Recognition: unknown
IntrAgent: An LLM Agent for Content-Grounded Information Retrieval through Literature Review
Pith reviewed 2026-05-09 21:15 UTC · model grok-4.3
The pith
IntrAgent retrieves fine-grained answers from scientific literature by ranking sections then iteratively extracting details, beating RAG baselines by 13.2 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
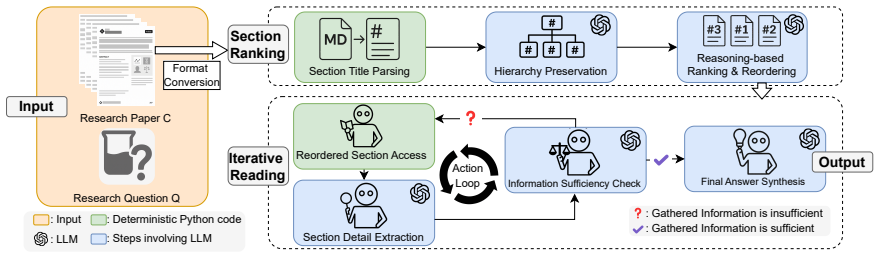
IntrAgent addresses the IntraView task through a two-stage pipeline: a Section Ranking stage that prioritizes relevant literature sections through structural-knowledge-enabled reasoning, followed by an Iterative Reading stage that continuously extracts details and synthesizes them into concise, contextually grounded answers. Across seven backbone LLMs, IntrAgent achieves on average 13.2 percent higher cross-domain accuracy than state-of-the-art RAG and research-agent baselines on the 315-instance IntraBench benchmark built from expert-authored questions spanning five STEM domains.
What carries the argument
The two-stage pipeline of Section Ranking, which uses structural knowledge to order relevant paper sections, and Iterative Reading, which extracts and refines details until a grounded answer is formed.
If this is right
- The method scales to seven different LLM backbones while preserving the accuracy gain.
- Content-grounded retrieval becomes more reliable for supporting analytical decisions across STEM fields.
- IntraBench provides a standardized way to measure faithfulness in literature-based question answering.
- Iterative extraction reduces the chance of incomplete or synthesized answers that stray from source material.
- Automation of fine-grained retrieval can now be evaluated directly against human-like reading behavior.
Where Pith is reading between the lines
- The section-ranking step could be applied to non-STEM domains to test whether structural cues remain effective outside scientific papers.
- Combining the iterative reading loop with larger multi-paper corpora might allow end-to-end literature reviews without manual section selection.
- If the grounding property holds, the same pipeline could lower hallucination rates in other LLM applications that must cite source text.
- Future benchmarks could add conflicting statements within papers to measure how well the iterative stage resolves internal inconsistencies.
Load-bearing premise
The 315 expert-authored questions in IntraBench are representative of real research-driven queries and the agent's iterative extraction stays strictly grounded in the provided literature without external knowledge leakage.
What would settle it
Human experts reviewing IntrAgent outputs on a fresh set of research queries find that answers contain details absent from the supplied papers, or that accuracy gains over baselines vanish when tested on literature from a sixth domain outside the original five.
Figures


read the original abstract
Scientific research relies on accurate information retrieval from literature to support analytical decisions. In this work, we introduce a new task, INformation reTRieval through literAture reVIEW (IntraView), which aims to automate fine-grained information retrieval faithfully grounded in the provided content in response to research-driven queries, and propose IntrAgent, an LLM-based agent that addresses this challenging task. In particular, IntrAgent is designed to mimic human behaviors when reading literature for information retrieval -- identifying relevant sections and then iteratively extracting key details to refine the retrieved information. It follows a two-stage pipeline: a Section Ranking stage that prioritizes relevant literature sections through structural-knowledge-enabled reasoning, and an Iterative Reading stage that continuously extracts details and synthesizes them into concise, contextually grounded answers. To support rigorous evaluation, we introduce IntraBench, a new benchmark consisting of 315 test instances built from expert-authored questions paired with literature spanning five STEM domains. Across seven backbone LLMs, IntrAgent achieves on average 13.2% higher cross-domain accuracy than state-of-the-art RAG and research-agent baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the IntraView task for automating fine-grained, content-grounded information retrieval from literature in response to research-driven queries. It proposes IntrAgent, an LLM-based agent that mimics human literature review behavior via a two-stage pipeline: Section Ranking (using structural-knowledge-enabled reasoning to prioritize relevant sections) followed by Iterative Reading (continuously extracting details and synthesizing concise, grounded answers). To evaluate, the authors release IntraBench, a benchmark of 315 expert-authored questions paired with literature from five STEM domains, and report that IntrAgent yields an average 13.2% higher cross-domain accuracy than SOTA RAG and research-agent baselines across seven backbone LLMs.
Significance. If the accuracy gains can be attributed to improved content grounding (rather than prompting or iteration artifacts), the work would meaningfully advance automated scientific literature analysis by providing a more faithful retrieval mechanism for complex, multi-document research queries. The new benchmark and task definition are useful contributions for the field, though their long-term value hinges on demonstrated representativeness and controls against parametric knowledge leakage.
major comments (3)
- [Experiments section] The headline result (13.2% average cross-domain accuracy lift) is presented without error bars, per-domain or per-LLM breakdowns, or statistical significance tests. This makes it impossible to determine whether the improvement is robust or driven by a subset of the five domains or seven backbones, directly affecting the central empirical claim.
- [Iterative Reading stage description] No mechanism, ablation, or audit (e.g., literature ablation, post-cutoff fact checks, or citation tracing) is described to verify that answers are strictly extracted from the supplied literature rather than the backbone LLM's parametric knowledge. This is load-bearing for the 'content-grounded' claim, as many IntraBench questions may be answerable from pre-training data alone.
- [IntraBench construction] The representativeness of the 315 expert-authored questions for real research-driven queries is asserted without supporting validation (e.g., comparison to actual researcher query logs or diversity metrics across domains). This weakens the generalizability of the benchmark and the reported gains.
minor comments (2)
- [Abstract and Results] The abstract and results section use 'cross-domain accuracy' without explicitly defining how domains are partitioned or whether the metric averages over questions or domains.
- [Figures/Tables] Figure or table captions for the pipeline diagram and benchmark statistics could be expanded to clarify the exact inputs/outputs at each stage.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify the presentation of our empirical results and strengthen the claims around content grounding and benchmark validity. We address each major comment point-by-point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments section] The headline result (13.2% average cross-domain accuracy lift) is presented without error bars, per-domain or per-LLM breakdowns, or statistical significance tests. This makes it impossible to determine whether the improvement is robust or driven by a subset of the five domains or seven backbones, directly affecting the central empirical claim.
Authors: We agree that the current results section would benefit from greater transparency. In the revised manuscript we will expand the evaluation to include (i) per-domain and per-LLM accuracy tables, (ii) standard deviations computed over three independent runs with different random seeds, and (iii) paired t-tests with p-values to establish statistical significance of the reported gains. These additions will allow readers to assess whether the 13.2% average improvement holds across all domains and backbones. revision: yes
-
Referee: [Iterative Reading stage description] No mechanism, ablation, or audit (e.g., literature ablation, post-cutoff fact checks, or citation tracing) is described to verify that answers are strictly extracted from the supplied literature rather than the backbone LLM's parametric knowledge. This is load-bearing for the 'content-grounded' claim, as many IntraBench questions may be answerable from pre-training data alone.
Authors: We acknowledge that an explicit verification mechanism is necessary to substantiate the content-grounded claim. The Iterative Reading stage is architecturally constrained to operate only on the sections returned by the Section Ranking stage, and the final answer is required to cite specific section identifiers. However, we did not include a dedicated ablation or audit in the original submission. In revision we will add (a) a literature-ablation experiment that removes all provided sections and measures the resulting drop in accuracy, and (b) manual citation-tracing on a random sample of 50 answers to confirm that every factual claim is traceable to the supplied literature. We will also note the use of literature published after the backbone models' training cutoffs where possible. revision: yes
-
Referee: [IntraBench construction] The representativeness of the 315 expert-authored questions for real research-driven queries is asserted without supporting validation (e.g., comparison to actual researcher query logs or diversity metrics across domains). This weakens the generalizability of the benchmark and the reported gains.
Authors: The 315 questions were authored by domain experts specifically to emulate the kinds of fine-grained, research-driven queries that arise during literature reviews in their respective fields. While we did not provide quantitative comparison against external query logs in the initial version, we will add supporting analyses in the revision: average query length and complexity statistics, term-overlap diversity metrics across the five domains, and a qualitative discussion of how the questions differ from generic QA benchmarks. We believe expert authorship confers substantial face validity, yet we accept that additional empirical validation would further strengthen the benchmark's claims. revision: partial
Circularity Check
No circularity: purely empirical evaluation on new benchmark
full rationale
The paper defines a new task (IntraView), proposes an LLM agent (IntrAgent) with a two-stage pipeline, introduces a benchmark (IntraBench with 315 expert questions), and reports direct empirical accuracy gains (13.2% average) against baselines. No mathematical derivations, equations, parameter fittings, or predictions are claimed that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central result is a falsifiable performance comparison on held-out test instances, fully independent of any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
9 Shahzeb Ansari, Haiping Du, Fazel Naghdy, and David Stirling
Epub 2021 May 14. 9 Shahzeb Ansari, Haiping Du, Fazel Naghdy, and David Stirling. 2022. Automatic driver cognitive fatigue detection based on upper body posture variations. Expert Systems with Applications, 203:117568. Anthropic. 2024. Introducing contextual retrieval. https://www.anthropic.com/engineering/ contextual-retrieval. Accessed: 2025-09-10. S. K...
2021
-
[2]
Scimaster: Towards general-purpose scientific ai agents, part i
Covid-19 pandemic in india: a mathematical model study.Nonlinear Dynamics, 102(1):537–553. Epub 2020 Sep 21. Andres M Bran, Sam Cox, Oliver Schilter, Carlo Baldas- sari, Andrew D White, and Philippe Schwaller. 2024. Augmenting large language models with chemistry tools.Nature Machine Intelligence, 6(5):525–535. Tex.copyright: 2024 The Author(s). Jingyi Ch...
-
[3]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang
Toward the digital twin of additive manufac- turing: Integrating thermal simulations, sensing, and analytics to detect process faults.Iise Transactions, 52(11):1204–1217. Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-augmented gen- eration for large language models: a ...
2024
-
[4]
Peng Gong, Bin Chen, Xuecao Li, Han Liu, Jie Wang, Yuqi Bai, Jingming Chen, Xi Chen, Lei Fang, and Shuailong et al
Finer resolution observation and monitoring of global land cover: first mapping results with Landsat TM and ETM+ data.International Journal of Remote Sensing, 34(7):2607–2654. Peng Gong, Bin Chen, Xuecao Li, Han Liu, Jie Wang, Yuqi Bai, Jingming Chen, Xi Chen, Lei Fang, and Shuailong et al. Feng. 2020a. Mapping essen- tial urban land use categories in Chi...
2018
-
[5]
arXiv preprint arXiv:2406.15319
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Sys- tems, 43(2):1–55. Enahoro A. Iboi, Oluwaseun Sharomi, Calistus N. Ngonghala, and Abba B. Gumel. 2020. Mathemati- cal modeling and analysis of COVID-19 pandemic in Nigeria.Mathematical biosciences and engineering: MB...
-
[6]
Siva Reddy, Danqi Chen, and Christopher D
Machine learning enabled multiplex detec- tion of periodontal pathogens by surface-enhanced Raman spectroscopy.International Journal of Bio- logical Macromolecules, 257:128773. Siva Reddy, Danqi Chen, and Christopher D. Manning
-
[7]
CoQA: a conversational question answering challenge.arXiv preprint. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Di- rani, Julian Michael, and Samuel R. Bowman. 2023. GPQA: a graduate-level google-proof Q&a bench- mark.arXiv preprint. Joshua C. Rothstein, Jiaheng Cui, Yanjun Yang, Xi- anyan Chen, and Yiping Z...
-
[8]
arXiv preprint arXiv:2401.00368
Efficient and Interpretable Compressive Text Summarisation with Unsupervised Dual-Agent Rein- forcement Learning.arXiv preprint. 12 Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchunshu Zhou, Pan Lu, Zhuosheng Zhang, and Yilun Zhao et al. 2025. ChemAgent: Self-updating library in large language models improves chemical rea...
-
[9]
Fuda Ye, Shuangyin Li, Yongqi Zhang, and Lei Chen
Rapid detection of SARS-CoV-2 RNA in human nasopharyngeal specimens using surface- enhanced raman spectroscopy and deep learning al- gorithms.ACS Sensors, 8(1):297–307. Fuda Ye, Shuangyin Li, Yongqi Zhang, and Lei Chen
-
[10]
Financial report chunking for effective retrieval augmented generation,
R^2AG: Incorporating retrieval information into retrieval augmented generation.arXiv preprint. Antonio Jimeno Yepes, Yao You, Jan Milczek, Sebas- tian Laverde, and Renyu Li. 2024. Financial report chunking for effective retrieval augmented genera- tion.Preprint, arXiv:2402.05131. Da Yin, Faeze Brahman, Abhilasha Ravichander, Khy- athi Chandu, Kai-Wei Chan...
-
[11]
Starting Out 1
Introduction 1. Starting Out 1. asdjkh Introduction blah 1. An Overture to the Matter at Hand
-
[12]
Stuff We Used and Did 2
Materials and methods 2. Stuff We Used and Did 2. jkjhas Materials and doings
-
[13]
Bacteria and sample preparation 2.1
Of Materials Gathered and Deeds Undertaken 2.1. Bacteria and sample preparation 2.1. Germs and How We Got Them 2.1. ajskdfh Bacteria things and getting stuff 2.1. Of Bacterium’s Harvest and Preparations Befitting Study 2.2. AFM imaging 2.2. Taking Tiny Pics 2.2. kjashdf AFM looking-at-things 2.2. Wherein the Art of Atomic Force Is Employed to Gaze Upon th...
-
[14]
What Happened 3
Results 3. What Happened 3. kjsdhf Results what happened
-
[15]
AFM analysis of microbial shape and dimension 3.1
Revelations and Findings Most Curious 3.1. AFM analysis of microbial shape and dimension 3.1. Shapes of the Germs 3.1. qwekjh Germ shapes and sizes 3.1. Of Form and Measure—The Shape of the Microscopic Realm 3.2. SERS signature of periodontal pathogens 3.2. Shiny Lights from Germs 3.2. kjasdh SERS noise from germs 3.2. Upon the Light’s Whisper: Signatures...
-
[16]
What We Think It Means 4
Discussion 4. What We Think It Means 4. lkjdfh What we think (maybe?)
-
[17]
A Discourse Upon the Meaning of These Happenings
-
[18]
Wrapping It Up 5
Conclusion 5. Wrapping It Up 5. THE END (idk lol) 5. A Summation, As the Curtain Draws Near CRediT authorship contribution statement Who Did What blorpflorp CRediT who did what maybe Of Quills and Labors: A Testament to Those Who Contributed Declaration of competing interest We Don’t Got Any Fights About This nope-no-fightz Declaration or whatever Of Conf...
2019
-
[19]
jkjhas Materials and doings - 2.3
2. jkjhas Materials and doings - 2.3. asdkljfh SERS zappy laser stuff — This section specifically mentions "SERS" in its title, indicating it likely contains detailed information about the SERS substrates, including their materials and structure or morphology
-
[20]
Materials and doings
2. jkjhas Materials and doings - 2.1. ajskdfh Bacteria things and getting stuff — As part of the "Materials and doings" main section, this subsection may dis- cuss materials related to the experimen- tal setup, possibly including the SERS substrates
-
[21]
jkjhas Materials and doings - 2.2
2. jkjhas Materials and doings - 2.2. kjashdf AFM looking-at-things — This subsection likely involves materials char- acterization using AFM, which may in- clude details about substrate morphology or materials
-
[22]
Abstract
asdjkh Introduction blah — The in- troduction often contains a summary of the materials and methods used, poten- tially offering an overview of the SERS substrate materials and structure. ... This ultimately leads to correct section alloca- tion, enabling detailed information gathering and passing the information sufficiency check without difficulty. It a...
-
[23]
[Title 1] — [1-sentence justification]
-
[24]
"" 27 E.2 Iterative Reading Prompts E.2.1 Action Loop Prompt Prompt: Action Loop main_prompt =
[Title 2] — [1-sentence justification] ... **Final ranking:** <<<2>>>, <<<1>>>, <<<3>>>, ... <<<n>>>,→ Let's think step by step. """ 27 E.2 Iterative Reading Prompts E.2.1 Action Loop Prompt Prompt: Action Loop main_prompt = """ You are an assistant designed to select the next Action based on the current observation. ,→ ,→ Each observation contains: - The...
-
[26]
Repeat this process until you can confidently terminate
Your task is to iteratively retrieve a Knowledge Chunk, extract relevant details, and evaluate whether you can answer the research question. Repeat this process until you can confidently terminate. ,→ ,→ ,→ ,→ ,→
-
[28]
,→ ,→ 28
In each iteration, you must select exactly one action based on the current observation. ,→ ,→ 28
-
[31]
,→ ,→ ,→ ,→ ,→
If the most recent action in the past actions taken was GET_CHUNK, your next action **must** be GET_DETAIL to extract information from the current Knowledge Chunk — do not perform this extraction yourself. ,→ ,→ ,→ ,→ ,→
-
[35]
,→ ,→ ,→
You must TERMINATE the process once you have gathered enough information to confidently answer the research question. ,→ ,→ ,→
-
[36]
Pay attention to the total number of Knowledge Chunks. If your most recent EVALUATE action was performed on the **last available Knowledge Chunk** and the result was insufficient, you must TERMINATE the process due to lack of additional information. ,→ ,→ ,→ ,→ ,→ ,→
-
[37]
If not, continue to the next Knowledge Chunk
The expected workflow is: GET_CHUNK→ GET_DETAIL→EVALUATE→TERMINATE (if evaluation result is sufficient). If not, continue to the next Knowledge Chunk. If you reach the final Knowledge Chunk and the evaluation is still insufficient, you must TERMINATE. ,→ ,→ ,→ ,→ ,→ ,→ ,→
-
[38]
,→ ,→ ,→ ,→
You may TERMINATE early if an EVALUATE action confirms that the gathered information is sufficient to answer the research question with high confidence. ,→ ,→ ,→ ,→
-
[39]
"" E.2.3 Section Detail Extraction Prompt Prompt: Action: Section Detail Extraction get_detail_prompt =
After your reasoning, output your response in the specified format.,→ """ E.2.3 Section Detail Extraction Prompt Prompt: Action: Section Detail Extraction get_detail_prompt = """ You are a research assistant helping extract detailed information relevant to the given Research Question based on a Knowledge Chunk given. ,→ ,→ ,→ --- Research Question: {quest...
-
[40]
,→ ,→ ,→
You must select **only one answer choice** from the list that is either correct or most relevant to the research question. ,→ ,→ ,→
-
[41]
Do not include any other text in your final output
Provide your answer as a single letter (e.g., A, B, C, D, E, F) enclosed in the format <<<ANS>>>. Do not include any other text in your final output. ,→ ,→ ,→
-
[42]
,→ ,→ ,→
You may include step-by-step reasoning to justify your decision, but your final output must consist of only one answer choice in the required format. ,→ ,→ ,→
-
[43]
F. None of the above
This is a science and technology-related research question. For cases where the short answer involves numerical values: ,→ ,→ ,→ - You must map the short answer to the most accurate and relevant answer choice. ,→ ,→ - If the short answer and an answer choice represent numerical values, apply the following decimal precision alignment rules: ,→ ,→ ,→ - If t...
-
[44]
No information in given details
Never provide multiple answers. **Example of output format:** *reasoning steps* --- <<<C>>> Let's think step by step. """ E.4 Confidence Level Ablation Study Prompts E.4.1 Confidence Level 1 Ablation Study - Conservative Information Sufficiency Check Prompt Prompt: Sufficiency Check Confidence Level 1 evaluation_prompt_confidence_level_1 = """ You are a r...
-
[45]
Earlier Knowledge Chunks are more likely to contain useful information
You will be provided with a list of Knowledge Chunks, ordered by relevance to the research question. Earlier Knowledge Chunks are more likely to contain useful information. ,→ ,→ ,→ ,→
-
[46]
Repeat this process until you have evaluated all available Knowledge Chunks or gathered enough information to confidently terminate
Your task is to iteratively retrieve a Knowledge Chunk, extract relevant details, and evaluate whether you can answer the research question. Repeat this process until you have evaluated all available Knowledge Chunks or gathered enough information to confidently terminate. ,→ ,→ ,→ ,→ ,→ ,→ ,→
-
[49]
,→ ,→ ,→
The observation includes: the current Knowledge Chunk index, the total number of available Knowledge Chunks, and the list of past actions taken. ,→ ,→ ,→
-
[51]
,→ ,→ ,→ ,→ ,→ 33
If the most recent action in the past actions taken was GET_CHUNK, your next action **must** be GET_DETAIL to extract information from the current Knowledge Chunk — do not perform this extraction yourself. ,→ ,→ ,→ ,→ ,→ 33
-
[54]
Use this ordering to guide your reading sequence
Since Knowledge Chunks are ordered by relevance to the research question, earlier Knowledge Chunks are more likely to contain useful information. Use this ordering to guide your reading sequence. ,→ ,→ ,→ ,→ ,→
-
[55]
,→ ,→ ,→ ,→ ,→
You must TERMINATE the process only after either (a) all available Knowledge Chunks have been evaluated, or (b) you are confident that the research question can be answered based on the most recent evaluation. ,→ ,→ ,→ ,→ ,→
-
[56]
If your most recent EVALUATE action was performed on the **last available Knowledge Chunk**, you must TERMINATE the process regardless of the outcome
Pay attention to the total number of Knowledge Chunks. If your most recent EVALUATE action was performed on the **last available Knowledge Chunk**, you must TERMINATE the process regardless of the outcome. ,→ ,→ ,→ ,→ ,→
-
[57]
If not, continue to the next chunk
The expected workflow is: GET_CHUNK→ GET_DETAIL→EVALUATE→TERMINATE (if evaluation result is sufficient). If not, continue to the next chunk. If you reach the final chunk and the evaluation is still insufficient, you must TERMINATE. ,→ ,→ ,→ ,→ ,→ ,→
-
[58]
Always continue until a conclusive evaluation result is available or all chunks are exhausted
Do not TERMINATE early based solely on assumptions about relevance. Always continue until a conclusive evaluation result is available or all chunks are exhausted. ,→ ,→ ,→ ,→
-
[59]
"" E.4.4 Confidence Level 3 Ablation Study - Action Loop Aggressive Instruction Prompt: Confidence Level Case Study Prompts 3 main_prompt_instructions_confidence_level_3 =
After your reasoning, output your response in the specified format.,→ """ E.4.4 Confidence Level 3 Ablation Study - Action Loop Aggressive Instruction Prompt: Confidence Level Case Study Prompts 3 main_prompt_instructions_confidence_level_3 = """,→
-
[60]
Earlier chunks are more likely to contain useful information
You will be provided with a list of knowledge chunks, ordered by relevance to the research question. Earlier chunks are more likely to contain useful information. ,→ ,→ ,→ ,→
-
[61]
Repeat this process until you can confidently terminate
Your task is to iteratively retrieve a knowledge chunk, extract relevant details, and evaluate whether you can answer the research question. Repeat this process until you can confidently terminate. ,→ ,→ ,→ ,→ ,→
-
[62]
You will be given a list of predefined actions to select from.,→
-
[63]
In each iteration, you must select exactly one action based on the current observation. ,→ ,→
-
[64]
,→ ,→ ,→
The observation includes: the current chunk index, the total number of available chunks, and the list of past actions taken. ,→ ,→ ,→
-
[65]
The available actions are: GET_CHUNK, GET_DETAIL, EVALUATE, and TERMINATE, as defined in the action list. ,→ ,→
-
[66]
,→ ,→ ,→ ,→ ,→
If the most recent action in the past actions taken was GET_CHUNK, your next action **must** be GET_DETAIL to extract information from the current knowledge chunk — do not perform this extraction yourself. ,→ ,→ ,→ ,→ ,→
-
[67]
,→ ,→ ,→ ,→ ,→
If the most recent action was GET_DETAIL, your next action **must** be EVALUATE to assess whether the gathered details are sufficient to answer the research question — do not perform the evaluation yourself. ,→ ,→ ,→ ,→ ,→
-
[68]
You must select only one action at a time — never choose multiple actions in a single step. ,→ ,→
-
[69]
Use this ordering to guide your reading sequence
Since knowledge chunks are ordered by relevance to the research question, earlier chunks are more likely to contain useful information. Use this ordering to guide your reading sequence. ,→ ,→ ,→ ,→ ,→
-
[70]
,→ ,→ ,→ ,→ ,→
You may TERMINATE the process as soon as you believe that additional knowledge chunks are unlikely to provide significantly better information, even if you are not fully confident. ,→ ,→ ,→ ,→ ,→
-
[71]
,→ ,→ ,→
If your most recent EVALUATE action was performed on the **last available chunk**, you must TERMINATE the process regardless of the outcome. ,→ ,→ ,→
-
[72]
You may also TERMINATE early based on the assumption that remaining chunks have diminishing relevance
The expected workflow is: GET_CHUNK→ GET_DETAIL→EVALUATE→TERMINATE. You may also TERMINATE early based on the assumption that remaining chunks have diminishing relevance. ,→ ,→ ,→ ,→
-
[73]
,→ ,→ ,→
Terminate aggressively if your evaluation suggests NO from continuing, even if high confidence has not yet been achieved. ,→ ,→ ,→
-
[74]
"" E.5 Contextual RAG Prompt Prompt: Contextual RAG Prompt prompt =
After your reasoning, output your response in the specified format.,→ """ E.5 Contextual RAG Prompt Prompt: Contextual RAG Prompt prompt = """ You are an expert technical writer specialised in contextual retrieval.,→ <document> {whole_document} </document> Here is the chunk we want to situate within the whole document,→ <chunk> {chunk} </chunk> 34 Please ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.