Recognition: unknown
Are Natural-Domain Foundation Models Effective for Accelerated Cardiac MRI Reconstruction?
Pith reviewed 2026-05-08 09:02 UTC · model grok-4.3
The pith
Natural-domain foundation models like CLIP inserted as frozen priors into unrolled networks match specialized models on cardiac MRI and outperform them on cross-domain knee and brain scans at high acceleration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Inserting pretrained frozen visual encoders from CLIP, DINOv2 or BiomedCLIP into each cascade of an unrolled reconstruction framework produces competitive reconstruction quality on in-distribution cardiac MRI while delivering measurably higher robustness than purely task-specific networks when the same models are evaluated on anatomically distinct knee and brain datasets, particularly under high acceleration factors and limited low-frequency sampling.
What carries the argument
An unrolled reconstruction framework that incorporates pretrained, frozen visual encoders such as CLIP, DINOv2, and BiomedCLIP within each cascade to guide the reconstruction process.
If this is right
- Task-specific networks such as E2E-VarNet remain strongest when training and test data come from the same cardiac distribution.
- Foundation-model versions close the performance gap on matched data and exceed it once the test anatomy changes to knee or brain.
- Natural-image pretraining alone supplies structural representations that transfer effectively; domain-specific pretraining yields only modest extra benefit in the most ill-posed regimes.
- Robustness gains appear most clearly at the highest acceleration rates and when low-frequency sampling is severely restricted.
- Pretrained foundation models therefore constitute a reusable source of priors that can reduce reliance on large amounts of target-domain MRI data.
Where Pith is reading between the lines
- The same frozen-encoder insertion pattern could be tested on other linear inverse problems such as accelerated CT or photoacoustic tomography.
- If the structural features learned from natural images remain effective after further scaling of pretraining diversity, data requirements for new medical-reconstruction tasks may drop substantially.
- Clinical deployment would still require verification on real scanner variability and patient motion patterns not captured in the current cross-domain splits.
- The approach opens a route to parameter-efficient adaptation: only the data-consistency layers need task-specific training while the visual prior stays frozen.
Load-bearing premise
Frozen natural-domain visual encoders can be directly inserted into each cascade of an unrolled reconstruction framework and will provide effective guidance for the physics-based inverse problem of accelerated cardiac MRI without any domain adaptation or fine-tuning.
What would settle it
A side-by-side test on knee and brain MRI at acceleration factor 8 using only the central four k-space lines, checking whether the foundation-model cascades produce higher or lower normalized root-mean-square error than E2E-VarNet.
Figures

read the original abstract
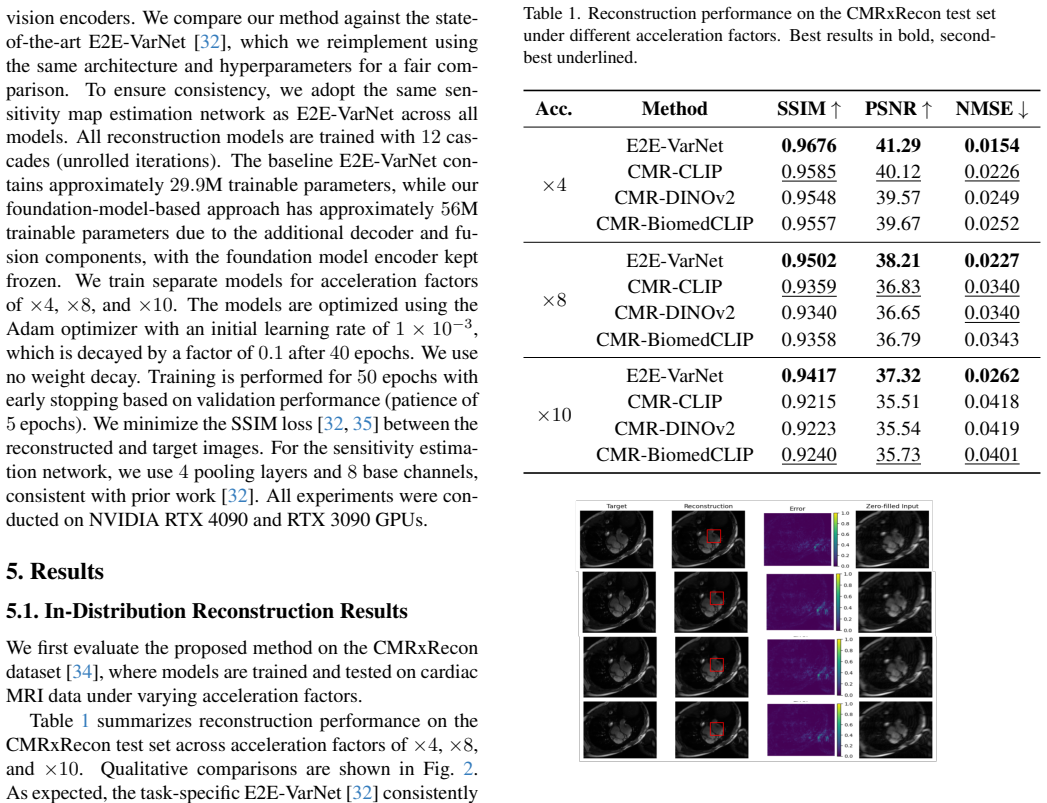
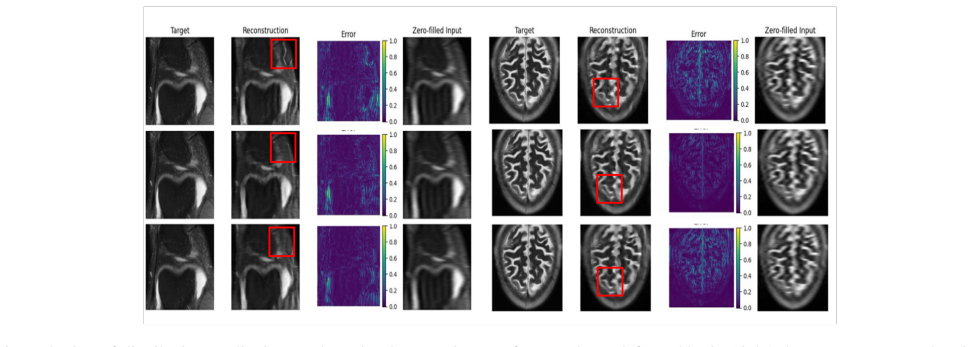
The emergence of large-scale pretrained foundation models has transformed computer vision, enabling strong performance across diverse downstream tasks. However, their potential for physics-based inverse problems, such as accelerated cardiac MRI reconstruction, remains largely underexplored. In this work, we investigate whether natural-domain foundation models can serve as effective image priors for accelerated cardiac MRI reconstruction, and compare the performance obtained against domain-specific counterparts such as BiomedCLIP. We propose an unrolled reconstruction framework that incorporates pretrained, frozen visual encoders, such as CLIP, DINOv2, and BiomedCLIP, within each cascade to guide the reconstruction process. Through extensive experiments, we show that while task-specific state-of-the-art reconstruction models such as E2E-VarNet achieve superior performance in standard in-distribution settings, foundation-model-based approaches remain competitive. More importantly, in challenging cross-domain scenarios, where models are trained on cardiac MRI and evaluated on anatomically distinct knee and brain datasets--foundation models exhibit improved robustness, particularly under high acceleration factors and limited low-frequency sampling. We further observe that natural-image-pretrained models, such as CLIP, learn highly transferable structural representations, while domain-specific pretraining (BiomedCLIP) provides modest additional gains in more ill-posed regimes. Overall, our results suggest that pretrained foundation models offer a promising source of transferable priors, enabling improved robustness and generalization in accelerated MRI reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an unrolled reconstruction framework that inserts frozen pretrained visual encoders (CLIP, DINOv2, BiomedCLIP) into each cascade to act as image-domain priors for accelerated cardiac MRI reconstruction. It claims that while task-specific models such as E2E-VarNet outperform on in-distribution cardiac data, the foundation-model variants remain competitive and exhibit superior robustness when trained on cardiac MRI and evaluated on anatomically distinct knee and brain datasets, particularly at high acceleration factors and with limited low-frequency sampling. Natural-image-pretrained encoders are reported to learn transferable structural representations, with domain-specific pretraining (BiomedCLIP) yielding only modest additional gains in ill-posed regimes.
Significance. If the reported cross-domain robustness gains hold under rigorous controls, the work would demonstrate that large-scale natural-image pretraining can supply useful structural priors for physics-constrained MRI inverse problems without domain adaptation. This would reduce reliance on task-specific training data and support more generalizable reconstruction pipelines across anatomies and acquisition protocols.
major comments (1)
- [Methods and Experiments (unrolled cascade integration)] The central attribution of improved cross-domain robustness to the foundation-model priors (abstract and §4) is load-bearing but not isolated: the unrolled network already contains explicit data-consistency blocks, and the manuscript does not report an ablation that replaces the frozen encoder with a randomly initialized or non-pretrained CNN of comparable capacity while keeping the rest of the cascade identical. Without this control, the observed gains on knee/brain test sets could arise from the shared unrolled skeleton or training protocol rather than the transferred features.
minor comments (2)
- [Abstract] The abstract states that 'extensive experiments' support the claims but contains no numerical metrics, error bars, or statistical tests; adding representative PSNR/SSIM values and p-values for the key in-distribution and cross-domain comparisons would make the summary self-contained.
- [Experimental setup] Clarify the precise coil-sensitivity estimation method and the k-space sampling masks (e.g., variable-density Cartesian or radial) used for the high-acceleration cross-domain tests; this detail is needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The major comment raises a valid point about isolating the contribution of the pretrained priors, which we address below by committing to a targeted revision. We believe this will strengthen the manuscript's claims regarding cross-domain robustness.
read point-by-point responses
-
Referee: The central attribution of improved cross-domain robustness to the foundation-model priors (abstract and §4) is load-bearing but not isolated: the unrolled network already contains explicit data-consistency blocks, and the manuscript does not report an ablation that replaces the frozen encoder with a randomly initialized or non-pretrained CNN of comparable capacity while keeping the rest of the cascade identical. Without this control, the observed gains on knee/brain test sets could arise from the shared unrolled skeleton or training protocol rather than the transferred features.
Authors: We agree that the current set of experiments does not fully isolate the effect of pretraining from the unrolled cascade architecture and training protocol. In the revised manuscript, we will add the requested ablation: a variant in which the frozen pretrained encoders (CLIP, DINOv2, BiomedCLIP) are replaced by randomly initialized CNNs of comparable capacity and depth, while keeping the data-consistency blocks, cascade structure, and all training details identical. Results from this control will be reported alongside the existing comparisons to E2E-VarNet and the foundation-model variants, allowing readers to assess whether the observed robustness on knee and brain data stems from the transferred features. We view this addition as a necessary clarification that directly strengthens the central attribution in the abstract and §4. revision: yes
Circularity Check
Empirical comparison with no derivation chain
full rationale
The paper proposes an unrolled reconstruction network that inserts frozen natural-domain encoders (CLIP, DINOv2, BiomedCLIP) into each cascade and reports performance via standard training and cross-domain testing on cardiac, knee, and brain MRI. No equations, first-principles derivations, or predictions are presented that reduce to fitted parameters, self-definitions, or self-citations by construction. All claims rest on direct empirical metrics (PSNR, SSIM, etc.) obtained from the described architecture and datasets, which are externally falsifiable and independent of any internal tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deepa Anand, Vanika Singhal, Dattesh D Shanbhag, Shri- ram KS, Uday Patil, Chitresh Bhushan, Kavitha Manickam, Dawei Gui, Rakesh Mullick, Avinash Gopal, et al. One-shot localization and segmentation of medical images with foun- dation models.arXiv preprint arXiv:2310.18642, 2023. 3
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hin- ton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review arXiv
-
[3]
Mohammed Baharoon, Waseem Qureshi, Jiahong Ouyang, Yanwu Xu, Abdulrhman Aljouie, and Wei Peng. Evaluating general purpose vision foundation models for medical im- age analysis: An experimental study of dinov2 on radiology benchmarks.arXiv preprint arXiv:2312.02366, 2023. 1, 3
-
[4]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Alt- man, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021. 1
work page internal anchor Pith review arXiv 2021
-
[5]
Uni- verseg: Universal medical image segmentation
Victor Ion Butoi, Jose Javier Gonzalez Ortiz, Tianyu Ma, Mert R Sabuncu, John Guttag, and Adrian V Dalca. Uni- verseg: Universal medical image segmentation. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 21438–21451, 2023. 1
2023
-
[6]
Emmanuel J Candes, Justin K Romberg, and Terence Tao. Stable signal recovery from incomplete and inaccurate mea- surements.Communications on Pure and Applied Mathe- matics: A Journal Issued by the Courant Institute of Mathe- matical Sciences, 59(8):1207–1223, 2006. 2
2006
-
[7]
Do vi- sion foundation models enhance domain generalization in medical image segmentation? InEuropean Conference on Computer Vision, pages 185–200
Kerem Cekmeceli, Meva Himmetoglu, Guney I Tombak, Anna Susmelj, Ertunc Erdil, and Ender Konukoglu. Do vi- sion foundation models enhance domain generalization in medical image segmentation? InEuropean Conference on Computer Vision, pages 185–200. Springer, 2024. 4
2024
-
[8]
Soumitri Chattopadhyay, Basar Demir, and Marc Nietham- mer. Zero-shot domain generalization of foundational mod- els for 3d medical image segmentation: an experimental study.arXiv preprint arXiv:2503.22862, 2025. 1
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 4
2009
-
[10]
Compressed sensing.IEEE Transactions on information theory, 52(4):1289–1306, 2006
David L Donoho. Compressed sensing.IEEE Transactions on information theory, 52(4):1289–1306, 2006. 2
2006
-
[11]
Katerina Eyre, Katherine Lindsay, Saad Razzaq, Michael Chetrit, and Matthias Friedrich. Simultaneous multi- parametric acquisition and reconstruction techniques in car- diac magnetic resonance imaging: basic concepts and sta- tus of clinical development.Frontiers in cardiovascular medicine, 9:953823, 2022. 1
2022
-
[12]
Humus-net: Hybrid unrolled multi-scale network architec- ture for accelerated mri reconstruction.Advances in Neural Information Processing Systems, 35:25306–25319, 2022
Zalan Fabian, Berk Tinaz, and Mahdi Soltanolkotabi. Humus-net: Hybrid unrolled multi-scale network architec- ture for accelerated mri reconstruction.Advances in Neural Information Processing Systems, 35:25306–25319, 2022. 1, 2, 3, 4, 5
2022
-
[13]
Depthwise convolution is all you need for learning multiple visual domains
Yunhui Guo, Yandong Li, Liqiang Wang, and Tajana Rosing. Depthwise convolution is all you need for learning multiple visual domains. InProceedings of the AAAI conference on artificial intelligence, pages 8368–8375, 2019. 4
2019
-
[14]
Unetr: Transformers for 3d med- ical image segmentation
Ali Hatamizadeh, Yucheng Tang, Vishwesh Nath, Dong Yang, Andriy Myronenko, Bennett Landman, Holger R Roth, and Daguang Xu. Unetr: Transformers for 3d med- ical image segmentation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 574–584, 2022. 4, 5
2022
-
[15]
Are natural domain foundation models useful for medical image classification? in 2024 ieee/cvf winter conference on applications of computer vi- sion (wacv)
JP Huix, AR Ganeshan, JF Haslum, M S ¨oderberg, C Mat- soukas, and K Smith. Are natural domain foundation models useful for medical image classification? in 2024 ieee/cvf winter conference on applications of computer vi- sion (wacv). waikoloa, hi, usa: Ieee;[cited 2024 aug 27]. 7619–7628, 2024. 1, 2, 3, 4
2024
-
[16]
Dongsheng Jiang, Yuchen Liu, Songlin Liu, Jin’e Zhao, Hao Zhang, Zhen Gao, Xiaopeng Zhang, Jin Li, and Hongkai Xiong. From clip to dino: Visual encoders shout in multi-modal large language models.arXiv preprint arXiv:2310.08825, 2023. 4
-
[17]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 1
2023
-
[18]
Bart: Denoising sequence-to- sequence pre-training for natural language generation, trans- lation, and comprehension
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvinine- jad, Abdelrahman Mohamed, Omer Levy, Veselin Stoy- anov, and Luke Zettlemoyer. Bart: Denoising sequence-to- sequence pre-training for natural language generation, trans- lation, and comprehension. InProceedings of the 58th an- nual meeting of the association for computational linguis- tics, pages 787...
2020
-
[19]
Data or language supervision: What makes clip better than dino?arXiv preprint arXiv:2510.11835, 2025
Yiming Liu, Yuhui Zhang, Dhruba Ghosh, Ludwig Schmidt, and Serena Yeung-Levy. Data or language supervision: What makes clip better than dino?arXiv preprint arXiv:2510.11835, 2025. 7
-
[20]
Compressed sensing mri.IEEE signal pro- cessing magazine, 25(2):72–82, 2008
Michael Lustig, David L Donoho, Juan M Santos, and John M Pauly. Compressed sensing mri.IEEE signal pro- cessing magazine, 25(2):72–82, 2008. 2
2008
-
[21]
The state-of-the-art in cardiac mri re- construction: Results of the cmrxrecon challenge in miccai 2023.Medical Image Analysis, 101:103485, 2025
Jun Lyu, Chen Qin, Shuo Wang, Fanwen Wang, Yan Li, Zi Wang, Kunyuan Guo, Cheng Ouyang, Michael T ¨anzer, Meng Liu, et al. The state-of-the-art in cardiac mri re- construction: Results of the cmrxrecon challenge in miccai 2023.Medical Image Analysis, 101:103485, 2025. 1
2023
-
[22]
Segment anything in medical images.Nature communications, 15(1):654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature communications, 15(1):654, 2024. 1
2024
-
[23]
What makes trans- fer learning work for medical images: Feature reuse & other factors
Christos Matsoukas, Johan Fredin Haslum, Moein Sorkhei, Magnus S ¨oderberg, and Kevin Smith. What makes trans- fer learning work for medical images: Feature reuse & other factors. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9225–9234,
-
[24]
Christos Matsoukas, Johan Fredin Haslum, Moein Sorkhei, Magnus S ¨oderberg, and Kevin Smith. Pretrained vits yield versatile representations for medical images.arXiv preprint arXiv:2303.07034, 2023. 2
-
[25]
Radiological reports improve pre-training for lo- calized imaging tasks on chest x-rays
Philip M ¨uller, Georgios Kaissis, Congyu Zou, and Daniel Rueckert. Radiological reports improve pre-training for lo- calized imaging tasks on chest x-rays. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 647–657. Springer, 2022. 3
2022
-
[26]
Deep learning techniques for inverse problems in imaging
Gregory Ongie, Ajil Jalal, Christopher A Metzler, Richard G Baraniuk, Alexandros G Dimakis, and Rebecca Willett. Deep learning techniques for inverse problems in imaging. IEEE Journal on Selected Areas in Information Theory, 1 (1):39–56, 2020. 1
2020
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 1, 2, 3
work page internal anchor Pith review arXiv 2023
-
[28]
Improving language understanding by gen- erative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by gen- erative pre-training. 2018. 1
2018
-
[29]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 2, 3
2021
-
[30]
Praveenbalaji Rajendran, Mojtaba Safari, Wenfeng He, Mingzhe Hu, Shansong Wang, Jun Zhou, and Xiaofeng Yang. Foundation models in medical image analysis: A systematic review and meta-analysis.arXiv preprint arXiv:2510.16973, 2025. 1
-
[31]
General pur- pose image encoder dinov2 for medical image registration
Xinrui Song, Xuanang Xu, and Pingkun Yan. General pur- pose image encoder dinov2 for medical image registration. arXiv preprint arXiv:2402.15687, 2024. 3
-
[32]
End-to-end variational networks for accelerated mri reconstruction
Anuroop Sriram, Jure Zbontar, Tullie Murrell, Aaron De- fazio, C Lawrence Zitnick, Nafissa Yakubova, Florian Knoll, and Patricia Johnson. End-to-end variational networks for accelerated mri reconstruction. InInternational conference on medical image computing and computer-assisted inter- vention, pages 64–73. Springer, 2020. 2, 3, 4, 5, 6, 7
2020
-
[33]
Instance Normalization: The Missing Ingredient for Fast Stylization
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. In- stance normalization: The missing ingredient for fast styliza- tion.arXiv preprint arXiv:1607.08022, 2016. 4
work page Pith review arXiv 2016
-
[34]
Chengyan Wang, Jun Lyu, Shuo Wang, Chen Qin, Kunyuan Guo, Xinyu Zhang, Xiaotong Yu, Yan Li, Fanwen Wang, Jianhua Jin, et al. Cmrxrecon: an open cardiac mri dataset for the competition of accelerated image reconstruction.arXiv preprint arXiv:2309.10836, 2023. 2, 5, 6
-
[35]
Multi- scale structural similarity for image quality assessment
Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multi- scale structural similarity for image quality assessment. In The thrity-seventh asilomar conference on signals, systems & computers, 2003, pages 1398–1402. Ieee, 2003. 5, 6
2003
-
[36]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3876–3887, 2022. 1, 3
2022
-
[37]
Navigating data scarcity using foundation models: A benchmark of few- shot and zero-shot learning approaches in medical imaging
Stefano Woerner and Christian F Baumgartner. Navigating data scarcity using foundation models: A benchmark of few- shot and zero-shot learning approaches in medical imaging. InInternational Workshop on Foundation Models for Gen- eral Medical AI, pages 30–39. Springer, 2024. 3
2024
-
[38]
Fill the k-space and refine the image: Prompting for dynamic and multi-contrast mri reconstruction
Bingyu Xin, Meng Ye, Leon Axel, and Dimitris N Metaxas. Fill the k-space and refine the image: Prompting for dynamic and multi-contrast mri reconstruction. InInternational Work- shop on Statistical Atlases and Computational Models of the Heart, pages 261–273. Springer, 2023. 1, 3
2023
-
[39]
Recurrent variational network: a deep learn- ing inverse problem solver applied to the task of accelerated mri reconstruction
George Yiasemis, Jan-Jakob Sonke, Clarisa S ´anchez, and Jonas Teuwen. Recurrent variational network: a deep learn- ing inverse problem solver applied to the task of accelerated mri reconstruction. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 732–741, 2022. 1
2022
-
[40]
Jure Zbontar, Florian Knoll, Anuroop Sriram, Tullie Mur- rell, Zhengnan Huang, Matthew J Muckley, Aaron Defazio, Ruben Stern, Patricia Johnson, Mary Bruno, et al. fastmri: An open dataset and benchmarks for accelerated mri.arXiv preprint arXiv:1811.08839, 2018. 3, 5, 6
-
[41]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915,
work page internal anchor Pith review arXiv
-
[42]
Clip in medical imaging: A survey.Medical Image Analysis, 102:103551, 2025
Zihao Zhao, Yuxiao Liu, Han Wu, Mei Wang, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, et al. Clip in medical imaging: A survey.Medical Image Analysis, 102:103551, 2025. 3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.