Recognition: unknown
Selective Depthwise Separable Convolution for Lightweight Joint Source-Channel Coding in Wireless Image Transmission
Pith reviewed 2026-05-08 09:20 UTC · model grok-4.3
The pith
Selective replacement of standard convolutions with depthwise separable ones at intermediate layers in joint source-channel coding reduces parameters while keeping reconstruction quality nearly intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
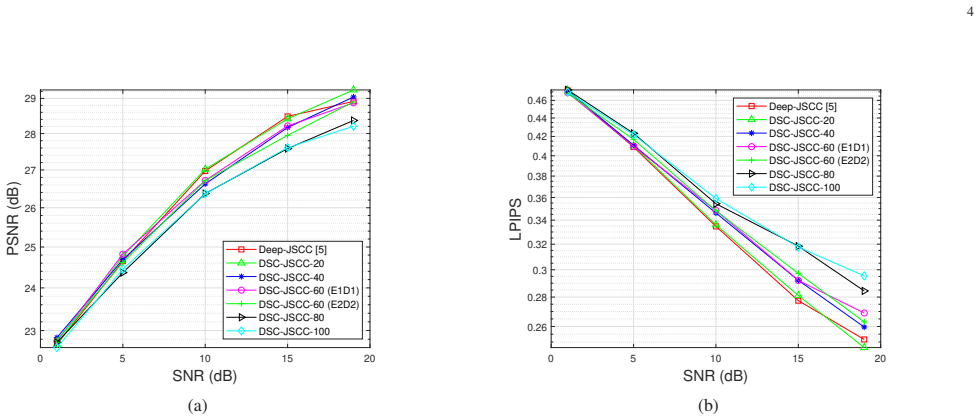
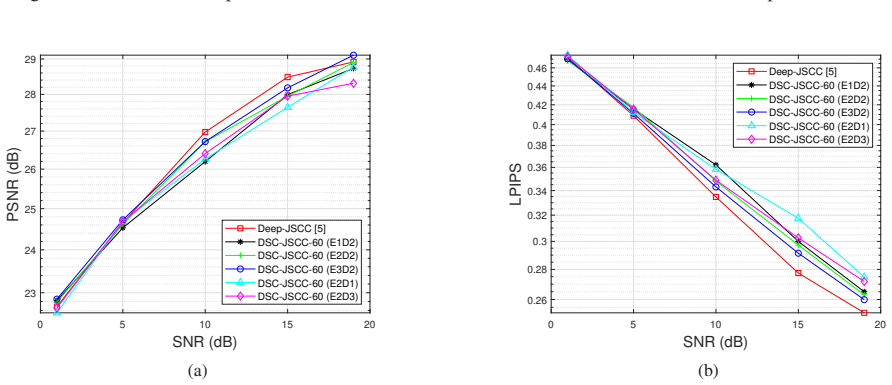
By enabling selective Conv-to-DSConv replacement at chosen layer positions and ratios inside a DL-based JSCC encoder-decoder pair, the framework produces families of models whose parameter counts can be reduced by large factors; experiments indicate that intermediate-layer replacements deliver the smallest quality penalty for a given compression level, exposing layer-wise redundancy in the learned representations used for joint source and channel coding.
What carries the argument
The selective replacement strategy, which specifies both the positions (encoder or decoder depth) and the ratio of layers converted from standard convolution to depthwise separable convolution, allowing systematic measurement of complexity versus reconstruction quality.
If this is right
- Varying the replacement ratio produces a continuous family of models whose sizes and accuracies can be traded off without separate training runs.
- Encoder and decoder depths are not symmetric in sensitivity: middle layers tolerate the DSConv change better than early or late layers.
- The resulting lightweight models remain functional for wireless image delivery on devices with tight memory or compute budgets.
Where Pith is reading between the lines
- The same layer-wise redundancy pattern may appear in other convolutional autoencoders used for compression or denoising, suggesting a general way to prune depthwise operations.
- Designers could pre-compute a small lookup table of replacement masks for a given backbone and then pick the mask that meets a target latency constraint at deployment time.
Load-bearing premise
The complexity-performance trade-off seen when replacing intermediate layers will remain similar when the same strategy is applied to new image datasets, different channel models, or wider ranges of signal-to-noise ratios.
What would settle it
Run the identical selective replacement schedule on a second dataset such as CIFAR-100 or under a different fading channel model and check whether the performance advantage of intermediate-layer swaps disappears or reverses.
Figures


read the original abstract
Depthwise separable convolutional (DSConv) layers have been successfully applied to deep learning (DL)-based joint source-channel coding (JSCC) schemes to reduce computational complexity. However, a systematic investigation of the layerwise and ratio-wise replacement of standard convolutional (Conv) layers with DSConv layers in JSCC systems for wireless image transmission remains largely unexplored. In this letter, we propose a configurable lightweight JSCC framework that incorporates a selective replacement strategy, enabling flexible substitution of standard Conv layers with DSConv layers at various layer positions and replacement ratios. By adjusting the proportion of layers replaced, we achieve different model compression levels and analyze their impact on reconstruction performance. Furthermore, we investigate how replacements at different encoder and decoder depths influence reconstruction quality under a fixed replacement ratio. Our results show that Conv-to-DSConv replacement at intermediate layers achieves a favorable complexity-performance trade-off, revealing layer-wise redundancy in DL-based JSCC systems. Extensive experiments further demonstrate that the proposed framework achieves substantial parameter reduction with only slight performance degradation, enabling flexible complexity-performance trade-offs for resource-constrained edge devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a configurable lightweight JSCC framework for wireless image transmission that selectively replaces standard Conv layers with DSConv layers at chosen encoder/decoder positions and replacement ratios. Experiments are used to show that intermediate-layer replacements yield the best complexity-performance trade-off, with substantial parameter reduction and only slight reconstruction degradation, thereby exposing layer-wise redundancy in DL-based JSCC architectures.
Significance. If the empirical trade-off holds under broader conditions, the work would supply a practical, tunable compression technique for deploying JSCC models on resource-limited edge devices and would offer architectural insight into where redundancy occurs in such networks. The configurable replacement mechanism itself constitutes a reusable design pattern for complexity control.
major comments (2)
- [§4] §4 (Experimental Results): the central claim that 'Conv-to-DSConv replacement at intermediate layers achieves a favorable complexity-performance trade-off' rests on unspecified quantitative outcomes; no tables, PSNR/SSIM values, parameter counts, error bars, or ablation results across datasets and channel models are referenced, leaving the 'slight degradation' and optimality of intermediate positions unverified and potentially setup-specific.
- [§3] §3 (Proposed Framework): the selective replacement strategy is presented as enabling flexible trade-offs, yet no equations define the replacement ratio, the resulting parameter count reduction, or the modified network architecture; without such formalization the reported 'substantial parameter reduction' cannot be reproduced or generalized.
minor comments (2)
- The abstract would be strengthened by including at least one concrete numerical example (e.g., 'X% parameter reduction at Y dB SNR with Z dB PSNR loss') to allow immediate assessment of the claimed trade-off.
- Figure captions and axis labels should explicitly state the channel model, SNR range, and dataset used so that the reported layer-wise results can be interpreted without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to improve the manuscript. We address each major comment point by point below. Revisions will be incorporated in the next version to enhance clarity, reproducibility, and verifiability of the results.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results): the central claim that 'Conv-to-DSConv replacement at intermediate layers achieves a favorable complexity-performance trade-off' rests on unspecified quantitative outcomes; no tables, PSNR/SSIM values, parameter counts, error bars, or ablation results across datasets and channel models are referenced, leaving the 'slight degradation' and optimality of intermediate positions unverified and potentially setup-specific.
Authors: We appreciate this observation. The original manuscript presents results primarily through figures (PSNR vs. SNR curves and parameter counts for varying replacement positions and ratios). To address the concern directly, we will add a dedicated table in the revised §4 summarizing quantitative outcomes: average PSNR/SSIM values, exact parameter counts before/after replacement, and ablation results across datasets (CIFAR-10, Kodak) and channel models (AWGN, Rayleigh fading). Multiple-run error bars will be included in updated figures. This will explicitly verify the slight degradation and confirm the optimality of intermediate-layer replacements under the tested conditions. revision: yes
-
Referee: [§3] §3 (Proposed Framework): the selective replacement strategy is presented as enabling flexible trade-offs, yet no equations define the replacement ratio, the resulting parameter count reduction, or the modified network architecture; without such formalization the reported 'substantial parameter reduction' cannot be reproduced or generalized.
Authors: We agree that the lack of formalization limits reproducibility. In the revised §3, we will introduce explicit definitions: the replacement ratio ρ (0 ≤ ρ ≤ 1) as the fraction of standard Conv layers substituted by DSConv layers at chosen positions; the parameter count for a Conv layer as C_in × C_out × K² and for DSConv as C_in × K² + C_in × C_out (depthwise separable decomposition), yielding a reduction factor of roughly 1/K² for typical K=3 and large C_out; and a precise description of the modified architecture (e.g., encoder layers 2–5 and decoder layers 3–6 replaced at ρ=0.5). These additions will enable exact reproduction and generalization of the reported parameter reductions. revision: yes
Circularity Check
No circularity: empirical validation of configurable JSCC replacement strategy
full rationale
The paper proposes a selective Conv-to-DSConv replacement framework for lightweight JSCC and reports experimental outcomes on parameter reduction and reconstruction quality under specific conditions. No equations, derivations, fitted parameters, or self-citations appear in the provided text that reduce any central claim to its own inputs by construction. Results are presented as direct simulation findings rather than predictions forced by prior definitions or ansatzes. This is a standard empirical architecture study whose claims rest on observed trade-offs, not on self-referential logic.
Axiom & Free-Parameter Ledger
free parameters (2)
- replacement ratio
- layer positions
axioms (1)
- domain assumption Depthwise separable convolutions can substitute for standard convolutions with acceptable accuracy loss in image-processing networks
Reference graph
Works this paper leans on
-
[1]
AI- Generated incentive mechanism and full-duplex semantic co mmunica- tions for information sharing,
H. Du, J. Wang, D. Niyato, J. Kang, Z. Xiong, and D. I. Kim, “ AI- Generated incentive mechanism and full-duplex semantic co mmunica- tions for information sharing,” IEEE J. Sel. Areas Commun. , vol. 41, no. 9, pp. 2981-2997, Sep. 2023
2023
-
[2]
Multimoda l- oriented interactive joint source-channel coding for ligh tweight semantic communication,
X. Niu, L. Tan, J. Wu, W. Y uan, and T. Q. S. Quek, “Multimoda l- oriented interactive joint source-channel coding for ligh tweight semantic communication,” IEEE Trans. V eh. Technol., vol. 74, no. 10, pp. 16516- 16520, Oct. 2025
2025
-
[3]
Lightweight sema ntic com- munication for wireless image transmission,
J. Tu, X. Liu, Y . Wei, F. Zhou, and S. Ma, “Lightweight sema ntic com- munication for wireless image transmission,” IEEE Wireless Commun. Lett., vol. 14, no. 12, pp. 4132-4136, Dec. 2025
2025
-
[4]
Deep joint source-channel coding for adaptive image transmissi on over MIMO channels,
H. Wu, Y . Shao, C. Bian, K. Mikolajczyk, and D. G¨ und¨ uz, “ Deep joint source-channel coding for adaptive image transmissi on over MIMO channels,” IEEE Trans. Wireless Commun. , vol. 23, no. 10, pp. 15002- 15017, Oct. 2024
2024
-
[5]
Deep joi nt source- channel coding for wireless image transmission,
E. Bourtsoulatze, D. B. Kurka, and D. G¨ und¨ uz, “Deep joi nt source- channel coding for wireless image transmission,” IEEE Trans. Cogn. Commun. Netw., vol. 5, no. 3, pp. 567-579, Sep. 2019
2019
-
[6]
Generative joint source-channel coding for semantic image transmissi on,
E. Erdemir, T. -Y . Tung, P . L. Dragotti, and D. G¨ und¨ uz, “ Generative joint source-channel coding for semantic image transmissi on,” IEEE J. Sel. Areas Commun. , vol. 41, no. 8, pp. 2645-2657, Aug. 2023
2023
-
[7]
Lightweight diffusion models fo rresource-constrained s emantic com- munication,
E. Grassucci, G. Pignata, G. Cicchetti, and D. Comminiel lo, “Lightweight diffusion models fo rresource-constrained s emantic com- munication,” IEEE Wireless Commun. Lett. , vol. 14, no. 9, pp. 2743- 2747, Sept. 2025
2025
-
[8]
Secure transm ission in wireless semantic communications with adversarial trai ning,
J. Shi, Q. Zhang, W. Zeng, S. Li, and Z. Qin, “Secure transm ission in wireless semantic communications with adversarial trai ning,” IEEE Commun. Lett. , vol. 29, no. 3, pp. 487-491, Mar. 2025
2025
-
[9]
Lightweight joint so urce-channel coding for semantic communications,
Y . Jia, Z. Huang, K. Luo, and W.Wen, “Lightweight joint so urce-channel coding for semantic communications,” IEEE Commun. Lett. , vol. 27, no. 12, pp. 3161–3165, Dec. 2023
2023
-
[10]
Lightweight and robust wireless semant ic communi- cations,
G. Chen et al., “Lightweight and robust wireless semant ic communi- cations,” IEEE Commun. Lett. , vol. 28, no. 11, pp. 2633-2637, Nov. 2024
2024
-
[11]
Light weight and adaptive deep coding for wireless image transmission in semantic Communication,
Y . Sun, J. Wang, L. Wei, H. Chen, S. Dang, and X. Li, “Light weight and adaptive deep coding for wireless image transmission in semantic Communication,” IEEE Access , vol. 13, pp. 158285-158301, 2025
2025
-
[12]
T ask-oriented JSCC with adaptive deep compressed sensing,
M. A. Jarrahi, E. Bourtsoulatze, and V . Abolghasemi, “T ask-oriented JSCC with adaptive deep compressed sensing,” IEEE Wireless Commun. Lett., to be published
-
[13]
A novel light weight deep joint source-channel coding framework: Using 1D-CNN f or SNR and compression rate adaptation,
T. Guo, S. Gu, Y . Wu, Q. Zhang, and W. Xiang, “A novel light weight deep joint source-channel coding framework: Using 1D-CNN f or SNR and compression rate adaptation,” in Proc. IEEE/CIC Int. Conf. Com- mun. China , Aug. 2025, pp. 1-6
2025
-
[14]
A novel lightweight j oint source- channel coding design in semantic communications,
X. Y u, D. Li, N. Zhang, and X. Shen, “A novel lightweight j oint source- channel coding design in semantic communications,” IEEE Internet Things J. , vol. 12, no. 11, pp. 18447-18450, Jun. 2025
2025
-
[15]
Deep learning face a ttributes in the wild,
Z. Liu, P . Luo, X. Wang, and X. Tang, “Deep learning face a ttributes in the wild,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV) , Santiago, Chile, 2015, pp. 3730-3738
2015
-
[16]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progress ive grow- ing of GANs for improved quality, stability, and variation, ” 2017, arXiv:1710.10196
work page internal anchor Pith review arXiv 2017
-
[17]
The unreasonable effectiveness of deep features as a perceptua l metric,
R. Zhang, P . Isola, A. A. Efros, E. Shechtman, and O. Wang , “The unreasonable effectiveness of deep features as a perceptua l metric,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. , Jun. 2018, pp. 586-595
2018
-
[18]
Optimizing depthwise sepa rable convolution operations on GPUs,
G. Lu, W. Zhang, and Z. Wang, “Optimizing depthwise sepa rable convolution operations on GPUs,” IEEE Trans. Parallel Distrib. Syst. , vol. 33, no. 1, pp. 70-87, 1 Jan. 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.