Recognition: unknown
Dream-Cubed: Controllable Generative Modeling in Minecraft by Training on Billions of Cubes
Pith reviewed 2026-05-10 01:32 UTC · model grok-4.3
The pith
Training 3D diffusion models on billions of Minecraft blocks produces generators that create and edit voxel worlds directly in block space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
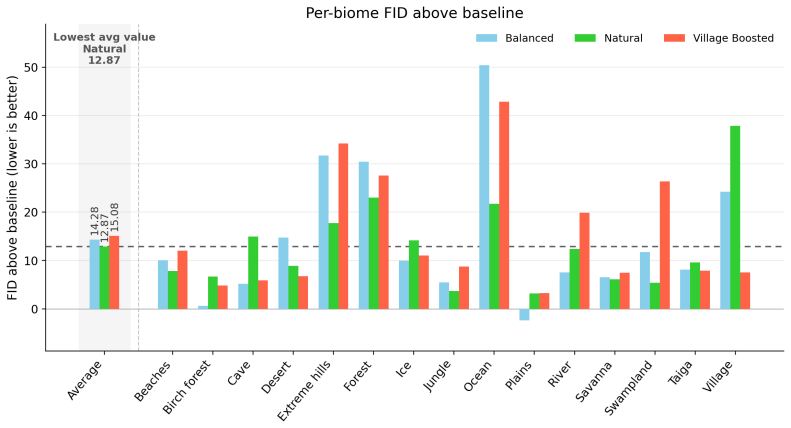
Dream-Cubed supplies a large-scale voxel dataset and trains diffusion models that treat blocks as the basic compositional units. These models generate Minecraft-style 3D environments efficiently while supporting direct interactive operations such as inpainting and outpainting from user-provided blocks, with quality measured by an adapted FID metric on rendered views and by human preference tests.
What carries the argument
3D diffusion models that generate by operating directly in the discrete space of individual Minecraft blocks as compositional units.
If this is right
- Models support interactive user workflows such as inpainting and outpainting from blocks supplied by the user.
- Generation runs efficiently because it stays inside the native block representation rather than converting to other formats.
- Large-scale comparisons identify effective choices for discrete versus continuous diffusion and for data composition in voxel tasks.
- Releasing the full dataset, code, and pretrained models provides a base for further work on structured 3D generative modeling.
Where Pith is reading between the lines
- Block-level diffusion could be extended by generating local chunks and assembling them into larger consistent worlds without retraining.
- The same direct-block approach might transfer to other voxel or grid-based domains such as architectural layouts or scientific volume data.
- Efficiency gains from staying in block space could enable real-time or on-device generation loops inside game engines.
Load-bearing premise
A carefully chosen mix of procedural terrain and human maps, when used to train diffusion models at this scale, will produce outputs that are both efficient and semantically meaningful for interactive 3D use, and that an adapted FID metric plus human preferences will reliably measure that quality.
What would settle it
A human preference study in which participants consistently rate generated worlds as less desirable than real Minecraft maps, or an adapted FID score that shows no reliable separation between real and generated renderings, would show the approach does not deliver controllable, semantically grounded generation.
Figures




















read the original abstract
We introduce Dream-Cubed, a large-scale dataset of Minecraft worlds at voxel resolution, and a family of models using cubes as powerful compositional units for efficient generation of interactive 3D environments. Dream-Cubed comprises tens of billions of tokens from a carefully curated mixture of procedural biome terrain and high-quality human-authored maps. We use this dataset to conduct the first large-scale study of 3D diffusion models for voxel generation, analyzing discrete and continuous diffusion formulations, data compositions, and architectural design choices. Our models operate directly in the space of blocks, enabling efficient and semantically grounded generation while supporting interactive user workflows such as inpainting and outpainting from user-authored blocks. To quantitatively evaluate our models, we adapt the FID metric to assess semantic differences between real and generated world renderings, and validate generation quality through a human preference study. We release the full dataset, code, and all our pretrained models, which we hope will provide a foundation for future research in efficient generative modeling for structured, interactive 3D environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dream-Cubed, a large-scale dataset of Minecraft voxel worlds comprising tens of billions of tokens from a curated mix of procedural biome terrain and human-authored maps. It conducts the first large-scale empirical study of 3D diffusion models for voxel generation, analyzing discrete versus continuous formulations, data compositions, and architectural choices. The models operate directly in block space to enable efficient, semantically grounded generation and support interactive workflows such as inpainting and outpainting from user-provided blocks. Evaluation adapts the FID metric to semantic differences in 2D renderings of real and generated worlds and includes a human preference study. The full dataset, code, and pretrained models are released.
Significance. If the central claims hold, this work provides a valuable open foundation for scalable generative modeling of structured, interactive 3D environments, with direct relevance to games, simulations, and voxel-based design tools. The release of billions of tokens of data and all pretrained models is a clear strength that enables reproducibility and follow-on research. The systematic ablations on diffusion formulations and data mixes offer practical insights for the community working on 3D generative models.
major comments (1)
- [Evaluation] The evaluation section relies on an adapted FID computed on 2D renderings of the 3D voxel outputs together with human preference ratings. It is unclear whether this metric captures 3D-specific properties such as block adjacency consistency, topological coherence, or spatial structure, which are load-bearing for the claims of 'semantically grounded generation' and reliable support for interactive inpainting/outpainting workflows. Without 3D-aware metrics or explicit validation on structural fidelity, the quantitative evidence for the headline efficiency and controllability claims remains incomplete.
minor comments (2)
- [Abstract] The abstract states 'tens of billions of tokens' without precise counts or a breakdown of the procedural versus human-authored portions; adding these statistics and a table summarizing dataset composition would improve clarity and allow readers to assess the data mix.
- [Evaluation] The description of the FID adaptation does not specify the rendering procedure (e.g., camera angles, resolution, or feature extractor) or how semantic differences are quantified; providing these implementation details is necessary for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the Dream-Cubed dataset and models. We address the evaluation concern point by point below and outline targeted revisions.
read point-by-point responses
-
Referee: The evaluation section relies on an adapted FID computed on 2D renderings of the 3D voxel outputs together with human preference ratings. It is unclear whether this metric captures 3D-specific properties such as block adjacency consistency, topological coherence, or spatial structure, which are load-bearing for the claims of 'semantically grounded generation' and reliable support for interactive inpainting/outpainting workflows. Without 3D-aware metrics or explicit validation on structural fidelity, the quantitative evidence for the headline efficiency and controllability claims remains incomplete.
Authors: We acknowledge that dedicated 3D structural metrics are not reported and that this leaves the quantitative support for certain claims incomplete. The adapted FID on 2D renderings serves as a semantic proxy because Minecraft worlds are experienced through their visual and functional structure, and renderings from multiple viewpoints capture adjacency patterns and overall coherence. The human preference study explicitly includes ratings on structural plausibility and usability for editing tasks. Because our models operate natively in discrete voxel space, block adjacency and topology are enforced by the representation itself rather than learned as soft constraints. We will revise the manuscript to add a short subsection with simple quantitative checks (e.g., empirical distributions of neighboring block types in generated versus training data) and to expand the discussion of qualitative inpainting/outpainting results that demonstrate local and global structural fidelity. These additions address the referee's concern without requiring a full redesign of the evaluation protocol. revision: partial
Circularity Check
Empirical ML study with no derivation chain or self-referential reductions
full rationale
The paper describes dataset curation from procedural biomes and human maps, training of voxel-space diffusion models, architectural ablations, and evaluation via adapted FID on 2D renderings plus human preference studies. No equations, first-principles derivations, or predictions are present that reduce by construction to fitted inputs, self-citations, or renamed quantities. Central claims rest on external training data, model outputs, and independent human validation rather than internal tautologies. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion schedule and architectural hyperparameters
axioms (1)
- domain assumption Diffusion models can effectively capture distributions over discrete voxel blocks when trained at large scale
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, 2021. Curran Associates Inc. ISBN 9781713845393
2021
-
[3]
World-gan: a generative model for minecraft worlds
Maren Awiszus, Frederik Schubert, and Bodo Rosenhahn. World-gan: a generative model for minecraft worlds. In2021 IEEE Conference on Games (CoG), page 1–8. IEEE Press,
-
[4]
In: IEEE Conference on Games (CoG)
doi: 10.1109/CoG52621.2021.9619133. URL https://doi.org/10.1109/CoG52621. 2021.9619133. 12
-
[5]
Unleashing transformers: Parallel token prediction with discrete absorbing diffusion for fast high-resolution image generation from vector-quantized codes
Sam Bond-Taylor, Peter Hessey, Hiroshi Sasaki, Toby P Breckon, and Chris G Willcocks. Unleashing transformers: Parallel token prediction with discrete absorbing diffusion for fast high-resolution image generation from vector-quantized codes. InEuropean Conference on Computer Vision, pages 170–188. Springer, 2022
2022
-
[6]
Oasis: A universe in a transformer.URL: https://oasis-model
Etched Decart, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a transformer.URL: https://oasis-model. github. io, 2(3):6, 2024
2024
-
[7]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bj¨orn Ommer. Taming transformers for high-resolution image synthesis. 2021 ieee. InCVF Conference on Computer Vision and Pattern Recognition (CVPR), volume 10, 2020
2021
-
[8]
Minedojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems, 35:18343–18362, 2022
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. Minedojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems, 35:18343–18362, 2022
2022
-
[9]
Beyond pixel histories: World models with persistent 3d state
Samuel Garcin, Thomas Walker, Steven McDonagh, Tim Pearce, Hakan Bilen, Tianyu He, Kaixin Wang, and Jiang Bian. Beyond pixel histories: World models with persistent 3d state. arXiv preprint arXiv:2603.03482, 2026
-
[10]
Openwebtext corpus
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. https://skylion007.github. io/OpenWebTextCorpus/, 2019. Accessed: 2026-04-10
2019
-
[11]
Evocraft: A new challenge for open-endedness
Djordje Grbic, Rasmus Berg Palm, Elias Najarro, Claire Glanois, and Sebastian Risi. Evocraft: A new challenge for open-endedness. InInternational Conference on the Applications of Evolutionary Computation (Part of EvoStar), pages 325–340. Springer, 2021
2021
-
[12]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10686–10696, 2022. doi: 10.1109/CVPR52688.2022.01043
-
[13]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018. URL https://arxiv.org/abs/1706.08500
work page Pith review arXiv 2018
-
[15]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781713829546
2020
-
[16]
Argmax flows and multinomial diffusion: Learning categorical distributions.Advances in neural information processing systems, 34:12454–12465, 2021
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forr´e, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions.Advances in neural information processing systems, 34:12454–12465, 2021
2021
-
[17]
Scaffold diffusion: Sparse multi-category voxel structure generation with discrete diffusion
Justin Jung. Scaffold diffusion: Sparse multi-category voxel structure generation with discrete diffusion. InNeurIPS 2025 Workshop on Structured Probabilistic Inference & Generative Modeling, 2025. URLhttps://openreview.net/forum?id=wdsPGJi40p
2025
-
[18]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35: 26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35: 26565–26577, 2022
2022
-
[19]
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions.arXiv preprint arXiv:2502.06768, 2025
-
[20]
Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012. 13
2012
-
[21]
Pyubiomes, a simple (wip) python wrapper for cubiomes by cubitect and other seedfinding utilities, 2021
Lilyyy411. Pyubiomes, a simple (wip) python wrapper for cubiomes by cubitect and other seedfinding utilities, 2021. URLhttps://github.com/lilyyy411/Pyubiomes
2021
-
[22]
Teamcraft: A benchmark for multi-modal multi-agent systems in minecraft,
Qian Long, Zhi Li, Ran Gong, Ying Nian Wu, Demetri Terzopoulos, and Xiaofeng Gao. Teamcraft: A benchmark for multi-modal multi-agent systems in minecraft.arXiv preprint arXiv:2412.05255, 2024
-
[23]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URL https: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834, 2023
work page internal anchor Pith review arXiv 2023
-
[25]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022
2022
-
[26]
Diffusion probabilistic models for 3d point cloud generation
Shitong Luo and Wei Hu. Diffusion probabilistic models for 3d point cloud generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2837–2845, 2021
2021
-
[27]
Building a large annotated corpus of english: The penn treebank.Computational linguistics, 19(2):313–330, 1993
Mitch Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of english: The penn treebank.Computational linguistics, 19(2):313–330, 1993
1993
-
[28]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInternational conference on machine learning, pages 8162–8171. PMLR, 2021
2021
-
[29]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review arXiv 2025
-
[30]
Moonshine: Distilling game content generators into steerable generative models
Yuhe Nie, Michael Middleton, Tim Merino, Nidhushan Kanagaraja, Ashutosh Kumar, Zhan Zhuang, and Julian Togelius. Moonshine: Distilling game content generators into steerable generative models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14344–14351, 2025
2025
-
[31]
New embedding models and API updates
OpenAI. New embedding models and API updates. https://openai.com/index/ new-embedding-models-and-api-updates/, January 2024
2024
-
[32]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[33]
mcaselector
Querz. mcaselector. URLhttps://github.com/Querz/mcaselector
-
[34]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review arXiv 2022
-
[35]
Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies
Xuanchi Ren, Jiahui Huang, Xiaohui Zeng, Ken Museth, Sanja Fidler, and Francis Williams. Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4209–4219, 2024
2024
-
[36]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[37]
Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
2024
-
[38]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022. 14
work page internal anchor Pith review arXiv 2022
-
[39]
Solaris: Building a multiplayer video world model in minecraft.arXiv preprint arXiv:2602.22208, 2026
Georgy Savva, Oscar Michel, Daohan Lu, Suppakit Waiwitlikhit, Timothy Meehan, Dhairya Mishra, Srivats Poddar, Jack Lu, and Saining Xie. Solaris: Building a multiplayer video world model in minecraft.arXiv preprint arXiv:2602.22208, 2026
-
[40]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis K. Titsias. Simplified and generalized masked diffusion for discrete data. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385
2024
-
[41]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[42]
Improved vector quan- tized diffusion models.ArXiv, abs/2205.16007, 2022
Zhicong Tang, Shuyang Gu, Jianmin Bao, Dong Chen, and Fang Wen. Improved vector quan- tized diffusion models.ArXiv, abs/2205.16007, 2022. URL https://api.semanticscholar. org/CorpusID:249209888
-
[43]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review arXiv 2023
-
[45]
Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jinbing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, Xiaojian Ma, and Yitao Liang. Jarvis-1: Open- world multi-task agents with memory-augmented multimodal language models.arXiv preprint arXiv: 2311.05997, 2023
-
[46]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[47]
Linqi Zhou, Yilun Du, and Jiajun Wu. 3d shape generation and completion through point-voxel diffusion. InProceedings of the IEEE/CVF international conference on computer vision, pages 5826–5835, 2021. 15 A Appendix A.1 Discussion Blocks as tokens.A recurring theme across our results is that operating directly on Minecraft’s na- tive block representation u...
-
[48]
We discard samples that are primarily underground via an air-content threshold (retaining chunks>15%air)
-
[49]
We discard chunks that contain less than 60 village-indicator blocks, such as doors and stairs, ensuring chunks contain structures, rather than natural terrain surrounding a village
-
[50]
We discard samples where village indicator blocks touch the boundary of the volume, ensuring that our model learns to generate complete structures rather than truncated ones. Overall, this data collection level yields 178,271 village chunks. Human data collectionWe extract chunk data from human-authored by extending the “mcaselector” tool [32], to allow f...
-
[51]
Both candidates are intended to represent the same target biome, which will be shown at the top of the screen
Each candidate contains four terrain chunks. Both candidates are intended to represent the same target biome, which will be shown at the top of the screen. Your task is to choose the better overall set. You will be asked to complete 60 trials as part of this study. When making your choice, use the following priority:
-
[52]
Visual quality and match to the target biome Prefer the set that looks more like plausible Minecraft terrain for the given biome and has fewer obvious artifacts, unnatural structures, broken patterns, or other visual errors. 2. Overall preference if still tied in your mind If the two sets seem equally good with respect to both quality and biome match, cho...
-
[53]
We finally compute per-biome win rates for each model, reported in table 15
We also construct a pairwise win-rate matrix for each pairing of sources (table 14), showing how each source performed against all others. We finally compute per-biome win rates for each model, reported in table 15. We report 95% Wilson confidence intervals and number of trials for tables 13 and 14. We also conduct a one-sided binomial test under the null...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.