Recognition: unknown
Point & Grasp: Flexible Selection of Out-of-Reach Objects Through Probabilistic Cue Integration
Pith reviewed 2026-05-08 10:41 UTC · model grok-4.3
The pith
Probabilistic integration of pointing and grasp cues enables accurate selection of out-of-reach objects in mixed reality despite cue ambiguity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present Point&Grasp, a technique that uses probabilistic cue integration to flexibly combine pointing direction and grasp gestures for inferring user intent when selecting out-of-reach objects. A likelihood model trained on the new Out-of-Reach Grasping dataset captures grasping patterns, allowing the system to handle ambiguity without relying on a single dominant cue or deterministic rules.
What carries the argument
The probabilistic cue integration framework that fuses pointing direction with a grasp gesture likelihood model trained on out-of-reach data to infer selection intent.
If this is right
- The method achieves higher accuracy and faster selection times than single-cue approaches.
- It maintains practical effectiveness against state-of-the-art techniques under different ambiguity sources.
- Flexible cue combination prevents performance drops when one cue becomes unreliable.
Where Pith is reading between the lines
- Extending this to more cues such as head orientation could further enhance intent inference in MR.
- The need for domain-specific datasets like ORG highlights that general gesture models may not suffice for distant interactions.
- This could influence design of future MR interfaces to encourage natural multi-cue behaviors from users.
Load-bearing premise
That the likelihood model trained on the ORG dataset generalizes to real mixed reality grasping patterns and that probabilistic integration infers intent more reliably than single-cue or deterministic methods.
What would settle it
If a controlled user study with ambiguous cues shows no improvement in accuracy or speed over single-cue baselines, or underperforms state-of-the-art methods, the central claim would be falsified.
Figures


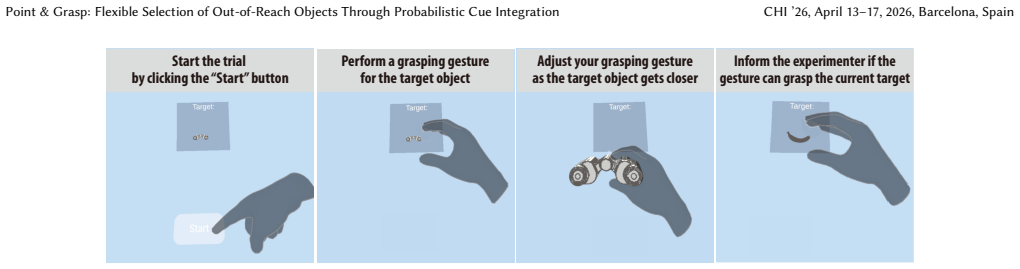
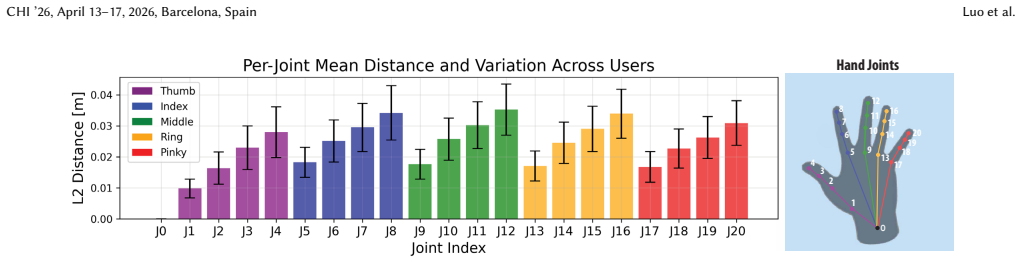

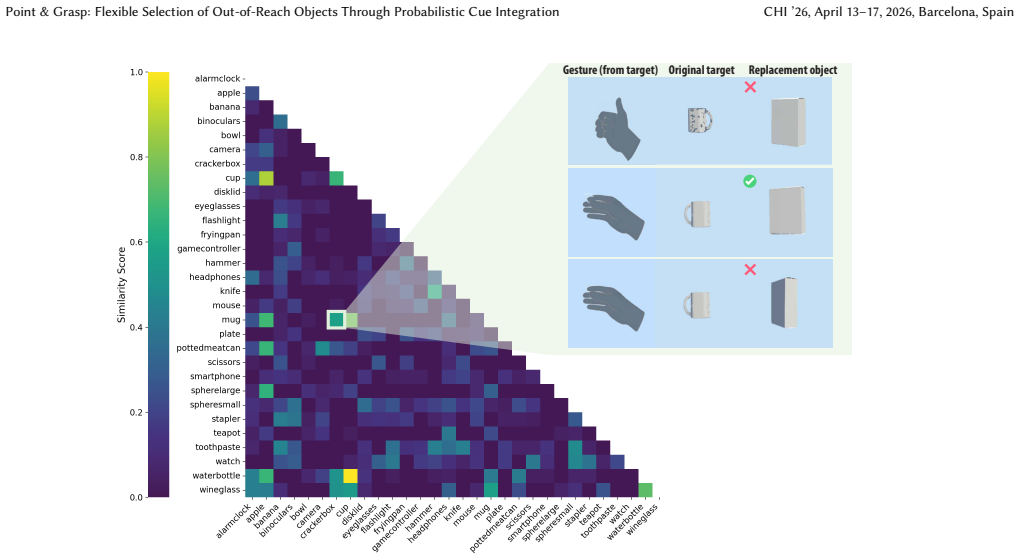







read the original abstract
Selecting out-of-reach objects is a fundamental task in mixed reality (MR). Existing methods rely on a single cue or deterministically fuse multiple cues, leading to performance degradation when the dominant cue becomes unreliable. In this work, we introduce a probabilistic cue integration framework that enables flexible combination of multiple user-generated cues for intent inference. Inspired by natural grasping behavior, we instantiate the framework with pointing direction and grasp gestures as a new interaction technique, Point&Grasp. To this end, we collect the Out-of-Reach Grasping (ORG) dataset to train a robust likelihood model of the gestural cue, which captures grasping patterns not present in existing in-reach datasets. User studies demonstrate that our selection method with cue integration not only improves accuracy and speed over single-cue baselines, but also remains practically effective compared to state-of-the-art methods across various sources of ambiguity. The dataset and code are available at https://github.com/drlxj/point-and-grasp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a probabilistic cue integration framework for selecting out-of-reach objects in mixed reality, instantiated as the Point&Grasp technique that combines pointing direction with grasp gestures. It collects the new Out-of-Reach Grasping (ORG) dataset to train a likelihood model capturing grasp patterns, and reports user studies claiming that cue integration improves accuracy and speed over single-cue baselines while remaining competitive with state-of-the-art methods across ambiguity sources. Dataset and code are released publicly.
Significance. If the user-study evidence and model generalization hold, the work could advance robust intent inference in MR interfaces by replacing deterministic fusion with probabilistic combination that handles unreliable cues. The ORG dataset addresses a clear gap in out-of-reach grasping data, and the open release of data and code is a clear strength supporting reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract: The central claim that cue integration 'improves accuracy and speed over single-cue baselines' and 'remains practically effective compared to state-of-the-art methods' rests on user studies, yet the abstract supplies no participant numbers, study design details, statistical tests, performance metrics, or error analysis. This absence makes it impossible to assess whether the reported gains are statistically reliable or practically meaningful.
- [Methods / Dataset] Likelihood model / ORG dataset section: The framework assumes the likelihood model p(cue|intent) trained on the ORG dataset will generalize to the user-study tasks and real MR conditions. No held-out validation, calibration metrics, or sensitivity analysis is described; if collection conditions (hardware, object set, ambiguity types) differ from the evaluation tasks, any observed advantage may be an artifact of dataset-specific fitting rather than a property of probabilistic integration.
minor comments (2)
- [Framework] The probabilistic integration step would be clearer if accompanied by an explicit equation or pseudocode showing how pointing and grasp posteriors are combined.
- [Evaluation] Figure captions and axis labels in the user-study results should include error bars or confidence intervals to allow visual assessment of the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight important opportunities to strengthen the clarity of our claims and the rigor of our model evaluation. We address each major comment below and will incorporate the suggested revisions into the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that cue integration 'improves accuracy and speed over single-cue baselines' and 'remains practically effective compared to state-of-the-art methods' rests on user studies, yet the abstract supplies no participant numbers, study design details, statistical tests, performance metrics, or error analysis. This absence makes it impossible to assess whether the reported gains are statistically reliable or practically meaningful.
Authors: We agree that the abstract should provide sufficient detail for readers to evaluate the central claims. The original abstract prioritized brevity at the expense of these specifics. In the revised manuscript we will expand the abstract to report the number of participants, a concise summary of the study design, key quantitative results (accuracy and speed improvements with associated statistical tests), and a brief mention of error patterns. This change will make the reported benefits directly verifiable from the abstract. revision: yes
-
Referee: [Methods / Dataset] Likelihood model / ORG dataset section: The framework assumes the likelihood model p(cue|intent) trained on the ORG dataset will generalize to the user-study tasks and real MR conditions. No held-out validation, calibration metrics, or sensitivity analysis is described; if collection conditions (hardware, object set, ambiguity types) differ from the evaluation tasks, any observed advantage may be an artifact of dataset-specific fitting rather than a property of probabilistic integration.
Authors: We acknowledge the importance of demonstrating that the likelihood model generalizes beyond the training conditions. The ORG dataset was collected under conditions chosen to match the ambiguity sources and interaction distances used in the user studies, but the submitted manuscript did not include explicit held-out validation or sensitivity results. We will add these analyses to the revised version: cross-validation performance on the ORG dataset, calibration metrics for the likelihood model, and a sensitivity analysis examining variations in hardware, object sets, and ambiguity types. These additions will provide direct evidence that the advantages of probabilistic cue integration are not an artifact of dataset-specific fitting. revision: yes
Circularity Check
No circularity: empirical validation via new dataset and separate user studies
full rationale
The paper presents a probabilistic cue integration method instantiated as Point&Grasp, trained on a newly collected ORG dataset for the grasp likelihood model and evaluated through independent user studies comparing against single-cue baselines and SOTA methods. No mathematical derivations, equations, or first-principles claims are present that reduce to fitted parameters or self-citations by construction. The central claims rest on data collection and human-subject experiments rather than any self-referential loop, making the work self-contained against external benchmarks with no load-bearing self-citation chains or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sean Andrist, Michael Gleicher, and Bilge Mutlu. 2017. Looking coordinated: Bidirectional gaze mechanisms for collaborative interaction with virtual char- acters. InProceedings of the 2017 CHI conference on human factors in computing systems. 2571–2582. doi:10.1145/3025453.3026033
-
[2]
Ferran Argelaguet and Carlos Andujar. 2013. A survey of 3D object selection techniques for virtual environments.Computers & Graphics37, 3 (2013), 121–136. doi:10.1016/j.cag.2012.12.003
-
[3]
Felipe Bacim, Regis Kopper, and Doug A Bowman. 2013. Design and evaluation of 3D selection techniques based on progressive refinement.International Journal of Human-Computer Studies71, 7-8 (2013), 785–802. doi:10.1016/j.ijhcs.2013.03.003
-
[4]
Marc Baloup, Thomas Pietrzak, and Géry Casiez. 2019. Raycursor: A 3d pointing facilitation technique based on raycasting. InProceedings of the 2019 CHI Confer- ence on Human Factors in Computing Systems. 1–12. doi:10.1145/3290605.3300331
-
[5]
Nikola Banovic, Tofi Buzali, Fanny Chevalier, Jennifer Mankoff, and Anind K Dey. 2016. Modeling and understanding human routine behavior. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems. 248–260. doi:10.1145/2858036.2858557
-
[6]
Bharat Lal Bhatnagar, Xianghui Xie, Ilya A Petrov, Cristian Sminchisescu, Chris- tian Theobalt, and Gerard Pons-Moll. 2022. Behave: Dataset and method for tracking human object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15935–15946. doi:10.1109/cvpr52688. 2022.01547 CHI ’26, April 13–17, 2026, Barcel...
- [7]
-
[8]
Andreea Dalia Blaga, Maite Frutos-Pascual, Chris Creed, and Ian Williams. 2025. VR-Grasp: a human grasp taxonomy for virtual reality.International Journal of Human–Computer Interaction41, 7 (2025), 4406–4422. doi:10.1080/10447318.2024. 2351719
-
[9]
Richard A Bolt. 1980. “Put-that-there” Voice and gesture at the graphics interface. InProceedings of the 7th annual conference on Computer graphics and interactive techniques. 262–270. doi:10.1145/965105.807503
- [10]
-
[11]
Jeffrey Cashion, Chadwick Wingrave, and Joseph J LaViola Jr. 2012. Dense and dynamic 3d selection for game-based virtual environments.IEEE transactions on visualization and computer graphics18, 4 (2012), 634–642. doi:10.1109/tvcg.2012.40
-
[12]
Umberto Castiello. 2005. The neuroscience of grasping.Nature Reviews Neuro- science6, 9 (2005), 726–736. doi:10.1038/nrn1744
- [13]
-
[14]
Woojin Cho, Jihyun Lee, Minjae Yi, Minje Kim, Taeyun Woo, Donghwan Kim, Taewook Ha, Hyokeun Lee, Je-Hwan Ryu, Woontack Woo, et al. 2024. Dense Hand-Object (HO) GraspNet with Full Grasping Taxonomy and Dynamics. In European Conference on Computer Vision. Springer, 284–303. doi:10.1007/978-3- 031-73007-8_17
-
[15]
Marc O Ernst and Martin S Banks. 2002. Humans integrate visual and haptic information in a statistically optimal fashion.Nature415, 6870 (2002), 429–433. doi:10.1038/415429a
-
[16]
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kauf- mann, Michael J Black, and Otmar Hilliges. 2023. ARCTIC: A dataset for dexterous bimanual hand-object manipulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12943–12954. doi:10.1109/cvpr52729. 2023.01244
-
[17]
Sarah F Frisken, Ronald N Perry, Alyn P Rockwood, and Thouis R Jones. 2000. Adaptively sampled distance fields: A general representation of shape for com- puter graphics. InProceedings of the 27th annual conference on Computer graphics and interactive techniques. 249–254. doi:10.1145/344779.344899
-
[18]
Tovi Grossman and Ravin Balakrishnan. 2005. The bubble cursor: enhancing target acquisition by dynamic resizing of the cursor’s activation area. InProceed- ings of the SIGCHI conference on Human factors in computing systems. 281–290. doi:10.1145/1054972.1055012
- [19]
-
[20]
Christopher M Harris and Daniel M Wolpert. 1998. Signal-dependent noise determines motor planning.Nature394, 6695 (1998), 780–784. doi:10.1038/29528
-
[21]
Chris Harrison, Robert Xiao, Julia Schwarz, and Scott E Hudson. 2014. TouchTools: leveraging familiarity and skill with physical tools to augment touch interaction. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems. 2913–2916. doi:10.1145/2556288.2557012
-
[22]
Marc Jeannerod. 1984. The timing of natural prehension movements.Journal of motor behavior16, 3 (1984), 235–254. doi:10.1080/00222895.1984.10735319
-
[23]
Juntao Jian, Xiuping Liu, Manyi Li, Ruizhen Hu, and Jian Liu. 2023. Affordpose: A large-scale dataset of hand-object interactions with affordance-driven hand pose. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14713–14724. doi:10.1109/iccv51070.2023.01352
-
[24]
Regis Kopper, Felipe Bacim, and Doug A Bowman. 2011. Rapid and accurate 3D selection by progressive refinement. In2011 IEEE symposium on 3D user interfaces (3DUI). IEEE, 67–74. doi:10.1109/3dui.2011.5759219
-
[25]
Byungjoo Lee. 2022. Cue integration in input performance.Bayesian methods for interaction and design(2022), 287–307. doi:10.1017/9781108874830.015
-
[26]
Byungjoo Lee, Sunjun Kim, Antti Oulasvirta, Jong-In Lee, and Eunji Park. 2018. Moving target selection: A cue integration model. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems. 1–12. doi:10.1145/3173574. 3173804
-
[27]
Sangyoon Lee, Jinseok Seo, Gerard Jounghyun Kim, and Chan-Mo Park. 2003. Evaluation of pointing techniques for ray casting selection in virtual environ- ments. InThird international conference on virtual reality and its application in industry, Vol. 4756. SPIE, 38–44. doi:10.1117/12.497665
-
[28]
Jiaman Li, Jiajun Wu, and C Karen Liu. 2023. Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG)42, 6 (2023), 1–11. doi:10. 1145/3618333
2023
-
[29]
Jiandong Liang and Mark Green. 1994. JDCAD: A highly interactive 3D modeling system.Computers & graphics18, 4 (1994), 499–506. doi:10.1016/0097-8493(94) 90062-0
-
[30]
Chiuhsiang Joe Lin, Benedikta Anna Haulian Siboro, and Wen-Ting Tsai. 2026. Interaction performance of mid-air touch with and without cursor in augmented reality environment.International Journal of Industrial Ergonomics112 (2026), 103894
2026
-
[31]
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Bo- qiang Liang, Zhoujie Fu, He Wang, and Li Yi. 2022. Hoi4d: A 4d egocen- tric dataset for category-level human-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21013–21022. doi:10.1109/cvpr52688.2022.02034
- [32]
-
[33]
Mathias N Lystbæk, Peter Rosenberg, Ken Pfeuffer, Jens Emil Grønbæk, and Hans Gellersen. 2022. Gaze-hand alignment: Combining eye gaze and mid-air pointing for interacting with menus in augmented reality.Proceedings of the ACM on Human-Computer Interaction6, ETRA (2022), 1–18. doi:10.1145/3530886
-
[34]
Frank J Massey Jr. 1951. The Kolmogorov-Smirnov test for goodness of fit.Journal of the American statistical Association46, 253 (1951), 68–78. doi:10.2307/2280095
-
[35]
Sven Mayer, Valentin Schwind, Robin Schweigert, and Niels Henze. 2018. The effect of offset correction and cursor on mid-air pointing in real and virtual environments. InProceedings of the 2018 CHI conference on human factors in computing systems. 1–13. doi:10.1145/3173574.3174227
-
[36]
Sven Mayer, Katrin Wolf, Stefan Schneegass, and Niels Henze. 2015. Modeling distant pointing for compensating systematic displacements. InProceedings of the 33rd annual ACM conference on human factors in computing systems. 4165–4168. doi:10.1145/2702123.2702332
-
[37]
Mark R Mine. 1995. Virtual environment interaction techniques.UNC Chapel Hill CS Dept(1995)
1995
-
[38]
Hee-Seung Moon, Yi-Chi Liao, Chenyu Li, Byungjoo Lee, and Antti Oulasvirta
-
[39]
Real-time 3d target inference via biomechanical simulation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–18. doi:10. 1145/3613904.3642131
-
[40]
Marco Moran-Ledesma, Oliver Schneider, and Mark Hancock. 2021. User-defined gestures with physical props in virtual reality.Proceedings of the ACM on Human- Computer Interaction5, ISS (2021), 1–23. doi:10.1145/3486954
-
[41]
Kai Nickel and Rainer Stiefelhagen. 2003. Pointing gesture recognition based on 3d-tracking of face, hands and head orientation. InProceedings of the 5th international conference on Multimodal interfaces. 140–146. doi:10.1145/958432. 958460
-
[42]
Stanley Osher, Ronald Fedkiw, and Krzysztof Piechor. 2004. Level set methods and dynamic implicit surfaces.Appl. Mech. Rev.57, 3 (2004), B15–B15. doi:10. 1115/1.1760520
2004
-
[43]
Brandon Paulson, Danielle Cummings, and Tracy Hammond. 2011. Object inter- action detection using hand posture cues in an office setting.International journal of human-computer studies69, 1-2 (2011), 19–29. doi:10.1016/j.ijhcs.2010.09.003
- [44]
-
[45]
Ilya A Petrov, Riccardo Marin, Julian Chibane, and Gerard Pons-Moll. 2023. Object pop-up: Can we infer 3d objects and their poses from human interactions alone?. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4726–4736. doi:10.1109/cvpr52729.2023.00458
-
[46]
Jeffrey S Pierce, Andrew S Forsberg, Matthew J Conway, Seung Hong, Robert C Zeleznik, and Mark R Mine. 1997. Image plane interaction techniques in 3D immersive environments. InProceedings of the 1997 symposium on Interactive 3D graphics. 39–44. doi:10.1145/253284.253303
-
[47]
Thammathip Piumsomboon, Adrian Clark, Mark Billinghurst, and Andy Cock- burn. 2013. User-defined gestures for augmented reality. InCHI’13 Extended Abstracts on Human Factors in Computing Systems. 955–960. doi:10.1145/2468356. 2468527
-
[48]
Ivan Poupyrev, Mark Billinghurst, Suzanne Weghorst, and Tadao Ichikawa. 1996. The go-go interaction technique: non-linear mapping for direct manipulation in VR. InProceedings of the 9th annual ACM symposium on User interface software and technology. 79–80. doi:10.1145/237091.237102
-
[49]
Sergey Prokudin, Christoph Lassner, and Javier Romero. 2019. Efficient learning on point clouds with basis point sets. InProceedings of the IEEE/CVF international conference on computer vision. 4332–4341. doi:10.1109/iccv.2019.00443
-
[50]
Tye Rattenbury and John Canny. 2007. CAAD: an automatic task support system. InProceedings of the SIGCHI conference on Human factors in computing systems. 687–696. doi:10.1145/1240624.1240731
-
[51]
Gang Ren and Eamonn O’Neill. 2013. 3D selection with freehand gesture.Com- puters & Graphics37, 3 (2013), 101–120. doi:10.1016/j.cag.2012.12.006
-
[52]
Valentin Schwind, Sven Mayer, Alexandre Comeau-Vermeersch, Robin Schweigert, and Niels Henze. 2018. Up to the finger tip: The effect of avatars Point & Grasp: Flexible Selection of Out-of-Reach Objects Through Probabilistic Cue Integration CHI ’26, April 13–17, 2026, Barcelona, Spain on mid-air pointing accuracy in virtual reality. InProceedings of the 20...
-
[53]
Rongkai Shi, Yushi Wei, Xueying Qin, Pan Hui, and Hai-Ning Liang. 2023. Ex- ploring gaze-assisted and hand-based region selection in augmented reality. Proceedings of the ACM on Human-Computer Interaction7, ETRA (2023), 1–19. doi:10.1145/3591129
-
[54]
Frank Steinicke, Timo Ropinski, and Klaus Hinrichs. 2006. Object selection in virtual environments using an improved virtual pointer metaphor. InCom- puter Vision and Graphics: International Conference, ICCVG 2004, Warsaw, Poland, September 2004, Proceedings. Springer, 320–326. doi:10.1007/1-4020-4179-9_46
-
[55]
Omid Taheri, Nima Ghorbani, Michael J Black, and Dimitrios Tzionas. 2020. GRAB: A dataset of whole-body human grasping of objects. InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceed- ings, Part IV 16. Springer, 581–600. doi:10.1007/978-3-030-58548-8_34
-
[56]
Vildan Tanriverdi and Robert JK Jacob. 2000. Interacting with eye movements in virtual environments. InProceedings of the SIGCHI conference on Human Factors in Computing Systems. 265–272. doi:10.1145/332040.332443
-
[57]
Juozas Vaicenavicius, David Widmann, Carl Andersson, Fredrik Lindsten, Jacob Roll, and Thomas Schön. 2019. Evaluating model calibration in classification. In The 22nd international conference on artificial intelligence and statistics. PMLR, 3459–3467. doi:10.48550/arXiv.1902.06977
- [58]
-
[59]
Radu-Daniel Vatavu and Ionuţ Alexandru Zaiţi. 2013. Automatic recognition of object size and shape via user-dependent measurements of the grasping hand. International Journal of Human-Computer Studies71, 5 (2013), 590–607. doi:10. 1016/j.ijhcs.2013.01.002
2013
-
[60]
Uta Wagner, Matthias Albrecht, Andreas Asferg Jacobsen, Haopeng Wang, Hans Gellersen, and Ken Pfeuffer. 2024. Gaze, wall, and racket: Combining gaze and hand-controlled plane for 3D selection in virtual reality.Proceedings of the ACM on Human-Computer Interaction8, ISS (2024), 189–213. doi:10.1145/3698134
-
[61]
Uta Wagner, Mathias N Lystbæk, Pavel Manakhov, Jens Emil Sloth Grønbæk, Ken Pfeuffer, and Hans Gellersen. 2023. A fitts’ law study of gaze-hand alignment for selection in 3d user interfaces. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–15. doi:10.1145/3544548.3581423
-
[62]
Ruicheng Wang, Jialiang Zhang, Jiayi Chen, Yinzhen Xu, Puhao Li, Tengyu Liu, and He Wang. 2023. Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation. In2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 11359–11366. doi:10.1109/icra48891.2023. 10160982
-
[63]
Yushi Wei, Rongkai Shi, Difeng Yu, Yihong Wang, Yue Li, Lingyun Yu, and Hai- Ning Liang. 2023. Predicting gaze-based target selection in augmented reality headsets based on eye and head endpoint distributions. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–14. doi:10.1145/3544548. 3581042
-
[64]
Jacob O Wobbrock, Meredith Ringel Morris, and Andrew D Wilson. 2009. User- defined gestures for surface computing. InProceedings of the SIGCHI conference on human factors in computing systems. 1083–1092. doi:10.1145/1518701.1518866
-
[65]
Jacob O Wobbrock, Kristen Shinohara, and Alex Jansen. 2011. The effects of task dimensionality, endpoint deviation, throughput calculation, and experiment design on pointing measures and models. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems. 1639–1648. doi:10.1145/1978942.1979181
-
[66]
Erik Wolf, Sara Klüber, Chris Zimmerer, Jean-Luc Lugrin, and Marc Erich Latoschik. 2019. ” Paint that object yellow”: Multimodal interaction to enhance creativity during design tasks in VR. In2019 International conference on multi- modal interaction. 195–204. doi:10.1145/3340555.3353724
-
[67]
Sirui Xu, Zhengyuan Li, Yu-Xiong Wang, and Liang-Yan Gui. 2023. Interdiff: Generating 3d human-object interactions with physics-informed diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14928– 14940. doi:10.1109/iccv51070.2023.01371
-
[68]
Yukang Yan, Chun Yu, Xiaojuan Ma, Xin Yi, Ke Sun, and Yuanchun Shi. 2018. Virtualgrasp: Leveraging experience of interacting with physical objects to facili- tate digital object retrieval. InProceedings of the 2018 Chi conference on human factors in computing systems. 1–13. doi:10.1145/3173574.3173652
- [69]
-
[70]
Difeng Yu, Xueshi Lu, Rongkai Shi, Hai-Ning Liang, Tilman Dingler, Eduardo Velloso, and Jorge Goncalves. 2021. Gaze-supported 3d object manipulation in virtual reality. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–13. doi:10.1145/3411764.3445343
-
[71]
Difeng Yu, Qiushi Zhou, Joshua Newn, Tilman Dingler, Eduardo Velloso, and Jorge Goncalves. 2020. Fully-occluded target selection in virtual reality.IEEE transactions on visualization and computer graphics26, 12 (2020), 3402–3413. doi:10.1109/tvcg.2020.3023606
-
[72]
Shumin Zhai, William Buxton, and Paul Milgram. 1994. The “Silk Cursor” investi- gating transparency for 3D target acquisition. InProceedings of the SIGCHI Confer- ence on Human Factors in Computing Systems. 459–464. doi:10.1145/191666.191822
-
[73]
Shumin Zhai, Jing Kong, and Xiangshi Ren. 2004. Speed–accuracy tradeoff in Fitts’ law tasks—on the equivalency of actual and nominal pointing precision. International journal of human-computer studies61, 6 (2004), 823–856. doi:10. 1016/j.ijhcs.2004.09.007
2004
-
[74]
Chenyang Zhang, Tiansu Chen, Eric Shaffer, and Elahe Soltanaghai. 2024. Focus- Flow: 3D gaze-depth interaction in virtual reality leveraging active visual depth manipulation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–18. doi:10.1145/3613904.3642589
-
[75]
Hui Zhang, Sammy Christen, Zicong Fan, Otmar Hilliges, and Jie Song. 2024. Graspxl: Generating grasping motions for diverse objects at scale. InEuropean Conference on Computer Vision. Springer, 386–403. doi:10.1007/978-3-031-73347- 5_22
-
[76]
Hui Zhang, Sammy Christen, Zicong Fan, Luocheng Zheng, Jemin Hwangbo, Jie Song, and Otmar Hilliges. 2024. Artigrasp: Physically plausible synthesis of bi-manual dexterous grasping and articulation. In2024 International Conference on 3D Vision (3DV). IEEE, 235–246. doi:10.1109/3dv62453.2024.00016
-
[77]
Yawen Zheng, Jin Huang, Hao Zhang, Yulong Bian, Juan Liu, Chenglei Yang, Feng Tian, and Xiangxu Meng. 2025. 3D Ternary-Gaussian model: Modeling pointing uncertainty of 3D moving target selection in virtual reality.International Journal of Human-Computer Studies198 (2025), 103454. doi:10.1016/j.ijhcs.2025.103454
-
[78]
Qian Zhou, George Fitzmaurice, and Fraser Anderson. 2022. In-depth mouse: Integrating desktop mouse into virtual reality. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–17. doi:10.1145/3491102. 3501884
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.