Recognition: unknown
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Pith reviewed 2026-05-08 11:57 UTC · model grok-4.3
The pith
A levels x laws taxonomy classifies world models for agents into three capability stages and four domain law regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
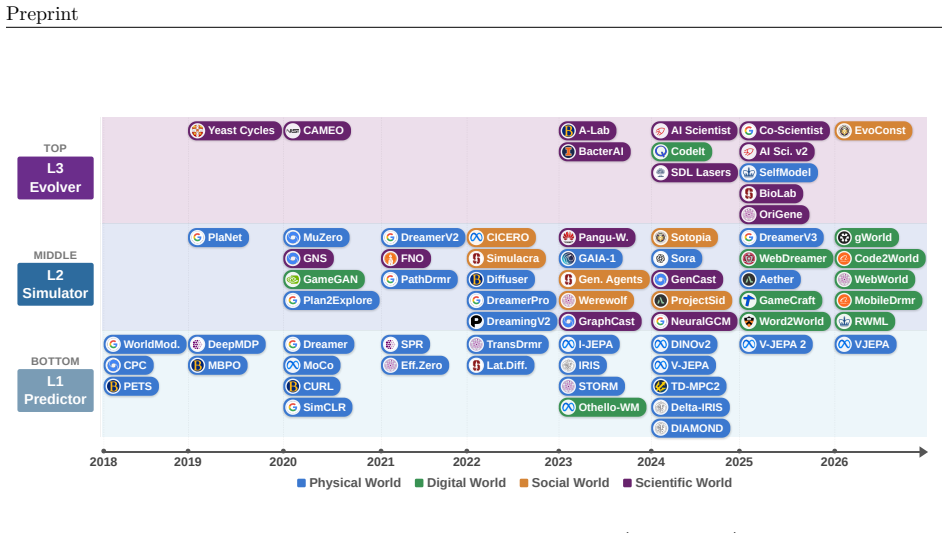
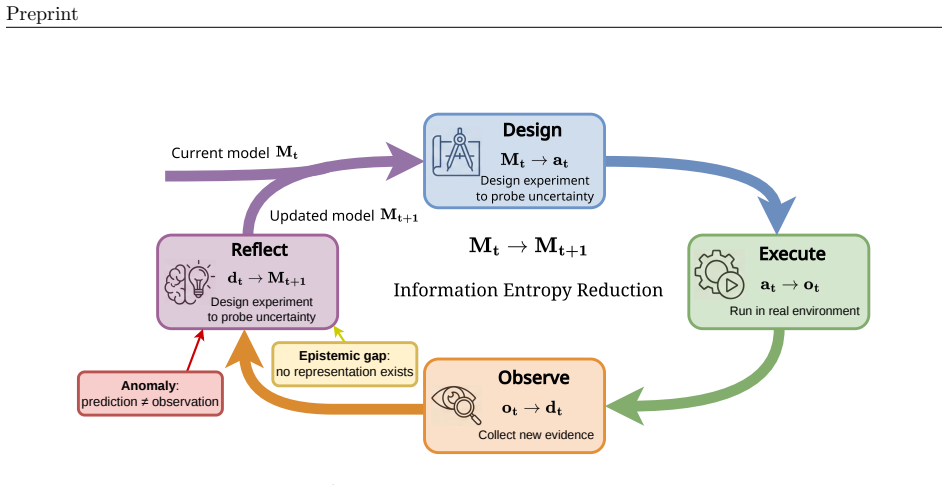
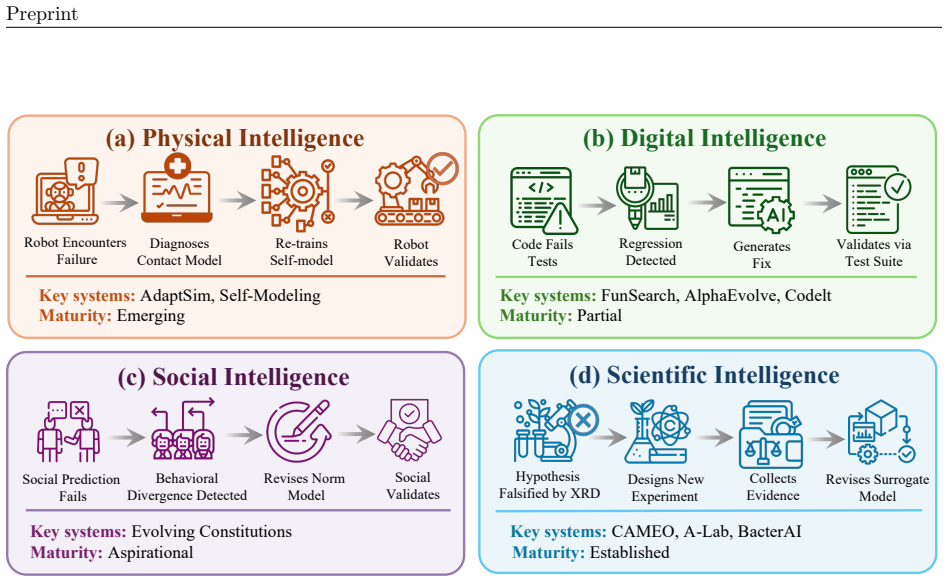
We introduce a levels x laws taxonomy with three capability levels—L1 Predictor for one-step local transitions, L2 Simulator for action-conditioned multi-step rollouts that obey domain laws, and L3 Evolver for autonomous model revision on prediction failures—and four governing-law regimes—physical, digital, social, and scientific—to organize research, expose failure modes, and outline paths from passive prediction toward models agents can use to simulate and reshape their surroundings.
What carries the argument
The levels x laws taxonomy, a two-axis grid that places any world model at the intersection of its capability stage and the type of law it must satisfy.
If this is right
- Model-based reinforcement learning methods supply the transition operators needed for L2 simulators in physical regimes.
- Video-generation pipelines can serve as L1 predictors but must gain explicit action conditioning to reach L2.
- Multi-agent social simulations expose distinct failure modes at the L3 boundary where models must revise themselves.
- Decision-centric evaluation protocols can replace task-specific benchmarks across all level-regime pairs.
- Modular architectures that separate transition learning from law enforcement become a practical route to L3 systems.
Where Pith is reading between the lines
- The grid suggests experiments that deliberately feed contradictory evidence to an L2 model and measure whether revision occurs without external retraining.
- Architectures developed for one regime could be stress-tested by transferring them to another to quantify how law type affects required capacity.
- Self-revision at L3 raises the practical question of how to certify that an evolving model remains aligned with human goals over time.
- The taxonomy could be extended with a fifth regime for hybrid human-AI environments once enough systems occupy that space.
Load-bearing premise
Research on world models can be partitioned into these three levels and four regimes without large overlaps or missing categories that would make the grid useless for guiding design choices.
What would settle it
A complete classification of the surveyed papers and systems reveals many that resist assignment to any single level-regime cell without stretching the definitions or adding new cells.
Figures






read the original abstract
As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a 'levels x laws' taxonomy for world models in agentic AI systems. It defines three capability levels—L1 Predictor (one-step local transition operators), L2 Simulator (composing operators into multi-step action-conditioned rollouts respecting domain laws), and L3 Evolver (autonomous model revision on prediction failures)—crossed with four governing-law regimes (physical, digital, social, scientific). Using this framework, the authors synthesize over 400 works, summarize more than 100 representative systems across model-based RL, video generation, web/GUI agents, multi-agent simulation, and AI-driven discovery, analyze methods/failure modes/evaluations, propose decision-centric evaluation principles with a minimal reproducible package, and outline architectural guidance and open problems.
Significance. If the taxonomy holds as a useful organizing lens, the work could connect previously siloed communities and provide a roadmap from passive prediction toward models that simulate and reshape environments. The large-scale synthesis of 400+ works, the explicit proposal of decision-centric evaluation principles, and the identification of cross-regime failure modes represent concrete strengths that could inform architectural choices and evaluation practices if the categories prove sharp and non-overlapping in practice.
major comments (2)
- [Abstract (taxonomy definition) and synthesis of representative systems] The central claim that the levels x laws framework forms a useful partition for synthesizing literature and guiding architecture/evaluation rests on the assumption that the L1/L2/L3 levels and four regimes are sufficiently disjoint. However, the definitions allow substantial overlap: L2 is explicitly described as composing L1 operators, and systems in model-based RL and video generation routinely perform both one-step prediction and multi-step rollouts. The synthesis of 100+ representative systems does not appear to include a quantitative breakdown of clean vs. multi-label assignments or forced categorizations, which is load-bearing for the claim that the taxonomy enables sharp failure-mode analysis.
- [Synthesis across level-regime pairs and failure-mode analysis] The paper claims the regimes determine 'what constraints a world model must satisfy and where it is most likely to fail,' yet social simulation papers frequently embed physical or digital constraints. Without explicit discussion of how multi-regime systems are handled in the analysis of methods and failure modes, the framework risks becoming loose labeling rather than a decision-centric tool.
minor comments (2)
- [Abstract and introduction] The abstract and introduction use 'over 400 works' and 'more than 100 representative systems' without a clear appendix or table listing the exact selection criteria or full bibliography mapping, which would aid reproducibility of the synthesis.
- [Taxonomy introduction] Notation for the levels (L1, L2, L3) and regimes is introduced clearly but could benefit from a single summary table early in the manuscript to facilitate cross-referencing in later sections on evaluation and open problems.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, offering clarifications on the taxonomy's design and committing to revisions that enhance transparency without altering the core claims.
read point-by-point responses
-
Referee: [Abstract (taxonomy definition) and synthesis of representative systems] The central claim that the levels x laws framework forms a useful partition for synthesizing literature and guiding architecture/evaluation rests on the assumption that the L1/L2/L3 levels and four regimes are sufficiently disjoint. However, the definitions allow substantial overlap: L2 is explicitly described as composing L1 operators, and systems in model-based RL and video generation routinely perform both one-step prediction and multi-step rollouts. The synthesis of 100+ representative systems does not appear to include a quantitative breakdown of clean vs. multi-label assignments or forced categorizations, which is load-bearing for the claim that the taxonomy enables sharp failure-mode analysis.
Authors: We appreciate the referee's point on potential overlaps. The levels are defined as progressive capability stages rather than mutually exclusive implementations: L1 centers on learning local one-step operators, L2 on their composition into law-respecting multi-step rollouts, and L3 on autonomous model revision. Systems are classified by the highest level for which they provide clear evidence, even if lower-level components are present. While the manuscript does not currently include a quantitative breakdown of assignments, we will add a supplementary table in the revision that lists the 100+ representative systems with their primary level-regime classification, notes on any hybrid aspects, and justification for each assignment. This addition will make the failure-mode analysis more rigorous and demonstrate the taxonomy's partitioning utility. revision: yes
-
Referee: [Synthesis across level-regime pairs and failure-mode analysis] The paper claims the regimes determine 'what constraints a world model must satisfy and where it is most likely to fail,' yet social simulation papers frequently embed physical or digital constraints. Without explicit discussion of how multi-regime systems are handled in the analysis of methods and failure modes, the framework risks becoming loose labeling rather than a decision-centric tool.
Authors: We agree that hybrid systems are common, with social simulations often incorporating physical or digital constraints. The framework classifies each system according to its dominant regime—the one that primarily dictates the key constraints and associated failure modes analyzed in the synthesis. To strengthen this, we will insert a new subsection on cross-regime systems in the revised manuscript. This subsection will explicitly discuss handling of multi-regime cases, provide concrete examples from the reviewed literature, and explain how intersecting constraints are accounted for in the method and failure-mode analysis. These changes will clarify the framework's application as a decision-centric lens while preserving its utility for identifying primary risks. revision: yes
Circularity Check
No circularity: taxonomy is an explicit proposal synthesizing external literature
full rationale
The paper defines its L1/L2/L3 levels and physical/digital/social/scientific regimes as a new organizing framework, then applies it to categorize >400 external works. No equations, fitted parameters, or predictions are present; the taxonomy is not derived from prior results but proposed outright. No self-citation chains or self-definitional reductions appear in the load-bearing claims. The central contribution is the synthesis and roadmap itself, which remains independent of the framework's internal definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ability to model environment dynamics is a central bottleneck for agents that accomplish goals through sustained interaction.
invented entities (4)
-
L1 Predictor
no independent evidence
-
L2 Simulator
no independent evidence
-
L3 Evolver
no independent evidence
-
Four governing-law regimes (physical, digital, social, scientific)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Graph World Models: Concepts, Taxonomy, and Future Directions
The paper unifies emerging graph-based world models under a new paradigm and proposes a taxonomy organized by spatial, physical, and logical relational inductive biases.
Reference graph
Works this paper leans on
-
[1]
Abramson, J
J. Abramson, J. Adler, J. Dunger, R. Evans, T. Green, A. Pritzel, O. Ronneberger, L. Willmore, A. J. Ballard, J. Bambrick, S. W. Bodenstein, D. A. Evans, C.-C. Hung, M. O'Neill, D. Reiman, K. Tunyasuvunakool, Z. Wu, A. Z emguly \. t \. e , E. Arvaniti, C. Beattie, O. Bertolli, A. Bridgland, A. Cherepanov, M. Congreve, A. I. Cowen-Rivers, A. Cowie, M. Figu...
2024
-
[2]
Cosmos World Foundation Model Platform for Physical AI
N. Agarwal, A. Ali, M. Bala, Y. Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y. Chen, Y. Cui, Y. Ding, D. Dworakowski, J. Fan, M. Fenzi, F. Ferroni, S. Fidler, D. Fox, S. Ge, Y. Ge, J. Gu, S. Gururani, E. He, J. Huang, J. Huffman, P. Jannaty, J. Jin, S. W. Kim, G. Klár, G. Lam, S. Lan, L. Leal-Taixe, A. Li, Z. Li, C.-H. Lin, T.-Y. Lin, H. Ling, M.-Y. Liu,...
work page internal anchor Pith review arXiv 2025
-
[3]
Agarwal, M
R. Agarwal, M. Schwarzer, P. S. Castro, A. C. Courville, and M. G. Bellemare. Deep reinforcement learning at the edge of the statistical precipice. In Advances in Neural Information Processing Systems, volume 34, 2021
2021
-
[4]
Agrawal, A
P. Agrawal, A. V. Nair, P. Abbeel, J. Malik, and S. Levine. Learning to poke by poking: Experiential learning of intuitive physics. In Advances in Neural Information Processing Systems, volume 29, pages 5092--5100, 2016
2016
- [5]
-
[6]
Alonso, A
E. Alonso, A. Jelley, V. Micheli, A. Kanervisto, A. Storkey, T. Pearce, and F. Fleuret. Diffusion for world modeling: Visual details matter in atari. Advances in Neural Information Processing Systems, 37: 0 58757--58791, 2024
2024
-
[7]
Andrychowicz, M
M. Andrychowicz, M. Denil, S. Gomez, M. W. Hoffman, D. Pfau, T. Schaul, B. Shillingford, and N. de Freitas. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems, volume 29, pages 3988--3996, 2016
2016
-
[8]
Angermueller, D
C. Angermueller, D. Belanger, A. Gane, Z. Mariet, D. Dohan, K. Murphy, L. Colwell, and D. Sculley. Population-based black-box optimization for biological sequence design. In International Conference on Machine Learning, pages 324--334. PMLR, 2020
2020
-
[9]
Effective context engineering for AI agents
Anthropic . Effective context engineering for AI agents. Anthropic Engineering Blog, 2025. URL https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
2025
-
[10]
L. P. Argyle, E. C. Busby, N. Fulda, J. R. Gubler, C. Rytting, and D. Wingate. Out of one, many: Using language models to simulate human samples. Political Analysis, 31 0 (3): 0 337--351, 2023
2023
-
[11]
V. Arunkumar, G. R. Gangadharan, and R. Buyya. Agentic artificial intelligence ( AI ): Architectures, taxonomies, and evaluation of large language model agents. arXiv preprint arXiv:2601.12560, 2026
-
[12]
A. F. Ashery, L. M. Aiello, and A. Baronchelli. Emergent social conventions and collective bias in LLM populations. Science Advances, 11, 2025
2025
-
[13]
Ashkboos, A
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, P. Cameron, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman. QuaRot : Outlier-free 4-bit inference in rotated LLMs . In Advances in Neural Information Processing Systems, volume 37, pages 100213--100240, 2024
2024
-
[14]
Assran, Q
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y. LeCun, and N. Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619--15629, 2023
2023
-
[15]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, Mojtaba, Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. R. Hogan, D. Dugas, P. Bojanowski, V. Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y. Li, X. Ma, S. Chandar, F. Meier, Y. LeCun, M. Rabbat, and N. Ballas. V-JEPA 2 : Self-supervi...
work page internal anchor Pith review arXiv 2025
-
[16]
Babaeizadeh, C
M. Babaeizadeh, C. Finn, D. Erhan, R. H. Campbell, and S. Levine. Stochastic variational video prediction. In International Conference on Learning Representations, 2018
2018
-
[17]
M. Baek, F. DiMaio, I. Anishchenko, J. Dauparas, S. Ovchinnikov, G. R. Lee, J. Wang, Q. Cong, L. N. Kinch, R. D. Schaeffer, C. Mill \'a n, H. Park, C. Adams, C. R. Glassman, A. DeGiovanni, J. H. Pereira, A. V. Rodrigues, A. A. van Dijk, A. C. Ebrecht, D. J. Opperman, T. Sagmeister, C. Buhlheller, T. Pavkov-Keller, M. K. Rathinaswamy, U. Dalwadi, C. K. Yip...
2021
-
[18]
A. P. Baker, M. J. Brookes, I. A. Rezek, S. M. Smith, T. Behrens, P. J. Probert Smith, and M. Woolrich. Fast transient networks in spontaneous human brain activity. eLife, 3: 0 e01867, 2014
2014
-
[19]
Baker, I
B. Baker, I. Akkaya, P. Zhokhov, J. Huizinga, J. Tang, A. Ecoffet, B. Houghton, R. Sampedro, and J. Clune. Video P re T raining ( VPT ): Learning to act by watching unlabeled online videos. In Advances in Neural Information Processing Systems, volume 35, pages 24639--24654, 2022
2022
-
[20]
Baker, R
C. Baker, R. Saxe, and J. Tenenbaum. Bayesian theory of mind: Modeling joint belief-desire attribution. In Annual Meeting of the Cognitive Science Society, volume 33, 2011
2011
-
[21]
Bakhtin, N
A. Bakhtin, N. Brown, E. Dinan, G. Farina, C. Flaherty, D. Fried, A. Goff, J. Gray, H. Hu, A. P. Jacob, M. Komeili, K. Konath, et al. Human-level play in the game of diplomacy by combining language models with strategic reasoning. Science, 378 0 (6624): 0 1067--1074, 2022
2022
-
[22]
P. J. Ball, J. Bauer, F. Belletti, B. Brownfield, A. Ephrat, S. Fruchter, A. Gupta, K. Holsheimer, A. Holynski, J. Hron, C. Kaplanis, M. Limont, M. McGill, Y. Oliveira, J. Parker-Holder, F. Perbet, G. Scully, J. Shar, S. Spencer, O. Tov, R. Villegas, E. Wang, J. Yung, C. Baetu, J. Berbel, D. Bridson, J. Bruce, G. Buttimore, S. Chakera, B. Chandra, P. Coll...
2025
-
[23]
Bar-Tal, H
O. Bar-Tal, H. Chefer, O. Tov, C. Herrmann, R. Paiss, S. Zada, A. Ephrat, J. Hur, G. Liu, A. Raj, Y. Li, M. Rubinstein, T. Michaeli, O. Wang, D. Sun, T. Dekel, and I. Mosseri. Lumiere: A space-time diffusion model for video generation. In SIGGRAPH Asia, pages 1--11, 2024
2024
-
[24]
L. Barcellona, A. Zadaianchuk, D. Allegro, S. Papa, S. Ghidoni, and E. Gavves. Dream to manipulate: Compositional world models empowering robot imitation learning with imagination. arXiv preprint arXiv:2412.14957, 2024
-
[25]
Revisiting Feature Prediction for Learning Visual Representations from Video
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. G. Rabbat, Y. LeCun, M. Assran, and N. Ballas. Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
Behler and M
J. Behler and M. Parrinello. Generalized neural-network representation of high-dimensional potential-energy surfaces. Physical Review Letters, 98 0 (14): 0 146401, 2007
2007
-
[27]
Beucler, P
T. Beucler, P. Gentine, J. Yuval, A. Gupta, L. Peng, J. Lin, S. Yu, S. Rasp, F. Ahmed, P. A. O'Gorman, J. D. Neelin, N. J. Lutsko, and M. Pritchard. Climate-invariant machine learning. Science Advances, 10 0 (6): 0 eadj7250, 2024
2024
-
[28]
K. Bi, L. Xie, H. Zhang, X. Chen, X. Gu, and Q. Tian. Accurate medium-range global weather forecasting with 3D neural networks. Nature, 619: 0 533--538, 2023
2023
-
[29]
H. Bian, L. Kong, H. Xie, L. Pan, Y. Qiao, and Z. Liu. DynamicCity : Large-scale 4D occupancy generation from dynamic scenes. In International Conference on Learning Representations, 2025
2025
-
[30]
F. Bianchi, P. J. Chia, M. Yuksekgonul, J. Tagliabue, D. Jurafsky, and J. Zou. How well can LLMs negotiate? negotiationarena platform and analysis. arXiv preprint arXiv:2402.05863, 2024
-
[31]
Bodnar, W
C. Bodnar, W. P. Bruinsma, A. Lucic, M. Stanley, A. Allen, J. Brandstetter, P. Garvan, M. Riechert, J. A. Weyn, H. Dong, J. K. Gupta, K. Thambiratnam, A. T. Archibald, C.-C. Wu, E. Heider, M. Welling, R. E. Turner, and P. Perdikaris. A foundation model for the earth system. Nature, 641 0 (8065): 0 1180--1187, 2025
2025
-
[32]
Boella and L
G. Boella and L. van der Torre. A game-theoretic approach to normative multi-agent systems. In Normative Multi-agent Systems. Schloss Dagstuhl, 2007
2007
-
[33]
N. M. Boffi, M. S. Albergo, and E. Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models. Transactions on Machine Learning Research, 2025
2025
-
[34]
D. A. Boiko, R. MacKnight, B. Kline, and G. Gomes. Autonomous chemical research with large language models. Nature, 624: 0 570--578, 2023
2023
-
[35]
Bolya and J
D. Bolya and J. Hoffman. Token merging for fast stable diffusion. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 4599--4603, 2023
2023
-
[36]
Bolya, C.-Y
D. Bolya, C.-Y. Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman. Token merging: Your vit but faster. In International Conference on Learning Representations, 2023
2023
-
[37]
A. M. Bran, S. Cox, O. Schilter, C. Baldassari, A. D. White, and P. Schwaller. Augmenting large language models with chemistry tools. Nature Machine Intelligence, 6 0 (5): 0 525--535, 2024
2024
-
[38]
Brooks, B
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y. Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh. Video generation models as world simulators. Technical report, OpenAI, 2024. URL https://openai.com/research/video-generation-models-as-world-simulators
2024
-
[39]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. A...
1901
-
[40]
Bruce, M
J. Bruce, M. Dennis, A. Edwards, J. Parker-Holder, Y. Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, Y. Aytar, S. Bechtle, F. Behbahani, S. Chan, N. Heess, L. Gonzalez, S. Osindero, S. Ozair, S. Reed, J. Zhang, K. Zolna, J. Clune, N. de Freitas, S. Singh, and T. Rockt \"a schel. Genie: Generative interactive environments. In International...
2024
-
[41]
N. Butt, B. Manczak, A. Wiggers, C. Rainone, D. W. Zhang, M. Defferrard, and T. Cohen. CodeIt : Self-improving language models with prioritized hindsight replay. In International Conference on Machine Learning, pages 5013--5034. PMLR, 2024
2024
-
[42]
Caesar, V
H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom. nuScenes : A multimodal dataset for autonomous driving. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11621--11631, 2020
2020
- [43]
- [44]
- [45]
-
[46]
H. Chae, N. Kim, K. T.-i. Ong, M. Gwak, G. Song, J. Kim, S. Kim, D. Lee, and J. Yeo. Web agents with world models: Learning and leveraging environment dynamics in web navigation. In International Conference on Learning Representations, 2025
2025
- [47]
-
[48]
Transdreamer: Reinforcement learning with transformer world models, 2024
C. Chen, Y.-F. Wu, J. Yoon, and S. Ahn. TransDreamer : Reinforcement learning with transformer world models. arXiv preprint arXiv:2202.09481, 2022
- [49]
-
[50]
L. Chen, Y. Meng, C. Tang, X. Ma, J. Jiang, X. Wang, Z. Wang, and W. Zhu. Q-DiT : Accurate post-training quantization for diffusion transformers. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28306--28315, 2025 b
2025
-
[51]
R. Chen, W. Jiang, C. Qin, and C. Tan. Theory of mind in large language models: Assessment and enhancement. In Annual Meeting of the Association for Computational Linguistics, pages 31539--31558, 2025 c
2025
-
[52]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning, pages 1597--1607. PMLR, 2020
2020
-
[53]
X. Chen, Y. Chen, Y. Fu, N. Gao, J. Jia, W. Jin, H. Li, Y. Mu, J. Pang, Y. Qiao, Y. Tian, B. Wang, B. Wang, F. Wang, H. Wang, T. Wang, Z. Wang, X. Wei, C. Wu, S. Yang, J. Ye, J. Yu, J. Zeng, J. Zhang, J. Zhang, S. Zhang, F. Zheng, B. Zhou, and Y. Zhu. InternVLA-M1 : A spatially guided vision-language-action framework for generalist robot policy. arXiv pre...
work page internal anchor Pith review arXiv 2025
- [54]
- [55]
- [56]
-
[57]
S. R. Chitturi, A. Ramdas, Y. Wu, B. Rohr, S. Ermon, J. Dionne, F. H. d. Jornada, M. Dunne, C. Tassone, W. Neiswanger, and D. Ratner. Targeted materials discovery using bayesian algorithm execution. NPJ Computational Materials, 10 0 (1): 0 156, 2024
2024
-
[58]
K. Chua, R. Calandra, R. McAllister, and S. Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. In Advances in Neural Information Processing Systems, volume 31, pages 4759--4770, 2018
2018
-
[59]
Chuang, A
Y.-S. Chuang, A. Goyal, N. Harlalka, S. Suresh, R. Hawkins, S. Yang, D. Shah, J. Hu, and T. Rogers. Simulating opinion dynamics with networks of llm-based agents. In Findings of the association for computational linguistics: NAACL 2024, pages 3326--3346, 2024
2024
-
[60]
A. Clark. Surfing Uncertainty: Prediction, Action, and the Embodied Mind. Oxford University Press, 2015
2015
-
[61]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
S. Community. Starvla: A lego-like codebase for vision-language-action model developing. arXiv preprint arXiv:2604.05014, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Cwm: An open-weights llm for research on code generation with world models
J. Copet, Q. Carbonneaux, G. Cohen, J. Gehring, J. Kahn, J. Kossen, F. Kreuk, E. McMilin, M. Meyer, Y. Wei, D. Zhang, K. Zheng, J. Armengol-Estap \'e , P. Bashiri, M. Beck, et al. CWM : An open-weights LLM for research on code generation with world models. arXiv preprint arXiv:2510.02387, 2025
-
[63]
Coutant, K
A. Coutant, K. Roper, D. Trejo-Banos, D. Bouthinon, M. Carpenter, J. Grzebyta, G. Santini, H. Soldano, M. Elati, J. Ramon, C. Rouveirol, L. N. Soldatova, and R. D. King. Closed-loop cycles of experiment design, execution, and learning accelerate systems biology model development in yeast. Proceedings of the National Academy of Sciences, 116 0 (36): 0 1814...
2019
-
[64]
K. J. W. Craik. The Nature of Explanation. Cambridge University Press, 1943
1943
- [65]
- [66]
-
[67]
Dainese, M
N. Dainese, M. Merler, M. Alakuijala, and P. Marttinen. Generating code world models with large language models guided by Monte Carlo tree search. In Advances in Neural Information Processing Systems, volume 37, pages 60429--60474, 2024
2024
-
[68]
A. C. Dama, K. S. Kim, D. M. Leyva, A. P. Lunkes, N. S. Schmid, K. Jijakli, and P. A. Jensen. BacterAI maps microbial metabolism without prior knowledge. Nature Microbiology, 8: 0 1018--1025, 2023
2023
-
[69]
Quevedo, Q
Decart, J. Quevedo, Q. McIntyre, S. Campbell, X. Chen, and R. Wachen. Oasis: A universe in a transformer. Blog post, 2024. URL https://oasis-model.github.io
2024
-
[70]
J. Degen. The rational speech act framework. Annual Review of Linguistics, 9 0 (1): 0 519--540, 2023
2023
-
[71]
M. P. Deisenroth and C. E. Rasmussen. PILCO : A model-based and data-efficient approach to policy search. In International Conference on Machine Learning, pages 465--472, 2011
2011
-
[72]
F. Deng, I. Jang, and S. Ahn. DreamerPro : Reconstruction-free model-based reinforcement learning with prototypical representations. In International Conference on Machine Learning, pages 4956--4975. PMLR, 2022
2022
-
[73]
X. Deng, Y. Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y. Su. Mind2Web : Towards a generalist agent for the web. In Advances in Neural Information Processing Systems, volume 36, pages 28091--28114, 2023
2023
-
[74]
Dettmers, M
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer. LLM.int8() : 8-bit matrix multiplication for transformers at scale. In Advances in Neural Information Processing Systems, volume 35, pages 30318--30332, 2022
2022
-
[75]
V. Dignum and F. Dignum. Agentifying agentic AI . arXiv preprint arXiv:2511.17332, 2025
-
[76]
J. Ding, Y. Zhang, Y. Shang, J. Feng, Y. Zhang, Z. Zong, Y. Yuan, H. Su, N. Li, J. Piao, Y. Deng, N. Sukiennik, C. Gao, F. Xu, and Y. Li. Understanding world or predicting future? A comprehensive survey of world models. ACM Computing Surveys, 2025 a
2025
-
[77]
X. Ding, G. Ding, Y. Guo, and J. Han. Centripetal sgd for pruning very deep convolutional networks with complicated structure. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4943--4953, 2019
2019
-
[78]
Z. Ding, C. Jin, D. Liu, H. Zheng, K. K. Singh, Q. Zhang, Y. Kang, Z. Lin, and Y. Liu. Dollar: Few-step video generation via distillation and latent reward optimization. In IEEE/CVF International Conference on Computer Vision, pages 17961--17971, 2025 b
2025
-
[79]
Dockhorn, A
T. Dockhorn, A. Vahdat, and K. Kreis. Genie: Higher-order denoising diffusion solvers. In Advances in Neural Information Processing Systems, volume 35, pages 30150--30166, 2022
2022
-
[80]
X. Dong, S. Chen, and S. Pan. Learning to prune deep neural networks via layer-wise optimal brain surgeon. Advances in Neural Information Processing Systems, 30: 0 4860--4874, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.