Recognition: unknown
Large Language Models Decide Early and Explain Later
Pith reviewed 2026-05-08 12:02 UTC · model grok-4.3
The pith
Large language models often fix their final answer early during chain-of-thought reasoning, making most later tokens post-decision explanation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
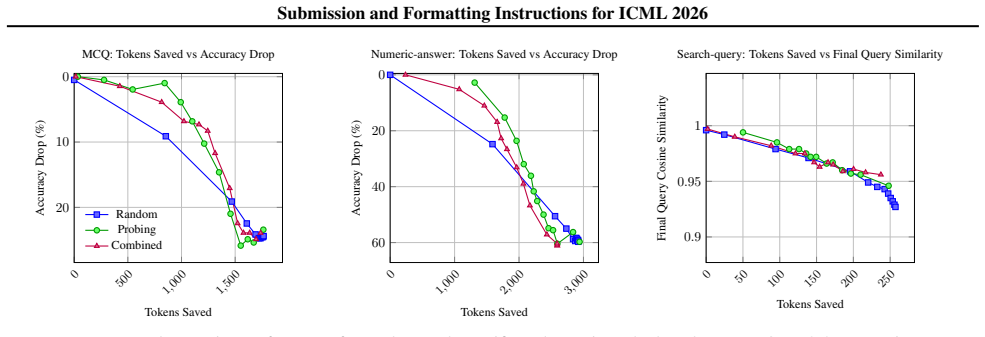
The authors use forced answer completion to probe the model's predicted answer at various points in the reasoning process. For the Qwen3-4B model across multiple datasets, predicted answers change in only 32% of queries. After the last change, an average of 760 additional reasoning tokens are generated, representing a substantial portion of the total output. Early stopping heuristics, such as probe-based stopping, reduce token usage by 500 per query with a 2% accuracy drop.
What carries the argument
Forced answer completion, which elicits the model's intermediate predictions by appending a prompt for the final answer at partial reasoning prefixes. It tracks when the answer stabilizes.
If this is right
- A substantial portion of chain-of-thought generation consists of post-decision explanation rather than active decision making.
- Simple heuristics for early stopping can reduce token usage by hundreds per query.
- Accuracy remains nearly the same when generation stops after the answer has stabilized.
- Inference latency and cost can be lowered by halting redundant reasoning steps.
Where Pith is reading between the lines
- Models may benefit from training that encourages shorter reasoning paths from the start.
- The early-fixation pattern could appear in other tasks or larger models beyond those tested.
- Early stopping could combine with existing efficiency methods to further cut inference costs.
- The results raise the possibility that chain-of-thought serves partly as formatting rather than discovery.
Load-bearing premise
Forcing the model to output an answer at an intermediate reasoning prefix accurately reveals the point at which its final decision is fixed, without the forcing itself altering the decision process.
What would settle it
Comparing answer changes and final accuracy when using forced probes versus uninterrupted generation on identical queries to check whether the forcing step itself shifts the model's decision.
Figures





























read the original abstract
Large Language Models often achieve strong performance by generating long intermediate chain-of-thought reasoning. However, it remains unclear when a model's final answer is actually determined during generation. If the answer is already fixed at an intermediate stage, subsequent reasoning tokens may constitute post-decision explanation, increasing inference cost and latency without improving correctness. We study the evolution of predicted answers over reasoning steps using forced answer completion, which elicits the model's intermediate predictions at partial reasoning prefixes. Focusing on Qwen3-4B and averaging results across all datasets considered, we find that predicted answers change in only 32% of queries. Moreover, once the final answer switch occurs, the model generates an average of 760 additional reasoning tokens per query, accounting for a substantial fraction of the total reasoning budget. Motivated by these findings, we investigate early stopping strategies that halt generation once the answer has stabilized. We show that simple heuristics, including probe-based stopping, can reduce reasoning token usage by 500 tokens per query while incurring only a 2% drop in accuracy. Together, our results indicate that a large portion of chain-of-thought generation is redundant and can be reduced with minimal impact on performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs fix their final answers early during chain-of-thought generation. Using forced answer completion (inserting an answer-eliciting prompt after partial CoT prefixes) on Qwen3-4B averaged across datasets, predicted answers change in only 32% of queries; after the last switch the model still emits an average of 760 reasoning tokens. Simple early-stopping heuristics (including probe-based) are shown to cut ~500 tokens per query at a 2% accuracy cost, implying that much post-stabilization CoT is redundant post-decision explanation.
Significance. If the core measurements are valid, the work supplies a practical route to lower inference cost and latency for CoT models while preserving accuracy. The empirical quantification of answer stabilization timing and the token-budget savings are concrete and actionable; the early-stopping results constitute a falsifiable, immediately deployable contribution.
major comments (2)
- [Methods (forced answer completion procedure)] The central measurement (32% answer-change rate and the 760-token post-switch budget) rests on forced answer completion. No ablation tests whether inserting the probe prompt (e.g., “So the answer is”) itself shifts token probabilities or internal state relative to uninterrupted continuation; without such controls (prompt wording, temperature, or alternative read-outs such as logit inspection), the reported statistics may be artifacts of the intervention rather than evidence of natural early fixation.
- [Results / Experiments] Results section: the headline numbers (32% change rate, 760 additional tokens, 500-token savings at 2% accuracy drop) are presented without dataset sizes, number of queries, per-dataset breakdowns, variance across runs, or statistical significance tests. These omissions make it impossible to assess whether the averaged figures are robust or driven by a few datasets.
minor comments (1)
- [Notation and figures] Notation for “final answer switch” and “probe-based stopping” should be defined once with a short equation or pseudocode before being used in figures and tables.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight important aspects of our methodology and presentation that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Methods (forced answer completion procedure)] The central measurement (32% answer-change rate and the 760-token post-switch budget) rests on forced answer completion. No ablation tests whether inserting the probe prompt (e.g., “So the answer is”) itself shifts token probabilities or internal state relative to uninterrupted continuation; without such controls (prompt wording, temperature, or alternative read-outs such as logit inspection), the reported statistics may be artifacts of the intervention rather than evidence of natural early fixation.
Authors: We acknowledge that the forced-answer-completion procedure is an intervention and that we did not include explicit ablations comparing probe insertion to fully uninterrupted generation or alternative read-outs such as logit inspection. Our choice of a short, standard prompt (“So the answer is”) was intended to minimize disruption while still eliciting the model’s current prediction; the low observed change rate (32%) and consistency across datasets provide indirect support that the measurement reflects genuine stabilization rather than prompt-induced artifacts. Nevertheless, to strengthen the claim, the revised manuscript will add a dedicated paragraph in the Methods section discussing potential intervention effects and will report new ablation results using (i) varied prompt phrasings, (ii) different temperatures, and (iii) logit-based answer extraction on a subset of queries. These additions will be placed before the main results to allow readers to assess robustness. revision: partial
-
Referee: [Results / Experiments] Results section: the headline numbers (32% change rate, 760 additional tokens, 500-token savings at 2% accuracy drop) are presented without dataset sizes, number of queries, per-dataset breakdowns, variance across runs, or statistical significance tests. These omissions make it impossible to assess whether the averaged figures are robust or driven by a few datasets.
Authors: We apologize for the omission of these details in the submitted version. The experiments were run on the full set of datasets referenced in the paper (totaling several thousand queries). In the revised manuscript we will expand the Results section to include: (1) a table listing each dataset, its size, and the number of queries evaluated; (2) per-dataset breakdowns of the 32% change rate, post-switch token count, and early-stopping savings; (3) standard deviations across multiple runs; and (4) statistical significance tests (paired t-tests or Wilcoxon tests) for the accuracy differences between full CoT and early-stopping conditions. These additions will make the robustness of the headline averages transparent. revision: yes
Circularity Check
No circularity; claims rest on direct empirical measurements
full rationale
The paper reports observational statistics obtained by applying forced answer completion probes to partial CoT prefixes and counting answer changes plus subsequent tokens. These quantities (32% change rate, 760-token average) are measured outputs, not quantities fitted to data and then re-presented as predictions, nor self-defined via the result itself. No equations, uniqueness theorems, or ansatzes are invoked that reduce the central claims to prior inputs by construction. The early-stopping heuristics are motivated by the observations but remain independent proposals whose performance is separately evaluated. No load-bearing self-citations appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forcing an answer at an intermediate prefix does not change the model's committed final answer relative to uninterrupted generation.
Forward citations
Cited by 1 Pith paper
-
LLMs Should Not Yet Be Credited with Decision Explanation
LLMs support decision prediction and rationale generation but lack evidence for genuine decision explanation, requiring stricter standards to avoid over-crediting.
Reference graph
Works this paper leans on
-
[1]
Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy
URL https://matharena.ai/. Bogdan, P. C., Macar, U., Nanda, N., and Conmy, A. Thought anchors: Which llm reasoning steps matter? arXiv preprint arXiv:2506.19143,
-
[2]
doi: 10.1038/s41586-025-09962-4. URL https://arxiv.org/abs/2501.14249. Karpas, E., Abend, O., Belinkov, Y ., Lenz, B., Lieber, O., Ratner, N., Shoham, Y ., Bata, H., Levine, Y ., Leyton- Brown, K., et al. Mrkl systems: A modular, neuro- symbolic architecture that combines large language mod- els, external knowledge sources and discrete reasoning. arXiv pr...
work page internal anchor Pith review doi:10.1038/s41586-025-09962-4
-
[3]
Can language models learn from explanations in context? InFindings of the Association for Computa- tional Linguistics: EMNLP 2022, pp
Lampinen, A., Dasgupta, I., Chan, S., Mathewson, K., Tessler, M., Creswell, A., McClelland, J., Wang, J., and Hill, F. Can language models learn from explanations in context? InFindings of the Association for Computa- tional Linguistics: EMNLP 2022, pp. 537–563,
2022
-
[4]
Measuring Faithfulness in Chain-of-Thought Reasoning
Lanham, T., Chen, A., Radhakrishnan, A., Steiner, B., Deni- son, C., Hernandez, D., Li, D., Durmus, E., Hubinger, E., Kernion, J., Luko ˇsi¯ut˙e, K., Nguyen, K., Cheng, N., Joseph, N., Schiefer, N., Rausch, O., Larson, R., McCan- dlish, S., Kundu, S., Kadavath, S., Yang, S., Henighan, T., Maxwell, T., Telleen-Lawton, T., Hume, T., Hatfield- Dodds, Z., Kap...
-
[5]
Liang, X., Song, S., Zheng, Z., Wang, H., Yu, Q., Li, X., Li, R.-H., Wang, Y ., Wang, Z., Xiong, F., et al. Internal consistency and self-feedback in large language models: A survey.arXiv preprint arXiv:2407.14507,
-
[6]
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and 9 Submission and Formatting Instructions for ICML 2026 Cobbe, K. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review arXiv 2026
-
[7]
Mao, Z. and Venkat, A. Recurrent confidence chain: Temporal-aware uncertainty quantification in large lan- guage models.arXiv preprint arXiv:2601.13368,
-
[8]
K., Singhu, S., and Ruchkin, I
Mao, Z., Venkat, A., Bisliouk, A., Kothiyal, A., Subra- manian, S. K., Singhu, S., and Ruchkin, I. Confidence over time: Confidence calibration with temporal logic for large language model reasoning.arXiv preprint arXiv:2601.13387,
-
[9]
Mei, Z., Zhang, C., Yin, T., Lidard, J., Shorinwa, O., and Majumdar, A. Reasoning about uncertainty: Do reason- ing models know when they don’t know?arXiv preprint arXiv:2506.18183,
-
[10]
Plaat, A., Wong, A., Verberne, S., Broekens, J., Van Stein, N., and B¨ack, T
URLhttps://arxiv.org/abs/2406.11811. Plaat, A., Wong, A., Verberne, S., Broekens, J., Van Stein, N., and B¨ack, T. Multi-step reasoning with large language models, a survey.ACM Computing Surveys, 58(6):1–35,
-
[11]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
URL https://arxiv.org/abs/2311.12022. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[12]
What evidence do language models find convincing?arXiv preprint arXiv:2402.11782,
Wan, A., Wallace, E., and Klein, D. What evidence do language models find convincing?arXiv preprint arXiv:2402.11782,
-
[13]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency im- proves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review arXiv
-
[14]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
URL https://arxiv.org/abs/2406.01574. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V ., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837,
work page internal anchor Pith review arXiv
-
[15]
arXiv preprint arXiv:1908.04626 , year=
Wiegreffe, S. and Pinter, Y . Attention is not not explanation. arXiv preprint arXiv:1908.04626,
-
[16]
URL https: //arxiv.org/abs/2505.09388. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y . React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations,
work page internal anchor Pith review arXiv
-
[17]
Reasoning models better express their confidence.arXiv preprint arXiv:2505.14489,
Yoon, D., Kim, S., Yang, S., Kim, S., Kim, S., Kim, Y ., Choi, E., Kim, Y ., and Seo, M. Reasoning models better express their confidence.arXiv preprint arXiv:2505.14489,
-
[18]
Zhang, B. and Zhang, R. Cot-uq: Improving response-wise uncertainty quantification in llms with chain-of-thought. arXiv preprint arXiv:2502.17214,
-
[19]
answer":
URL https://openreview.net/forum? id=WZH7099tgfM. 10 Submission and Formatting Instructions for ICML 2026 A. Datasets We use the sample sizes described in Table 2 to conduct our analyses and early stopping experiments for all the datasets. We shuffle and randomly sample from the dataset to obtain samples. DatasetS MCQ 1000 Numeric-answer 500 Search-query ...
2026
-
[20]
C.2.1. RANDOM PROBING Table 16.MCQ Accuracy drop Tokens saved Token % 24.390 1764 99.5 24.429 1762 99.4 24.527 1759 99.2 24.527 1755 99.0 24.473 1751 98.8 24.571 1745 98.4 24.732 1735 97.9 24.707 1721 97.0 24.141 1690 95.3 22.459 1608 90.7 19.107 1468 82.8 9.112 854 48.2 0.488 0 0.0 Table 17.Numeric-answer Accuracy drop Tokens saved Token % 59.722 2920 99...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.