Recognition: unknown
CNSL-bench: Benchmarking the Sign Language Understanding Capabilities of MLLMs on Chinese National Sign Language
Pith reviewed 2026-05-08 11:43 UTC · model grok-4.3
The pith
Current MLLMs perform substantially worse than humans at understanding Chinese National Sign Language, with clear gaps across input types and signing styles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CNSL-bench supplies the first large-scale, dictionary-grounded collection of Chinese National Sign Language examples that align textual glosses, still images, and video clips while tagging each item by articulatory form. When 21 current MLLMs are run on the benchmark, their accuracy stays well below human levels and varies systematically by modality and by whether the sign uses air-writing, finger-spelling, or the manual alphabet; diagnostic checks indicate that these shortfalls are not removed by stronger reasoning alone and that instruction-following stability differs markedly across models.
What carries the argument
CNSL-bench, the benchmark that supplies aligned text, image, and video data anchored to the National Common Sign Language Dictionary and broken down by manual articulatory form.
If this is right
- MLLMs require targeted gains in processing sign-language video and image streams beyond current multimodal training.
- Instruction-following reliability must be improved separately from raw reasoning capacity.
- Performance differences across air-writing, finger-spelling, and manual-alphabet items point to uneven coverage of articulatory detail in existing training data.
- Human baselines set a concrete target that future models can be measured against on the same fixed items.
Where Pith is reading between the lines
- Wider adoption of such benchmarks could accelerate development of sign-language interfaces for Chinese deaf users.
- The same evaluation design could be replicated for other national sign languages to test whether similar modality gaps appear.
- If instruction-following varies so much, prompt engineering or fine-tuning for signed input may yield quick gains without full model retraining.
Load-bearing premise
The tasks in the benchmark truly isolate sign-language comprehension rather than being solved mainly by general visual recognition or ordinary language skills.
What would settle it
A new MLLM that reaches human accuracy on the full CNSL-bench suite while still showing the same modality and form differences would indicate the reported gaps are not fundamental.
Figures













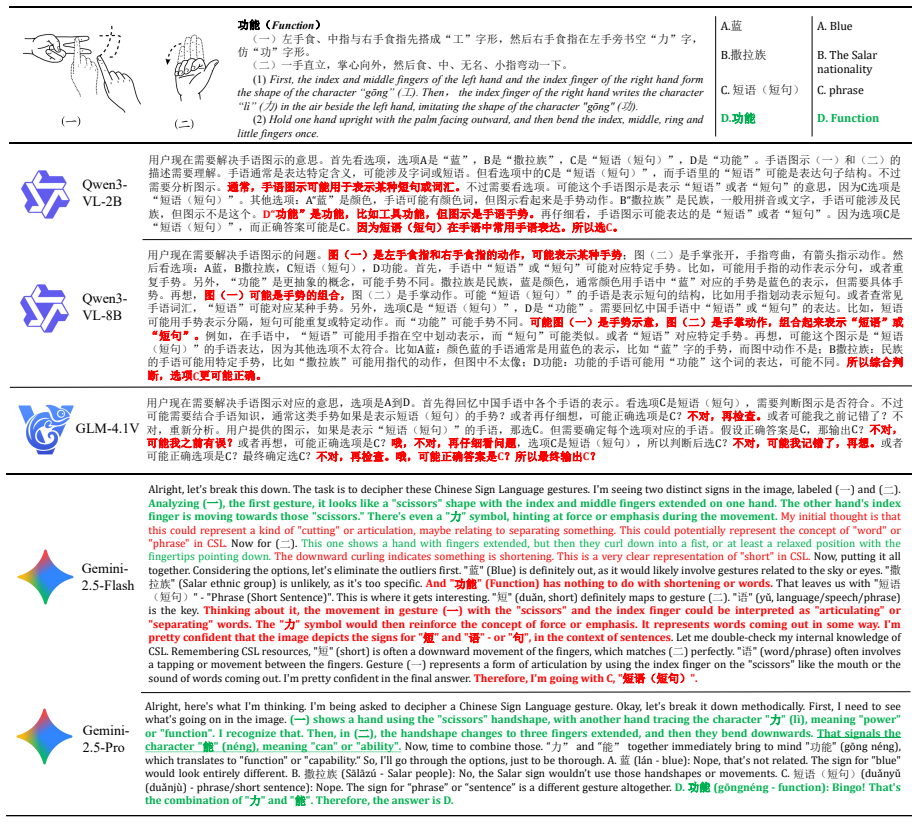
read the original abstract
Sign language research has achieved significant progress due to the advances in large language models (LLMs). However, the intrinsic ability of LLMs to understand sign language, especially in multimodal contexts, remains underexplored. To address this limitation, we introduce CNSL-bench, the first comprehensive Chinese em{National Sign Language benchmark designed for evaluating multimodal large language models (MLLMs) in sign language understanding. The proposed CNSL-bench is characterized by: 1) Authoritative grounding, as it is anchored to the officially standardized \textit{National Common Sign Language Dictionary, mitigating ambiguity from regional or non-canonical variants and ensuring consistent semantic definitions; 2) Multimodal coverage, providing aligned textual descriptions, illustrative images, and sign language videos; and 3) Articulatory diversity, supporting fine-grained analysis across key manual articulatory forms, including air-writing, finger-spelling, and the Chinese manual-alphabet. Using CNSL-bench, we extensively evaluate 21 open-source and proprietary up-to-date MLLMs. Our results reveal that, despite recent advances in multimodal modeling, current MLLMs remain substantially inferior to human performance, exhibiting systematic disparities across input modalities and manual articulatory forms. Additional diagnostic analyses suggest that several performance limitations persist beyond improvements in reasoning and that instruction-following robustness varies substantially across models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CNSL-bench, the first benchmark for Chinese National Sign Language understanding in multimodal large language models (MLLMs). It is anchored to the officially standardized National Common Sign Language Dictionary, supplies aligned textual descriptions, images, and videos, and supports analysis across articulatory forms including air-writing, finger-spelling, and the Chinese manual alphabet. The authors evaluate 21 open-source and proprietary MLLMs and report that current models remain substantially inferior to human performance while exhibiting systematic disparities across input modalities and manual articulatory forms.
Significance. If the benchmark labels prove reliable, the work supplies the first large-scale, multimodal resource for CNSL and documents clear performance gaps in existing MLLMs. The combination of authoritative dictionary grounding, multimodal alignment, and articulatory stratification offers a reusable testbed that could drive targeted improvements in sign-language multimodal modeling.
major comments (2)
- [Benchmark construction] Benchmark construction section: the claim that anchoring to the National Common Sign Language Dictionary 'mitigates ambiguity from regional or non-canonical variants' is presented without any reported verification (e.g., inter-signer agreement scores, independent expert review of video fidelity, or checks for residual idiolectal variation). This verification is load-bearing for the central claim that observed model errors and modality/articulatory disparities can be attributed to model limitations rather than label noise.
- [Evaluation and results] Evaluation section: the manuscript reports human baselines and systematic disparities yet provides no dataset cardinality, exact task formulations (e.g., recognition vs. translation vs. multiple-choice), statistical testing procedures, or human-baseline collection protocol. These omissions prevent independent assessment of whether the reported performance gaps are statistically robust or reproducible.
minor comments (1)
- [Abstract] Abstract: the statement that 21 models were evaluated would be strengthened by naming the models or at least indicating the split between open-source and proprietary systems.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, providing clarifications and indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the claim that anchoring to the National Common Sign Language Dictionary 'mitigates ambiguity from regional or non-canonical variants' is presented without any reported verification (e.g., inter-signer agreement scores, independent expert review of video fidelity, or checks for residual idiolectal variation). This verification is load-bearing for the central claim that observed model errors and modality/articulatory disparities can be attributed to model limitations rather than label noise.
Authors: We agree that additional verification details would strengthen the presentation. The CNSL-bench is directly anchored to the officially published National Common Sign Language Dictionary, which is the government-standardized reference intended to define canonical forms and reduce regional or idiolectal variation by design. The videos and images are sourced from the dictionary's official materials without modification. We have revised the Benchmark construction section to include an expanded description of the data sourcing and curation process, along with references to the dictionary's standardization authority. While we did not conduct new inter-signer agreement studies (as the source material is already standardized), this revision clarifies the basis for attributing errors primarily to model limitations rather than label noise. revision: partial
-
Referee: [Evaluation and results] Evaluation section: the manuscript reports human baselines and systematic disparities yet provides no dataset cardinality, exact task formulations (e.g., recognition vs. translation vs. multiple-choice), statistical testing procedures, or human-baseline collection protocol. These omissions prevent independent assessment of whether the reported performance gaps are statistically robust or reproducible.
Authors: We acknowledge that these methodological details were not presented with sufficient explicitness in the initial submission. We have revised the Evaluation section to include the dataset cardinality, precise task formulations (covering recognition, translation, and multiple-choice variants), the statistical testing procedures used to assess significance of gaps and disparities, and the full human-baseline collection protocol (including participant criteria and agreement measures). These additions enable independent verification of the robustness and reproducibility of the reported results. revision: yes
Circularity Check
No circularity: benchmark introduction and external evaluations are self-contained.
full rationale
The paper introduces CNSL-bench as a new dataset anchored to an external official dictionary and reports empirical evaluations of 21 third-party MLLMs. No equations, fitted parameters, predictions, or derivations appear in the provided text. Central claims rest on direct model performance measurements rather than any self-referential construction, self-citation chain, or renamed prior result. The anchoring assumption is an external grounding claim, not a definitional loop. This matches the default expectation of no significant circularity for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The National Common Sign Language Dictionary provides unambiguous and authoritative semantic definitions for signs.
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Studying and mitigating biases in sign lan- guage understanding models. InProceedings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing, pages 268–283, Miami, Florida, USA. Association for Computational Lin- guistics. Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zho...
work page internal anchor Pith review arXiv 2024
-
[2]
因为 (because/due to)
Part (二) shows the dominant hand signifying the reason placing into the palm of the other hand representing the result. Considering this, option C, "因为 (because/due to)", looks like the clear winner. ...... First, I see two distinct movements. Movement (一) involves a typing motion, palms down, fingers bent, hands moving up and down slightly. That's clearl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.