Recognition: unknown
SketchVLM: Vision language models can annotate images to explain thoughts and guide users
Pith reviewed 2026-05-09 21:28 UTC · model grok-4.3
The pith
Vision-language models can generate editable SVG overlays on images to visually explain their answers and raise task accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
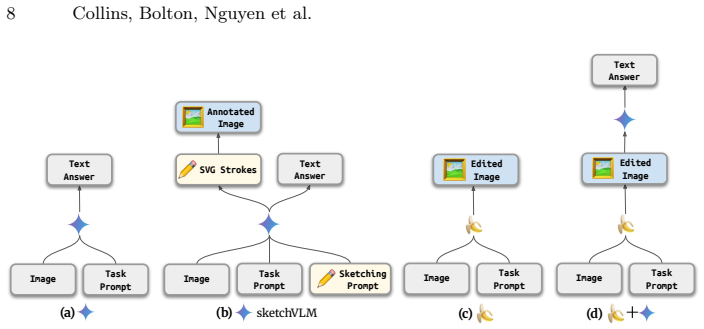
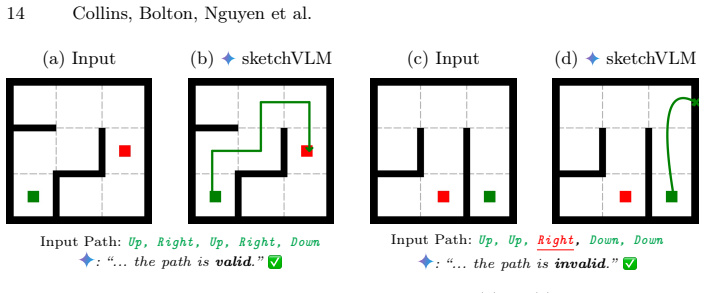
SketchVLM is a model-agnostic framework that prompts vision-language models to output SVG overlays on the original image as a way to explain their reasoning. Across visual-reasoning and drawing tasks the overlays raise accuracy by as much as 28.5 points and annotation quality by up to 1.48 times relative to baselines while remaining more faithful to the model's stated answer. Single-turn generation already delivers strong results, and multi-turn use supports iterative human-AI refinement.
What carries the argument
Non-destructive, editable SVG overlays generated by the VLM that visualize its reasoning steps directly on the input image without altering the original pixels.
If this is right
- Users receive a direct visual record of the model's reasoning that can be inspected and edited without changing the source image.
- Accuracy rises on concrete tasks such as maze navigation, trajectory prediction, and object counting.
- Annotation quality improves over both image-editing tools and fine-tuned sketching models.
- The visual explanations stay more consistent with the model's own text output than baseline approaches.
- Multi-turn interaction becomes possible, allowing humans to refine or question the model's visual steps.
Where Pith is reading between the lines
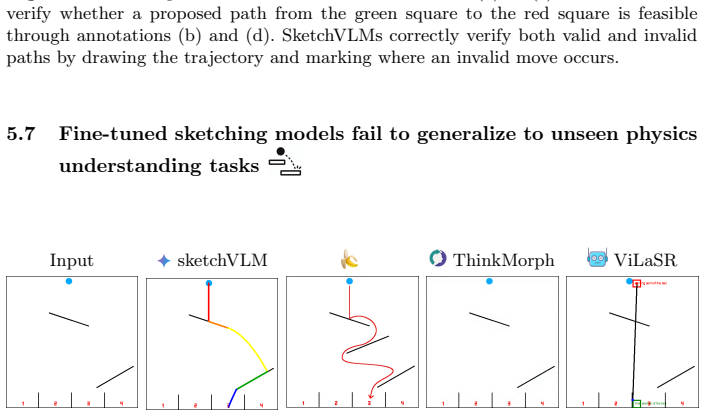
- The method could be extended to video or 3D data by replacing static SVG with time-aware or depth-aware overlays.
- Visual output may help surface and reduce cases where a model gives a correct text answer but follows an inconsistent internal path.
- Educational or assistive interfaces could adopt the same overlay style so users receive both the answer and the visual steps in one view.
- Because the framework is training-free, it could be applied quickly to new models or domains without additional data collection.
Load-bearing premise
The SVG overlays accurately capture the model's actual reasoning rather than being separate drawings that only appear plausible.
What would settle it
A controlled test on a simple counting or navigation task in which the generated SVG marks contradict the model's text answer or fail to improve user accuracy when the marks are shown.
Figures









read the original abstract
When answering questions about images, humans naturally point, label, and draw to explain their reasoning. In contrast, modern vision-language models (VLMs) such as Gemini-3-Pro and GPT-5 only respond with text, which can be difficult for users to verify. We present SketchVLM, a training-free, model-agnostic framework that enables VLMs to produce non-destructive, editable SVG overlays on the input image to visually explain their answers. Across seven benchmarks spanning visual reasoning (maze navigation, ball-drop trajectory prediction, and object counting) and drawing (part labeling, connecting-the-dots, and drawing shapes around objects), SketchVLM improves visual reasoning task accuracy by up to +28.5 percentage points and annotation quality by up to 1.48x relative to image-editing and fine-tuned sketching baselines, while also producing annotations that are more faithful to the model's stated answer. We find that single-turn generation already achieves strong accuracy and annotation quality, and multi-turn generation opens up further opportunities for human-AI collaboration. An interactive demo and code are at https://sketchvlm.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SketchVLM, a training-free, model-agnostic framework enabling VLMs (e.g., Gemini-3-Pro, GPT-5) to generate editable, non-destructive SVG overlays on input images for visually explaining answers to questions about images. It evaluates the approach on seven benchmarks spanning visual reasoning (maze navigation, ball-drop trajectory prediction, object counting) and drawing tasks (part labeling, connecting-the-dots, shape drawing), reporting accuracy gains of up to +28.5 percentage points and annotation quality improvements of up to 1.48x over image-editing and fine-tuned sketching baselines, with overlays claimed to be more faithful to the model's stated answer. Single-turn prompting is highlighted as already effective, with multi-turn enabling further human-AI collaboration; code and an interactive demo are provided.
Significance. If the results hold under rigorous controls, the work offers a practical, zero-training way to add visual interpretability to VLMs, which could aid verification and collaboration on spatial reasoning tasks. Strengths include the model-agnostic design, emphasis on editable SVGs, and public demo. However, the significance is limited by the absence of evidence that SVG generation is integrated into reasoning rather than post-hoc, which directly affects whether the reported gains can be attributed to explanatory power.
major comments (3)
- [§3] §3 (Method, single-turn generation): The procedure instructs the VLM to output both the textual answer and SVG code in one response, but the manuscript provides no mechanism or ablation showing that SVG token generation causally affects the answer tokens (as opposed to rationalizing a pre-computed text answer). This is load-bearing for the central claim that overlays 'explain thoughts' and 'guide users,' especially since VLMs lack an internal visual buffer.
- [§4.2, Table 2] §4.2 (Visual Reasoning Benchmarks, Table 2): The +28.5 pp accuracy gain on maze navigation (and similar gains on trajectory prediction) is reported without specifying exact baseline prompt templates, number of evaluation runs, variance, or statistical significance tests. This makes it impossible to determine whether improvements are robust or attributable to the SVG component versus prompt engineering differences.
- [§4.3] §4.3 (Annotation Quality and Faithfulness): Faithfulness is measured only by consistency between the final text answer and the generated SVG; no experiment tests whether removing or altering the SVG changes the answer (or vice versa). Without this, the 1.48x quality improvement cannot be linked to explanatory utility rather than post-hoc annotation.
minor comments (2)
- [Figures 2-3] Figure 2 and 3: The SVG rendering examples would benefit from explicit callouts indicating which visual elements correspond to the model's reasoning steps versus decorative annotations.
- [§5] §5 (Limitations): The discussion of multi-turn collaboration is promising but lacks quantitative metrics on how many turns are typically needed for user correction or accuracy improvement.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us improve the clarity and rigor of our work. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§3] §3 (Method, single-turn generation): The procedure instructs the VLM to output both the textual answer and SVG code in one response, but the manuscript provides no mechanism or ablation showing that SVG token generation causally affects the answer tokens (as opposed to rationalizing a pre-computed text answer). This is load-bearing for the central claim that overlays 'explain thoughts' and 'guide users,' especially since VLMs lack an internal visual buffer.
Authors: We appreciate this insightful observation regarding the potential post-hoc nature of the SVG generation. In our framework, the single-turn prompt is designed to have the VLM interleave reasoning steps with SVG generation commands, such that the SVG tokens are produced as part of the reasoning process rather than after a finalized text answer. However, we acknowledge the lack of a direct causal ablation in the original submission. In the revised manuscript, we have added an ablation study comparing the VLM's performance when prompted to generate only text answers versus text plus SVG. The results show that requiring SVG generation leads to higher accuracy, supporting that it influences the reasoning. We also clarify that the SVG acts as an external visual buffer, addressing the limitation of VLMs lacking internal ones. We have updated §3 accordingly. revision: yes
-
Referee: [§4.2, Table 2] §4.2 (Visual Reasoning Benchmarks, Table 2): The +28.5 pp accuracy gain on maze navigation (and similar gains on trajectory prediction) is reported without specifying exact baseline prompt templates, number of evaluation runs, variance, or statistical significance tests. This makes it impossible to determine whether improvements are robust or attributable to the SVG component versus prompt engineering differences.
Authors: We thank the referee for pointing out these missing details, which are crucial for reproducibility and assessing robustness. In the revised version, we have included the full prompt templates for all baselines in a new appendix section. Additionally, we now report results averaged over 5 independent runs with standard deviations, and include p-values from paired t-tests confirming statistical significance (p < 0.01) for the reported gains. These additions ensure the improvements can be attributed to the SVG component rather than prompt variations. revision: yes
-
Referee: [§4.3] §4.3 (Annotation Quality and Faithfulness): Faithfulness is measured only by consistency between the final text answer and the generated SVG; no experiment tests whether removing or altering the SVG changes the answer (or vice versa). Without this, the 1.48x quality improvement cannot be linked to explanatory utility rather than post-hoc annotation.
Authors: We agree that demonstrating the causal impact of the SVG on the answer would better link it to explanatory utility. To address this, we have conducted a new experiment in the revised §4.3: we generate the SVG, then create variants where the SVG is removed or key elements altered, and re-prompt the VLM with the modified image to observe changes in the textual answer. The results show that altering the SVG often leads to different answers, indicating interdependence. We also retain the consistency metric but frame it as complementary to this new test. This revision strengthens the claim regarding faithfulness and explanatory power. revision: yes
Circularity Check
No circularity: empirical benchmark claims with no internal derivations or self-referential steps
full rationale
The paper describes a training-free, model-agnostic prompting framework evaluated via direct accuracy and quality comparisons on seven external benchmarks against image-editing and fine-tuned baselines. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the abstract or described method. All reported gains (+28.5 pp accuracy, 1.48x quality) are presented as outcomes of benchmark runs rather than reductions to definitions or prior self-work. The chain is self-contained against external test sets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current VLMs possess the latent ability to generate accurate SVG representations of visual reasoning without additional training.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the AAAI conference on artificial intelligence
Acharya,M.,Kafle,K.,Kanan,C.:Tallyqa:Answeringcomplexcountingquestions. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 8076– 8084 (2019)
2019
-
[2]
AllenInstituteforAI:Molmo:Anopenvision-languagemodelfromallenai.https: //github.com/allenai/molmo(2024), open-source multimodal model family for vision-language tasks; accessed 2026-01-18
2024
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bakhtin, A., van der Maaten, L., Johnson, J., Gustafson, L., Girshick, R.: Phyre: A new benchmark for physical reasoning. arXiv:1908.05656 (2019)
-
[5]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A.S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., et al.: Paligemma: A ver- satile 3b vlm for transfer. arXiv preprint arXiv:2407.07726 (2024)
work page internal anchor Pith review arXiv 2024
-
[6]
Bloomberg Intelligence: Generative ai outlook. Tech. rep., Bloomberg, New York (2025),https://assets.bbhub.io/professional/sites/41/Generative- AI- Outlook.pdf, accessed: 2026-01-18
2025
-
[7]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
cbrower: Vpct ball drop benchmark.https://cbrower.dev/vpct(2025), accessed: 2025-11-09
2025
-
[9]
In: Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F
Chen, D., Chen, R., Zhang, S., Wang, Y., Liu, Y., Zhou, H., Zhang, Q., Wan, Y., Zhou, P., Sun, L.: MLLM-as-a-judge: Assessing multimodal LLM-as-a-judge with vision-language benchmark. In: Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F. (eds.) Proceedings of the 41st Inter- national Conference on Machine Lear...
2024
-
[10]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Chen, X., Mottaghi, R., Liu, X., Fidler, S., Urtasun, R., Yuille, A.: Detect what you can: Detecting and representing objects using holistic models and body parts. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1971–1978 (2014)
1971
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cheng, B., Girshick, R., Dollar, P., Berg, A.C., Kirillov, A.: Boundary iou: Im- proving object-centric image segmentation evaluation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15334–15342 (June 2021)
2021
-
[12]
The Keyword (Google Blog) (Dec 2025),https://blog.google/products- and- platforms/ products/gemini/gemini-3-flash/
DeepMind, G.: Gemini 3 flash: frontier intelligence built for speed. The Keyword (Google Blog) (Dec 2025),https://blog.google/products- and- platforms/ products/gemini/gemini-3-flash/
2025
-
[13]
Accessed: 2026-01-25
DeepMind, G.: Introducing nano banana pro (Nov 2025),https://blog.google/ innovation-and-ai/products/nano-banana-pro/, . Accessed: 2026-01-25
2025
-
[14]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Deitke, M., Clark, C., Lee, S., Tripathi, R., Yang, Y., Park, J.S., Salehi, M., Muen- nighoff, N., Lo, K., Soldaini, L., et al.: Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 91–104 (2025) 20 Collins, Bolton, Nguyen et al
2025
-
[15]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., Shi, G., Fan, H.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review arXiv 2025
-
[16]
The Canadian Cartographer 10(2), 112–122 (1973)
Douglas, D.H., Peucker, T.K.: Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. The Canadian Cartographer 10(2), 112–122 (1973)
1973
-
[17]
com/us/app/skitch-snap-mark-up-share/id425955336, accessed: 2026-01-28
EvernoteCorporation:Skitch:Snap.markup.share.(2026),https://apps.apple. com/us/app/skitch-snap-mark-up-share/id425955336, accessed: 2026-01-28
2026
-
[18]
Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning
Gu, J., Hao, Y., Wang, H.W., Li, L., Shieh, M.Q., Choi, Y., Krishna, R., Cheng, Y.: Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning. arXiv preprint arXiv:2510.27492 (2025)
-
[19]
Advances in Neural Information Processing Systems37, 139348–139379 (2024)
Hu, Y., Shi, W., Fu, X., Roth, D., Ostendorf, M., Zettlemoyer, L., Smith, N.A., Krishna, R.: Visual sketchpad: Sketching as a visual chain of thought for multi- modal language models. Advances in Neural Information Processing Systems37, 139348–139379 (2024)
2024
-
[20]
arXiv preprint arXiv:2506.22146 (2025)
Izadi, A., Banayeeanzade, M.A., Askari, F., Rahimiakbar, A., Vahedi, M.M., Hasani, H., Soleymani Baghshah, M.: Visual structures helps visual reasoning: Addressing the binding problem in vlms. arXiv preprint arXiv:2506.22146 (2025). https://doi.org/10.48550/arXiv.2506.22146
-
[21]
arXiv preprint arXiv:2507.22904 (2025)
Latif, E., Khan, Z., Zhai, X.: Sketchmind: A multi-agent cognitive framework for assessing student-drawn scientific sketches. arXiv preprint arXiv:2507.22904 (2025)
-
[22]
In: Rambow, O., Wan- ner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S
Lei, X., Yang, Z., Chen, X., Li, P., Liu, Y.: Scaffolding coordinates to promote vision-language coordination in large multi-modal models. In: Rambow, O., Wan- ner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S. (eds.) Pro- ceedings of the 31st International Conference on Computational Linguistics. pp. 2886–2903. Association for Computa...
2025
- [23]
-
[24]
arXiv preprint arXiv:2602.09007 (2026)
Li, H., Wu, J., Sun, Q., Li, G., Tian, J., Zhang, H., Lai, Y., An, R., Peng, H., Dai, Y., et al.: Gebench: Benchmarking image generation models as gui environments. arXiv preprint arXiv:2602.09007 (2026)
-
[25]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[26]
Masters, K.: Why OpenAI’s ad announcement should worry retail media net- works (Jan 2026),https : / / www . thedrum . com / opinion / why - openai - s - ad - announcement-should-worry-retail-media-networks
2026
-
[27]
arXiv (2024)
Menon, S., Zemel, R., Vondrick, C.: Whiteboard-of-thought: Thinking step-by-step across modalities. arXiv (2024)
2024
-
[28]
microsoft
Microsoft Corporation: Draw on slides during a presentation (2026),https: / / support . microsoft . com / en - us / office / draw - on - slides - during - a - presentation-80a78a11-cb5d-4dfc-a1ad-a26e877da770, accessed: 2026-01-28
2026
-
[29]
Hot: High- lighted chain of thought for referencing supporting facts from inputs,
Nguyen, T., Bolton, L., Taesiri, M.R., Bui, T., Nguyen, A.T.: Hot: Highlighted chain of thought for referencing supporting facts from inputs. arXiv preprint arXiv:2503.02003 (2025)
-
[30]
OpenAI: Openai gpt-5 system card (2025),https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
OpenAI: Fix with chatgpt (Feb 2026),https://www.youtube.com/watch?v= PHKpsVIdAcc SketchVLM 21
2026
-
[32]
org / search / ?query = silhouette(2025), accessed: 2025-11- 10
Openclipart Contributors: Openclipart silhouette collection.https : / / openclipart . org / search / ?query = silhouette(2025), accessed: 2025-11- 10
2025
- [33]
-
[34]
arXiv preprint arXiv:2302.12066 (2023)
Paiss, R., Ephrat, A., Tov, O., Zada, S., Mosseri, I., Irani, M., Dekel, T.: Teaching CLIP to Count to Ten. arXiv preprint arXiv:2302.12066 (2023)
-
[35]
Perez, S.: Chatgpt’s user growth has slowed, report finds | techcrunch (12 2025), https://techcrunch.com/2025/12/05/chatgpts- user- growth- has- slowed- report-finds/, [Online; accessed 2026-01-28]
2025
-
[36]
The Keyword (Google Blog) (Nov 2025),https://blog.google/products-and- platforms/products/gemini/gemini-3/
Pichai, S., Hassabis, D., Kavukcuoglu, K.: A new era of intelligence with gemini 3. The Keyword (Google Blog) (Nov 2025),https://blog.google/products-and- platforms/products/gemini/gemini-3/
2025
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ramanathan, V., Kalia, A., Petrovic, V., Wen, Y., Zheng, B., Guo, B., Wang, R., Marquez, A., Kovvuri, R., Kadian, A., et al.: Paco: Parts and attributes of common objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7141–7151 (2023)
2023
-
[38]
Ribeiro, L.S.F., Bui, T., Collomosse, J., Ponti, M.: Sketchformer: Transformer- basedrepresentationforsketchedstructure(2020),https://arxiv.org/abs/2002. 10381
2020
- [39]
-
[40]
Su, Z., Li, L., Song, M., Hao, Y., Yang, Z., Zhang, J., Chen, G., Gu, J., Li, J., Qu, X., et al.: Openthinkimg: Learning to think with images via visual tool reinforce- ment learning. arXiv preprint arXiv:2505.08617 (2025)
-
[42]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024)
work page internal anchor Pith review arXiv 2024
-
[43]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Team, K.: Kimi k2.5: Visual agentic intelligence (2026),https://arxiv.org/abs/ 2602.02276
work page internal anchor Pith review arXiv 2026
-
[45]
Vikhyat:Moondream:Tinyvisionlanguagemodel.https://github.com/vikhyat/ moondream(2023), open-source vision-language model with small-footprint multi- modal capabilities
2023
-
[46]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Vinker, Y., Shaham, T.R., Zheng, K., Zhao, A., E Fan, J., Torralba, A.: Sketcha- gent: Language-driven sequential sketch generation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 23355–23368 (2025)
2025
-
[47]
Transactions on Machine Learning Research (2025),https://openreview.net/forum?id=WzS33L1iPC 22 Collins, Bolton, Nguyen et al
Wang, Z., Hsu, J., Wang, X., Huang, K.H., Li, M., Wu, J., Ji, H.: Visually de- scriptive language model for vector graphics reasoning. Transactions on Machine Learning Research (2025),https://openreview.net/forum?id=WzS33L1iPC 22 Collins, Bolton, Nguyen et al
2025
- [48]
-
[49]
Wu, P., Xie, S.: V*: Guided visual search as a core mechanism in multimodal llms (2023).https://doi.org/10.48550/arXiv.2312.14135,https://arxiv.org/ abs/2312.14135
-
[50]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Yu, T., et al.: Visual prompting in multimodal large language models: A sur- vey. arXiv preprint arXiv:2409.15310 (2024).https://doi.org/10.48550/arXiv. 2409.15310,https://arxiv.org/abs/2409.15310
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[51]
Zhang, C., Qiu, H., Zhang, Q., Zeng, Z., Ma, L., Zhang, J.: Deepsketcher: Internal- izing visual manipulation for multimodal reasoning (2025),https://arxiv.org/ abs/2509.25866
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
arXiv preprint arXiv:2510.24514 , year=
Zhang, H., Wu, W., Li, C., Shang, N., Xia, Y., Huang, Y., Zhang, Y., Dong, L., Zhang, Z., Wang, L., Tan, T., Wei, F.: Latent sketchpad: Sketching visual thoughts to elicit multimodal reasoning in mllms. arXiv preprint arXiv:2510.24514 (2025)
-
[53]
Zhang, J., Khayatkhoei, M., Chhikara, P., Ilievski, F.: MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs. In: The Thirteenth International Conference on Learning Representations (2025),https: //arxiv.org/abs/2502.17422
-
[54]
(2025),https://agents-x.space/pyvision/
Zhao, S., Zhang, H., Lin, S., Li, M., Wu, Q., Zhang, K., Wei, C.: Pyvision: Agentic vision with dynamic tooling. (2025),https://agents-x.space/pyvision/
2025
-
[55]
arXiv preprint arXiv:2510.22922 (2025)
Zhou, R., Nguyen, G., Kharya, N., Nguyen, A.T., Agarwal, C.: Improving hu- man verification of llm reasoning through interactive explanation interfaces. arXiv preprint arXiv:2510.22922 (2025)
-
[56]
Zoom Video Communications, Inc.: Using annotation tools for collaboration (2026),https : / / support . zoom . com / hc / en / article ? id = zm _ kb & sysparm _ article=KB0067931, accessed: 2026-01-28
2026
-
[57]
Uni-MMMU: A Massive Multi-discipline Multimodal Unified Benchmark
Zou, K., Huang, Z., Dong, Y., Tian, S., Zheng, D., Liu, H., He, J., Liu, B., Qiao, Y., Liu, Z.: Uni-MMMU: A massive multi-discipline multimodal unified benchmark. arXiv preprint arXiv:2510.13759 (2025) Table of Contents SketchVLM: Vision language models can annotate images to explain thoughts and guide users. . . . . . . . . . . . . . . . . . . . . . . . ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Each image contains only one object corresponding to the target class name
-
[59]
The object’s size occupies at least 10% of the total image area
-
[60]
Each selected object has at least four part labels annotated
-
[61]
Sketch” adds strokes/system prompt; “Grid
The dataset maintains a balanced distribution of objects across different classes. After selection, the final dataset used for the part labeling task consists of 985 images covering 52 class names. 28 Collins, Bolton, Nguyen et al. B.5 Maze Navigation Given a start point, an end point, and a set of direction commands (e.g.,Up, Down, Left, Right), the mode...
-
[62]
The drawn path clips through any of the black walls
-
[63]
For example , the ball path m o m e n t a r i l y di so be ys gravity by moving upwards or moving in a d i r e c t i o n that is not logical for gravity
The drawn path has very u n r e a l i s t i c physics . For example , the ball path m o m e n t a r i l y di so be ys gravity by moving upwards or moving in a d i r e c t i o n that is not logical for gravity
-
[64]
The drawn path s u b s t a n t i a l l y alters the o rig in al image ( like adding or r em ov in g walls )
-
[65]
# # Things that are good
The drawn path con ta in s mu lt ip le d i f f e r e n t paths instead of a single path . # # Things that are good
-
[66]
The drawn path is a single path that clearly shows where the final resting po sit io n of the ball will be
-
[67]
# # Things that are okay
The drawn path does not cut through any of the black walls . # # Things that are okay
-
[68]
We want to heavily pen al iz e the ball going through walls and f o l l o w i n g a totally i l l o g i c a l path
If the path sl ig htl y clips through the walls , but the t r a j e c t o r y of the path still makes sense , then this is only a minor issue and not a major issue . We want to heavily pen al iz e the ball going through walls and f o l l o w i n g a totally i l l o g i c a l path
-
[69]
As long as it is close , then this is not a minor or major issue
It ’s okay if the drawn path does not start exactly at the origin of the ball . As long as it is close , then this is not a minor or major issue . # Scoring b r e a k d o w n
-
[70]
The sketch has several cr iti ca l flaws
-
[71]
The sketch has a c rit ic al flaw
-
[72]
The sketch c on ta in s some errors , overall d i r e c t i o n of the path is valid and makes sense
-
[73]
The sketch c on ta in s one minor logical error
-
[74]
The sketch c on ta in s zero errors . # Output Format You should follow this output format EXACTLY with no other output : { r e a s o n i n g for logical c o n s i s t e n c y score } Quality Score : { integer from 1 - 5} # Example Output < example_1 > The drawing co nt ai ns m ul ti ple errors . The ball path barely clips through one of the platforms , b...
-
[75]
C li pp in g through walls when it is not re qui re d to
-
[76]
The drawn path does not go to the CENTER of each cell that it goes through
-
[77]
Below are more details : # # Things that are bad
The drawn path c o n t r a d i c t s the given text path . Below are more details : # # Things that are bad
-
[78]
For example , even if the d i r e c t i o n s of the drawn path are correct , if the path touches or goes through a wall , then it is a bad sketch
The drawn path clips through any of the black walls when it is not re qui re d to . For example , even if the d i r e c t i o n s of the drawn path are correct , if the path touches or goes through a wall , then it is a bad sketch . That means that if the path goes through a wall even when it is not a b s o l u t e l y r eq ui re d to , then it is a bad sketch
-
[79]
If the drawn path is a curved path , then this does not apply
Each move in the drawn path should go to the ** center ** of the next cell in the path . If the drawn path is a curved path , then this does not apply . This is i m p o r t a n t ! Look at each step in the path and make sure that the drawn path goes to the center of the next cell
-
[80]
The sketch c on ta in s a d d i t i o n a l moves that are not in the path
-
[81]
The drawn sketch c o n t r a d i c t s the given text path
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.