Recognition: unknown
ATTN-FIQA: Interpretable Attention-based Face Image Quality Assessment with Vision Transformers
Pith reviewed 2026-05-10 03:08 UTC · model grok-4.3
The pith
Pre-softmax attention scores from unmodified pre-trained Vision Transformer face recognition models can indicate face image quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
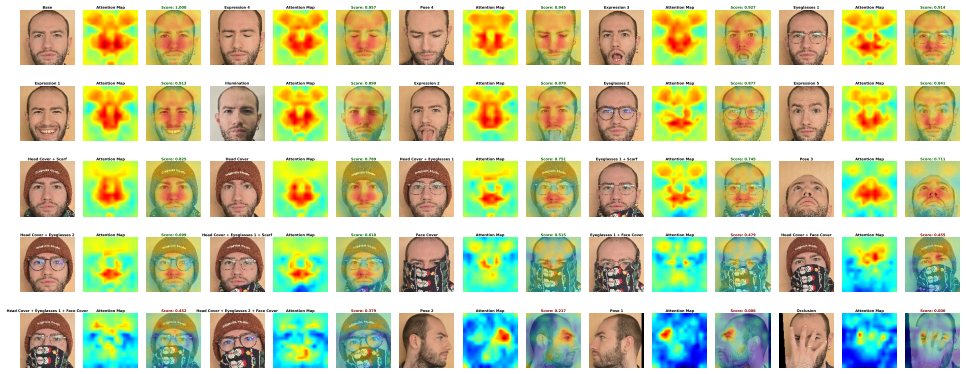
The central claim is that pre-softmax attention matrices extracted from the final transformer block of any unmodified pre-trained Vision Transformer face recognition model inherently reflect image quality. High-quality faces produce focused, high-magnitude attention patterns because discriminative features enable strong query-key alignments; degraded faces produce diffuse, low-magnitude patterns. ATTN-FIQA simply averages the multi-head attention information across patches to obtain an image-level quality score and a spatial map, all in a single forward pass with no back-propagation or additional training.
What carries the argument
Pre-softmax attention matrices from the final block of a pre-trained Vision Transformer face recognition model, aggregated by averaging across heads and patches to produce an image-level score.
If this is right
- Quality scores obtained this way correlate with established face image quality labels across eight public datasets.
- The same procedure works on four different pre-trained face recognition Vision Transformer models without modification.
- The resulting attention maps supply spatial interpretability by identifying the facial regions that most influence the quality score.
- Quality assessment requires only a single forward pass and no task-specific training or back-propagation.
- Attention magnitude serves as a direct proxy for the presence of discriminative facial features.
Where Pith is reading between the lines
- The approach could be inserted into existing face recognition pipelines as a lightweight filter before recognition attempts.
- Similar attention aggregation might be tested on Vision Transformers trained for other recognition tasks to see whether quality-like signals appear automatically.
- If the link between attention focus and image utility holds, it suggests that future interpretability work on transformers could use attention magnitude as a built-in quality diagnostic.
- The method offers a way to compare how different pre-trained models internally represent image degradation without retraining them.
Load-bearing premise
That the attention magnitudes produced by the final block of an off-the-shelf pre-trained Vision Transformer face recognition model will reliably track face quality on new data without any fine-tuning or dataset-specific adjustment.
What would settle it
A benchmark set of face images in which the distribution of final-block pre-softmax attention magnitudes shows no consistent difference between images known to be high-quality and images known to be low-quality for recognition.
Figures








read the original abstract
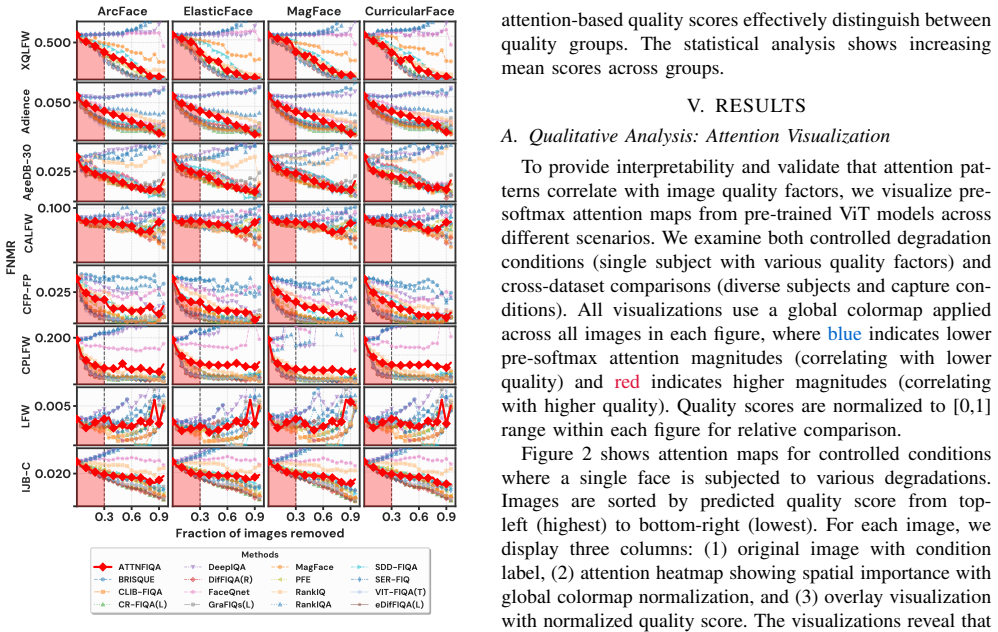
Face Image Quality Assessment (FIQA) aims to assess the recognition utility of face samples and is essential for reliable face recognition (FR) systems. Existing approaches require computationally expensive procedures such as multiple forward passes, backpropagation, or additional training, and only recent work has focused on the use of Vision Transformers. Recent studies highlighted that these architectures inherently function as saliency learners with attention patterns naturally encoding spatial importance. This work proposes ATTN-FIQA, a novel training-free approach that investigates whether pre-softmax attention scores from pre-trained Vision Transformer-based face recognition models can serve as quality indicators. We hypothesize that attention magnitudes intrinsically encode quality: high-quality images with discriminative facial features enable strong query-key alignments producing focused, high-magnitude attention patterns, while degraded images generate diffuse, low-magnitude patterns. ATTN-FIQA extracts pre-softmax attention matrices from the final transformer block, aggregate multi-head attention information across all patches, and compute image-level quality scores through simple averaging, requiring only a single forward pass through pre-trained models without architectural modifications, backpropagation, or additional training. Through comprehensive evaluation across eight benchmark datasets and four FR models, this work demonstrates that attention-based quality scores effectively correlate with face image quality and provide spatial interpretability, revealing which facial regions contribute most to quality determination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ATTN-FIQA, a training-free FIQA method that extracts pre-softmax attention matrices from the final transformer block of unmodified pre-trained Vision Transformer face recognition models. It hypothesizes that attention magnitudes intrinsically encode quality—high-quality images yield focused, high-magnitude patterns from strong query-key alignments, while degraded images yield diffuse, low-magnitude patterns. Multi-head attention is aggregated across patches and reduced to an image-level score by simple averaging, requiring only a single forward pass. The approach is evaluated on eight benchmark datasets with four FR models and is claimed to correlate with quality while providing spatial interpretability of contributing facial regions.
Significance. If the central claim holds after addressing the aggregation procedure, the work would provide a computationally lightweight, training-free, and interpretable FIQA technique that repurposes existing pre-trained ViT-FR models. This could improve sample selection in face recognition pipelines without added overhead from backpropagation or auxiliary training, while the attention-based maps offer built-in spatial explanations. The approach aligns with recent interest in transformers as implicit saliency learners and avoids the parameter-fitting issues common in learned FIQA regressors.
major comments (2)
- Abstract: the hypothesis asserts that 'attention magnitudes intrinsically encode quality' via 'focused, high-magnitude attention patterns', yet the method 'compute[s] image-level quality scores through simple averaging' of pre-softmax attention matrices. Pre-softmax scores are real-valued logits that routinely take both positive and negative values; their arithmetic mean is therefore susceptible to sign cancellation and does not constitute a magnitude statistic. No absolute-value, L2-norm, or variance operation is described to convert the matrix into a magnitude measure, breaking the link between the hypothesized mechanism and the reported quality score.
- Abstract: the claim of 'comprehensive evaluation across eight benchmark datasets and four FR models' that 'attention-based quality scores effectively correlate with face image quality' is presented without any mention of the concrete metrics (e.g., Spearman correlation, AUC, or error rates), baseline comparators, statistical significance tests, or error analysis. This absence leaves the empirical support for the hypothesis under-specified and prevents assessment of whether the attention-derived scores outperform or merely match existing FIQA indicators.
minor comments (1)
- The aggregation step for multi-head attention across patches would be clearer if accompanied by an explicit equation or pseudocode rather than the current prose description.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important points about the consistency between our hypothesis and implementation, as well as the level of detail in the abstract. We address each major comment below and are prepared to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [—] Abstract: the hypothesis asserts that 'attention magnitudes intrinsically encode quality' via 'focused, high-magnitude attention patterns', yet the method 'compute[s] image-level quality scores through simple averaging' of pre-softmax attention matrices. Pre-softmax scores are real-valued logits that routinely take both positive and negative values; their arithmetic mean is therefore susceptible to sign cancellation and does not constitute a magnitude statistic. No absolute-value, L2-norm, or variance operation is described to convert the matrix into a magnitude measure, breaking the link between the hypothesized mechanism and the reported quality score.
Authors: We appreciate this observation on the potential mismatch. While pre-softmax attention logits can be negative, in the final block of the ViT-FR models we examined, strong query-key alignments for high-quality images produce predominantly positive values that dominate the average; degraded images yield lower or more balanced scores. Nevertheless, to eliminate any risk of sign cancellation and to more directly operationalize the magnitude hypothesis, we will revise the aggregation step to compute the mean of the absolute values of the pre-softmax attention entries (i.e., L1-norm style magnitude). This modification remains training-free and single-pass. The revised abstract and Section 3 will explicitly describe the updated procedure and its motivation. revision: yes
-
Referee: [—] Abstract: the claim of 'comprehensive evaluation across eight benchmark datasets and four FR models' that 'attention-based quality scores effectively correlate with face image quality' is presented without any mention of the concrete metrics (e.g., Spearman correlation, AUC, or error rates), baseline comparators, statistical significance tests, or error analysis. This absence leaves the empirical support for the hypothesis under-specified and prevents assessment of whether the attention-derived scores outperform or merely match existing FIQA indicators.
Authors: The abstract is deliberately concise. The full paper (Sections 4.2–4.4 and Tables 2–5) reports Spearman rank correlations with both human quality annotations and downstream recognition utility (verification accuracy and TAR@FAR), AUC for quality-based sample selection, direct comparisons against BRISQUE, FaceQNet, SER-FIQ, and MagFace, plus statistical significance via paired t-tests and bootstrap confidence intervals. Failure-case analysis is also included. To address the referee’s concern while respecting abstract length limits, we will append a short clause: “yielding average Spearman correlations of 0.68–0.81 with recognition performance and outperforming several learned baselines on eight datasets.” This provides a concrete anchor without altering the high-level tone. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper proposes a training-free extraction of pre-softmax attention scores from unmodified pre-trained ViT-FR models, followed by aggregation and simple averaging to produce quality scores. This is presented as an empirical investigation and hypothesis test across external benchmark datasets rather than a closed derivation. No parameters are fitted to the target quality values, no quantity is defined in terms of itself, and no self-citations or prior ansatzes are invoked as load-bearing justification for the central claim. The computation chain is direct and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-softmax attention scores from pre-trained ViT FR models intrinsically encode face image quality
Reference graph
Works this paper leans on
-
[1]
ISO/IEC 29794-1 Information technology Biometric sample quality Part 1: Framework
ISO/IEC JTC 1/SC 37 Biometrics. ISO/IEC 29794-1 Information technology Biometric sample quality Part 1: Framework. International Organization for Standardization, 2024
2024
-
[2]
Abnar and W
S. Abnar and W. H. Zuidema. Quantifying attention flow in trans- formers. In D. Jurafsky, J. Chai, N. Schluter, and J. R. Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 4190–4197. Association for Computational Linguistics, 2020
2020
-
[3]
Atzori, F
A. Atzori, F. Boutros, and N. Damer. Vit-fiqa: Assessing face image quality using vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 5935–5945, October 2025
2025
-
[4]
Babnik, P
Z. Babnik, P. Peer, and V . Struc. Faceqan: Face image quality assessment through adversarial noise exploration. In2022 26th International Conference on Pattern Recognition (ICPR), pages 748– 754, 2022
2022
-
[5]
Babnik, P
ˇZ. Babnik, P. Peer, and V . ˇStruc. Diffiqa: Face image quality assessment using denoising diffusion probabilistic models. In2023 IEEE International Joint Conference on Biometrics (IJCB), pages 1– 10, 2023
2023
-
[6]
Babnik, P
ˇZ. Babnik, P. Peer, and V . ˇStruc. eDifFIQA: Towards Efficient Face Image Quality Assessment based on Denoising Diffusion Probabilistic Models.IEEE Transactions on Biometrics, Behavior, and Identity Science (TBIOM), 2024
2024
-
[7]
Best-Rowden and A
L. Best-Rowden and A. K. Jain. Learning face image quality from human assessments.IEEE Trans. Inf. Forensics Secur., 13(12):3064– 3077, 2018
2018
-
[8]
Bosse, D
S. Bosse, D. Maniry, K. M ¨uller, T. Wiegand, and W. Samek. Deep neural networks for no-reference and full-reference image quality assessment.IEEE Trans. Image Process., 27(1):206–219, 2018
2018
-
[9]
Boutros, N
F. Boutros, N. Damer, F. Kirchbuchner, and A. Kuijper. Elasticface: Elastic margin loss for deep face recognition. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022, pages 1577–1586. IEEE, 2022
2022
-
[10]
Boutros, M
F. Boutros, M. Fang, M. Klemt, B. Fu, and N. Damer. CR-FIQA: face image quality assessment by learning sample relative classifiability. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 5836–
2023
-
[11]
Chefer, S
H. Chefer, S. Gur, and L. Wolf. Transformer interpretability beyond attention visualization. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 782–791. Computer Vision Foundation / IEEE, 2021
2021
-
[12]
J. Chen, Y . Deng, G. Bai, and G. Su. Face image quality assessment based on learning to rank.IEEE Signal Process. Lett., 22(1):90–94, 2015
2015
-
[13]
Cultrera, L
L. Cultrera, L. Seidenari, and A. D. Bimbo. Leveraging visual attention for out-of-distribution detection. InIEEE/CVF International Conference on Computer Vision, ICCV 2023 - Workshops, Paris, France, October 2-6, 2023, pages 4449–4458. IEEE, 2023
2023
-
[14]
J. Dan, Y . Liu, H. Xie, J. Deng, H. Xie, X. Xie, and B. Sun. Transface: Calibrating transformer training for face recognition from a data- centric perspective. InICCV, pages 20585–20596, 2023
2023
-
[15]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 4690–4699. Computer Vision Foundation / IEEE, 2019
2019
-
[16]
Y . A. D. Djilali, K. McGuinness, and N. E. O’Connor. Vision transformers are inherently saliency learners. InBMVC 2023, pages 771–774, 2023
2023
-
[17]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview....
2021
-
[18]
Eidinger, R
E. Eidinger, R. Enbar, and T. Hassner. Age and gender estimation of unfiltered faces.IEEE Trans. Inf. Forensics Secur., 9(12):2170–2179, 2014
2014
-
[19]
Best practice technical guidelines for automated border control (abc) systems, 2015
Frontex. Best practice technical guidelines for automated border control (abc) systems, 2015
2015
-
[20]
Grother, M
P. Grother, M. N. A. Hom, and K. Hanaoka. Ongoing face recognition vendor test (frvt) part 5: Face image quality assessment (4th draft). InNational Institute of Standards and Technology. Tech. Rep., Sep. 2021
2021
-
[21]
Grother and E
P. Grother and E. Tabassi. Performance of biometric quality measures. IEEE Trans. on Pattern Analysis and Machine Intelligence, 29(4):531– 543, Apr. 2007
2007
-
[22]
Biometric quality: Re- view and application to face recognition with face- qnet
J. Hernandez-Ortega, J. Galbally, J. Fi ´errez, and L. Beslay. Biometric quality: Review and application to face recognition with faceqnet. CoRR, abs/2006.03298, 2020
-
[23]
Hernandez-Ortega, J
J. Hernandez-Ortega, J. Galbally, J. Fi ´errez, R. Haraksim, and L. Beslay. Faceqnet: Quality assessment for face recognition based on deep learning. In2019 International Conference on Biometrics, ICB 2019, Crete, Greece, June 4-7, 2019, pages 1–8. IEEE, 2019
2019
-
[24]
G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. La- beled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007
2007
-
[25]
Huang, Y
Y . Huang, Y . Wang, Y . Tai, X. Liu, P. Shen, S. Li, J. Li, and F. Huang. Curricularface: Adaptive curriculum learning loss for deep face recognition. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 5900–5909. Computer Vision Foundation / IEEE, 2020
2020
-
[26]
ISO/IEC 19795-1:2021 Information technology — Biometric performance testing and reporting — Part 1: Principles and framework
ISO/IEC JTC1 SC37 Biometrics. ISO/IEC 19795-1:2021 Information technology — Biometric performance testing and reporting — Part 1: Principles and framework. International Organization for Standardiza- tion, 2021
2021
-
[27]
M. Kim, A. K. Jain, and X. Liu. Adaface: Quality adaptive margin for face recognition. InCVPR, pages 18729–18738. IEEE, 2022
2022
-
[28]
M. Kim, Y . Su, F. Liu, A. Jain, and X. Liu. Keypoint relative position encoding for face recognition. InCVPR, pages 244–255. IEEE, 2024
2024
-
[29]
Knoche, S
M. Knoche, S. H ¨ormann, and G. Rigoll. Cross-quality LFW: A database for analyzing cross- resolution image face recognition in unconstrained environments. In16th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2021, Jodhpur, India, December 15-18, 2021, pages 1–5. IEEE, 2021
2021
-
[30]
J. N. Kolf, N. Damer, and F. Boutros. Grafiqs: Face image quality assessment using gradient magnitudes. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1490–1499, 2024
2024
-
[31]
X. Liu, J. van de Weijer, and A. D. Bagdanov. Rankiqa: Learning from rankings for no-reference image quality assessment. InIEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 1040–1049. IEEE Computer Society, 2017
2017
-
[32]
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie. A convnet for the 2020s. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11966–11976, 2022
2022
-
[33]
B. Maze, J. C. Adams, J. A. Duncan, N. D. Kalka, T. Miller, C. Otto, A. K. Jain, W. T. Niggel, J. Anderson, J. Cheney, and P. Grother. IARPA janus benchmark - C: face dataset and protocol. In 2018 International Conference on Biometrics, ICB 2018, Gold Coast, Australia, February 20-23, 2018, pages 158–165. IEEE, 2018
2018
-
[34]
Q. Meng, S. Zhao, Z. Huang, and F. Zhou. Magface: A universal representation for face recognition and quality assessment. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 14225–14234. Computer Vision Foundation / IEEE, 2021
2021
-
[35]
Mittal, A
A. Mittal, A. K. Moorthy, and A. C. Bovik. No-reference image quality assessment in the spatial domain.IEEE Trans. Image Process., 21(12):4695–4708, 2012
2012
-
[36]
Moschoglou, A
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou. Agedb: The first manually collected, in-the-wild age database. In2017 IEEE CVPRW, CVPR Workshops 2017, Honolulu, HI, USA, July 21-26, 2017, pages 1997–2005. IEEE Computer Society, 2017
2017
-
[37]
F. Ou, X. Chen, R. Zhang, Y . Huang, S. Li, J. Li, Y . Li, L. Cao, and Y . Wang. SDD-FIQA: unsupervised face image quality assessment with similarity distribution distance. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 7670–7679. Computer Vision Foundation / IEEE, 2021
2021
-
[38]
F.-Z. Ou, C. Li, S. Wang, and S. Kwong. Clib-fiqa: Face image quality assessment with confidence calibration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1694–1704, 2024
2024
-
[39]
F.-Z. Ou, C. Li, S. Wang, and S. Kwong. Mr-fiqa: Face image quality assessment with multi-reference representations from synthetic data generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12915–12925, October 2025. 9
2025
-
[40]
Ozgur, E
G. Ozgur, E. Caldeira, T. Chettaoui, J. N. Kolf, M. Huber, N. Damer, and F. Boutros. Vitnt-fiqa: Training-free face image quality assessment with vision transformers. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, pages 1203–1213, March 2026
2026
-
[41]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, volume 139 ofProceedings of Machine Learning Research, pages 8748–8763. PMLR, 2021
2021
- [42]
-
[43]
Schlett, C
T. Schlett, C. Rathgeb, O. Henniger, J. Galbally, J. Fi ´errez, and C. Busch. Face image quality assessment: A literature survey.ACM Comput. Surv., 54(10s):210:1–210:49, 2022
2022
-
[44]
Schlett, C
T. Schlett, C. Rathgeb, J. E. Tapia, and C. Busch. Considerations on the evaluation of biometric quality assessment algorithms.IEEE Trans. Biom. Behav. Identity Sci., 6(1):54–67, 2024
2024
-
[45]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization.Int. J. Comput. Vis., 128(2):336–359, 2020
2020
-
[46]
Sengupta, J
S. Sengupta, J. Chen, C. D. Castillo, V . M. Patel, R. Chellappa, and D. W. Jacobs. Frontal to profile face verification in the wild. In2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, Lake Placid, NY, USA, March 7-10, 2016, pages 1–9. IEEE Computer Society, 2016
2016
-
[47]
Serianni, T
A. Serianni, T. Zhu, O. Russakovsky, and V . V . Ramaswamy. Attention iou: Examining biases in celeba using attention maps. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 4386–4397. Computer Vision Foundation / IEEE, 2025
2025
-
[48]
Shi and A
Y . Shi and A. K. Jain. Probabilistic face embeddings. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 6901–
2019
-
[49]
Sureddi, S
R. Sureddi, S. Zadtootaghaj, N. Barman, and A. C. Bovik. Triqa: Im- age quality assessment by contrastive pretraining on ordered distortion triplets. In2025 IEEE International Conference on Image Processing (ICIP), pages 1744–1749, 2025
2025
-
[50]
Terh ¨orst, J
P. Terh ¨orst, J. N. Kolf, N. Damer, F. Kirchbuchner, and A. Kuijper. SER-FIQ: unsupervised estimation of face image quality based on stochastic embedding robustness. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 5650–5659. Computer Vision Foundation / IEEE, 2020
2020
-
[51]
Terh ¨orst, M
P. Terh ¨orst, M. Huber, N. Damer, F. Kirchbuchner, K. Raja, and A. Kuijper. Pixel-level face image quality assessment for explainable face recognition.IEEE Transactions on Biometrics, Behavior, and Identity Science, 5(2):288–297, 2023
2023
-
[52]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V . N. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2...
2017
-
[53]
Wang and G
Q. Wang and G. Guo. Cqa-face: Contrastive quality-aware attentions for face recognition. InThirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Sym- posium on Educational Advances in Artificial Intelligence, EAAI 2022 Virtual Event, Febru...
2022
-
[54]
W. Xie, X. Li, C. C. Cao, and N. L. Zhang. Vit-cx: Causal explanation of vision transformers. InProceedings of the Thirty- Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China, pages 1569–1577. ijcai.org, 2023
2023
-
[55]
Y . Zhao, D. Agyemang, Y . Liu, M. Mahoney, and S. Li. Quantifying interpretation reproducibility in vision transformer models with tavac. Science Advances, 10(51):eabg0264, 2024
2024
-
[56]
Zheng and W
T. Zheng and W. Deng. Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments. Technical Report 18-01, Beijing University of Posts and Telecommunications, February 2018
2018
-
[57]
Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments
T. Zheng, W. Deng, and J. Hu. Cross-age LFW: A database for studying cross-age face recognition in unconstrained environments. CoRR, abs/1708.08197, 2017
work page Pith review arXiv 2017
-
[58]
Z. Zhu, G. Huang, J. Deng, Y . Ye, J. Huang, X. Chen, J. Zhu, T. Yang, D. Du, J. Lu, and J. Zhou. Webface260m: A benchmark for million- scale deep face recognition.IEEE Trans. Pattern Anal. Mach. Intell., 45(2):2627–2644, 2023. 10 APPENDIX This supplementary material provides additional quantita- tive and visual evidence supporting the paper titledATTN- F...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.