech 2024, 2024, pp. 3989–3993
2024
-
[28]
S.-H. Wang, J. Shi, C.-y. Huang, S. Watanabe, H.-y. Lee, Fusion of discrete representations and self-augmented representations for multi- lingual automatic speech recognition, in: 2024 IEEE Spoken Language Technology Workshop (SLT), IEEE, 2024, pp. 247–254
2024
-
[29]
Chiu, C.-H
S.-C. Chiu, C.-H. Wu, J.-K. Hsieh, Y. Tsao, H.-M. Wang, Learnable layer selection and model fusion for speech self-supervised learning mod- els, in: Proc. Interspeech 2024, 2024, pp. 3914–3918. 33
2024
-
[30]
H. Lin, X. Cheng, X. Wu, D. Shen, Cat: Cross attention in vision transformer, in: 2022 IEEE international conference on multimedia and expo (ICME), IEEE, 2022, pp. 1–6
2022
-
[31]
C.-F. R. Chen, Q. Fan, R. Panda, Crossvit: Cross-attention multi- scale vision transformer for image classification, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 357– 366
2021
-
[32]
Y. Cai, Y. Yuan, Car-transformer: Cross-attention reinforcement trans- former for cross-lingual summarization, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, 2024, pp. 17718–17726
2024
-
[33]
J. H. Hansen, A. Joglekar, M. C. Shekhar, V. Kothapally, C. Yu, L. Kaushik, A. Sangwan, The 2019 Inaugural Fearless Steps Challenge: A Giant Leap for Naturalistic Audio, ISCA Interspeech-2019 (2019) 1851–1855doi:10.21437/Interspeech.2019-2301. URLhttp://dx.doi.org/10.21437/Interspeech.2019-2301
-
[34]
Joglekar, J
A. Joglekar, J. H. Hansen, M. C. Shekar, A. Sangwan, FEARLESS STEPS Challenge (FS-2): Supervised Learning with Massive Naturalis- tic Apollo Data, ISCA Interspeech-2020 (2020) 2617–2621
2020
-
[35]
A. Joglekar, S. O. Sadjadi, M. Chandra-Shekar, C. Cieri, J. H. Hansen, Fearless Steps Challenge Phase-3 (FSC P3): Advancing SLT for Un- seen Channel and Mission Data Across NASA Apollo Audio, ISCA Interspeech-2021 (2021) 986–990doi:10.21437/Interspeech.2021-2011
-
[36]
This is Houston. Say again, please
A. Gorin, D. Kulko, S. Grima, A. Glasman, “This is Houston. Say again, please.” The Behavox system for the Apollo-11 Fearless Steps Challenge (Phase II), ISCA Interspeech-2020 (2020) 2612–2616
2020
-
[37]
Watanabe, T
S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N.- E. Y. Soplin, J. Heymann, M. Wiesner, N. Chen, et al., Espnet: End-to- end speech processing toolkit, Proc. Interspeech 2018 (2018) 2207–2211
2018
-
[38]
Boeddeker, J
C. Boeddeker, J. Heitkaemper, J. Schmalenstroeer, L. Drude, J. Hey- mann, R. Haeb-Umbach, Front-end processing for the chime-5 dinner party scenario, in: CHiME5 Workshop, Hyderabad, India, Vol. 1, 2018. 34
2018
-
[39]
Gulati, J
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu, et al., Conformer: Convolution-augmented Transformer for Speech Recognition, Proc. Interspeech 2020 (2020) 5036–5040
2020
-
[40]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Attention is all you need, Advances in Neural Info. Proc. Systems 30 (2017) 5998–6008
2017
-
[41]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, International Conference on Learning Representations (2014)
2014
-
[42]
Decoupled Weight Decay Regularization
I. Loshchilov, Decoupled weight decay regularization, arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review arXiv 2017
-
[43]
D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, Q. V. Le, Specaugment: A simple data augmentation method for au- tomatic speech recognition, Proc. Annu. Conf. Int. Speech Commun. Assoc. (2019) 2613–2617
2019
-
[44]
Gillick, S
L. Gillick, S. J. Cox, Some statistical issues in the comparison of speech recognition algorithms, in: International Conference on Acous- tics, Speech, and Signal Processing,, IEEE, 1989, pp. 532–535
1989
-
[45]
Fiscus, NIST SCTK Toolkit,https://github.com/usnistgov/SCTK, online; (2018)
J. Fiscus, NIST SCTK Toolkit,https://github.com/usnistgov/SCTK, online; (2018)
2018
-
[46]
Pasad, B
A. Pasad, B. Shi, K. Livescu, Comparative layer-wise analysis of self- supervised speech models, in: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2023, pp. 1–5
2023
-
[47]
Ashihara, M
T. Ashihara, M. Delcroix, T. Moriya, K. Matsuura, T. Asami, Y. Ijima, What do self-supervised speech and speaker models learn? new findings from a cross model layer-wise analysis, in: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2024, pp. 10166–10170
2024
-
[48]
Gaussian Error Linear Units (GELUs)
D. Hendrycks, K. Gimpel, Gaussian error linear units (gelus), arXiv preprint arXiv:1606.08415 (2016). 35
work page internal anchor Pith review arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.