Recognition: 2 theorem links
· Lean TheoremEpicure: Multidimensional Flavor Structure in Food Ingredient Embeddings
Pith reviewed 2026-05-13 20:43 UTC · model grok-4.3
The pith
FlavorGraph's 300-dimensional ingredient embeddings already encode at least fifteen classifiable dimensions of taste, texture, geography, processing, and culture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
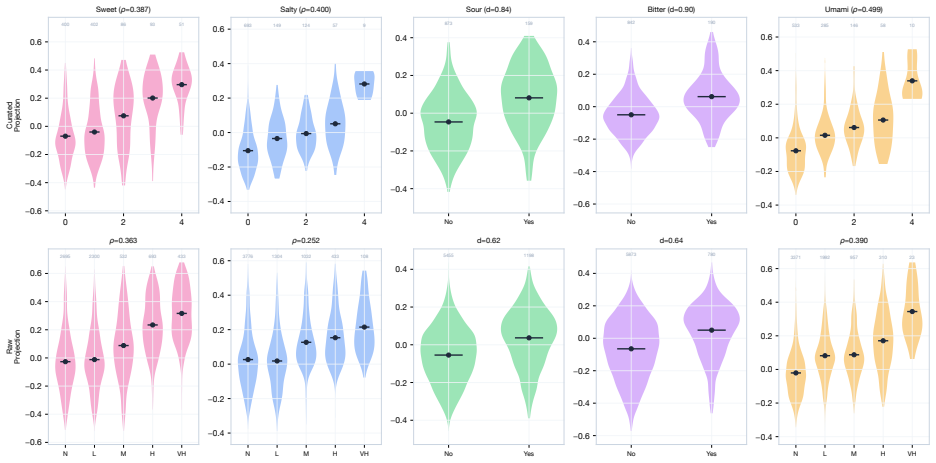
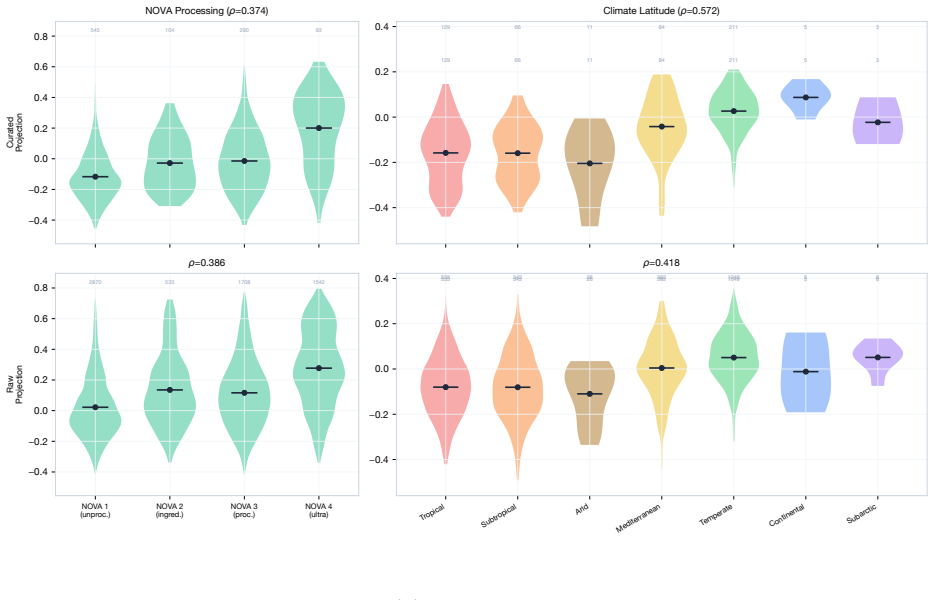
The authors show that chef intuition about flavor, texture, and cultural identity is already encoded in FlavorGraph's 300-dimensional ingredient embeddings trained on recipe co-occurrence and food chemistry, and that this knowledge can be systematically recovered after an LLM-augmented curation pipeline consolidates 6,653 raw entries into 1,032 canonical ingredients, yielding at least fifteen independently classifiable dimensions spanning taste, texture, geography, food processing, and culture.
What carries the argument
300-dimensional vectors for canonical ingredients, from which linear or clustering methods recover the fifteen or more orthogonal culinary axes.
If this is right
- Recipe search and recommendation systems can filter or rank results along explicit taste or texture axes instead of opaque similarity scores.
- Product developers can use the dimensions to predict how substituting one ingredient for another will change sensory and cultural profiles.
- Cross-cultural recipe adaptation becomes quantifiable by measuring shifts along geography and processing axes.
- Automated flavor pairing tools gain interpretable controls rather than black-box suggestions.
Where Pith is reading between the lines
- Similar latent structure may exist in other co-occurrence graphs such as music tracks or molecular compounds, allowing recovery of expert tacit knowledge without domain-specific labels.
- If the dimensions prove stable, they could serve as a low-dimensional basis for generating novel but plausible ingredient combinations.
- The approach suggests that large recipe corpora implicitly learn chemical and sensory regularities, so further supervised flavor data may yield only marginal gains.
Load-bearing premise
The LLM curation step merges raw ingredients into canonical forms without distorting or selectively amplifying the flavor-related patterns already present in the original embeddings.
What would settle it
Human culinary experts independently rate a held-out set of ingredients along the claimed dimensions; if agreement with the embedding-derived axes falls to chance level, the claimed structure is absent.
Figures










read the original abstract
A chef's intuition about flavor, texture, and cultural identity represents tacit knowledge that is difficult to articulate yet central to culinary practice. We show that this knowledge is already encoded in FlavorGraph's 300-dimensional ingredient embeddings, trained on recipe cooccurrence and food chemistry, and that it can be systematically recovered. An LLM-augmented curation pipeline consolidates 6,653 raw FlavorGraph ingredients into 1,032 canonical entries, substantially strengthening the recoverable structure. We identify at least fifteen independently classifiable dimensions spanning taste, texture, geography, food processing, and culture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that tacit culinary knowledge on flavor, texture, and cultural identity is already encoded in FlavorGraph's 300-dimensional ingredient embeddings (trained on recipe co-occurrence and food chemistry) and can be systematically recovered. An LLM-augmented curation pipeline reduces 6,653 raw ingredients to 1,032 canonical entries, which is said to strengthen the recoverable structure, and the work identifies at least fifteen independently classifiable dimensions spanning taste, texture, geography, food processing, and culture.
Significance. If the central recovery claim holds with proper validation, the result would be significant for computational food science: it would demonstrate that rich, multi-dimensional human-interpretable structure can be extracted from existing embedding models without retraining, offering a foundation for data-driven flavor pairing, recipe generation, and cultural analysis. The grounding in a publicly available embedding set like FlavorGraph is a potential strength if the extraction is shown to be faithful to the original geometry.
major comments (3)
- [Abstract] Abstract: The claim that the LLM-augmented curation pipeline 'substantially strengthening the recoverable structure' lacks any quantitative support such as before/after comparison of embedding coherence, explained variance in dimensionality reduction, or classification performance on the fifteen dimensions; this is load-bearing for the pipeline's role in the central claim.
- [Abstract] Abstract: No validation metrics, independence tests (e.g., pairwise correlations or mutual information between dimensions), or error analysis are supplied for the 'at least fifteen independently classifiable dimensions,' making it impossible to verify that the dimensions are recovered from the 300-d embeddings rather than imposed by the analysis.
- [Abstract] Abstract: The recovery claim treats the FlavorGraph embeddings as an external input whose latent structure is merely extracted, yet the LLM curation step (consolidating 6,653 to 1,032 entries) risks injecting external flavor and cultural knowledge; without an ablation (e.g., repeating the analysis via PCA/ICA on the raw embedding matrix alone) the contribution of the embeddings versus the LLM priors cannot be isolated.
minor comments (1)
- [Abstract] Abstract: The exact number of dimensions and the precise criteria used to declare them 'independently classifiable' are not stated, which would aid reproducibility even if the main validation is added elsewhere.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. These have identified key areas where additional quantitative support and validation are required to strengthen the manuscript. We address each major comment below and commit to revisions that incorporate the suggested analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the LLM-augmented curation pipeline 'substantially strengthening the recoverable structure' lacks any quantitative support such as before/after comparison of embedding coherence, explained variance in dimensionality reduction, or classification performance on the fifteen dimensions; this is load-bearing for the pipeline's role in the central claim.
Authors: We agree that quantitative evidence for the curation pipeline's contribution is essential. In the revised manuscript we will add explicit before-and-after comparisons on the same embedding space, reporting silhouette scores for dimension-based clustering, explained variance ratios from PCA, and classification F1 scores for the fifteen dimensions using both the raw 6,653-ingredient set and the curated 1,032-ingredient set. These metrics will directly quantify the improvement in recoverable structure. revision: yes
-
Referee: [Abstract] Abstract: No validation metrics, independence tests (e.g., pairwise correlations or mutual information between dimensions), or error analysis are supplied for the 'at least fifteen independently classifiable dimensions,' making it impossible to verify that the dimensions are recovered from the 300-d embeddings rather than imposed by the analysis.
Authors: We acknowledge the absence of these diagnostics. The revised version will include (i) a pairwise correlation matrix and mutual-information table across the fifteen dimensions, (ii) cross-validated classification accuracies with standard errors, and (iii) an error analysis that reports per-dimension precision/recall together with the unsupervised extraction procedure (PCA loadings and clustering) used to surface each dimension from the 300-d vectors. This will demonstrate that the dimensions arise from the embedding geometry. revision: yes
-
Referee: [Abstract] Abstract: The recovery claim treats the FlavorGraph embeddings as an external input whose latent structure is merely extracted, yet the LLM curation step (consolidating 6,653 to 1,032 entries) risks injecting external flavor and cultural knowledge; without an ablation (e.g., repeating the analysis via PCA/ICA on the raw embedding matrix alone) the contribution of the embeddings versus the LLM priors cannot be isolated.
Authors: The LLM step is restricted to name consolidation and canonicalization using textual similarity; no flavor, texture, or cultural labels are assigned by the model. All fifteen dimensions are recovered via unsupervised operations (PCA, ICA, and clustering) performed on the post-curation embedding matrix. To isolate contributions we will add an ablation that repeats the PCA/ICA pipeline on the raw 6,653-ingredient embedding matrix (where computationally tractable) and compares the stability and interpretability of the recovered axes. We will also expand the methods section to clarify the narrow scope of the LLM intervention. revision: yes
Circularity Check
Embeddings treated as external input; no reduction of dimensions to fitted parameters or self-citation chain
full rationale
The central claim states that flavor knowledge is already encoded in FlavorGraph's 300-d embeddings (trained externally on co-occurrence and chemistry) and is recovered via LLM-augmented curation that consolidates raw entries. No equation, derivation step, or self-citation is shown that defines the 15 dimensions in terms of quantities fitted inside this paper or that renames a fitted result as a prediction. The curation pipeline is presented as a tool to strengthen recoverable structure rather than as the source of the structure itself. This is consistent with a low-level external-input scenario (score 2) rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FlavorGraph 300-dimensional embeddings trained on recipe cooccurrence and food chemistry encode tacit knowledge of flavor, texture, geography, processing, and culture
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe show that this knowledge is already encoded in FlavorGraph's 300-dimensional ingredient embeddings, trained on recipe cooccurrence and food chemistry... We identify at least fifteen independently classifiable dimensions spanning taste, texture, geography, food processing, and culture.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearAn LLM-augmented curation pipeline consolidates 6,653 raw FlavorGraph ingredients into 1,032 canonical entries... using Gemini 3.1 Pro with structured JSON output.
Reference graph
Works this paper leans on
-
[1]
Michael Polanyi.The Tacit Dimension
doi: 10.52202/079017-0970. Michael Polanyi.The Tacit Dimension. Doubleday, New York, 1966. Charles Spence. Multisensory flavour perception: Blending, mixing, fusion, and pairing within and between the senses.Foods, 9(4):407, 2020. doi: 10.3390/foods9040407. Alina Surmacka Szczesniak. Classification of textural characteristics.Journal of Food Science, 28 (...
-
[2]
doi: 10.1145/3711118. 34 Appendices A Embedding Space Overview: Toroidal Manifold The 3D UMAP projection suggests that the embedding space forms atoroidal manifold: two dense clouds, corresponding to the sweet and savoury poles, connected by a transition zone of ingredi- ents that straddle both culinary contexts. We strongly encourage readers to explore t...
-
[3]
**botanical_family**: The APG IV botanical family of the primary plant source. - Only assign for whole or minimally processed plant-derived ingredients where the source plant is unambiguous. - Use "N/A" for: animal products, highly processed items, multi-ingredient items, and items where the botanical source is ambiguous. - Valid families: Amaryllidaceae,...
-
[4]
**climate_zone**: The primary climate zone where this ingredient is traditionally cultivated or originates. - Use "N/A" for: highly processed items, synthetic ingredients, items cultivated globally with no clear primary zone. - Valid zones: Tropical, Subtropical, Mediterranean, Temperate, Continental, Arid, Subarctic, N/A
-
[5]
1" = Unprocessed or minimally processed -
**nova_level**: NOVA food processing classification (Monteiro et al. 2019). - "1" = Unprocessed or minimally processed - "2" = Processed culinary ingredients - "3" = Processed foods - "4" = Ultra-processed
work page 2019
- [6]
-
[7]
**scoville_shu**: Estimated median Scoville Heat Units. 38 - 0 for any ingredient that is not a significant source of pungent heat. INGREDIENTS TO CLASSIFY: [numbered list of 25 ingredients] Return a JSON array with one object per ingredient, in the same order as listed above. Response schema(enforced via Gemini structured output): { "type": "ARRAY", "ite...
-
[8]
none" = no sweetness (salt, vinegar, most raw meats) -
**sweet_level**: Perceived sweetness intensity. - "none" = no sweetness (salt, vinegar, most raw meats) - "low" = faint sweetness (milk, carrot, corn) - "moderate" = clearly sweet (apple, beet, sweet potato) - "high" = distinctly sweet (honey, maple syrup, banana) - "very_high" = intensely sweet (sugar, molasses, candy)
-
[9]
[analogous 5-level scale with examples]
**salty_level**: Perceived saltiness intensity. [analogous 5-level scale with examples]
-
[10]
[analogous 5-level scale with examples]
**sour_level**: Perceived sourness / acidity. [analogous 5-level scale with examples]
-
[11]
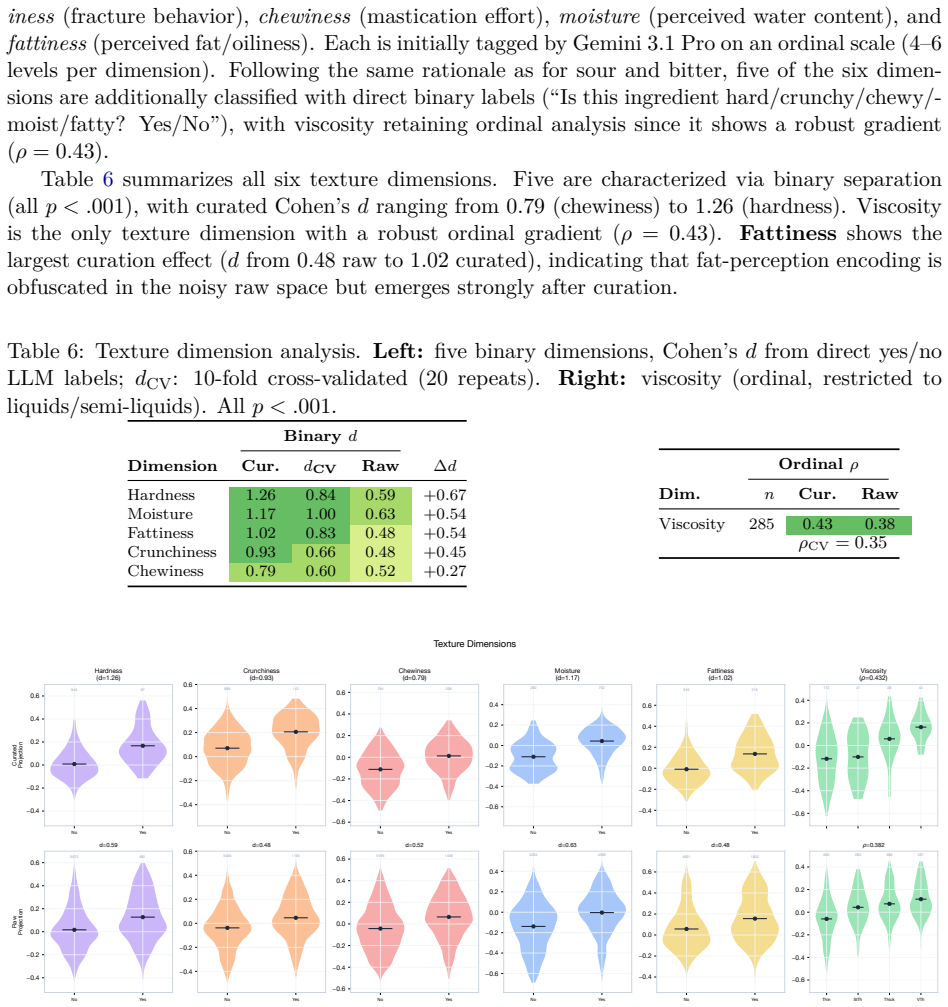
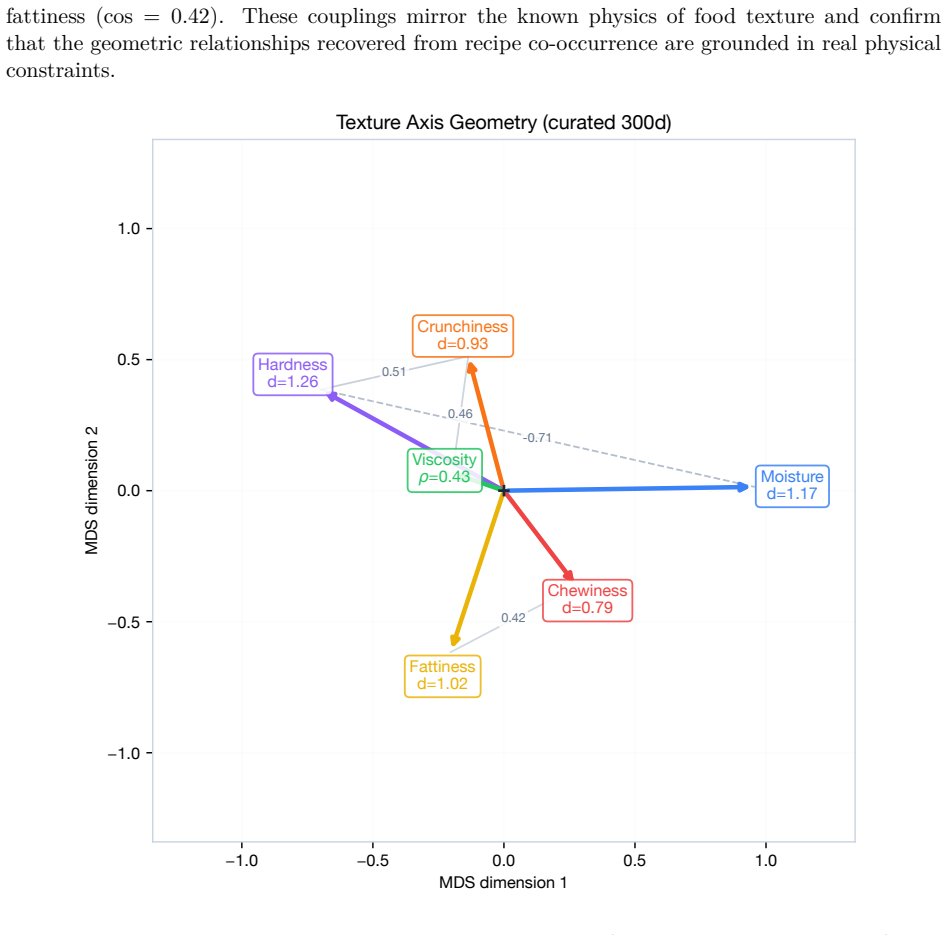
**bitter_level**: Perceived bitterness intensity. [analogous 5-level scale with examples] 39 B.3 Texture Dimensions SixtexturedimensionsgroundedinISO11036InternationalOrganizationforStandardization[2020] and the Szczesniak classification Szczesniak [1963]. Ingredients are classifiedas typically used in cooking. You are a food scientist specializing in sen...
work page 2020
- [12]
- [13]
- [14]
- [15]
-
[16]
**moisture**: Perceived water content. "dry" / "slightly_moist" / "moist" / "wet" / "very_wet"
-
[17]
**fattiness**: Perceived fat/oil content. "none" / "low" / "moderate" / "high" / "very_high" Each level includes concrete food examples (e.g., hardness: “liquid” = water, oil, soy sauce; “very_hard” = whole nutmeg, cinnamon stick, rock sugar). B.4 Binary Classification Independent yes/no classification for 7 dimensions, with no reference to the ordinal sc...
-
[18]
**sour**: Is this ingredient notably sour or acidic? (lemon, vinegar = yes; sugar, butter = no)
-
[19]
**bitter**: Is this ingredient notably bitter? (coffee, dark chocolate = yes; sugar, milk = no)
-
[20]
**hard**: Is this ingredient hard or very hard? (raw nuts, hard candy = yes; butter, yogurt = no)
-
[21]
**crunchy**: Is this ingredient notably crunchy or crispy? (raw carrot, tortilla chip = yes; milk, cheese = no)
-
[22]
**chewy**: Is this ingredient notably chewy? 40 (beef jerky, caramel = yes; water, sugar = no)
-
[23]
**moist**: Is this ingredient notably moist or wet? (watermelon, tomato = yes; flour, crackers = no)
-
[24]
**fatty**: Is this ingredient notably fatty or oily? (butter, olive oil = yes; water, vinegar = no) B.5 Cultural Cuisine Annotations Distinctive cultural marker tagging with the critical instruction that most ingredients should receive zerocuisine tags. You are a culinary anthropologist and food scientist. For each ingredient below, provide two classifica...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.