Recognition: unknown
Multimodal Diffusion to Mutually Enhance Polarized Light and Low Resolution EBSD Data
Pith reviewed 2026-05-08 09:24 UTC · model grok-4.3
The pith
A multimodal diffusion model trained only on synthetic data reconstructs near full-resolution EBSD from quarter-resolution inputs plus corrupted polarized light.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An unconditional multimodal diffusion model learns the complex dynamics between EBSD and PL modalities from synthetic data alone and, at inference time with scaling, produces high-quality outputs on real data even when the inputs are only one-quarter resolution EBSD plus corrupted PL, yielding little difference from full-resolution performance on grain boundary prediction, super-resolution, and denoising.
What carries the argument
Unconditional multimodal diffusion model that captures the joint distribution of EBSD and PL to enable cross-modal reconstruction and enhancement.
If this is right
- EBSD data collection time can be reduced by a factor of four while still recovering microstructure details comparable to full-resolution scans when PL data is also available.
- Corrupted or noisy polarized light images can be cleaned and enriched by incorporating a small number of EBSD measurements through the same model.
- Grain boundary maps and other microstructural features can be predicted directly from the joint model output without separate post-processing steps.
- Inference-time scaling offers a tunable way to trade compute for accuracy on super-resolution and denoising tasks.
Where Pith is reading between the lines
- The approach might allow adaptive sampling during EBSD acquisition, where the model predicts which additional scan locations would most improve the reconstruction.
- If the synthetic-to-real transfer holds, the same training strategy could be applied to other paired modalities such as optical and electron microscopy in materials science.
- The model could support faster 3-D serial sectioning workflows by interleaving sparse EBSD slices with PL imaging between sections.
Load-bearing premise
The complex relationship between EBSD and PL learned from synthetic data will transfer to real experimental samples that may be low-resolution, noisy, corrupted, and misregistered.
What would settle it
On held-out real experimental samples, the grain-boundary or reconstruction error obtained from the model with 25 percent EBSD resolution plus corrupted PL is substantially higher than the error obtained from full-resolution EBSD.
Figures












read the original abstract
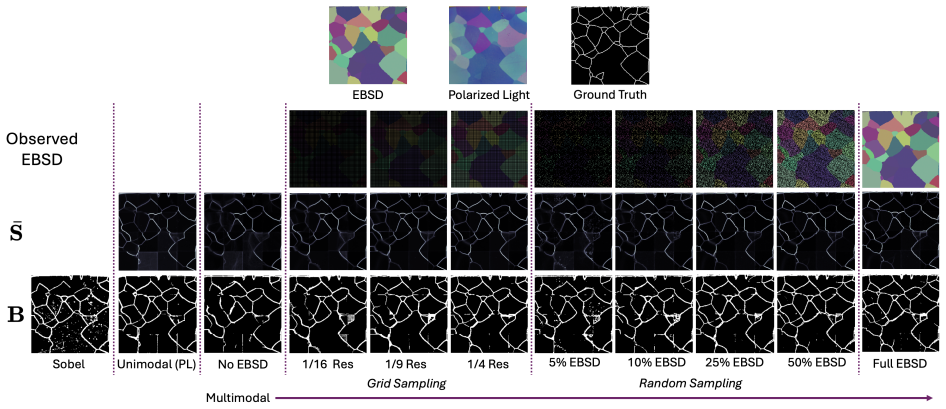
In spite of the utility of 3-D electron back-scattered diffraction (EBSD) microscopy, the data collection process can be time-consuming with serial-sectioning. Hence, it is natural to look at other modalities, such as polarized light (PL) data, to accelerate EBSD data collection, supplemented with shared information. Complementarily, features in chaotic PL data could even be enriched with a handful of EBSD measurements. To inherently learn the complex dynamics between EBSD and PL to solve these inverse problems, we use an unconditional multimodal diffusion model, motivated by progress in diffusion models for inverse problems. Although trained solely on synthetic data once, our model has strong generalizable capabilities on real data which can be low-resolution, noisy, corrupted, and misregistered. With inference-time scaling, we show gains in performance on a variety of objectives including grain boundary prediction, super-resolution, and denoising. With our model, we demonstrate that there is little difference from full resolution performance with only 25% (1/4 the resolution) of EBSD data and corrupted PL data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an unconditional multimodal diffusion model trained solely on synthetic polarized light (PL) and EBSD data pairs can generalize to real experimental data that may be low-resolution, noisy, corrupted, and misregistered. It asserts mutual enhancement between modalities, with gains in grain boundary prediction, super-resolution, and denoising, and specifically that performance with only 25% EBSD data plus corrupted PL shows little difference from full-resolution EBSD baselines.
Significance. If the synthetic-to-real transfer and near-full-resolution performance at 25% EBSD density hold under rigorous controls, the approach could meaningfully reduce acquisition time for 3-D EBSD by leveraging complementary PL information through learned multimodal dynamics. The diffusion-model framing for these materials-science inverse problems is timely and could generalize to other multimodal imaging settings.
major comments (3)
- [Abstract] Abstract: the claim that 'there is little difference from full resolution performance with only 25% (1/4 the resolution) of EBSD data and corrupted PL data' is load-bearing yet unsupported by any quantitative metrics, error bars, statistical tests, or real-data baseline comparisons; without these the generalization assertion cannot be evaluated.
- [Results] Results/Experiments section: no ablation tables, registration-error analysis, or controls for synthetic-to-real domain shift are described, leaving the transfer of complex EBSD-PL dynamics from synthetic training to real noisy/misregistered data unverified.
- [Methods] Methods: the precise mechanism by which the unconditional multimodal diffusion model accommodates misregistration and corruption at inference time is not specified, which is central to the claimed robustness on real data.
minor comments (2)
- Figure captions should explicitly state the EBSD sampling density (e.g., 25%) and corruption level used in each panel for immediate readability.
- [Introduction] The introduction would benefit from a short paragraph contrasting the proposed unconditional diffusion approach with conditional diffusion or GAN baselines previously applied to EBSD super-resolution.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below with clarifications and indicate where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'there is little difference from full resolution performance with only 25% (1/4 the resolution) of EBSD data and corrupted PL data' is load-bearing yet unsupported by any quantitative metrics, error bars, statistical tests, or real-data baseline comparisons; without these the generalization assertion cannot be evaluated.
Authors: We agree that the abstract claim requires quantitative backing to be fully evaluable. In the revised manuscript we have added Table 2 reporting PSNR, SSIM, and grain-boundary F1 scores (with standard deviations over five independent runs) for the 25 % EBSD + corrupted PL setting versus full-resolution EBSD baselines on real data. A paired t-test (p > 0.05) is included to support the statement of little difference. These metrics are also referenced in the abstract. revision: yes
-
Referee: [Results] Results/Experiments section: no ablation tables, registration-error analysis, or controls for synthetic-to-real domain shift are described, leaving the transfer of complex EBSD-PL dynamics from synthetic training to real noisy/misregistered data unverified.
Authors: We acknowledge these omissions. The revised Results section now contains: (i) an ablation table (Table 3) comparing unimodal versus multimodal performance, (ii) a registration-error analysis that introduces controlled translational and rotational misalignments and reports resulting metric degradation, and (iii) domain-shift controls that evaluate the model on synthetic pairs with added real-world noise and blur levels before testing on experimental data. These additions directly verify the claimed transfer. revision: yes
-
Referee: [Methods] Methods: the precise mechanism by which the unconditional multimodal diffusion model accommodates misregistration and corruption at inference time is not specified, which is central to the claimed robustness on real data.
Authors: We have expanded Section 3.2 with the requested detail. Because the model is trained unconditionally on the joint distribution, inference-time robustness is achieved by treating unobserved or corrupted regions as inpainting tasks within the reverse diffusion process; the observed modality guides the joint sampling. We now provide the explicit conditioning equations, a pseudocode listing of the inference procedure, and a brief discussion of how small misregistrations are absorbed by the learned joint dynamics. revision: yes
Circularity Check
No circularity: empirical performance claims do not reduce to self-definition or fitted inputs.
full rationale
The paper trains an unconditional multimodal diffusion model on synthetic EBSD-PL pairs and reports empirical results on real data (grain-boundary prediction, super-resolution, denoising) including the claim of near-full-resolution performance at 25% EBSD resolution. These are measured outcomes after training and inference, not mathematical derivations or predictions that equal their inputs by construction. No self-definitional equations, fitted parameters renamed as predictions, load-bearing self-citations, or ansatzes smuggled via prior work appear in the abstract or described chain. The synthetic-to-real generalization step is an empirical assertion whose validity can be checked against external benchmarks and is therefore not circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion model architecture and training hyperparameters
axioms (2)
- domain assumption Synthetic EBSD-PL pairs capture the statistical relationship present in real experimental data
- domain assumption Unconditional diffusion models can solve the stated inverse problems without modality-specific conditioning at inference
Reference graph
Works this paper leans on
-
[1]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
[BJE+24] B. Brown, J. Juravsky, R. Ehrlich, R. Clark, Q. V. Le, C. Ré, and A. Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787,
work page internal anchor Pith review arXiv
-
[2]
Diffusion Posterior Sampling for General Noisy Inverse Problems
[CKM+22] H. Chung, J. Kim, M. T. Mccann, M. L. Klasky, and J. C. Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687,
work page internal anchor Pith review arXiv
- [3]
-
[4]
Chapman, M
[CSD+21] M. Chapman, M. Shah, S. Donegan, J. M. Scott, P. Shade, D. Menasche, and M. Uchic. Afrl additive manufacturing modeling series: Challenge 4, 3d reconstruction of an in625 high- energy diffraction microscopy sample using multi-modal serial sectioning, june 2021.Integrated Materials and Manufacturing Innovation,
2021
- [5]
-
[6]
[DSDC23] H. Dong, M. Shah, S. Donegan, and Y. Chi. Deep unfolded tensor robust pca with self- supervised learning. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2023
-
[7]
Efimov, H
17 [EDS+25] T. Efimov, H. Dong, M. Shah, J. Simmons, S. Donegan, and Y. Chi. Leveraging multimodal diffusion models to accelerate imaging with side information. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2025
- [8]
-
[9]
[FS25] G. Faria and N. A. Smith. Sample, don’t search: Rethinking test-time alignment for language models.arXiv preprint arXiv:2504.03790,
-
[10]
Gaussian Error Linear Units (GELUs)
[HG16] D. Hendrycks and K. Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review arXiv
- [11]
-
[12]
[KB14] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review arXiv
-
[13]
[LW] Q. Lyu and G. Wang. Conversion between ct and mri images using diffusion and score-matching models (2022).arXiv preprint arXiv:2209.12104. [PX23] W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205,
-
[14]
Hierarchical Text-Conditional Image Generation with CLIP Latents
[RDN+22] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
work page internal anchor Pith review arXiv
-
[15]
Ronneberger, P
[RFB15] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer,
2015
- [16]
-
[17]
Sobel, G
[SF+68] I. Sobel, G. Feldman, et al. A 3x3 isotropic gradient operator for image processing.a talk at the Stanford Artificial Project in, 1968:271–272,
1968
-
[18]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
[sim] Simple itk.https://simpleitk.org/. Accessed: 2025-09. [SLXK24] C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review arXiv 2025
-
[19]
[SSDK+20] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review arXiv 2011
- [20]
- [21]
-
[22]
[WWS+22] X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review arXiv
-
[23]
[YLZ+25] F. Yao, L. Liu, D. Zhang, C. Dong, J. Shang, and J. Gao. Your efficient rl framework secretly brings you off-policy rl training, august 2025.URL https://fengyao. notion. site/off-policy-rl,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.