Recognition: unknown
SwarmDrive: Semantic V2V Coordination for Latency-Constrained Cooperative Autonomous Driving
Pith reviewed 2026-05-10 00:35 UTC · model grok-4.3
The pith
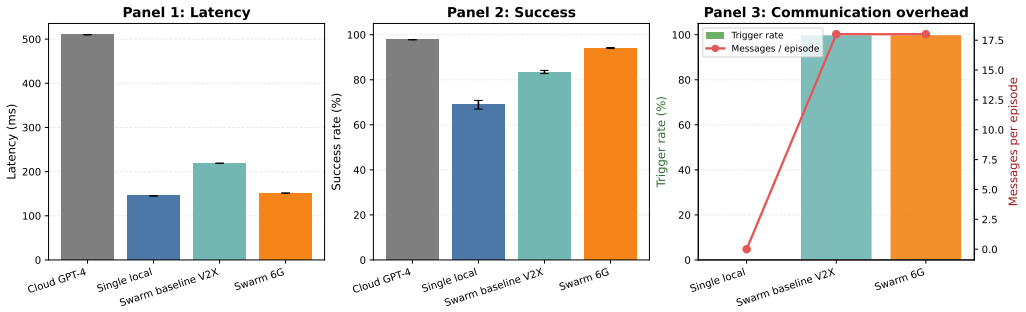
SwarmDrive lets nearby vehicles share local model intents on high uncertainty to reach 94.1 percent success at occluded intersections in 151 milliseconds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SwarmDrive is a semantic V2V framework in which each vehicle runs a local small language model, transmits compact intent distributions solely when entropy is high, and applies event-triggered consensus to combine the distributions from nearby vehicles, producing 94.1 percent success and 151.4 ms latency in the occluded intersection case under a 6G communication setting, compared with 68.9 percent success for an isolated local model and 510 ms latency for cloud inference.
What carries the argument
Event-triggered consensus that merges compact intent distributions shared by local SLMs only when uncertainty exceeds a threshold.
If this is right
- The cooperative success gain remains stable across the tested range of swarm sizes and packet-loss rates.
- Best balance occurs near an active swarm of four vehicles and an entropy trigger threshold of 0.65.
- Larger numbers of participating vehicles raise communication overhead and increase packet loss.
- Semantic edge cooperation achieves the reported gains under the tight latency constraints of the intersection scenario.
Where Pith is reading between the lines
- The finding that gains hold across ablations implies the framework may tolerate moderate variations in communication quality without losing its core advantage.
- The observed limit around four vehicles suggests coordination benefits may peak at small groups before overhead dominates, a pattern worth checking in other multi-agent settings.
- Because the method avoids constant cloud reliance, it could reduce infrastructure demands for cooperative driving if the intent-sharing logic transfers to additional traffic maneuvers.
Load-bearing premise
The five-seed simulation built around one occluded intersection, together with the modeled local SLM intent distributions and event-triggered consensus, accurately represents real-world V2V communication dynamics and model reliability under occlusion.
What would settle it
A physical test at a comparable occluded intersection using actual vehicles and 6G V2V links that yields success rates below 80 percent or average latencies above 300 milliseconds would show the performance gains do not hold outside the simulation.
Figures



read the original abstract
Cloud-hosted LLM inference for autonomous driving adds round-trip delay and depends on stable connectivity, while purely local edge models struggle under occlusion. We present SwarmDrive, a semantic Vehicle-to-Vehicle (V2V) coordination framework in which nearby vehicles run local Small Language Models (SLMs), share compact intent distributions only when uncertainty is high, and fuse them through event-triggered consensus. We evaluate SwarmDrive in a 5-seed executable study built around one occluded intersection case, combining matched operating-point comparisons with robustness sweeps. In that setting, SwarmDrive under its 6G communication setting ("Swarm 6G") raises success from 68.9% to 94.1% over a single local SLM while reducing latency from a 510 ms cloud reference to 151.4 ms. However, an increased number of participating vehicles leads to higher communication overhead and packet loss. SwarmDrive also evaluates the impact of swarm-size, packet-loss, and entropy-threshold sweeps and shows that the cooperative gain holds across ablations and is best balanced near an active swarm size of 4 vehicles and an entropy trigger threshold of 0.65 in the current prototype. These results show that semantic edge cooperation can work under tight latency constraints in the targeted intersection case, but they are not a deployment-grade validation of a real 6G stack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SwarmDrive, a semantic V2V coordination framework for latency-constrained cooperative autonomous driving. Vehicles run local SLMs that share compact intent distributions only on high-uncertainty events and fuse them via event-triggered consensus. In a 5-seed executable simulation study of one occluded intersection, the Swarm 6G variant improves success rate from 68.9% (single local SLM) to 94.1% while cutting latency from a 510 ms cloud baseline to 151.4 ms. Ablations over swarm size, packet loss, and entropy threshold identify a practical operating point near 4 vehicles and 0.65 threshold; the work explicitly scopes results to this simulated case and disclaims deployment-grade validation.
Significance. If the simulation faithfully captures the targeted dynamics, the result indicates that semantic edge cooperation among SLMs can deliver substantial gains in both reliability and latency over purely local or cloud-only baselines in occlusion scenarios. The executable 5-seed study, explicit ablations, and clear scoping of claims constitute a reproducible starting point for research on cooperative edge AI in autonomous driving. The absence of circular derivations or fitted parameters further supports the internal consistency of the reported performance deltas.
major comments (2)
- Evaluation: The central quantitative claims (success-rate lift from 68.9% to 94.1% and latency drop to 151.4 ms) rest on a 5-seed study, yet no error bars, per-seed values, or statistical significance tests are provided. This directly affects confidence in whether the reported gains are robust, which is load-bearing for the paper's performance assertions.
- Methods / simulation description: The manuscript supplies insufficient detail on the concrete SLM used, the precise generation and verification of intent distributions, the consensus algorithm implementation, and how the occluded-intersection scenario (vehicle dynamics, sensor models, occlusion geometry) is realized. These elements are required to reproduce or assess the validity of the success-rate and latency numbers that constitute the paper's main result.
minor comments (1)
- The abstract and evaluation section could more explicitly state the definition of 'success' (e.g., collision avoidance, goal reaching) and the exact latency measurement points to aid reader interpretation.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We appreciate the positive assessment of the work's internal consistency and reproducibility potential. Below we address each major comment in detail, indicating the revisions we will undertake.
read point-by-point responses
-
Referee: Evaluation: The central quantitative claims (success-rate lift from 68.9% to 94.1% and latency drop to 151.4 ms) rest on a 5-seed study, yet no error bars, per-seed values, or statistical significance tests are provided. This directly affects confidence in whether the reported gains are robust, which is load-bearing for the paper's performance assertions.
Authors: We agree that the lack of variability measures and formal significance testing reduces confidence in the robustness of the reported deltas. In the revised manuscript we will add error bars (standard deviation across the five seeds) to all quantitative figures, include a table of per-seed success rates and latencies in an appendix, and report the results of a paired statistical test (Wilcoxon signed-rank) on the improvements versus the single-SLM and cloud baselines. These additions draw directly from the existing simulation runs. revision: yes
-
Referee: Methods / simulation description: The manuscript supplies insufficient detail on the concrete SLM used, the precise generation and verification of intent distributions, the consensus algorithm implementation, and how the occluded-intersection scenario (vehicle dynamics, sensor models, occlusion geometry) is realized. These elements are required to reproduce or assess the validity of the success-rate and latency numbers that constitute the paper's main result.
Authors: We acknowledge that the current level of implementation detail is insufficient for independent reproduction. We will expand the Methods and Simulation Setup sections to specify the exact SLM (model family, parameter count, quantization, and inference settings), the mathematical formulation and verification procedure for the intent distributions, pseudocode plus hyperparameters for the event-triggered consensus algorithm, and the full scenario configuration including vehicle kinematic models, sensor noise models, and geometric occlusion parameters. We will also release the executable simulation code and configuration files as supplementary material upon acceptance. revision: yes
Circularity Check
No significant circularity; empirical simulation results only
full rationale
The manuscript presents an empirical framework evaluated via a 5-seed simulation study around one occluded intersection, with direct reporting of success rates (68.9% to 94.1%), latency (510 ms to 151.4 ms), and ablation sweeps over swarm size, packet loss, and entropy threshold. No derivation chain, first-principles equations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text or abstract. All performance claims are scoped as outcomes of executable simulation runs rather than reductions to inputs by construction. The central claim remains independent of any circular structure.
Axiom & Free-Parameter Ledger
free parameters (2)
- entropy trigger threshold =
0.65
- active swarm size =
4
axioms (1)
- domain assumption Local small language models can produce reliable compact intent distributions under occlusion conditions.
Reference graph
Works this paper leans on
-
[1]
A survey of autonomous driving: Common practices and emerging technologies,
E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda, “A survey of autonomous driving: Common practices and emerging technologies,” IEEE Access, vol. 8, pp. 58 443–58 469, 2020
2020
-
[2]
Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles,
C. Cuiet al., “Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles,” in2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), 2024, pp. 902–909
2024
-
[3]
GPT-Driver: Learning to Drive with GPT
J. Mao, Y . Qian, H. Zhao, and Y . Wang, “Gpt-driver: Learning to drive with large language models,”arXiv preprint arXiv:2310.01415, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model,
Z. Xuet al., “Drivegpt4: Interpretable end-to-end autonomous driving via large language model,”IEEE Robotics and Automation Letters, pp. 8186–8193, 2024
2024
-
[5]
C. Cuiet al., “LLM4AD: Large language models for autonomous driving: Concept, review, benchmark, experiments, and future trends,” arXiv preprint arXiv:2410.15281, 2024
-
[6]
Y . Wu, D. Li, Y . Chen, R. Jianget al., “Multi-agent autonomous driving systems with large language models: A survey of recent advances, resources, and future directions,”arXiv preprint arXiv:2502.16804, 2025
-
[7]
Chain- of-thought for autonomous driving: A comprehensive survey and future prospects,
Y . Cui, H. Lin, S. Yang, Y . Wang, Y . Huang, and H. Chen, “Chain- of-thought for autonomous driving: A comprehensive survey and future prospects,”arXiv preprint arXiv:2505.20223, 2025
-
[8]
Drivemlm: aligning multi-modal large language models with behavioral planning states for autonomous driving,
W. Wang, J. Xie, C. Hu, H. Zou, J. Fan, W. Tong, Y . Wen, S. Wu, H. Deng, Z. Li, H. Tian, L. Lu, X. Zhu, X. Wang, Y . Qiao, and J. Dai, “Drivemlm: aligning multi-modal large language models with behavioral planning states for autonomous driving,”Visual Intelligence, vol. 3, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:266210476
2023
-
[9]
Driving with llms: Fusing object-level vector modality for explainable autonomous driving,
L. Chenet al., “Driving with llms: Fusing object-level vector modality for explainable autonomous driving,” in2024 IEEE International Con- ference on Robotics and Automation (ICRA), 2024, pp. 14 093–14 100
2024
-
[10]
L. Wen, D. Fu, X. Li, X. Cai, T. Ma, P. Cai, M. Dou, B. Shi, L. He, and Y . Qiao, “Dilu: A knowledge-driven approach to autonomous driving with large language models,”arXiv preprint arXiv:2309.16292, 2023
-
[11]
Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to- vehicle communication,
R. Xu, H. Xiang, X. Xia, J. Han, J. Li, and J. Ma, “Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to- vehicle communication,” inIEEE International Conference on Robotics and Automation (ICRA), 2022, pp. 2583–2589
2022
-
[12]
V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,
R. Xu, H. Xiang, J. Han, X. Xia, Z. Zhang, J. Li, and J. Ma, “V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,” in European Conference on Computer Vision (ECCV), 2022, pp. 107–124
2022
-
[13]
Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,
Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022
2022
-
[14]
Monthly Weather Review 78, 1–3
H.-k. Chiu, R. Hachiuma, C.-Y . Wang, S. F. Smith, Y .-C. F. Wang, and M.-H. Chen, “V2V-LLM: Vehicle-to-vehicle cooperative autonomous driving with multimodal large language models,”arXiv preprint arXiv:2502.09980, 2025
-
[15]
Achievable performance gains by connected driving,
S. Partani, D. Wang, R. Sattiraju, A. Qiu, A. Weinand, and H. D. Schotten, “Achievable performance gains by connected driving,” in Commercial Vehicle Technology 2020/2021. Wiesbaden, Germany: Springer Vieweg, 2021, pp. 39–49
2020
-
[16]
A survey on the role of artificial intelligence and machine learning in 6G-V2X applications,
D. Wang, A. Qiu, Q. Zhou, and H. D. Schotten, “A survey on the role of artificial intelligence and machine learning in 6G-V2X applications,” arXiv preprint arXiv:2506.09512, 2025
-
[17]
Q. Team, “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Effect of retransmissions on the performance of C-V2X communication for 5G,
D. Wang, R. R. Sattiraju, A. Qiu, S. Partani, and H. D. Schotten, “Effect of retransmissions on the performance of C-V2X communication for 5G,” in2020 IEEE 92nd Vehicular Technology Conference (VTC2020- Fall), 2020
2020
-
[19]
Eval- uating the impact of numerology and retransmission on 5G NR V2X communication at a system-level simulation,
D. Wang, P. B. Mohite, Q. Zhou, A. Qiu, and H. D. Schotten, “Eval- uating the impact of numerology and retransmission on 5G NR V2X communication at a system-level simulation,” in2023 IEEE Conference on Standards for Communications and Networking (CSCN), 2023, pp. 59–65
2023
-
[20]
Mitigat- ing broadcast storm problem in V ANET when parked cars being awaken as relays,
A. Qiu, D. Wang, S. Partani, R. Sattiraju, and H. D. Schotten, “Mitigat- ing broadcast storm problem in V ANET when parked cars being awaken as relays,” in2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), 2020, pp. 631– 639
2020
-
[21]
Modern OpenAI gym simulation platforms for vehicular ad-hoc network systems,
A. Qiu, D. Wang, S. Partani, and H. D. Schotten, “Modern OpenAI gym simulation platforms for vehicular ad-hoc network systems,” 2023, researchGate article manuscript, March 2023
2023
-
[22]
Methodologies of link-level simulator and system-level simulator for C-V2X communication,
D. Wang, R. R. Sattiraju, A. Qiu, S. Partani, and H. D. Schotten, “Methodologies of link-level simulator and system-level simulator for C-V2X communication,” in2019 IEEE 2nd International Conference on Electronics and Communication Engineering (ICECE), 2019, pp. 178– 184
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.